 SLaK:從稀疏性的角度將卷積核擴展到51×51
SLaK:從稀疏性的角度將卷積核擴展到51×51
導讀
本文作者從稀疏性的角度提出了一個應用超大 Kernel 的方法,它可以平滑地將 Kernel 擴展到 61×61,并具有更好的性能。因此作者將模型命名為稀疏大 Kernel 網絡 (SLaK),一種配備 51×51 卷積核的純 CNN 架構。
1 SLaK:從稀疏性的角度將卷積核擴展到 51×51
論文名稱:More ConvNets in the 2020s: Scaling up Kernels Beyond 51 × 51 using Sparsity

論文:https://arxiv.org/abs/2207.03620
代碼:https://github.com/VITA-Group/SLaK
1.1 SLaK 原理分析
本文的背景是超大 Kernel 的卷積神經網絡的出現,大核卷積的思路來自 ViT 模型建模全局信息的性質。其中代表性的工作就是 RepLKNet,將卷積核的大小增加到了 31×31,同時獲得了和 Swin Transformer 相當的分類性能和更好的下游任務性能。本文作者探索了訓練大于 31×31 的極端卷積的可能性,本文發現持續地增加卷積核會帶來性能飽和,所以本文意在探索是否可以通過策略性地擴大卷積來消除性能差距。經過不斷探索,本文作者從稀疏性的角度提出了一個應用超大 Kernel 的方法,它可以平滑地將 Kernel 擴展到 61×61,并具有更好的性能。因此作者將模型命名為稀疏大 Kernel 網絡 (SLaK),一種配備 51×51 卷積核的純 CNN 架構。
1.1.1 背景和動機
在現代計算機視覺任務中,通用視覺模型最早以深而 Kernel 小的 CNN 為主。自從 ViTs 出現之后,人們漸漸發現建模全局信息的重要性:人們開始覺得 ViTs 的幾本構件:類 Self-attention 模塊具有建模全局信息的能力[1]。很多工作也證明了,即使 Token-Mixer 不設計成 Query-Key-Value 的形式,模型也能夠訓練出很出色的性能。所以大家覺得,Self-attention 的這種在全局尺度或較大的窗口內進行運算的模式,才是模型性能提升的關鍵。來自單個 Self-attention 層的每個輸出能夠從相對大的區域收集信息。與 CNN 共享權重的小滑動窗口 (3×3 或 5×5) 相比,ViTs 中具有較大窗口大小的全局注意或局部注意直接使每一層能夠捕獲大的感受野。
受這種趨勢的啟發,最近一些關于 CNN 的工作 (RepLKNet[2],ConvNeXt[3]) 通過設計較大的 Kernel 獲得了與Swin Transformer 相當的結果。但即使是使用了重參數化技術,使用平行的小 Kernel 分支來輔助訓練,大 Kernel 仍然存在難以訓練的問題。本文發現,隨著 Kernel 大小的不斷增加,RepLKNet 的性能逐漸趨于飽和。我們是否可以通過進一步將 Kernel 的大小從 31×31 再向上擴展,以超越基于 Transformer 的模型,這仍然是一個謎,所以本文意在探索是否可以通過策略性地擴大卷積來消除性能差距。
