 6種卷積神經網絡壓縮方法
6種卷積神經網絡壓縮方法
我們知道,在一定程度上,網絡越深,參數越多,模型越復雜,其最終效果越好。神經網絡的壓縮算法是,旨在將一個龐大而復雜的預訓練模型(pre-trained model)轉化為一個精簡的小模型。按照壓縮過程對網絡結構的破壞程度,我們將模型壓縮技術分為 “前端壓縮” 和 “后端壓縮” 兩部分。
-
前端壓縮,是指在不改變原網絡結構的壓縮技術,主要包括知識蒸餾、輕量級網絡(緊湊的模型結構設計)以及濾波器(filter)層面的剪枝(結構化剪枝)等;
-
后端壓縮,是指包括低秩近似、未加限制的剪枝(非結構化剪枝 / 稀疏)、參數量化以及二值網絡等,目標在于盡可能減少模型大小,會對原始網絡結構造成極大程度的改造。
一,低秩近似
簡單理解就是,卷積神經網絡的權重矩陣往往稠密且巨大,從而計算開銷大,有一種辦法是采用低秩近似的技術將該稠密矩陣由若干個小規模矩陣近似重構出來,這種方法歸類為低秩近似算法。一般地,行階梯型矩陣的秩等于其 “臺階數”- 非零行的行數。低秩近似算法能減小計算開銷的原理如下: 基于以上想法,Sindhwani 等人提出使用結構化矩陣來進行低秩分解的算法,具體原理可自行參考論文。另一種比較簡便的方法是使用矩陣分解來降低權重矩陣的參數,如 Denton 等人提出使用奇異值分解(Singular Value Decomposition,簡稱 SVD)分解來重構全連接層的權重。
基于以上想法,Sindhwani 等人提出使用結構化矩陣來進行低秩分解的算法,具體原理可自行參考論文。另一種比較簡便的方法是使用矩陣分解來降低權重矩陣的參數,如 Denton 等人提出使用奇異值分解(Singular Value Decomposition,簡稱 SVD)分解來重構全連接層的權重。1.1,總結
低秩近似算法在中小型網絡模型上,取得了很不錯的效果,但其超參數量與網絡層數呈線性變化趨勢,隨著網絡層數的增加與模型復雜度的提升,其搜索空間會急劇增大,目前主要是學術界在研究,工業界應用不多。二,剪枝與稀疏約束
給定一個預訓練好的網絡模型,常用的剪枝算法一般都遵從如下操作:-
衡量神經元的重要程度
-
移除掉一部分不重要的神經元,這步比前 1 步更加簡便,靈活性更高
-
對網絡進行微調,剪枝操作不可避免地影響網絡的精度,為防止對分類性能造成過大的破壞,需要對剪枝后的模型進行微調。對于大規模行圖像數據集(如 ImageNet)而言,微調會占用大量的計算資源,因此對網絡微調到什么程度,是需要斟酌的
-
返回第一步,循環進行下一輪剪枝
2.1,總結
總體而言,剪枝是一項有效減小模型復雜度的通用壓縮技術,其關鍵之處在于如何衡量個別權重對于整體模型的重要程度。剪枝操作對網絡結構的破壞程度極小,將剪枝與其他后端壓縮技術相結合,能夠達到網絡模型最大程度壓縮,目前工業界有使用剪枝方法進行模型壓縮的案例。三,參數量化
相比于剪枝操作,參數量化則是一種常用的后端壓縮技術。所謂 “量化”,是指從權重中歸納出若干 “代表”,由這些 “代表” 來表示某一類權重的具體數值。“代表” 被存儲在碼本(codebook)之中,而原權重矩陣只需記錄各自 “代表” 的索引即可,從而極大地降低了存儲開銷。這種思想可類比于經典的詞包模型(bag-of-words model)。常用量化算法如下:-
標量量化(scalar quantization)。
-
標量量化會在一定程度上降低網絡的精度,為避免這個弊端,很多算法考慮結構化的向量方法,其中一種是乘積向量(Product Quantization, PQ),詳情咨詢查閱論文。
-
以 PQ 方法為基礎,Wu 等人設計了一種通用的網絡量化算法:QCNN (quantized CNN),主要思想在于 Wu 等人認為最小化每一層網絡輸出的重構誤差,比最小化量化誤差更有效。

