") 視覺-語言預訓練入門指南
視覺-語言預訓練入門指南
前言
視覺-語言 (Vision-Language, VL) 是計算機視覺和自然語言處理這兩個研究領域之間形成的交叉領域,旨在賦予 AI 系統(tǒng)從多模態(tài)數(shù)據(jù)中學習有效信息的能力。受 NLP 預訓練語言模型(如BERTGPT等)的啟發(fā),視覺-語言預訓練 (Vision-Language Pre-training, VLP) 逐漸受到關注,成為如今 VL 任務的核心訓練范式。本文對 VLP 領域近期的綜述文章進行整理,回顧其最新的研究進展,旨在提供一份 VLP 入門指南。
什么是視覺-語言任務?
首先,我們需要知道視覺-語言任務是什么?顧名思義,視覺-語言任務指的是處理視覺和語言這兩種多模態(tài)信號輸入的任務,根據(jù)歷史工作主要可以分為三類:
圖像-文本任務。
這一類任務在 VL 研究中最重要并且也最廣泛,包含視覺問答、圖像描述、圖像-文本檢索等任務(如圖 1 中橙色部分)。另外圍繞這些任務,若干其它的相關任務被提出。例如文本-圖像生成,它被看作是圖像描述的孿生任務,模型需要根據(jù)輸入的文本生成高保真圖像。本文后續(xù)介紹的 VLP 模型主要以圖像-文本任務為主。
視作 VL 問題的 CV 任務。
傳統(tǒng)的 CV 領域中的圖像分類、目標檢測和分割任務等(如圖 1 中粉色部分)被看作是單純的計算機視覺問題。而隨著 CLIP 和 ALIGN 等多模態(tài)大模型的出現(xiàn),研究人員意識到語言監(jiān)督信號也可以在 CV 任務中發(fā)揮重要作用。具體做法是,首先利用從網(wǎng)絡上抓取的帶噪聲的大規(guī)模圖像-文本對數(shù)據(jù),從頭開始對視覺編碼器進行預訓練。其次,不再將監(jiān)督信號(例如類別標簽)用作獨熱編碼向量,而是考慮標簽中所蘊含的語義信息,并將這些 CV 任務視作 VL 問題來解決。
視頻-文本任務。
除了靜態(tài)的圖像,視頻也是一種重要的視覺表現(xiàn)形式。那么自然,上述所有圖像-文本任務都有相應的視頻-文本任務,例如視頻字幕、視頻檢索和視頻問答任務等(如圖 1 中綠色部分)。與圖像相比,視頻輸入的特殊性要求系統(tǒng)不僅要捕獲單個視頻幀中的空間信息,還要捕獲視頻幀之間固有的時序依賴性。
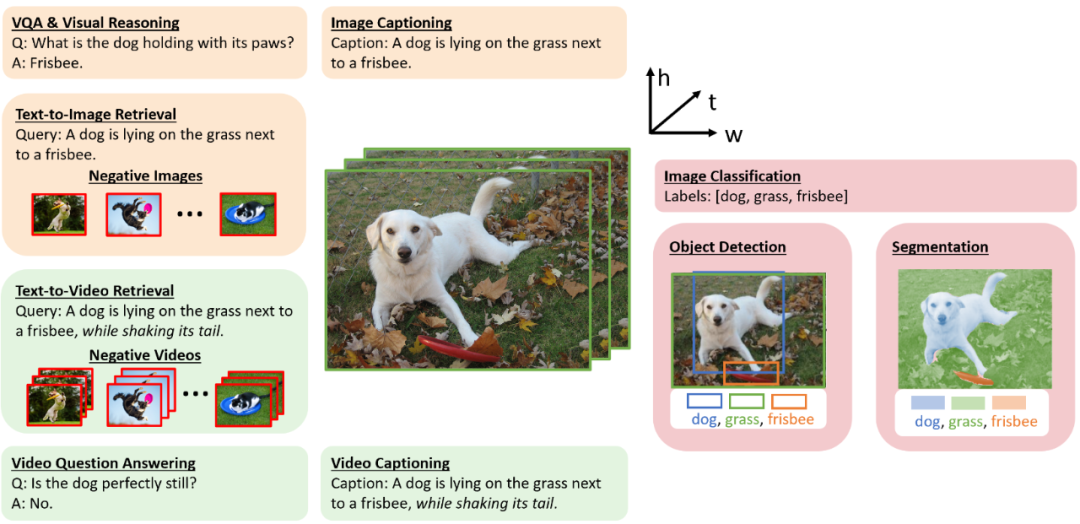
圖 1:視覺-語言任務圖示
模型結構
受預訓練語言模型 (PLM) 的啟發(fā),以及 NLP 和 CV 領域越來越多地使用基于 Transformer 的統(tǒng)一架構的趨勢,關于視覺-語言預訓練的研究也受到越來越多的關注。VLP 主要通過在大規(guī)模數(shù)據(jù)上進行預訓練來學習不同模態(tài)之間的語義對應關系。例如,在圖像-文本預訓練中,我們希望模型將文本中的“狗”與圖像中“狗”的樣子相關聯(lián)。
