 英偉達耗費64個A100訓練StyleGAN-T!
英偉達耗費64個A100訓練StyleGAN-T!
擴散模型在文本到圖像生成方面是最好的嗎?不見得,英偉達等機構推出的新款 StyleGAN-T,結果表明 GAN 仍具有競爭力。
文本合成圖像任務是指,基于文本內容生成圖像內容。當下這項任務取得的巨大進展得益于兩項重要的突破:其一,使用大的預訓練語言模型作為文本的編碼器,讓使用通用語言理解實現生成模型成為可能。其二,使用由數億的圖像 - 文本對組成的大規模訓練數據,只要你想到的,模型都可以合成。
訓練數據集的大小和覆蓋范圍持續飛速擴大。因此,文本生成圖像任務的模型必須擴展成為大容量模型,以適應訓練數據的增加。最近在大規模文本到圖像生成方面,擴散模型(DM)和自回歸模型(ARM)催生出了巨大的進展,這些模型似乎內置了處理大規模數據的屬性,同時還能處理高度多模態數據的能力。
有趣的是,2014 年,由 Goodfellow 等人提出的生成對抗網絡(GAN),在生成任務中并沒有大放異彩,正當大家以為 GAN 在生成方面已經不行的時候,來自英偉達等機構的研究者卻試圖表明 GAN 仍然具有競爭力,提出 StyleGAN-T 模型。

StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
論文地址:https://arxiv.org/abs/2301.09515
論文主頁:https://sites.google.com/view/stylegan-t/
StyleGAN-T 只需 0.1 秒即可生成 512×512 分辨率圖像:
?

?
StyleGAN-T 生成宇航員圖像:

?
