 一文淺談Graph Transformer領域近期研究進展
一文淺談Graph Transformer領域近期研究進展
在圖表示學習中,Graph Transformer 通過位置編碼對圖結構信息進行編碼,相比 GNN,可以捕獲長距離依賴,減輕過平滑現象。本文介紹 Graph Transformer 的兩篇近期工作。
SAT

論文標題:Structure-Aware Transformer for Graph Representation Learning收錄會議:ICML 2022
論文鏈接:
https://arxiv.org/abs/2202.03036
代碼鏈接:
https://github.com/BorgwardtLab/SAT
本文分析了 Transformer 的位置編碼,認為使用位置編碼的 Transformer 生成的節點表示不一定捕獲它們之間的結構相似性。為了解決這個問題,提出了結構感知 Transformer,通過設計新的自注意機制,使其能夠捕獲到結構信息。新的注意力機制通過在計算注意力得分之前,提取每個節點的子圖表示,并將結構信息合并到原始的自注意機制中。
本文提出了幾種自動生成子圖表示的方法,并從理論上表明,生成的表示至少與子圖表示具有相同的表達能力。該方法在五個圖預測基準上達到了最先進的性能,可以利用任何現有的 GNN 來提取子圖表示。它系統地提高了相對于基本 GNN 模型的性能,成功地結合了 GNN 和 Transformer。
1.1 方法
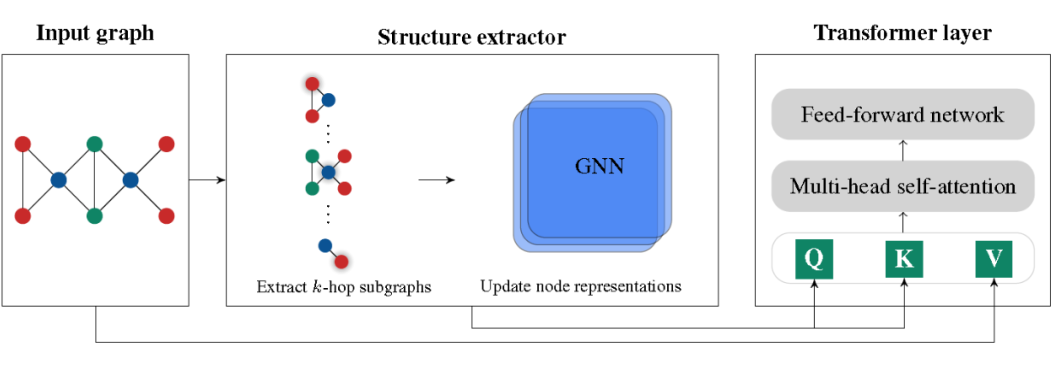
本文提出了一個將圖結構編碼到注意力機制中的模型。首先,通過 Structure extractor 抽取節點的子圖結構,進行子圖結構的注意力計算。其次,遵循 Transformer 的結構進行計算。