在視頻-文本預訓練中,我們期望模型將文本中的對象/動作映射到視頻中的對象/動作。為了實現(xiàn)這一目標,需要巧妙地設計 VLP 的模型架構,使模型有能力挖掘不同模態(tài)之間的關聯(lián)。
具體來講,給定圖像-文本對,VL 模型首先分別通過視覺編碼器和文本編碼器提取視覺特征 = {1, ··· , M} 和文本特征 = {1, ··· , N}。這里,M 是圖像的視覺特征數(shù)量,它可以是圖像區(qū)域/網(wǎng)格/圖像塊的數(shù)量,具體取決于所使用的特定的視覺編碼器,N 則是句子中子詞的數(shù)量。然后將視覺和文本特征送入多模態(tài)融合模塊來產(chǎn)生跨模態(tài)表示,然后在生成最終輸出之前可選擇地將其送入至解碼器。圖 2 展示了這個通用框架的結構。
在許多情況下,圖像/文本主干、多模態(tài)融合模塊和解碼器之間沒有明確的界限。一般將模型中僅以圖像/文本特征作為輸入的部分稱為相應的視覺/文本編碼器,將模型中同時以圖像和文本特征作為輸入的部分稱為多模態(tài)融合模塊。除此之外,如果有額外的模塊將多模態(tài)特征作為輸入來生成輸出,則稱之為解碼器。
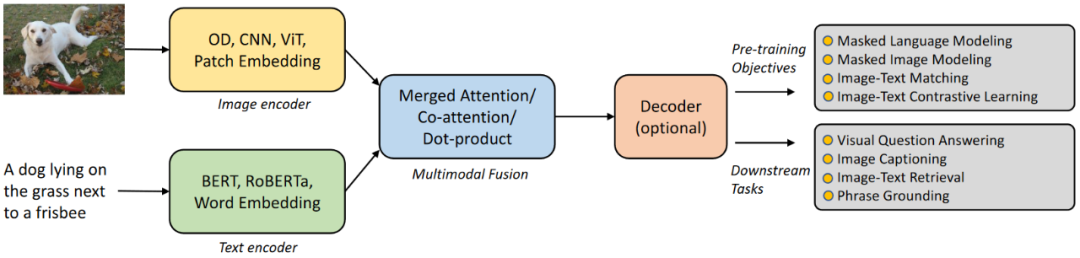
圖 2:基于Transformer的VL模型的通用框架
視覺編碼器
視覺編碼器主要分為三種類型:(i) 對象檢測器 (OD),(ii) 卷積神經(jīng)網(wǎng)絡 (CNN),以及 (iii) Vision Transformer (ViT):
基于OD區(qū)域特征:使用 Object Detectors(例如 Faster R-CNN)識別圖像中的目標區(qū)域,獲取每個目標區(qū)域的特征表示。例如在圖 3 中,ViLBERT 通過提取邊界框及其視覺特征來生成圖像的區(qū)域特征,并與文本特征拼接輸入到主模型中。雖然區(qū)域特征是對象級的且語義豐富,但是提取區(qū)域特征往往十分耗時,并且訓練好的 OD 通常在預訓練期間被凍結,這可能會限制 VLP 模型的容量。
基于CNN網(wǎng)格特征:為了解決上述兩個問題,研究人員嘗試了不同的方法來以端到端的方式預訓練 VL 模型。其中,PixelBERT 和 CLIP-ViL 提出將卷積神經(jīng)網(wǎng)絡的網(wǎng)格特征和文本一起直接輸入到到后續(xù)的 Transformer 中。此外,SOHO 首先使用已學習的視覺字典離散化網(wǎng)格特征,然后將離散化特征輸入到它們的跨模態(tài)模塊中。雖然直接使用網(wǎng)格特征會很有效,但 CNN 和 Transformer 所使用地優(yōu)化器通常不一致。例如,PixelBERT 和 CLIP-ViL 在 Transformer 使用 AdamW,而在 CNN 中使用 SGD。
