

案發現場
昨天晚上突然短信收到 APM (即 Application Performance Management 的簡稱,我們內部自己搭建了這樣一套系統來對應用的性能、可靠性進行線上的監控和預警的一種機制)大量告警畫外音: 監控是一種非常重要的發現問題的手段,沒有的話一定要及時建立哦
緊接著運維打來電話告知線上部署的四臺機器全部 OOM (out of memory, 內存不足),服務全部不可用,趕緊查看問題!
問題排查
首先運維先重啟了機器,保證線上服務可用,然后再仔細地看了下線上的日志,確實是因為 OOM 導致服務不可用

第一時間想到 dump 當時的內存狀態,但由于為了讓線上盡快恢復服務,運維重啟了機器,導致無法 dump 出事發時的內存。所以我又看了下我們 APM 中對 JVM 的監控圖表
畫外音:一種方式不行,嘗試另外的角度切入!再次強調,監控非常重要!完善的監控能還原當時的事發現場,方便定位問題。
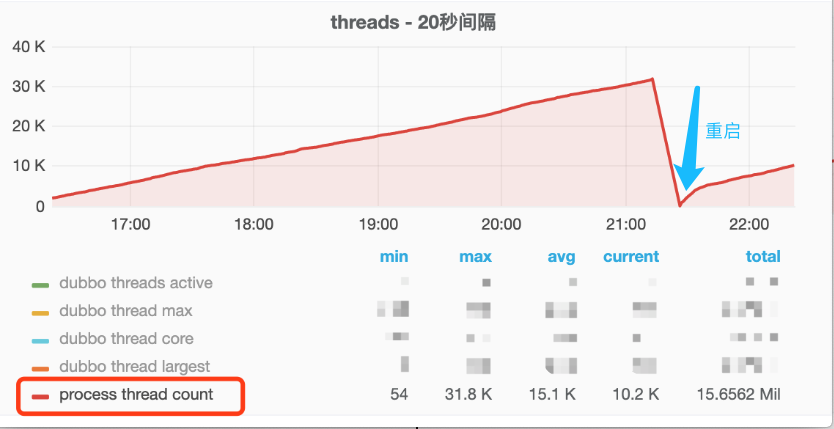
不看不知道,一看嚇一跳,從 16:00 開始應用中創建的線程居然每時每刻都在上升,一直到 3w 左右,重啟后(藍色箭頭),線程也一直在不斷增長),正常情況下的線程數是多少呢,600!問題找到了,應該是在下午 16:00 左右發了一段有問題的代碼,導致線程一直在創建,且創建的線程一直未消亡!查看發布記錄,發現發布記錄只有這么一段可疑的代碼 diff:在 HttpClient 初始化的時候額外加了一個evictExpiredConnections配置