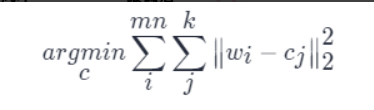 這樣,只需將 kk個聚類中心(cjcj,標量)存儲在碼本中,而原權重矩陣則只負責記錄各自聚類中心在碼本中索引。如果不考慮碼本的存儲開銷,該算法能將存儲空間減少為原來的 log2 (k)/32log2(k)/32。基于 kk均值算法的標量量化在很多應用中非常有效。參數量化與碼本微調過程圖如下:
這樣,只需將 kk個聚類中心(cjcj,標量)存儲在碼本中,而原權重矩陣則只負責記錄各自聚類中心在碼本中索引。如果不考慮碼本的存儲開銷,該算法能將存儲空間減少為原來的 log2 (k)/32log2(k)/32。基于 kk均值算法的標量量化在很多應用中非常有效。參數量化與碼本微調過程圖如下: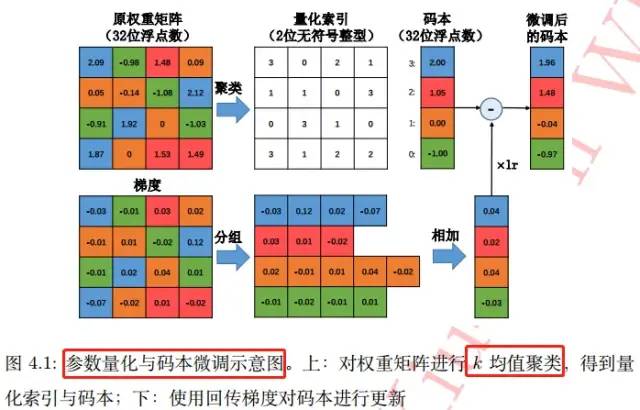 這三類基于聚類的參數量化算法,其本質思想在于將多個權重映射到同一個數值,從而實現權重共享,降低存儲開銷的目的。
這三類基于聚類的參數量化算法,其本質思想在于將多個權重映射到同一個數值,從而實現權重共享,降低存儲開銷的目的。3.1,總結
參數量化是一種常用的后端壓縮技術,能夠以很小的性能損失實現模型體積的大幅下降,不足之處在于,量化的網絡是 “固定” 的,很難對其做任何改變,同時這種方法通用性差,需要配套專門的深度學習庫來運行網絡。這里,權重參數從浮點轉定點、二值化等方法都是是試圖避免浮點計算耗時而引入的方法,這些方法能加快運算速率,同時減少內存和存儲空間的占用,并保證模型的精度損失在可接受的范圍內,因此這些方法的應用是有其現實價值的。更多參數量化知識,請參考此github 倉庫:https://github.com/Ewenwan/MVision/blob/master/CNN/Deep_Compression/quantization/readme.md四,二值化網絡
1. 二值化網絡可以視為量化方法的一種極端情況:所有的權重參數取值只能為 ±1±1 ,也就是使用 1bit 來存儲 Weight 和 Feature。在普通神經網絡中,一個參數是由單精度浮點數來表示的,參數的二值化能將存儲開銷降低為原來的 1/32。2. 二值化神經網絡以其高的模型壓縮率和在前傳中計算速度上的優勢,近幾年格外受到重視和發展,成為神經網絡模型研究中的非常熱門的一個研究方向。但是,第一篇真正意義上將神經網絡中的權重值和激活函數值同時做到二值化的是 Courbariaux 等人 2016 年發表的名為《Binarynet: Training deep neural networks with weights and activations constrained to +1 or -1》的一篇論文。這篇論文第一次給出了關于如何對網絡進行二值化和如何訓練二值化神經網絡的方法。3.CNN 網絡一個典型的模塊是由卷積 (Conv)-> 批標準化 (BNorm)-> 激活 (Activ)-> 池化 (Pool) 這樣的順序操作組成的。對于異或神經網絡,設計出的模塊是由批標準化 (BNorm)->二值化激活 (BinActiv)-> 二值化卷積 (BinConv)-> 池化 (Pool) 的順序操作完成。這樣做的原因是批標準化以后,保證了輸入均值為 0,然后進行二值化激活,保證了數據為 -1 或者 +1,然后進行二值化卷積,這樣能最大程度上減少特征信息的損失。二值化殘差網絡結構定義實例代碼如下:
def residual_unit(data, num_filter, stride, dim_match, num_bits=1):
"""殘差塊 Residual Block 定義
"""
bnAct1 = bnn.BatchNorm(data=data, num_bits=num_bits)
conv1 = bnn.Convolution(data=bnAct1, num_filter=num_filter, kernel=(3, 3), stride=stride, pad=(1, 1))
convBn1 = bnn.BatchNorm(data=conv1, num_bits=num_bits)
