") 谷歌新作Dreamix:視頻擴(kuò)散模型是通用視頻編輯器,效果驚艷!
谷歌新作Dreamix:視頻擴(kuò)散模型是通用視頻編輯器,效果驚艷!
AIGC 已經(jīng)火了很長(zhǎng)時(shí)間了,出現(xiàn)了文本生成圖像、文本生成視頻、圖像生成視頻等廣泛的應(yīng)用場(chǎng)景,如今谷歌研究院的一項(xiàng)新研究可以讓我們根據(jù)輸入視頻生成其他視頻了!
我們知道,生成模型和多模態(tài)視覺語(yǔ)言模型的進(jìn)展已經(jīng)為具備前所未有生成真實(shí)性和多樣性的大型文本到圖像模型鋪平了道路。這些模型提供了新的創(chuàng)作過(guò)程,但僅限于合成新圖像而非編輯現(xiàn)有圖像。為了彌合這一差距,基于文本的直觀編輯方法可以對(duì)生成和真實(shí)圖像進(jìn)行基于文本的編輯,并保留這些圖像的一些原始屬性。與圖像類似,近來(lái)文本到視頻模型也提出了很多,但使用這些模型進(jìn)行視頻編輯的方法卻很少。 在文本指導(dǎo)的視頻編輯中,用戶提供輸入視頻以及描述生成視頻預(yù)期屬性的文本 prompt,如下圖 1 所示。目標(biāo)有以下三個(gè)方面,1)對(duì)齊,編輯后的視頻應(yīng)符合輸入文本 prompt;2)保真度,編輯后的視頻應(yīng)保留原始視頻的內(nèi)容,3)質(zhì)量,編輯后的視頻應(yīng)具備高質(zhì)量。 可以看到,視頻編輯比圖像編輯更加具有挑戰(zhàn)性,它需要合成新的動(dòng)作,而不僅僅是修改視覺外觀。此外還需要保持時(shí)間上的一致性。因此,將 SDEdit、Prompt-to-Prompt 等圖像級(jí)別的編輯方法應(yīng)用于視頻幀上不足以實(shí)現(xiàn)很好的效果。

在近日谷歌研究院等發(fā)表在 arXiv 的一篇論文中,研究者提出了一種新方法 Dreamix,它受到了 UniTune 的啟發(fā),將文本條件視頻擴(kuò)散模型(video diffusion model, VDM)應(yīng)用于視頻編輯。

Dreamix: Video Diffusion Models are General Video Editors
論文地址:https://arxiv.org/abs/2302.01329
項(xiàng)目主頁(yè):https://dreamix-video-editing.github.io/
文中方法的核心是通過(guò)以下兩種主要思路使文本條件 VDM 保持對(duì)輸入視頻的高保真度。其一不使用純?cè)肼曌鳛槟P统跏蓟鞘褂迷家曨l的降級(jí)版本,通過(guò)縮小尺寸和添加噪聲僅保留低時(shí)空信息;其二通過(guò)微調(diào)原始視頻上的生成模型來(lái)進(jìn)一步提升對(duì)原始視頻的保真度。 微調(diào)確保模型了解原始視頻的高分辨率屬性。對(duì)輸入視頻的簡(jiǎn)單微調(diào)會(huì)促成相對(duì)較低的運(yùn)動(dòng)可編輯性,這是因?yàn)槟P蛯W(xué)會(huì)了更傾向于原始運(yùn)動(dòng)而不是遵循文本 prompt。研究者提出了一種新穎的混合微調(diào)方法,其中 VDM 也在輸入視頻各個(gè)幀的集合上進(jìn)行微調(diào),并丟棄了它們的時(shí)序。混合微調(diào)顯著提升了運(yùn)動(dòng)編輯的質(zhì)量。 研究者進(jìn)一步利用其視頻編輯模型提出了一個(gè)新的圖像動(dòng)畫框架,如下圖 2 所示。該框架包含了幾個(gè)步驟,比如為圖像中的對(duì)象和背景設(shè)置動(dòng)畫、創(chuàng)建動(dòng)態(tài)相機(jī)運(yùn)動(dòng)等。他們通過(guò)幀復(fù)制或幾何圖像變換等簡(jiǎn)單的圖像處理操作來(lái)實(shí)現(xiàn),從而創(chuàng)建粗糙的視頻。接著使用 Dreamix 視頻編輯器對(duì)視頻進(jìn)行編輯。此外研究者還使用其微調(diào)方法進(jìn)行目標(biāo)驅(qū)動(dòng)的視頻生成,也即 Dreambooth 的視頻版本。

在實(shí)驗(yàn)展示部分,研究者進(jìn)行了廣泛的定性研究和人工評(píng)估,展示了他們方法的強(qiáng)大能力,具體可參考如下動(dòng)圖。

?