具體而言,本文作者從稀疏性的角度來探索這個問題。稀疏性是人類視覺系統中視覺皮層 (V1) 的重要特點,視覺皮層中傳入的刺激可以假設為稀疏編碼 (sparsely coded) 并被選擇。作者廣泛研究了大 Kernel 的可訓練性,并在本文章給出了3個主要觀察結果:
直接訓練大 Kernel 模型,或者輔助結構重新參數化技術都不能將核的大小縮放到 31×31 以上。
用兩個矩形的并行內核 (M×N 和 N×M,其中 N < M) 代替一個大的 M×M Kernel,可以平滑地將內核大小縮放到 61×61,并改進性能。
使用稀疏方法,同時加大模型的寬度,可以再顯著提升性能。
基于這些觀察,本文提出的稀疏大 Kernel 網絡 (SLaK),一種新的純 CNN 架構,配備了前所未有的 51×51 的超大 Kernel。在包括 ImageNet 圖像分類、ADE20K 語義分割和 PASCAL VOC 2007 上的物體檢測在內的各種任務中進行評估,SLaK 實現了比 SOTA CNN (如 ConvNeXt 等) 以及 SOTA Transformer (如 Swin 等) 更高的準確性。有效感受野 (ERF) 的分析也證明了 SLaK 能夠覆蓋比現有更大的 ERF 區域,同時引入更多的 human-like peripheral shape bias。
1.1.2 動態稀疏化技術
動態稀疏化技術是一種從頭開始訓練稀疏神經網絡的技術。后訓練剪枝 (post-training pruning) 一般是指先訓練好一個密集的大模型,再對其參數進行剪枝。但在動態稀疏化中,模型從一開始就是稀疏的,訓練和推理的 FLOPs 以及內存的需求只是密集模型的一小部分。不涉及任何預訓練。
如下圖1所示,動態稀疏化技術來自 Sparse Evolutionary Training (SET) 方法,該方法首先隨機初始化層之間的稀疏連接,并在訓練過程中通過參數修剪-增長方案動態調整模型的稀疏連接。這個方案允許模型的稀疏結構逐漸進化,比單純訓練靜態稀疏網絡獲得更好的性能。
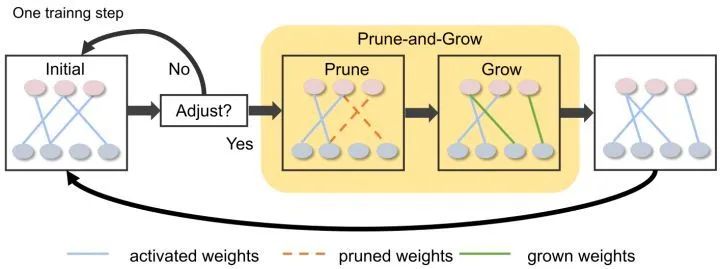
圖1:動態稀疏化技術
1.1.3 縮放卷積核的大小使之超過 31×31 的三個觀察
作者首先研究大于 31×31 的極限 Kernel 的性能,并分享3個主要的觀察結果。以最近的 SOTA CNN 架構ConvNeXt 和 ImageNet-1K 數據集作為基準。
作者遵循骨干模型的一般訓練策略,即數據增強方式為 Mixup,Cutmix,RandAugment,Random Erasing 。正則化方法是:Stochastic Depth 和 Label Smoothing。AdamW 作為優化器,分析性試驗都是訓練 120 Epochs 目的是快速觀察方法的效果,正式實驗訓練 300 Epochs,以便能夠與最先進的模型進行公平的比較。
觀察1:已有方法 (結構重參數化技術) 無法進一步將 Kernel 的大小從 31×31 再向上擴展