Structure-Aware Self-Attention
Transformer 原始結構的注意力機制可以被重寫為一個核平滑器:
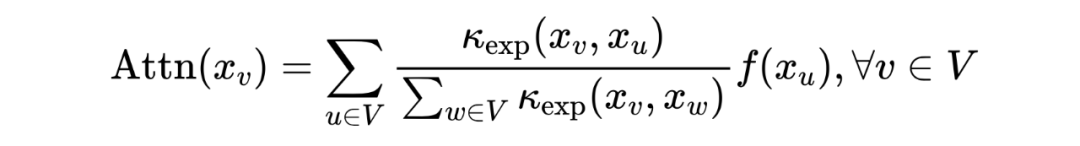
其中, 是一個線性函數。 是 空間中,由 和 參數化的(非對稱)指數核:
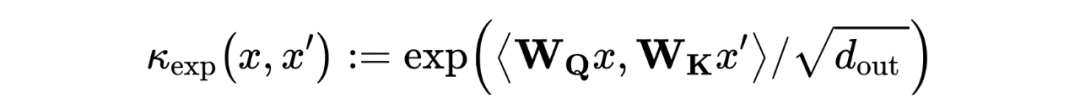
是定義在節點特征上的可訓練指數核函數,這就帶來了一個問題:當節點特征相似時,結構信息無法被識別并編碼。為了同時考慮節點之間的結構相似性,我們考慮了一個更一般化的核函數,額外考慮了每個節點周圍的局部子結構。通過引入以每個節點為中心的一組子圖,定義結構感知注意力如下:
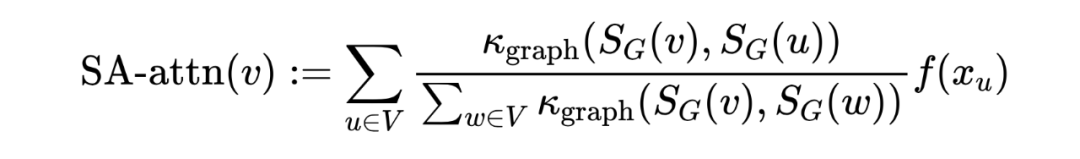
其中, 是節點 在圖 中的子圖,與節點特征 相關, 是可以是任意比較一對子圖的核函數。該自注意函數不僅考慮了節點特征的相似度,而且考慮了子圖之間的結構相似度。因此,它生成了比原始的自我關注更有表現力的節點表示。定義如下形式的 :
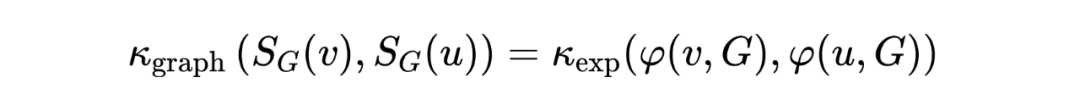
其中 是一個結構提取器,它提取以 為中心、具有節點特征 的子圖的向量表示。結構感知自我注意力十分靈活,可以與任何生成子圖表示的模型結合,包括 GNN 和圖核函數。在自注意計算中并不考慮邊緣屬性,而是將其合并到結構感知節點表示中。文章提出兩種生成子圖的方法:k-subtree GNN extractor 和 k-subgraph GNN extractor,并進行相關實驗。
1.2 實驗
下圖是模型在圖回歸和圖分類任務上的效果。