值得一提的是,谷歌大腦研究科學家 Ben Poole 表示:StyleGAN-T 在低分辨率 (64x64) 時生成的樣本比擴散模型更快更好,但在高分辨率 (256x256) 時表現不佳。
研究者們表示,他們在 64 臺 NVIDIA A100 上進行了 4 周的訓練。有人給這項研究算了一筆賬,表示:StyleGAN-T 在 64 塊 A100 GPU 上訓練 28 天,根據定價約為 473000 美元,這大約是典型擴散模型成本的四分之一……
GAN 提供的主要好處在于推理速度以及可以通過隱空間控制合成的結果。StyleGAN 的特別之處在于,其具有一個精心設計的隱空間,能從根本上把控生成的圖像結果。而對于擴散模型來說,盡管有些工作在其加速方面取得了顯著進展,但速度仍然遠遠落后于僅需要一次前向傳播的 GAN。
本文從觀察到 GAN 在 ImageNet 合成中同樣落后于擴散模型中得到啟發,接著受益于 StyleGAN-XL 對判別器的架構進行了重構,使得 GAN 和擴散模型的差距逐漸縮小。在原文的第 3 節中,考慮到大規模文本生成圖像任務的特定要求:數量多、類別多的數據集、強大的文本對齊以及需要在變化與文本對齊間進行權衡,研究者以 StyleGAN-XL 作為開始,重新審視了生成器和判別器的架構。
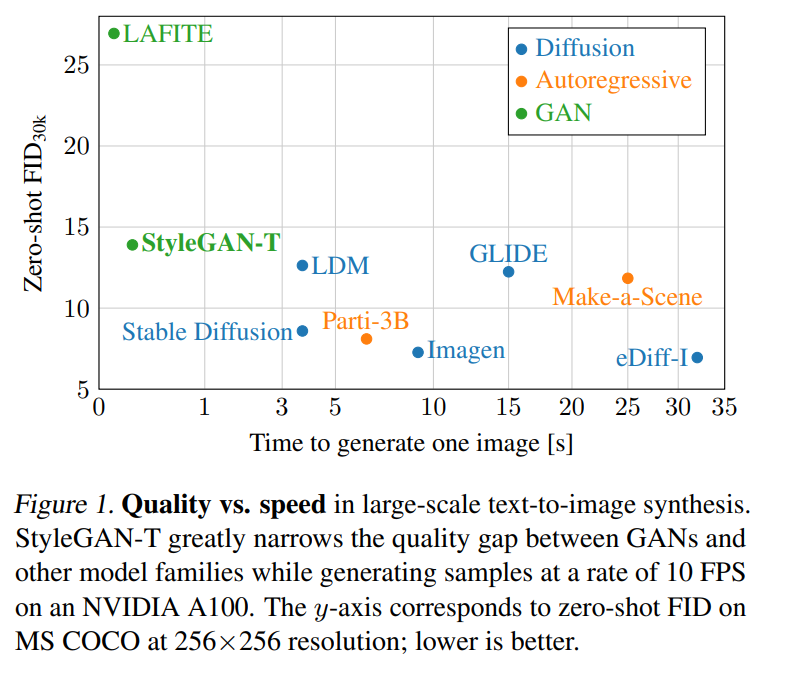
在 MS COCO 上的零樣本任務中,StyleGAN-T 以 64×64 的分辨率實現了比當前 SOTA 擴散模型更高的 FID 分數。在 256×256 分辨率下,StyleGAN-T 更是達到之前由 GAN 實現的零樣本 FID 分數的一半,不過還是落后于 SOTA 的擴散模型。StyleGAN-T 的主要優點包括其快速的推理速度和在文本合成圖像任務的上下文中進行隱空間平滑插值,分別如圖 1 和圖 2 所示。