RepLKNet 通過結構重新參數化技術成功地將卷積擴展到 31×31,同時使得模型獲得了和 Swin Transformer 相當的性能。本文作者進一步將內核大小增加到 51×51 和 61×61,看看更大的 Kernel 是否能夠帶來更多的性能增益。按照 RepLKNet 中的設計,作者相繼將每一個 Stage 的 Kernel 大小設置為 [51, 49, 47, 13] 和 [61, 59, 57, 13],結果如下圖2所示。結果顯示,僅僅將 Kernel 的大小從 7×7 增加到 31×31 會顯著降低性能,而 RepLKNet可以克服這個問題,將精度提高 0.5%。然而,這種趨勢不適用于較大的內核,因為將 Kernel 的大小增加到51×51 會開始損害性能。
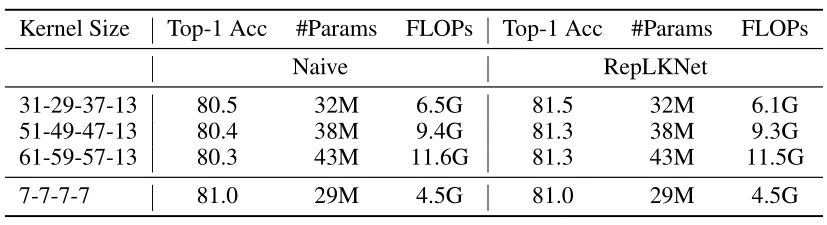
圖2:在 ImageNet-1K 上用各種大 Kernel 訓練的 ConvNeXt-T 的測試精度,naive 是指直接增加 Kernel 的大小,RepLKNet 是指使用了結構重參數化技術
對于這種現象,一種合理的解釋是:我們把卷積核擴大到 51×51 或者 61×61 之后,雖然模型的感受野增加了,但是它可能無法保持某些期望的特性,比如局部性。由于標準 ResNet 和 ConvNeXt 的 Stem 模塊已經把輸入降采樣了4倍,所以 51×51 這種超大的 Kernel 其實就基本相當于是 global convolution (對于 224×224 的 ImageNet 而言)。因此,這種觀察是有意義的,因為在 ViTs 的類似機制中,局部注意力 (如 Swin) 通常優于整體注意力 (如 DeiT) 。借此啟發,作者希望借助局部性來解決這個問題,同時要使模型保留捕捉全局關系的能力。
觀察2:把一個正方形的大 Kernel 分解成兩個矩形的、平行的不規則 Kernel 可以平滑地將 Kernel 的大小擴展到61
作者的方法是用兩個平行的矩形卷積來逼近超大 M×M 的 Kernel,這兩個卷積的 Kernel 大小分別是 M×N 和N×M (其中 N < M),如下圖2所示。這種等于是改進得 RepLKNet,只是并行的分支變為了兩支。同時再多一支 5×5 的分支,并且在 BN 層的輸出合并這3個分支。

圖2:用兩個平行的矩形卷積來逼近超大 M×M 的 Kernel,這兩個卷積的 Kernel 大小分別是 M×N 和N×M (其中 N < M)
這種分解不僅繼承了超大 Kernel 捕捉長距離關系的能力,而且可以提取具有較短邊緣的局部上下文特征。此外,如下圖3所示,現有的大 Kernel 訓練技術 (RepLKNet) 隨著 Kernel Size 的增加,計算和存儲開銷也呈平方增長。N=5 被記為 Decomposed,由于不再有 31×31 的大 Kernel,所以 Decomposed 相比于結構重參數化的 31×31 會犧牲一定的精度。但是,隨著卷積大小增加到全局卷積,它可以令人驚訝地將內核大小擴展到61,同時提高性能。