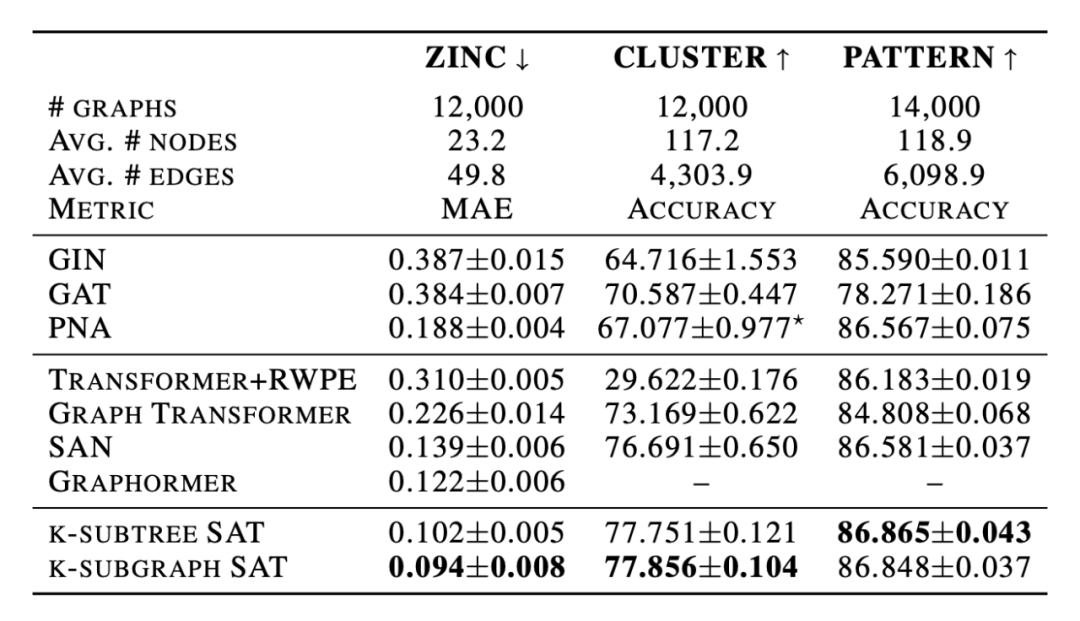
使用 GNN 抽取結構信息后,再用 Transformer 學習特征,由下圖可以看出,Transformer 可以增強 GNN 的性能。
GraphGPS

論文標題:Recipe for a General, Powerful, Scalable Graph Transformer收錄會議:NeurIPS 2022
論文鏈接:
https://arxiv.org/abs/2205.12454
代碼鏈接:
https://github.com/rampasek/GraphGPS 本文首先總結了不同類型的編碼,并對其進行了更清晰的定義,將其分為局部編碼、全局編碼和相對編碼。其次,提出了模塊化框架 GraphGPS,支持多種類型的編碼,在小圖和大圖中提供效率和可伸縮性。框架由位置/結構編碼、局部消息傳遞機制、全局注意機制三個部分組成。該架構在所有基準測試中顯示了極具競爭力的結果,展示了模塊化和不同策略組合所獲得的經驗好處。
2.1 方法
在相關工作中,位置/結構編碼是影響 Graph Transformer 性能的最重要因素之一。因此,更好地理解和組織位置/結構編碼將有助于構建更加模塊化的體系結構,并指導未來的研究。本文將位置/結構編碼分成三類:局部編碼、全局編碼和相對編碼。各類編碼的含義和示例如下表所示。 現有的 MPNN + Transformer 混合模型往往是 MPNN 層和 Transformer 層逐層堆疊,由于 MPNN 固有結構帶來的過平滑問題,導致這樣的混合模型的性能也會受到影響。因此,本文提出新的混合架構,使 MPNN 和 Transformer 的計算相互獨立,獲得更好的性能。具體框架如圖所示。