對(duì)于谷歌這項(xiàng)研究,有人表示,3D + 運(yùn)動(dòng)和編輯工具可能是下一波論文的熱門主題。
還有人表示:大家可以很快在預(yù)算內(nèi)制作自己的的電影了,你所需要的只是一個(gè)綠幕以及這項(xiàng)技術(shù):

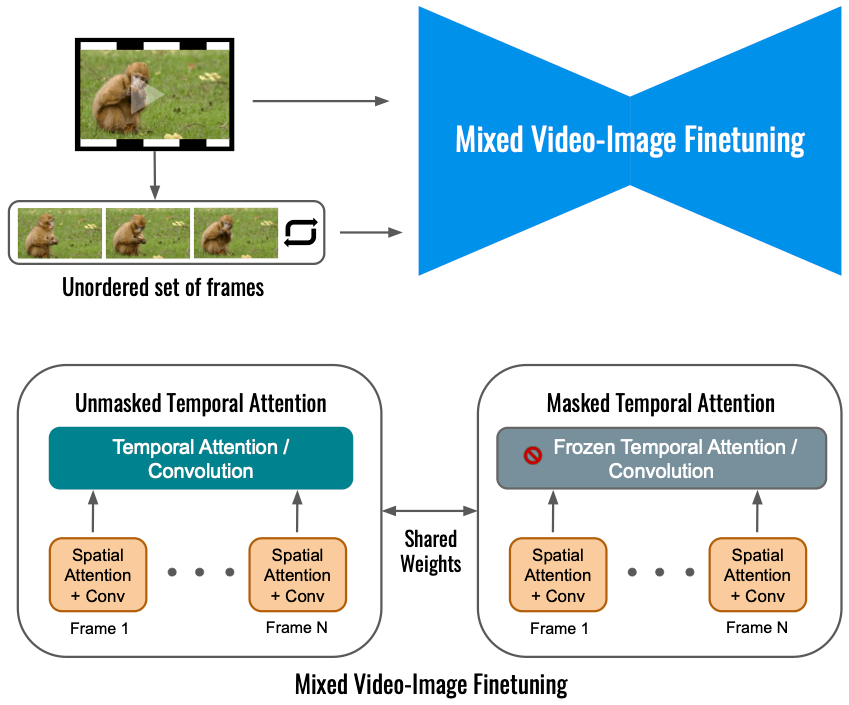
方法概覽 本文提出了一種新的方法用于視頻編輯,具體而言: 通過(guò)逆向被破壞視頻進(jìn)行文本引導(dǎo)視頻編輯 他們采用級(jí)聯(lián) VDM( Video Diffusion Models ),首先通過(guò)下采樣對(duì)輸入視頻就行一定的破壞,后加入噪聲。接下來(lái)是級(jí)聯(lián)擴(kuò)散模型用于采樣過(guò)程,并以時(shí)間 t 為條件,將視頻升級(jí)到最終的時(shí)間 - 空間分辨率。 在對(duì)輸入視頻進(jìn)行破壞處理的這一過(guò)程中,首先需要進(jìn)行下采樣操作,以得到基礎(chǔ)模型(16 幀 24 × 40),然后加入方差為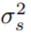 高斯噪聲,從而進(jìn)一步破壞輸入視頻。 ? 對(duì)于上述處理好的視頻,接下來(lái)的操作是使用級(jí)聯(lián) VDM 將損壞掉的低分辨率視頻映射到與文本對(duì)齊的高分辨率視頻。這里的核心思想是,給定一個(gè)嘈雜的、時(shí)間空間分辨率非常低的視頻,有許多完全可行的、高分辨率的視頻與之對(duì)應(yīng)。本文中基礎(chǔ)模型從損壞的視頻開始,它與時(shí)間 s 的擴(kuò)散過(guò)程具有相同的噪聲。然后該研究用 VDM 來(lái)逆向擴(kuò)散過(guò)程直到時(shí)間 0。最后通過(guò)超分辨率模型對(duì)視頻進(jìn)行升級(jí)。 ?混合視頻圖像微調(diào)? 僅利用輸入視頻進(jìn)行視頻擴(kuò)散模型的微調(diào)會(huì)限制物體運(yùn)動(dòng)變化,相反,該研究使用了一種混合目標(biāo),即除了原始目標(biāo)(左下角)之外,本文還對(duì)無(wú)序的幀集進(jìn)行了微調(diào),這是通過(guò)「masked temporal attention」來(lái)完成的,以防止時(shí)間注意力和卷積被微調(diào)(右下)。這種操作允許向靜態(tài)視頻中添加運(yùn)動(dòng)。 ?