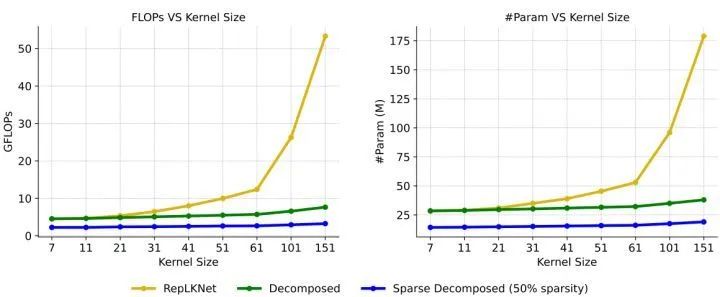
圖3:應用于 ConvNeXt-T 時各種大 Kernel 訓練方法的縮放效率
觀察3:使用更多稀疏的 Group,可以提高模型的容量
ConvNeXt 的卷積操作設計原則是使用 Depth-wise Convolution,同時加大寬度,因此這個設計思路可以概括成 "use more groups, expand width"。本文的設計思路可以概括成 "use sparse groups, expand more"。具體來講,作者首先用稀疏卷積替換密集卷積,其中稀疏核基于 SNIP 構建。在構建之后,作者用動態稀疏化技術來訓練稀疏模型。其中稀疏化的權重在訓練期間動態調整:先隨機剪掉一部分,再隨機增加相同數量的權重。這樣做允許稀疏權重的動態適應,從而產生更好的局部特征。由于核在整個訓練過程中是稀疏的,相應的 Params 和訓練/推理的 FLOPs 都不大。作者用 40% 的稀疏度,結果被記為 Sparse Decomposed。

圖4:ConvNeXt 在不同實驗設置下的測試精度
如上圖4所示為 ConvNeXt 在不同實驗設置下的測試精度。從第2列可以看到,用 40% 的稀疏度之后,模型的參數量和計算量出現了明顯下降,但是性能出現了暫時的下降。但是動態稀疏可以提高模型的可擴展性 (scalability)。具體而言就是,動態稀疏性允許我們擴大模型的規模。例如,使用相同的稀疏度 (40%),可以將模型寬度 (width) 擴展1.3倍,同時保持參數計數和 FLOPs 與密集模型大致相同。這帶來了顯著的性能提升,使用 51×51Kernel 時,性能從 81.3% 提高到 81.6%。
1.1.4 稀疏大 Kernel 網絡:SLaK
到目前為止,已經可以成功地將 Kernel 的大小擴展到 61,同時不會犧牲模型的性能。擴展的方法包括2個稀疏啟發的設計。在宏觀層面上,構建了一個系數模型,通過動態稀疏化技術提高模型的容量。在微觀層面上,作者將一個超大 Kernel 分解為兩個互補的動態稀疏核,以提高超大 Kernel 的可擴展性。作者直接從頭開始訓練 SLaK,不涉及任何預訓練或微調。
SLaK 是基于 ConvNeXt 的架構構建的,Stem 的設計繼承了 ConvNeXt。SLaK-T 的每個 Stage 的塊數為 [3, 3, 9, 3],SLaK-S/B 的每一階段的塊數為 [3, 3, 27, 3],Stem 層是一個 K=S=4 的卷積層。作者將 ConvNeXt 各個 Stage 的 Kernel 的大小分別增加到 [51, 49, 47, 13],并將每個 M×M 的 Kernel 替換為 M×5 和 5×M 的組合。作者發現在 M×5 和 5×M 之后加一個 BN 層之后再求和非常有必要,同時按照使用更多稀疏的 Group 的原則,作者進一步稀疏化整個網絡,并將各個 Stage 的寬度擴展1.3倍,最終得到 SLaK-T/S/B 模型。
1.1.5 SLaK 實驗結果