基于ViT 圖像塊特征:第三種編碼器類型來源于 Vision-Transformer,它首先將圖像切分成圖像塊,然后將其展平為向量并線性投影以獲得圖像塊的嵌入序列。同時,一個可學習的特殊標記 [CLS] 嵌入也被添加到序列中。這些圖像塊嵌入,與可學習的 1D 位置嵌入和潛在的圖像類型嵌入相加后,被饋送到多層的 Transformer 塊中以獲得最終的輸出圖像特征。
隨著 ViT 的發(fā)展,這種視覺特征編碼方式逐漸成為主流,與前兩種方式相比它運行效率更高,不需要依賴預先訓練好的 Object Detection 模型或前置的 CNN 特征提取模塊。
總之,無論使用什么視覺編碼器,輸入圖像都被表示為一組特征向量 = {1, ··· , M}。
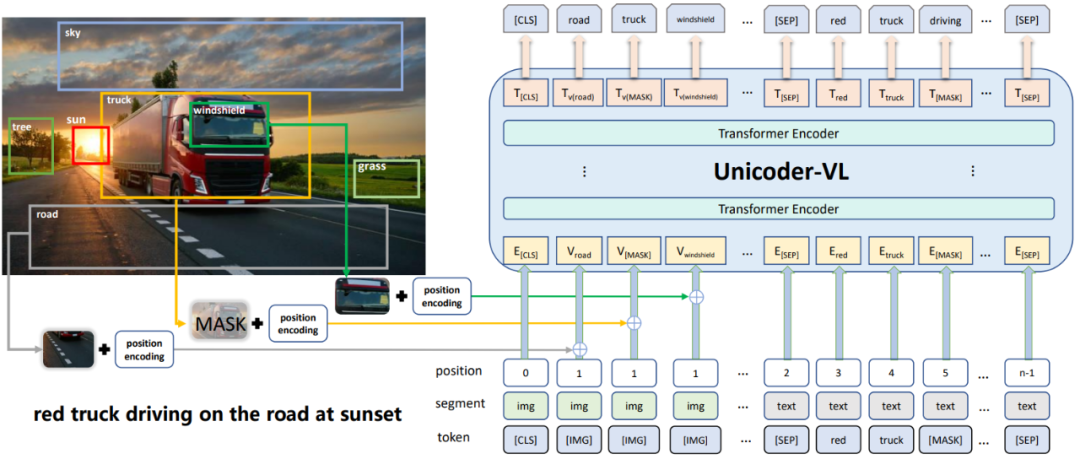
圖 3:ViLBERT中的OD區(qū)域特征
文本編碼器
文本編碼器的處理方式遵循 BERT 和 RoBERTa 等預訓練語言模型。如圖 4 所示,首先將輸入句子分割成子詞序列。然后在句子的開頭和結尾插入兩個特殊標記以生成輸入文本序列。在獲得文本嵌入之后,現(xiàn)有的工作要么將它們直接輸入給多模態(tài)融合模塊,要么在融合之前輸入給若干個文本信息處理層。
對于前者,融合模塊通常使用 BERT 進行初始化,文本編碼器和多模態(tài)融合也因此作用在單個 BERT 模型中,在這種情況下,我們將文本編碼器視為詞嵌入層。在歷史的工作中,研究人員研究了使用 BERT、RoBERTa、ELECTRA、ALBERT 和 DeBERTa 等多種不同的模型進行文本編碼。簡而言之,無論使用什么文本編碼器,輸入文本都表示為一組特征向量 = {1, ··· , N}。
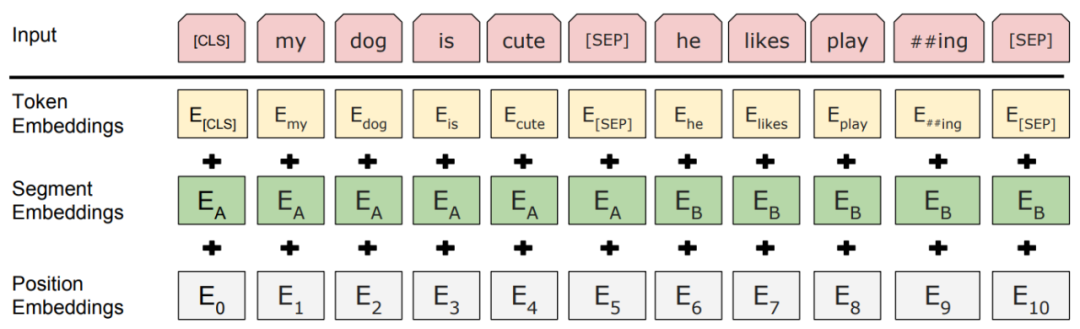
圖 4:文本編碼器輸入表示
多模態(tài)融合
多模態(tài)融合模塊旨在將編碼自不同模態(tài)的信息整合成一個穩(wěn)定的多模態(tài)表征。對于像 CLIP 和 ALIGN 這樣的雙編碼器模型,融合是通過兩個全局圖像和文本特征向量之間的點積來執(zhí)行的。對于融合編碼器,它以 = {1, ··· , M} 和 = {1, ··· , N} 作為輸入,并學習表示為 = {1, ··· , M} 和 = {1, ··· , N}。多模態(tài)融合模塊主要有兩類,即單流模式和雙流模式,也稱作 merged attention 和 co-attention,如圖 5 所示。
單流模式指的是將視覺和文本編碼特征組合在一起,然后輸入單個 Transformer 塊中,如圖 5(a) 所示。單流架構通過合并注意力來融合多模態(tài)輸入,通常也被叫做 merged attention。單流架構的參數(shù)效率更高,因為兩種模式都使用相同的參數(shù)集。