conv2 = bnn.Convolution(data=convBn1, num_filter=num_filter, kernel=(3, 3), stride=(1, 1), pad=(1, 1))
if dim_match:
shortcut = data
else:
shortcut = bnn.Convolution(data=bnAct1, num_filter=num_filter, kernel=(3, 3), stride=stride, pad=(1, 1))
return conv2 + shortcut
4.1,二值網絡的梯度下降
現在的神經網絡幾乎都是基于梯度下降算法來訓練的,但是二值網絡的權重只有 ±1±1,無法直接計算梯度信息,也無法進行權重更新。為解決這個問題,Courbariaux等人提出二值連接(binary connect)算法,該算法采取單精度與二值結合的方式來訓練二值神經網絡,這是第一次給出了關于如何對網絡進行二值化和如何訓練二值化神經網絡的方法。過程如下:1. 權重 weight 初始化為浮點
2. 前向傳播 Forward Pass:
-
-
利用決定化方式(sign (x) 函數)把 Weight 量化為 +1/-1, 以 0 為閾值
-
利用量化后的 Weight (只有 + 1/-1) 來計算前向傳播,由二值權重與輸入進行卷積運算(實際上只涉及加法),獲得卷積層輸出。
-
3. 反向傳播 Backward Pass:
-
-
把梯度更新到浮點的 Weight 上(根據放松后的符號函數,計算相應梯度值,并根據該梯度的值對單精度的權重進行參數更新)
-
訓練結束:把 Weight 永久性轉化為 +1/-1, 以便 inference 使用
-
4.2,兩個問題
網絡二值化需要解決兩個問題:如何對權重進行二值化和如何計算二值權重的梯度。1,如何對權重進行二值化?權重二值化一般有兩種選擇:-
直接根據權重的正負進行二值化:xb=sign (x)xb=sign(x)。符號函數 sign (x) 定義如下:
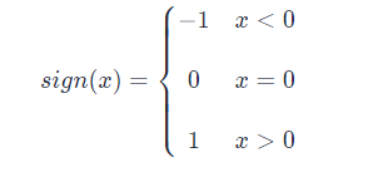
-
進行隨機的二值化,即對每一個權重,以一定概率取 ±1±1
4.3,二值連接算法改進
之前的二值連接算法只對權重進行了二值化,但是網絡的中間輸出值依然是單精度的,于是 Rastegari 等人對此進行了改進,提出用單精度對角陣與二值矩陣之積來近似表示原矩陣的算法,以提升二值網絡的分類性能,彌補二值網絡在精度上弱勢。該算法將原卷積運算分解為如下過程:
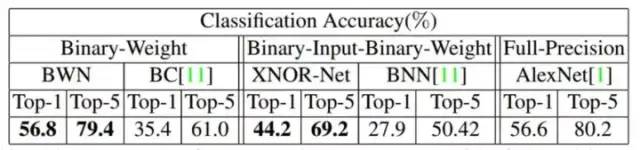 可以看到的是權重二值化神經網絡(BWN)和全精度神經網絡的精確度幾乎一樣,但是與異或神經網絡(XNOR-Net)相比而言,Top-1 和 Top-5 都有 10+% 的損失。相比于權重二值化神經網絡,異或神經網絡將網絡的輸入也轉化為二進制值,所以,異或神經網絡中的乘法加法 (Multiplication and ACcumulation) 運算用按位異或 (bitwise xnor) 和數 1 的個數 (popcount) 來代替。
可以看到的是權重二值化神經網絡(BWN)和全精度神經網絡的精確度幾乎一樣,但是與異或神經網絡(XNOR-Net)相比而言,Top-1 和 Top-5 都有 10+% 的損失。相比于權重二值化神經網絡,異或神經網絡將網絡的輸入也轉化為二進制值,所以,異或神經網絡中的乘法加法 (Multiplication and ACcumulation) 運算用按位異或 (bitwise xnor) 和數 1 的個數 (popcount) 來代替。4.4,二值網絡設計注意事項
-
不要使用 kernel = (1, 1) 的 Convolution (包括 resnet 的 bottleneck):二值網絡中的 weight 都為 1bit, 如果再是 1x1 大小, 會極大地降低表達能力