圖像分類實驗設置:ImageNet 數據集,300 Epochs,AdamW 優化器,Batch size:4096,weight decay:0.05,lr:4e-3,20-epoch linear warmup rate,cosine lr decay schedule,數據增強:RandAugment (rand-m9-mstd0.5-inc1), Label Smoothing (coefficient of 0.1), Mixup (α = 0.8), Cutmix (α = 1.0), Random Erasing (p = 0.25), Stochastic Depth with drop rate (0.1 SLaK-T, 0.4 SLaK-S, 0.5 SLaK-B),EMA (decay factor=0.9999)。
語義分割實驗設置:ADE20K 數據集,ImageNet pre-trained 的預訓練模型,UperNet 語義分割模型,訓練 80K-iteration,測試 single-scale mIoU。
目標檢測實驗設置:PASCAL VOC 數據集,ImageNet pre-trained 的預訓練模型,Faster-RCNN 目標檢測模型,訓練 36 Epochs,遵循 Swin。
ImageNet 實驗結果
如下圖4所示,在模型 Params 和 FLOPs 相似的情況下,SLaK 優于現有的卷積模型,如 ResNe(X)t 、RepLKNet 和 ConvNeXt。在不使用任何復雜的 Self-attention 模塊和 Patch embedding 的情況下,SLaK 能夠實現比最先進的視覺 Transformer (Swin,PVT 等)更高的精確度。更有趣的是,直接將 ConvNeXt-S 的 7×7 替換為 51×51能夠提高 0.7% 的精度。
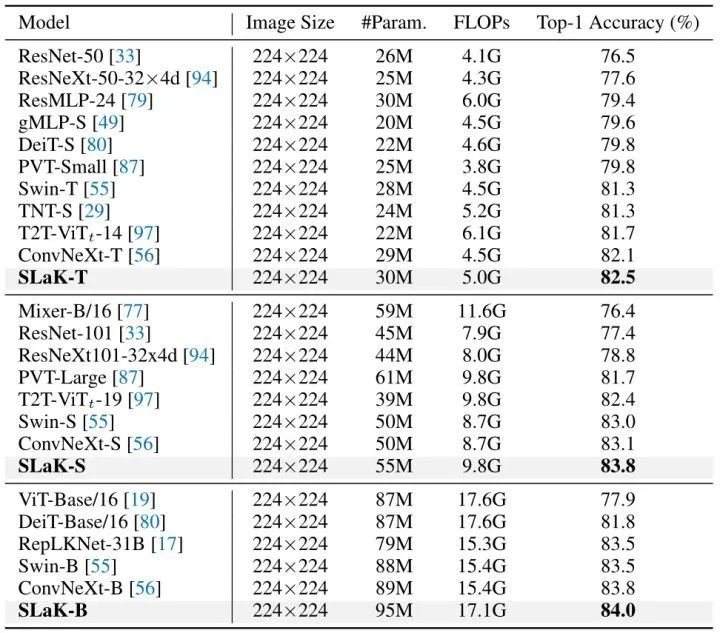
圖4:ImageNet 實驗結果
語義分割實驗結果
ADE20K 數據集使用了 180K-iteration training schedule。結果如下圖5所示,可以看到一個非常明顯的趨勢,性能隨著 Kernel 大小的增加而增加:RepLKNet 將 ConvNeXt-T 的 Kernel 大小從 7×7 擴展到 31×31,mIoU 提高了 1.6%。值得注意的是,具有更大 Kernel (51×51) 的 SLaK-T 比具有 31×31 內核的 ConvNeXt-T (RepLKNet) 進一步提高了 0.9% mIoU,而所需的 FLOPs 更少。
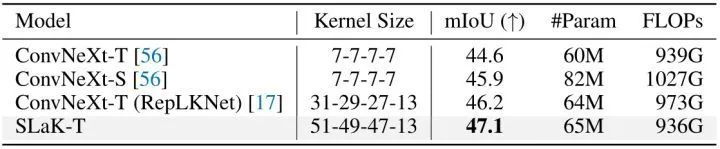
圖5:語義分割實驗結果
目標檢測實驗結果
如下圖6所示顯示了 SLaK-T、ConvNeXt-T、RepLKNet 和傳統卷積網絡 (ResNet) 的比較結果。同樣,大 Kernel 會帶來更好的性能。具體來說,具有 31×31 Kernel 的 ConvNeXt-T 比 7×7 Kernel 的平均精度 (mAP) 高 0.7%,具有 51×51 Kernel 大小的 SLaK-T 進一步帶來了 1.4% 的 mAP 提升,突出了超大 Kernel 在下游視覺任務中的關鍵作用。