雙流模式是指視覺和文本編碼特征沒有組合在一起,而是獨立輸入到兩個不同的 Transformer 塊,如圖 5(b) 所示。這兩個 Transformer 塊不共享參數(shù),而是通過交叉注意力實現(xiàn)跨模態(tài)交互,因此也被叫做 co-attention。
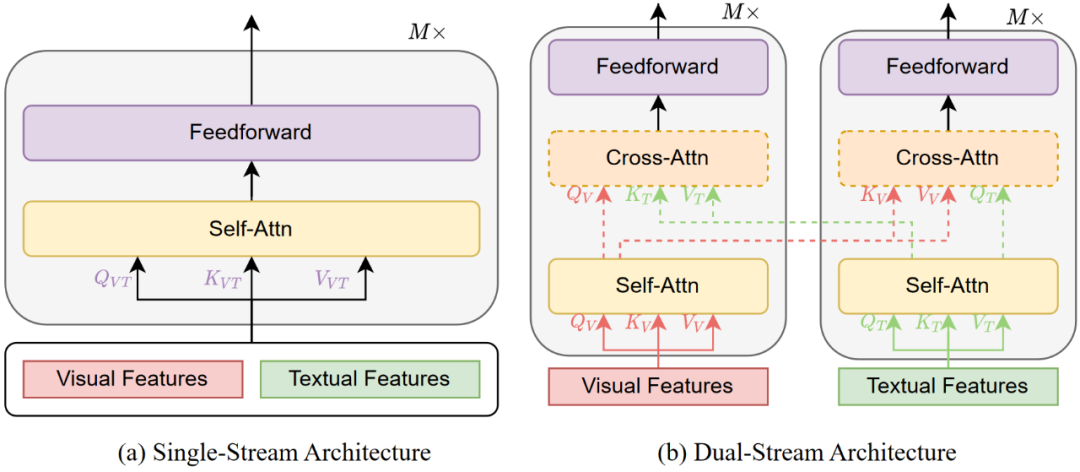
圖 5:多模態(tài)融合圖示
僅編碼器 vs. 編碼器-解碼器
大多數(shù) VLP 模型僅包含編碼器,其中跨模態(tài)表示直接輸入到基于 MLP 的輸出層來生成最終輸出。這種設計自然適合 VL 理解任務,例如 VQA 和視覺推理。當用于圖像描述時,結構類似的編碼器充當解碼器,通過使用因果掩碼逐個標記地生成輸出圖像描述文本。
最近,受到 NLP 領域中 T5 和 BART 的啟發(fā),VL-T5SimVLMOFA 等提出使用基于 Transformer 的編碼器-解碼器架構,其中跨模態(tài)表示首先被送入解碼器,然后送入輸出層。在這些模型中,解碼器同時關注編碼器表示和先前生成的標記,以自回歸地方式產(chǎn)生輸出。使用編碼器-解碼器架構可以實現(xiàn)各種圖像-文本任務的統(tǒng)一和 VLP 模型的零樣本/少樣本學習,并且也很自然地適合生成類的任務。圖 6 展示了僅編碼器和編碼器-解碼器架構之間的說明性比較。
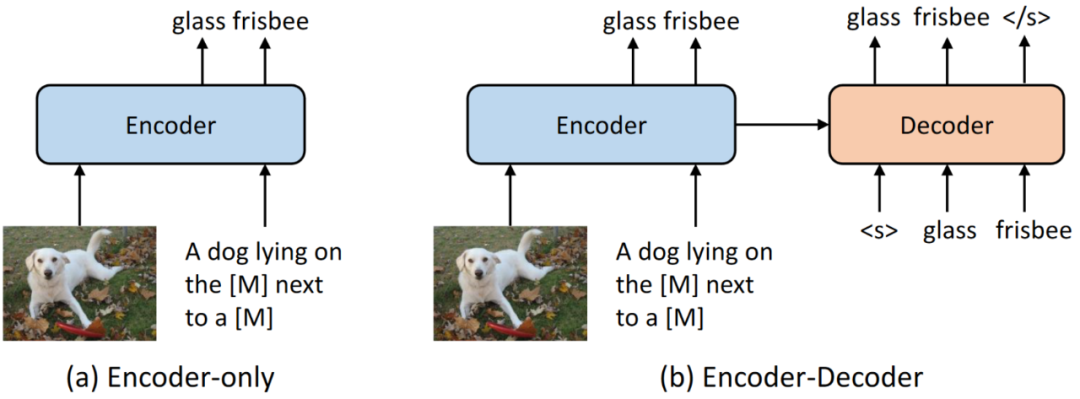
圖 6:僅編碼器 vs. 編碼器-解碼器
預訓練目標
預訓練目標指導模型如何學習視覺-語言的關聯(lián)信息。歷史工作中的主流預訓練目標主要可以分為三大類:Masked Language Modeling (MLM)、Masked Vision Modeling (MVM) 和 Vision-Language Matching (VLM)。
Masked Language Modeling
MLM 源自于 NLP 領域,由于 BERT 將其改編為一種新穎的預訓練任務而廣為人知。為了以視覺信息為條件對語言進行建模,VLP 模型中的 MLM 與預訓練語言模型中的 MLM 類似,但它不僅通過剩下的未遮蔽文本標記,而且還通過視覺標記來預測被遮蔽的文本標記。
根據(jù)經(jīng)驗,遵循 BERT 的 VLP 模型以 15% 的概率隨機遮蔽每個文本輸入標記,并在遮蔽的過程中 80% 的時間里使用特殊標記 [MASK] 替換被遮蔽的標記,10% 的時間使用隨機文本標記,還有 10% 的時間使用原始標記來進行遮蔽操作。其公式定義如下:
其中, 表示視覺輸入, 表示文本標記, 表示未遮蔽文本標記, 表示訓練數(shù)據(jù)集。
Masked Vision Modeling