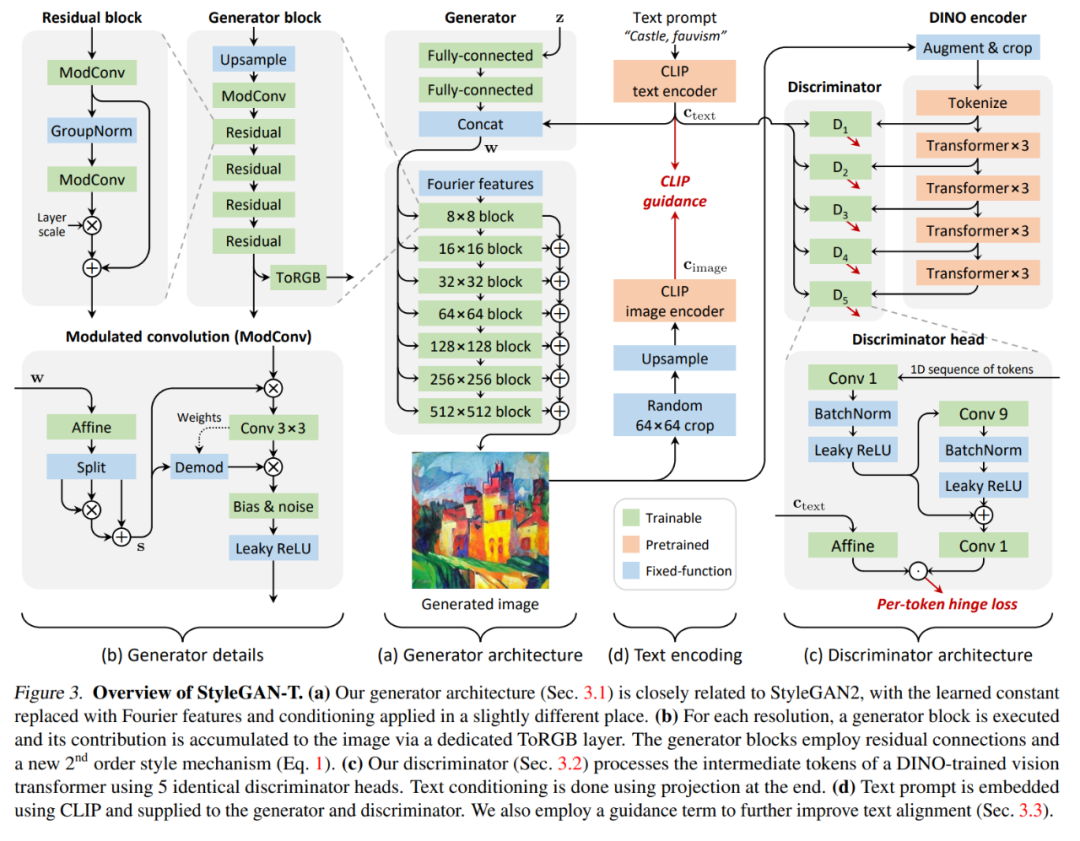
StyleGAN-T 架構概覽
該研究選擇 StyleGAN-XL 作為基線架構,因為 StyleGAN-XL 在以類別為條件的 ImageNet 合成任務中表現出色。然后該研究依次從生成器、判別器和變長與文本對齊的權衡機制的角度修改 StyleGAN-XL。
在整個重新設計過程中,作者使用零樣本 MS COCO 來衡量改動的效果。出于實際原因,與原文第 4 節中的大規模實驗相比,測試步驟的計算資源預算有限,該研究使用了更小模型和更小的數據集;詳見原文附錄 A。除此以外,該研究使用 FID 分數來量化樣本質量,并使用 CLIP 評分來量化文本對齊質量。
為了在基線模型中將以類別為引導條件更改為以文本為引導條件,作者使用預訓練的 CLIP ViT-L/14 文本編碼器來嵌入文本提示,以此來代替類別嵌入。接著,作者刪除了用于引導生成的分類器。這種簡單的引導機制與早期的文本到圖像模型相匹配。如表 1 所示,該基線方法在輕量級訓練配置中達到了 51.88 的零樣本 FID 和 5.58 的 CLIP 分數。值得注意的是,作者使用不同的 CLIP 模型來調節生成器和計算 CLIP 分數,這降低了人為夸大結果的風險。
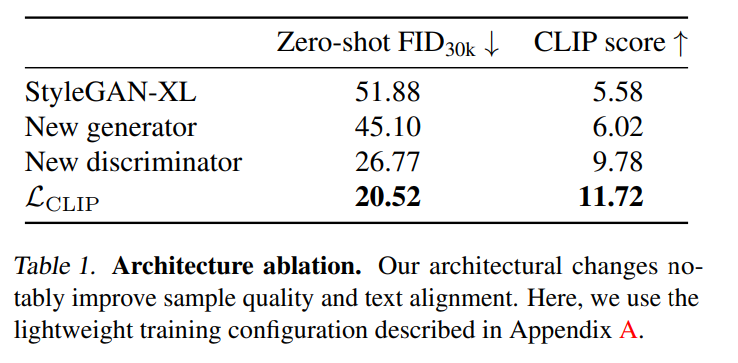
實驗結果
該研究使用零樣本 MS COCO 在表 2 中的 64×64 像素輸出分辨率和表 3 中的 256×256 像素輸出分辨率下定量比較 StyleGAN-T 的性能與 SOTA 方法的性能。