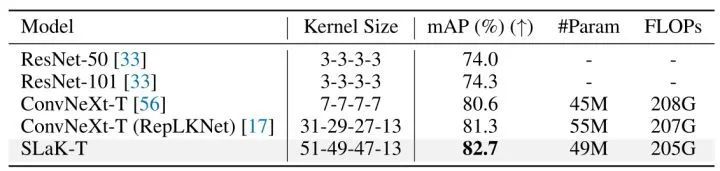
圖6:目標檢測實驗結果
1.1.6 SLaK 的其他討論
淺而大 Kernel 的 CNN 比深而小 Kernel 的 CNN 具有更大的有效感受野
RepLKNet 的作者在原論文中討論了幾種網絡模型的有效感受野:RepLKNet 作者認為, 就獲得大的有效感受野而言, 單個大 Kernel 比許多小 Kernel 有效得多。根據有效感受野 (ERF) 理論 , ERF的大小與 成正比, 其中 是卷積核大小, 是深度, 即層數。換句話說, ERF 隨 Kernel 的大小線性增長, 而隨深度亞線性增長。
因此,SLaK 中的 Kernel 分解操作背后的假設是,兩個獨立的 M×N 和 N×M 的 Kernel 可以很好地保持大 Kernel 在捕獲很大的有效感受野方面的能力,同時卷積核的短邊 (N) 也有利于捕捉細粒度的局部特征。為了評估這一假設,作者對 SLaK 和 RepLKNet 捕獲的 ERF 進行了比較。
作者從驗證集中選擇50張圖像并將其大小調整為 1024×1024,測量輸入圖像上的像素對最后一層中生成的特征圖的中心點的貢獻,并將它們相加得到 1024×1024 矩陣。如下圖7所示作者分析了 ResNet 和 RepLKNet 的有效感受野。可視化有效感受野的方法是:
令 表示輸入圖片, 表示最終的輸出特征, 我們希望測量一下輸入圖片的每一個像素對于最終輸出特征中心位置 的貢獻。這可以通過 autograd 機制通過計算 對輸入的導數來得到。形式上, 得分矩陣 由下式給出:
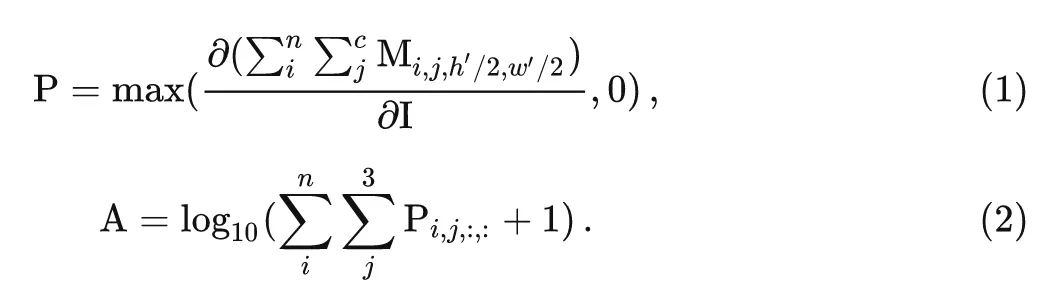
最后, 把得分矩陣 rescale 到 0-1。簡而言之, 得分矩陣 測量輸入圖像上的對應像素對由最后一層產生的特征圖的中心點的貢獻。如上圖1所示, 暗色區域分布得越離散, 代表有效感受野 (ERF) 越大。結果發現, 更多的層 (例如從 ResNet-101 到 ResNet-152) 對擴大 ERF 幾乎沒有幫助。相反, 較淺的大 Kernel 模型的有效感受野非常大。
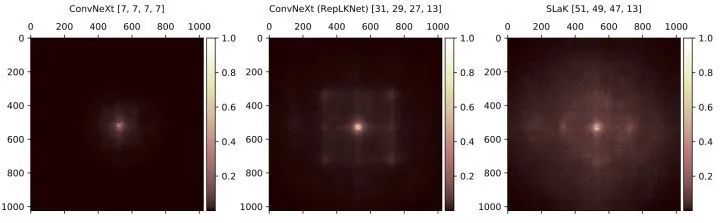
圖7:ConvNeXt,RepLKNet 和 SLaK 的有效感受野,以及所使用的的卷積核大小
從圖7中可以看到,盡管原始的 ConvNeXt 已經將 Kernel 大小提高到 7×7,但是對輸出的某個像素具有高貢獻度的輸入圖片的像素僅出現在中心部分。對于 RepLKNet,即使它使用了 31×31 的 Kernel,也不足以讓 ConvNeXt 的有效感受野覆蓋整個輸入。相比之下,SLaK 的高貢獻像素分布在更大的輸入范圍內,表明 ERF 更大。另外,SLaK 的感受野呈現出了明暗交替的現象,中心區域更加明亮,外圍區域更暗淡一點。這一發現與假設完全一致,即 SLaK 不僅能夠捕獲長程距離的依賴性,還能夠捕獲局部特征。