與 MLM 類似,MVM 它對視覺區(qū)域或圖像塊進行采樣,通常以 15% 的概率遮蔽它們的視覺特征。VLP 模型需要在給定剩余的視覺特征和所有文本特征的情況下重建被遮蔽的視覺特征,其中被遮蔽的視覺特征設置為零。例如 LXMERT 和 UNITER 中,遮蔽了一些輸入?yún)^(qū)域,并且訓練模型來回歸預測原始區(qū)域特征。
形式上,給定一個視覺特征序列 v =〈v1,· · ·,vM〉,其中 vi 一般是區(qū)域特征表示。在隨機遮蔽一些區(qū)域特征后,模型通過剩下的視覺特征和未遮蔽的標記 t 輸出重構的視覺特征 ov,其回損失函數(shù)旨在最小化均方誤差損失。部分研究工作還嘗試先使用預訓練的對象檢測器為每個區(qū)域生成對象標簽,該對象檢測器可以包含高級的語義信息,并且訓練該模型來預測遮蔽區(qū)域的對象標簽,而不是原來的區(qū)域特征。
由于視覺特征是高維和連續(xù)的,VLP 模型為 MVM 提出了兩種變體:Masked Features Regression (MFR) 和 Masked Feature Classification (MFC)。
MFR 學習將掩碼特征的模型輸出回歸至其原始視覺特征。VLP 模型首先將掩碼特征的模型輸出轉(zhuǎn)換為與原始視覺特征相同維度的向量,并在原始視覺特征和該向量之間應用 L2 回歸。MRC 學習預測掩碼特征的對象語義類別。VLP 模型首先將掩碼特征的輸出輸入到 FC 層來預測對象類別的分數(shù),然后通過 softmax 函數(shù)將其轉(zhuǎn)換為歸一化分布。
注意這里沒有真實標簽。有兩種訓練 VLP 模型的方法,一種是 VLP 模型將對象檢測模型中最有可能的對象類作為硬標簽,假設檢測到的對象類是掩碼特征的真實標簽,并應用交叉熵損失來最小化預測結果和偽標簽之間的差距。另一個是 VLP 模型利用軟標簽作為監(jiān)督信號,它是檢測器的原始輸出(即對象類別的分布),并最小化兩個分布之間的 KL 散度。
Vision-Language Matching
VLM 是最常用的視覺和文本對齊的預訓練目標,旨在將視覺和文本投射到同一個表示空間中。在單流 VLP 模型中,它們使用特殊標記 [CLS] 的表示作為兩種模式的融合表示。在雙流 VLP 模型中,他們將表征視覺信息的特殊視覺標記 [CLSV] 和表征文本信息的特殊文本標記 [CLST] 拼接起來,作為兩種模態(tài)輸入的融合表示。
VLP 模型將兩種模態(tài)輸入的融合表示提供給 FC 層和 sigmoid 函數(shù)來預測 0 到 1 之間的分數(shù),其中 0 表示視覺和文本不匹配,1 則反之。在訓練過程中,VLP 模型在每一步都從數(shù)據(jù)集中采樣正負對,其中負樣本對是通過用從其它樣本中隨機選擇的樣本替換配對樣本中的視覺或文本數(shù)據(jù)來創(chuàng)建的。