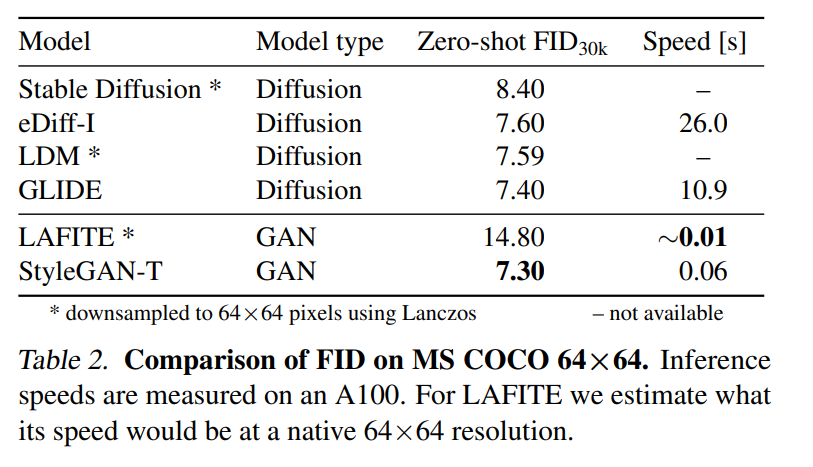
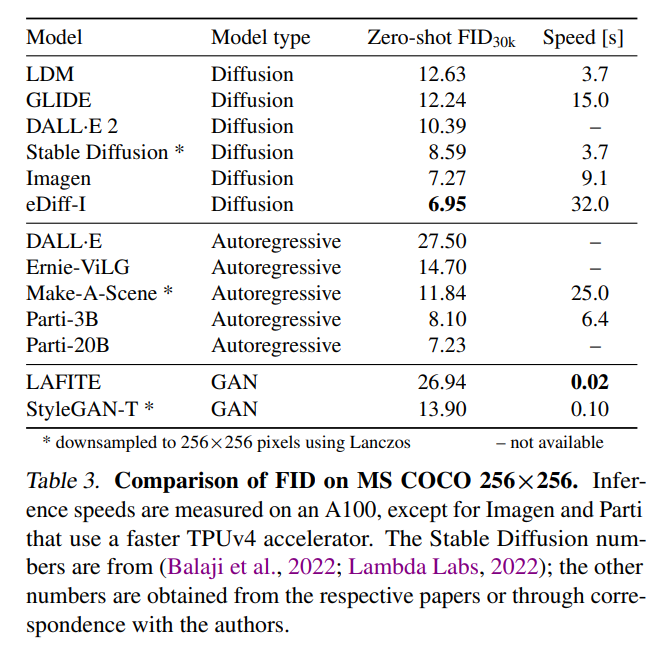
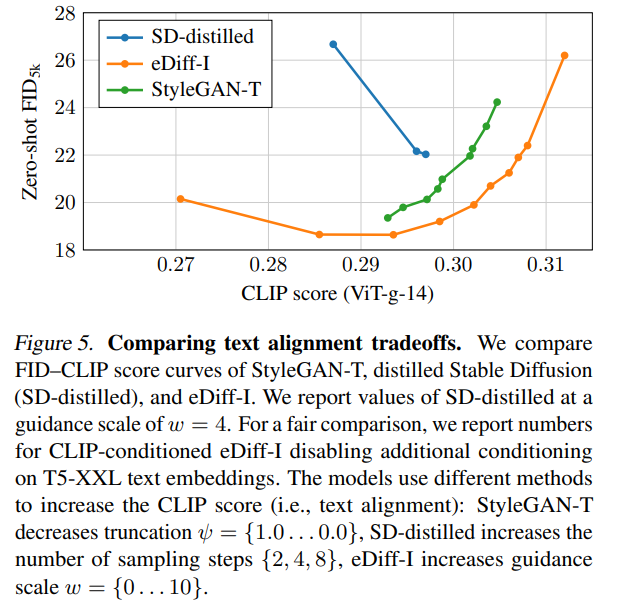
圖 5 展示了 FID-CLIP 評分曲線:
為了隔離文本編碼器訓練過程產生的影響,該研究評估了圖 6 中的 FID–CLIP 得分曲線。
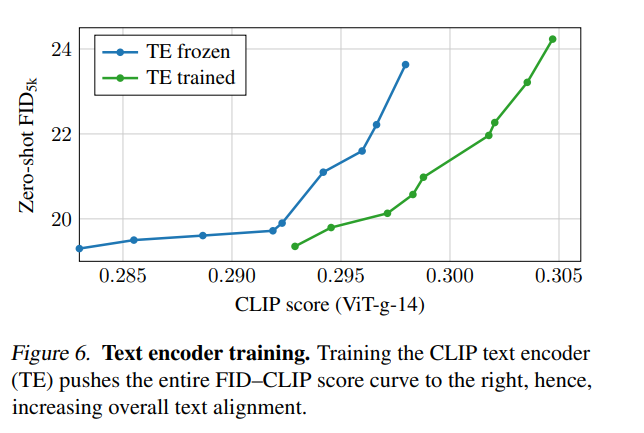
圖 2 顯示了 StyleGAN-T 生成的示例圖像,以及它們之間的插值。
在不同的文本提示之間進行插值非常簡單。對于由中間變量 w_0 = [f (z), c_text0] 生成的圖像,該研究用新的文本條件 c_text1 替換文本條件 c_text0。然后將 w_0 插入到新的隱變量 w_1 = [f (z), c_text1] 中,如圖 7 所示。

通過向文本提示附加不同的樣式,StyleGAN-T 可以生成多種樣式,如圖 8 所示。

審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3648瀏覽量
134731 -
語言模型
+關注
關注
0文章
528瀏覽量
10292 -
英偉達
+關注
關注
22文章
3788瀏覽量
91290
原文標題:GAN強勢歸來?英偉達耗費64個A100訓練StyleGAN-T!僅為擴散模型成本的四分之一
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論