作者還做了定量分析:給定一個閾值 , 作者報告了覆蓋面積的貢獻分數達到了閾值 的最小矩形的面積比 ,如下圖8所示。比如對于 ResNet-101 模型, 中間 102×102 的區域的貢獻分數達到了閾值 20%, 所占面積為 。較大的值代表模型考慮更大范圍的像素來做決策。可以看到, 有了全局內核, SLaK 自然會比 ConvNeXt 和 RepLKNet 的最小矩形的面積比 值高。
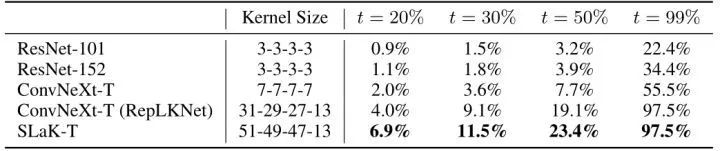
圖8:ERF 的定量分析結果
使用更多稀疏的 Group,可以提高模型的容量
除此之外,本文的第3點觀察 "使用更多稀疏的 Group,可以提高模型的容量"。為了維持模型的參數量和計算量盡量接近,當模型的稀疏度足夠低時,寬度就得小一些;當模型的稀疏度很高時,寬度就可以大一些。因此,存在一個 Sparsity-Width 的權衡。為了更好地理解這種權衡,作者選擇了 Sparsity-Width 的5種組合,所有設置都有大約 5.0M 的 FLOPs,但網絡寬度不同。實驗在 SLaK-T 上進行。正如作者預期的那樣,隨著模型寬度的增加,模型的性能不斷提高,直到寬度因子達到1.5倍。
之后,隨著稀疏度的進一步增大,模型開始變得高度稀疏,使得訓練變得很困難,所以此時再增加寬度,就會開始損害性能。
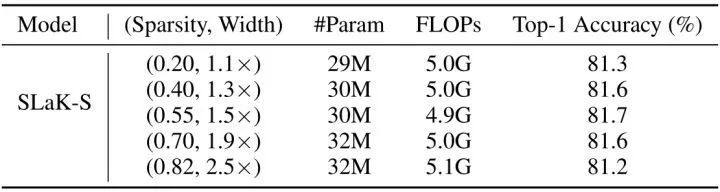
圖9:Sparsity-Width 的權衡
總結
本文發現持續地增加卷積核會帶來性能飽和,所以本文意在探索是否可以通過策略性地擴大卷積來消除性能差距。經過不斷探索,本文作者從稀疏性的角度提出了一個應用超大 Kernel 的方法,它可以平滑地將 Kernel 擴展到 61×61,并具有更好的性能。因此作者將模型命名為稀疏大 Kernel 網絡 (SLaK),一種配備 51×51 卷積核的純 CNN 架構。主要的策略是把一個正方形的大 Kernel 分解成兩個矩形的、平行的不規則 Kernel,以及使用更多稀疏的 Group,同時提高模型的寬度。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100835 -
卷積
+關注
關注
0文章
95瀏覽量
18521 -
cnn
+關注
關注
3文章
352瀏覽量
22237
原文標題:ICLR 2023 | 卷積核大到51x51!SLaK:一種純CNN新主干
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
可以將ESP Basic擴展到ESP32嗎?

ADI公司如何從硬件擴展到軟件和API以及集成收發器的功能
蘋果將iPhone 的保修范圍擴展到全球
如何使用稀疏卷積特征和相關濾波進行實時視覺跟蹤算法
蘋果可能正在尋求將蘋果地圖的范圍擴展到其iDevices之外
AN-1529:使用AD9215高頻VGA將10位65 MSPS ADC的動態范圍擴展到100 dB以上

通過應用頻率將TPS92210的調光范圍擴展到通用AC范圍





 工商網監
工商網監
評論