值得一提的是,在視覺和文本對齊任務中,基于對比學習的預訓練目標也經(jīng)常被用到,例如 Image-Text Contrastive Learning (ITC)。與 VLM 不同,ITC 在給定一個批次大小為 N 的視覺-文本對的情況下,從 N × N 個構造的視覺-文本對中預測真實匹配的視覺-文本對。在一個訓練批次中有 N2 ? N 個視覺-語言對負樣本。
VLP 模型使用特殊視覺標記 [CLSV] 和特殊文本標記 [CLST] 來聚合視覺和語言表示。VLP 模型計算通過 softmax 歸一化的視覺-文本相似度和文本-視覺相似度,并利用視覺-文本和文本-視覺相似度的交叉熵損失來更新自身。相似度計算一般通過由點積運算來得到。其公式定義如下:
其中,. 表示圖像和文本, 表示相似度計算函數(shù), 是溫度系數(shù)。
下游任務目標
為了更好地適應下游任務,VLP 模型有時會使用一些下游任務的訓練目標,例如視覺問答(VQA)和視覺描述(VC),作為預訓練目標。對于 VQA,VLP 模型采用上述融合表示,應用 FC 層,并使用轉(zhuǎn)換后的表示來預測預定義的候選答案的類別。除此之外,VLP 模型還可以直接生成原始文本格式的答案。對于 VC,為了賦予 VLP 模型生成的能力來重構輸入語句,VLP 模型使用自回歸解碼器來生成圖像或視頻的相應文本描述。由于篇幅限制,這里只介紹一些流行的預訓練目標。
數(shù)據(jù)集
預訓練數(shù)據(jù)集對于 VLP 模型至關重要。預訓練數(shù)據(jù)集的質(zhì)量和大小有時會超過訓練策略和算法的重要性。由于 VLP 包括圖像-語言預訓練和視頻-語言預訓練,可以大致將預訓練數(shù)據(jù)集分為兩大類。在大多數(shù)工作中,VLP 的預訓練數(shù)據(jù)集是通過組合多模態(tài)任務或跨場景的公共數(shù)據(jù)集來構建的。
然而,也有一些工作如 ALIGN 和 CLIP,使用自建數(shù)據(jù)集進行預訓練。這些自建數(shù)據(jù)集通常比大多數(shù)公共數(shù)據(jù)集大,但包含的噪聲可能也更多。表 1 展示了一些主流 VLP 預訓練數(shù)據(jù)集的統(tǒng)計數(shù)據(jù)。
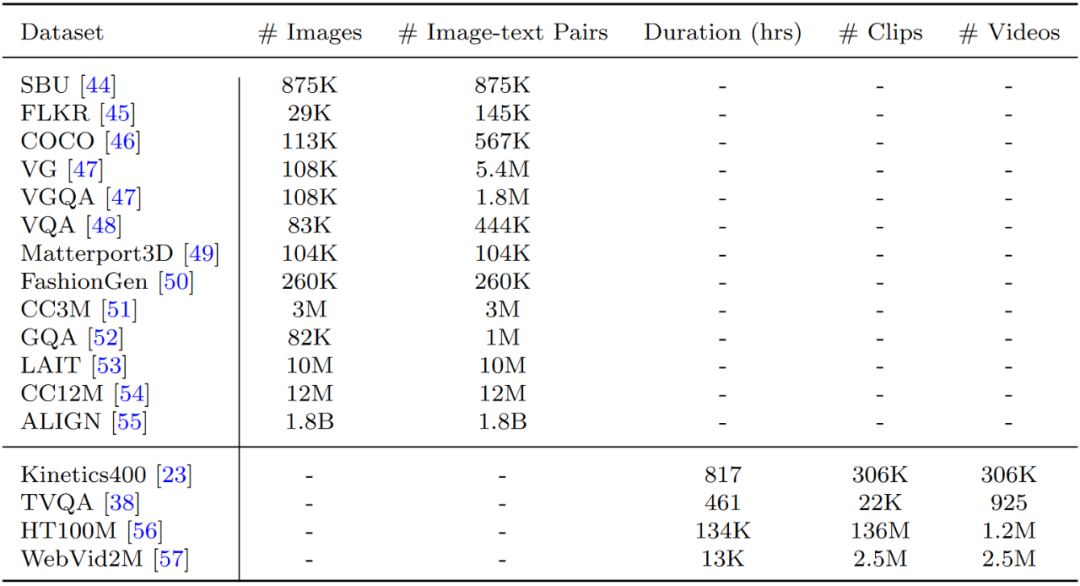
表 1:VLP 數(shù)據(jù)集
圖像-文本數(shù)據(jù)集
對于圖像-語言預訓練,使用最廣泛的數(shù)據(jù)形式是圖像-文本對。大多數(shù)圖像-語言預訓練數(shù)據(jù)集由大量的圖像-文本對組成。SBU 和Flickr30k 從 Flickr 收集而來,并進行人工標注。COCO 由帶有五個人工生成標題的圖像組成,并通過特殊程序進行過濾來保證圖像和標注的質(zhì)量。