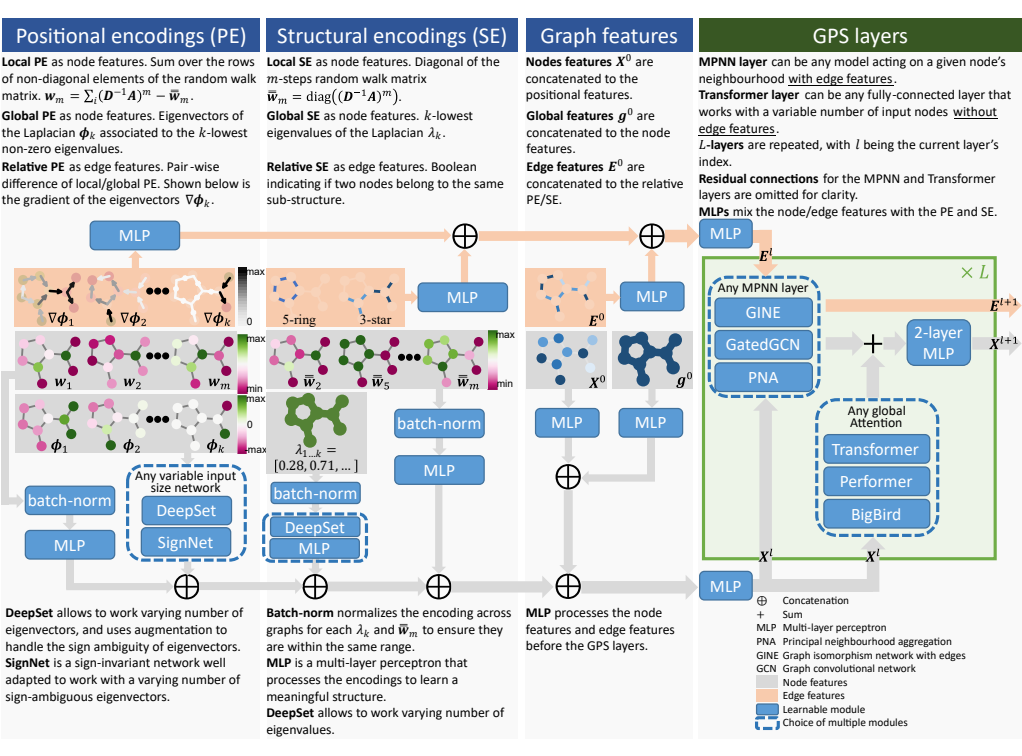
框架主要由位置/結構編碼、局部消息傳遞機制(MPNN)、全局注意機制(Self Attention)三部分組成。根據不同的需求設計位置/結構編碼,與輸入特征相加,然后分別輸入到 MPNN 和 Transformer 模型中進行訓練,再對兩個模型的結果相加,最后經過一個 2 層 MLP 將輸出結果更好的融合,得到最終的輸出。更新公式如下:
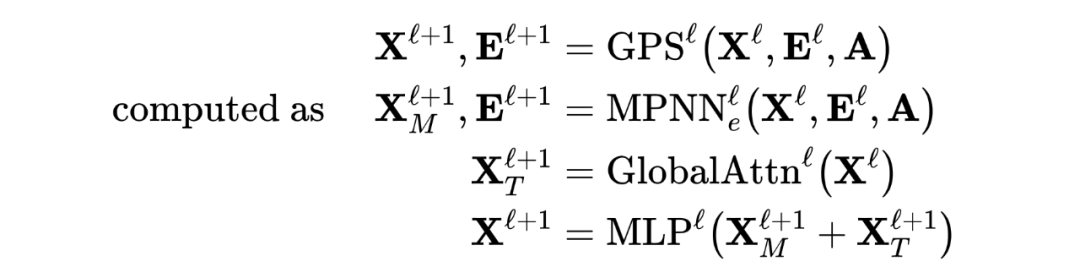
2.2 實驗
在圖級別的任務上,效果超越主流方法:
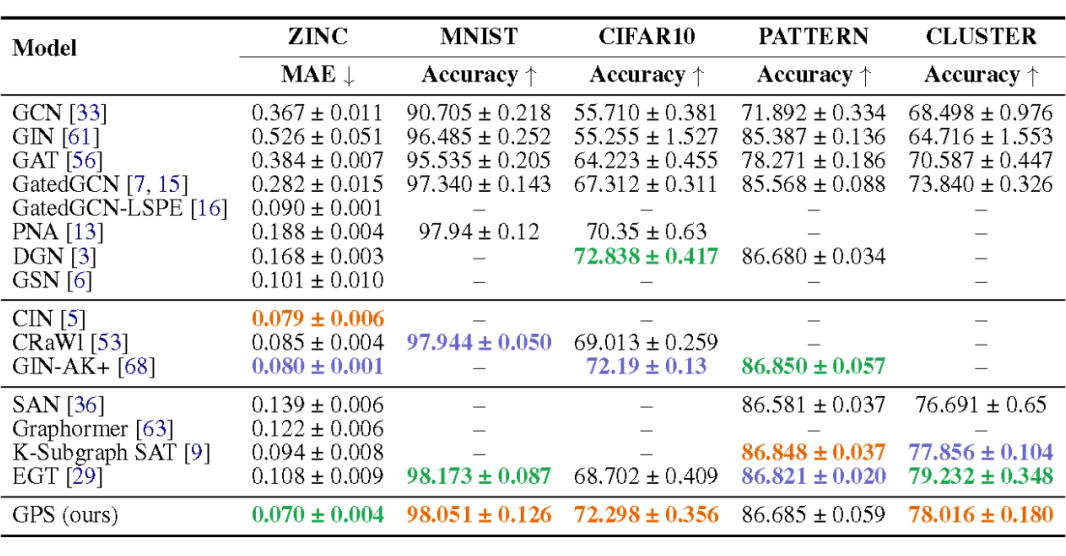
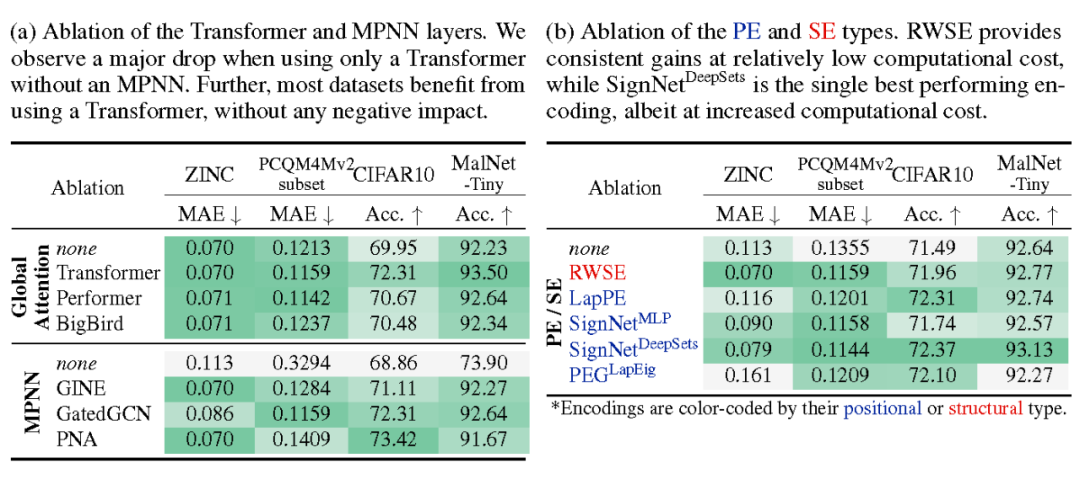
通過消融實驗,研究框架中各個結構的作用,可以看到,MPNN 和位置/結構編碼模塊對 Transformer 的效果均有提升作用。
總結
兩篇文章都有一個共同特點,就是采用了 GNN + Transformer 混合的模型設計,結合二者的優勢,以不同的方式對兩種模型進行融合,GNN 學習到圖結構信息,然后在 Transformer 的計算中起到提供結構信息的作用。在未來的研究工作中,如何設計更加合理的模型,也是一個值得探討的問題。
審核編輯 :李倩
-
編碼
+關注
關注
6文章
942瀏覽量
54823 -
Graph
+關注
關注
0文章
36瀏覽量
9082 -
線性函數
+關注
關注
0文章
3瀏覽量
1257
原文標題:一文淺談Graph Transformer領域近期研究進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論