-
增大 Channel 數目 + 增大 activation bit 數 要協同配合:如果一味增大 channel 數, 最終 feature map 因為 bit 數過低, 還是浪費了模型容量。同理反過來也是。
-
建議使用 4bit 及以下的 activation bit, 過高帶來的精度收益變小, 而會顯著提高 inference 計算量
五,知識蒸餾
本文只簡單介紹這個領域的開篇之作 - Distilling the Knowledge in a Neural Network,這是蒸 "logits" 方法,后面還出現了蒸 “features” 的論文。想要更深入理解,中文博客可參考這篇文章 - 知識蒸餾是什么?一份入門隨筆。知識蒸餾(knowledge distillation),是遷移學習(transfer learning)的一種,簡單來說就是訓練一個大模型(teacher)和一個小模型(student),將龐大而復雜的大模型學習到的知識,通過一定技術手段遷移到精簡的小模型上,從而使小模型能夠獲得與大模型相近的性能。 所以,可以知道 student 模型最終的損失函數由兩部分組成:這兩個損失函數的重要程度可通過一定的權重進行調節,在實際應用中,T 的取值會影響最終的結果,一般而言,較大的 T 能夠獲得較高的準確度,T(蒸餾溫度參數) 屬于知識蒸餾模型訓練超參數的一種。T 是一個可調節的超參數、T 值越大、概率分布越軟(論文中的描述),曲線便越平滑,相當于在遷移學習的過程中添加了擾動,從而使得學生網絡在借鑒學習的時候更有效、泛化能力更強,這其實就是一種抑制過擬合的策略。知識蒸餾的整個過程如下圖:
所以,可以知道 student 模型最終的損失函數由兩部分組成:這兩個損失函數的重要程度可通過一定的權重進行調節,在實際應用中,T 的取值會影響最終的結果,一般而言,較大的 T 能夠獲得較高的準確度,T(蒸餾溫度參數) 屬于知識蒸餾模型訓練超參數的一種。T 是一個可調節的超參數、T 值越大、概率分布越軟(論文中的描述),曲線便越平滑,相當于在遷移學習的過程中添加了擾動,從而使得學生網絡在借鑒學習的時候更有效、泛化能力更強,這其實就是一種抑制過擬合的策略。知識蒸餾的整個過程如下圖: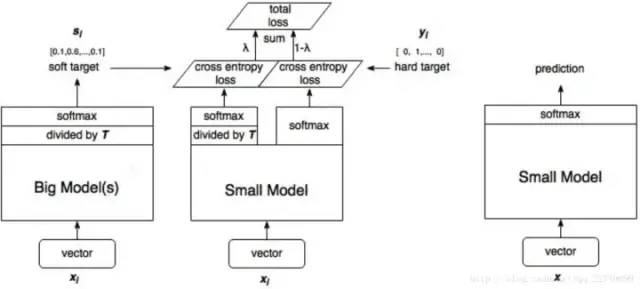 student 模型的實際模型結構和小模型一樣,但是損失函數包含了兩部分,分類網絡的知識蒸餾 mxnet 代碼示例如下:
student 模型的實際模型結構和小模型一樣,但是損失函數包含了兩部分,分類網絡的知識蒸餾 mxnet 代碼示例如下:
# -*-coding-*- : utf-8
"""
本程序沒有給出具體的模型結構代碼,主要給出了知識蒸餾 softmax 損失計算部分。
"""
import mxnet as mx
def get_symbol(data, class_labels, resnet_layer_num,Temperature,mimic_weight,num_classes=2):
backbone = StudentBackbone(data) # Backbone 為分類網絡 backbone 類
flatten = mx.symbol.Flatten(data=conv1, name="flatten")
fc_class_score_s = mx.symbol.FullyConnected(data=flatten, num_hidden=num_classes, name='fc_class_score')
softmax1 = mx.symbol.SoftmaxOutput(data=fc_class_score_s, label=class_labels, name='softmax_hard')
import symbol_resnet # Teacher model