問題定位了,應該是就是這個配置導致的!(線程上升的時間點和發布時間點完全吻合!),于是先把這個新加的配置給干掉上線,上線之后線程數果然恢復正常了。那evictExpiredConnections做了什么導致線程數每時每刻在上升呢?這個配置又是為了解決什么問題而加上的呢?于是找到了相關同事來了解加這個配置的前因后果
還原事發經過
最近線上出現不少NoHttpResponseException的異常, 而上面那個配置就是為了解決這個異常而添加的,那是什么導致了這個異常呢?
在說這個問題之前我們得先了解一下 http 的 keep-alive 機制。
先看下正常的一個 TCP 連接的生命周期
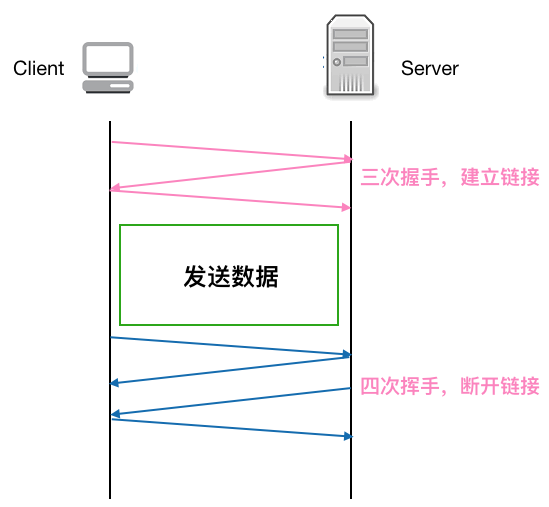
可以看到每個 TCP 連接都要經過三次握手建立連接后才能發送數據,要經過四次揮手才能斷開連接,如果每個 TCP 連接在 server 返回 response 后都立馬斷開,則發起多個 HTTP 請求就要多次創建斷開 TCP, 這在Http 請求很多的情況下無疑是很耗性能的, 如果在 server 返回 response 不立即斷開 TCP 鏈接,而是復用這條鏈接進行下一次的 Http 請求,則無形中省略了很多創建 / 斷開 TCP 的開銷,性能上無疑會有很大提升。
如下圖示,左圖是不復用 TCP 發起多個 HTTP 請求的情況,右圖是復用 TCP 的情況,可以看到發起三次 HTTP 請求,復用 TCP 的話可以省去兩次建立 / 斷開 TCP 的開銷,理論上一個應用只要開啟一個 TCP 連接即可,其他 HTTP 請求都可以復用這個 TCP 連接,這樣 n 次 HTTP 請求可以省去 n-1 次創建 / 斷開 TCP 的開銷。這對性能的提升無疑是有巨大的幫助。
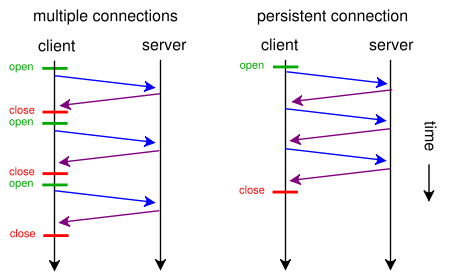
回過頭來看 keep-alive (又稱持久連接,連接復用)做的就是復用連接, 保證連接持久有效。
畫外音: Http 1.1 之后 keep-alive 默認支持并開啟,目前大部分網站都用了 http 1.1 了,也就是說大部分都默認支持連接復用了
天下沒有免費的午餐,雖然 keep-alive 省去了很多不必要的握手/揮手操作,但由于連接長期保活,如果一直沒有 http 請求的話,這條連接也就長期閑著了,會占用系統資源,有時反而會比復用連接帶來更大的性能消耗。所以我們一般會為 keep-alive 設置一個 timeout, 這樣如果連接在設置的 timeout 時間內一直處于空閑狀態(未發生任何數據傳輸),經過 timeout 時間后,連接就會釋放,就能節省系統開銷。
看起來給 keep-alive 加 timeout 是完美了,但是又引入了新的問題(一波已平,一波又起!),考慮如下情況:
如果服務端關閉連接,發送 FIN 包(注:在設置的 timeout 時間內服務端如果一直未收到客戶端的請求,服務端會主動發起帶 FIN 標志的請求以斷開連接釋放資源),在這個 FIN 包發送但是還未到達客戶端期間,客戶端如果繼續復用這個 TCP 連接發送 HTTP 請求報文的話,服務端會因為在四次揮手期間不接收報文而發送 RST 報文給客戶端,客戶端收到 RST 報文就會提示異常 (即NoHttpResponseException)
我們再用流程圖仔細梳理一下上述這種產生NoHttpResponseException的原因,這樣能看得更明白一些
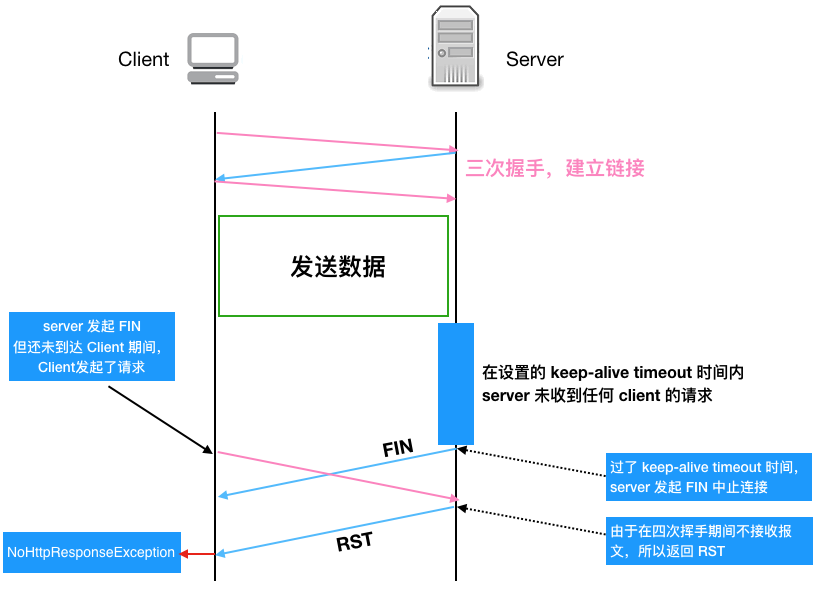