CC3M 和 CC12M 是通過從互聯(lián)網(wǎng)抓取圖像及其 HTML 屬性中的 alt 標簽,并使用經(jīng)過濾的描述文本來標注這些圖片而構建的。由于過濾策略相對寬松,CC12M 比 CC3M 包含更多的噪聲。另一個數(shù)據(jù)源是視覺問答任務 (VQA)。許多圖像-語言數(shù)據(jù)集在 VQA 的上下文中被組織成結構化數(shù)據(jù)。
代表性的大規(guī)模數(shù)據(jù)集是 VG。VG 以其結構化數(shù)據(jù)形式包含豐富的信息。在圖像-語言預訓練研究中,其區(qū)域級描述和問答對被廣泛使用。除了 VG 之外,VQA 和 GQA 也是流行的視覺問答對數(shù)據(jù)集。與 VGA 相比,GQA 進一步減輕了系統(tǒng)性偏差。
上述數(shù)據(jù)集適用于大多數(shù)常見場景。還有一些數(shù)據(jù)集是為特殊場景設計的。例如,Matterport3D 由建筑規(guī)模場景的 RGB-D 圖像組成,并標注了分類和分割標簽。Fashion-Gen 包含由專業(yè)設計師生成的帶有物品描述的時尚圖片。
視頻-文本數(shù)據(jù)集
與圖像-語言預訓練數(shù)據(jù)集相比,視頻-語言預訓練數(shù)據(jù)集通常更耗時,且更難收集和處理。這些不便也制約了該領域發(fā)展和預訓練的規(guī)模。用于視頻-語言預訓練的數(shù)據(jù)集涵蓋不同的場景和來源。其中大多數(shù)數(shù)據(jù)集,例如 Kinetics-400、HowTo100M、WebVid-2M 都是從網(wǎng)上收集的,并采用了不同的處理流程。這些類型的視頻通常伴隨有字幕信息,從而在視頻片段和文本之間提供了或弱或強的對齊關系。
盡管這些字幕有時可能太弱而無法對齊,但它們?nèi)匀惶峁┝擞杏玫男畔ⅲ貏e是對于大規(guī)模數(shù)據(jù)集上的預訓練。視頻-文本對的另一個來源是電視節(jié)目。TVQA 是從電視節(jié)目生成的視頻-語言預訓練數(shù)據(jù)集。這些電視節(jié)目被收集并轉(zhuǎn)換成包括許多對話的數(shù)據(jù)集,用于理解視頻和識別視頻中的語義概念。
考慮到這些數(shù)據(jù)集的來源和形成的多樣性,研究人員應用了不同的標注和處理程序。例如,Kinetics-400 包含許多帶有動作類標注的動作相關視頻。對于其它的一些數(shù)據(jù)集,視頻剪輯的附帶描述/字幕或視頻中的概念類別通常被處理并用作標注信息。
VLP 模型
19年提出的 VisualBERT 被稱為第一個圖像-文本預訓練模型,它使用 Faster R-CNN 提取視覺特征,并將視覺特征和文本嵌入拼接起來,然后輸入到單個由 BERT 初始化的 transformer 中。后續(xù)許多 VLP 模型在調(diào)整預訓練目標和預訓練數(shù)據(jù)集時遵循與 VisualBERT 相似的特征提取方式和架構設計。