fc_class_score_t = symbol_resnet.get_symbol(net_depth=resnet_layer_num, num_class=num_classes, data=data)
s_input_for_softmax=fc_class_score_s/Temperature
t_input_for_softmax=fc_class_score_t/Temperature
t_soft_labels=mx.symbol.softmax(t_input_for_softmax, name='teacher_soft_labels')
softmax2 = mx.symbol.SoftmaxOutput(data=s_input_for_softmax, label=t_soft_labels, name='softmax_soft',grad_scale=mimic_weight)
group=mx.symbol.Group([softmax1,softmax2])
group.save('group2-symbol.json')
return group
tensorflow 代碼示例如下:
# 將類別標簽進行one-hot編碼
one_hot = tf.one_hot(y, n_classes,1.0,0.0) # n_classes為類別總數, n為類別標簽
# one_hot = tf.cast(one_hot_int, tf.float32)
teacher_tau = tf.scalar_mul(1.0/args.tau, teacher) # teacher為teacher模型直接輸出張量, tau為溫度系數T
student_tau = tf.scalar_mul(1.0/args.tau, student) # 將模型直接輸出logits張量student處于溫度系數T
objective1 = tf.nn.sigmoid_cross_entropy_with_logits(student_tau, one_hot)
objective2 = tf.scalar_mul(0.5, tf.square(student_tau-teacher_tau))
"""
student模型最終的損失函數由兩部分組成:
第一項是由小模型的預測結果與大模型的“軟標簽”所構成的交叉熵(cross entroy);
第二項為預測結果與普通類別標簽的交叉熵。
"""
tf_loss = (args.lamda*tf.reduce_sum(objective1) + (1-args.lamda)*tf.reduce_sum(objective2))/batch_size
tf.scalar_mul 函數為對 tf 張量進行固定倍率 scalar 縮放函數。一般 T 的取值在 1 - 20 之間,這里我參考了開源代碼,取值為 3。我發現在開源代碼中 student 模型的訓練,有些是和 teacher 模型一起訓練的,有些是 teacher 模型訓練好后直接指導 student 模型訓練。
六,淺層 / 輕量網絡
淺層網絡:通過設計一個更淺(層數較少)結構更緊湊的網絡來實現對復雜模型效果的逼近,但是淺層網絡的表達能力很難與深層網絡相匹敵。因此,這種設計方法的局限性在于只能應用解決在較為簡單問題上。如分類問題中類別數較少的 task。
輕量網絡:使用如 MobilenetV2、ShuffleNetv2 等輕量網絡結構作為模型的 backbone 可以大幅減少模型參數數量。
審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100745 -
算法
+關注
關注
23文章
4610瀏覽量
92859 -
線性
+關注
關注
0文章
198瀏覽量
25148
原文標題:6種卷積神經網絡壓縮方法
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論