費了這么大的功夫,我們終于知道了產生NoHttpResponseException的原因,那該怎么解決呢,有兩種策略
重試,收到異常后,重試一兩次,由于重試后客戶端會用有效的連接去請求,所以可以避免這種情況,不過一次要注意重試次數,避免引起雪崩!
設置一個定時線程,定時清理上述的閑置連接,可以將這個定時時間設置為 keep alive timeout 時間的一半以保證超時前回收。
evictExpiredConnections就是用的上述第二種策略,來看下官方用法使用說明
Makes this instance of HttpClient proactively evict idle connections from the connection pool using a background thread.
調用這個方法只會產生一個定時線程,那為啥應用中線程會一直增加呢,因為我們對每一個請求都創建了一個 HttpClient! 這樣由于創建每一個 HttpClient 實例j時都會調用 evictExpiredConnections,導致有多少請求就會創建多少個定時線程!
還有一個問題,為啥線上四臺機器幾乎同一時間點全掛呢?因為由于負載均衡,這四臺機器的權重是一樣的,硬件配置也一樣,收到的請求其實也可以認為是差不多的,這樣這四臺機器由于創建 HttpClient 而生成的后臺線程也在同一時間達到最高點,然后同時 OOM。
解決問題
所以針對以上提到的問題,我們首先把 HttpClient 改成了單例,這樣保證服務啟動后只會有一個定時清理線程,另外我們也讓運維針對應用的線程數做了監控,如果超過某個閾值直接告警,這樣能在應用 OOM 前及時發現處理。
畫外音:再次強調,監控相當重要,能把問題扼殺在搖籃里!
總結
本文通過線上四臺機器同時 OOM 的現象,來詳細剖析定位了產生問題的原因,可以看到我們在應用某個庫時首先要對這個庫要有充分的了解(上述 HttpClient 的創建不用單例顯然是個問題),其次必要的網絡知識還是需要的,所以要成為一個合格的程序員,不光對語言本身有所了解,還要對網絡,數據庫等也要有所涉獵,這些對排查問題以及性能調優等會有非常大的幫助,再次,完善的監控非常重要,通過觸發某個閾值提前告警,可以將問題扼殺在搖籃里!
審核編輯 :李倩
-
機器
+關注
關注
0文章
790瀏覽量
41115 -
APM
+關注
關注
1文章
72瀏覽量
13306 -
線程
+關注
關注
0文章
507瀏覽量
20070
原文標題:震驚!線上四臺機器同一時間全部 OOM,到底發生了什么?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何保證同一時間串口只進行一個操作
可以請教大家一個問題嗎!大家能幫我看看這個板子是不是上錯物料呢!就是同一時
電源電路控制,使用與非門的74,不知道這樣的是需要設計一個什么樣的電路?
多個SmartXplorer在一臺機器上運行
ad9361基帶信號輸入為什么P路在同一時間周期內攜帶兩個相位相反的信號?
為什么一般的無線遙控玩具同一時間只能控制一個電機轉動
為什么我打印出來的都是同一時間的CPU使用率?
UART和CAN總線在同一時間會怎么樣
可以在同一時間使用STM32WB55的外部RAM和FLASH呢?
百度對Robin第一時間做出回答:我沒說過
高通、博通同一時間大量裁員_商量好了?
現場設備發生故障,虹科物聯網HMI第一時間通知相關人員?
虹科方案 | 現場設備發生故障,如何第一時間通知相關人員?






 工商網監
工商網監

評論