最近,VLMo 將圖像的塊嵌入和文本的詞嵌入進行拼接組合,輸入到混合模態(tài)專家的 transformer (MoME) 中。METER 則探索了如何使用單模態(tài)的預訓練模型,并提出一種雙流架構模型來處理多模態(tài)融合的問題。
表 2 介紹了一些目前具有代表性的 VLP 模型,并且對這些模型各個模塊的配置進行了匯總。
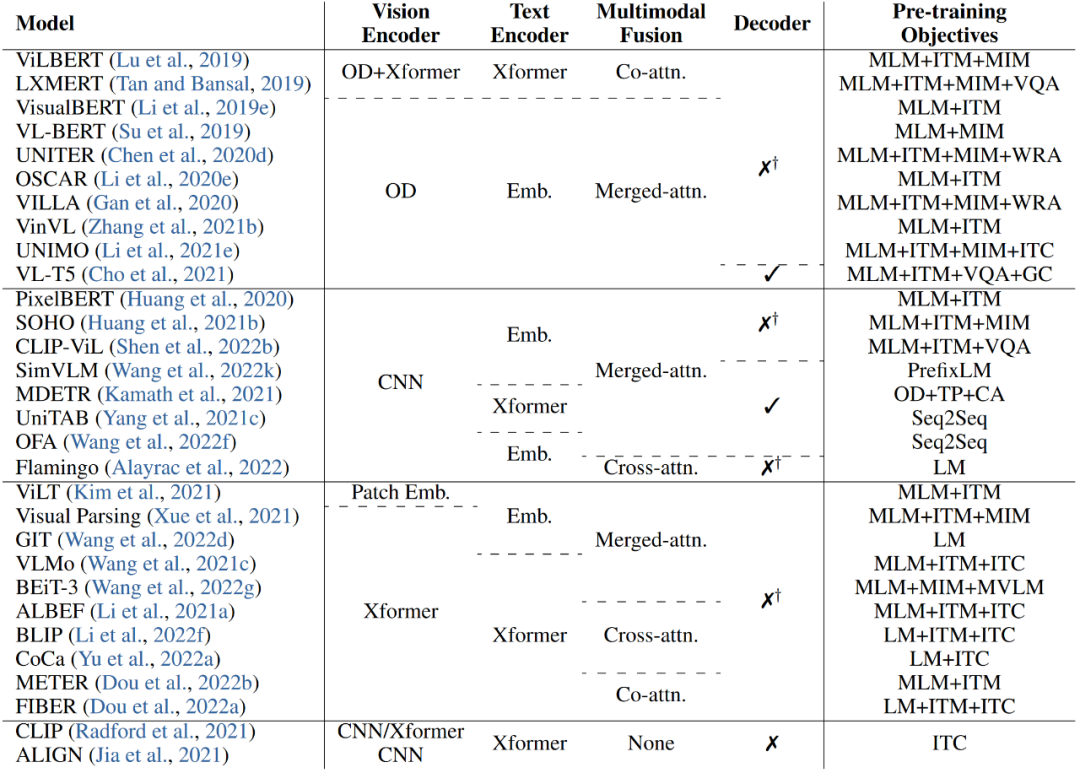
表 2:主流 VLP 模型
(OD: object detector. Xformer: transformer. Emb.: embedding. WRA: word-region alginment. TP: token prediction. CA:contrastive alignment. GC: grounding+captioning.)
小結
在本篇文章中,筆者通過整理多篇研究綜述,從多個方面梳理了視覺-語言訓練的技術路線:任務描述、模型結構、預訓練目標以及預訓練數(shù)據(jù)集等,旨在幫助對該領域有興趣的小伙伴快速入門。隨著 VLP 研究的發(fā)展,還涌現(xiàn)出許多其它有趣的研究課題,例如大模型、小樣本學習、統(tǒng)一建模、魯棒性評估等。后續(xù),筆者將會進一步探討這些更高層次的研究課題。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3639瀏覽量
134439 -
J-BERT
+關注
關注
0文章
5瀏覽量
7795 -
PLM
+關注
關注
2文章
121瀏覽量
20863 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45982
原文標題:多模態(tài) | 視覺-語言預訓練入門指南
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的預訓練
新的預訓練方法——MASS!MASS預訓練幾大優(yōu)勢!

預訓練語言模型設計的理論化認識

基于預訓練視覺-語言模型的跨模態(tài)Prompt-Tuning

Multilingual多語言預訓練語言模型的套路
一種基于亂序語言模型的預訓練模型-PERT
利用視覺語言模型對檢測器進行預訓練
CogBERT:腦認知指導的預訓練語言模型
利用視覺+語言數(shù)據(jù)增強視覺特征
多維度剖析視覺-語言訓練的技術路線
基礎模型自監(jiān)督預訓練的數(shù)據(jù)之謎:大量數(shù)據(jù)究竟是福還是禍?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論