高斯噪聲,從而進(jìn)一步破壞輸入視頻。 ? 對(duì)于上述處理好的視頻,接下來(lái)的操作是使用級(jí)聯(lián) VDM 將損壞掉的低分辨率視頻映射到與文本對(duì)齊的高分辨率視頻。這里的核心思想是,給定一個(gè)嘈雜的、時(shí)間空間分辨率非常低的視頻,有許多完全可行的、高分辨率的視頻與之對(duì)應(yīng)。本文中基礎(chǔ)模型從損壞的視頻開始,它與時(shí)間 s 的擴(kuò)散過(guò)程具有相同的噪聲。然后該研究用 VDM 來(lái)逆向擴(kuò)散過(guò)程直到時(shí)間 0。最后通過(guò)超分辨率模型對(duì)視頻進(jìn)行升級(jí)。 ?混合視頻圖像微調(diào)? 僅利用輸入視頻進(jìn)行視頻擴(kuò)散模型的微調(diào)會(huì)限制物體運(yùn)動(dòng)變化,相反,該研究使用了一種混合目標(biāo),即除了原始目標(biāo)(左下角)之外,本文還對(duì)無(wú)序的幀集進(jìn)行了微調(diào),這是通過(guò)「masked temporal attention」來(lái)完成的,以防止時(shí)間注意力和卷積被微調(diào)(右下)。這種操作允許向靜態(tài)視頻中添加運(yùn)動(dòng)。 ?
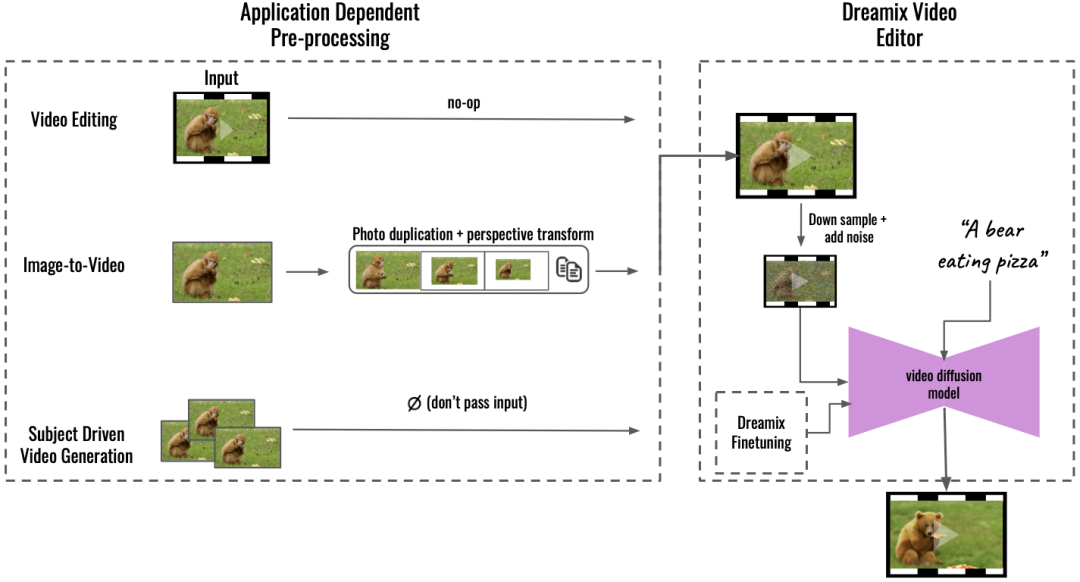
推理 在應(yīng)用程序預(yù)處理的基礎(chǔ)上(Aapplication Dependent Pre-processing,下圖左),該研究支持多種應(yīng)用,能將輸入內(nèi)容轉(zhuǎn)換為統(tǒng)一的視頻格式。對(duì)于圖像到視頻,輸入圖像被復(fù)制并被變換,合成帶有一些相機(jī)運(yùn)動(dòng)的粗略視頻;對(duì)于目標(biāo)驅(qū)動(dòng)視頻生成,其輸入被省略,單獨(dú)進(jìn)行微調(diào)以維持保真度。然后使用 Dreamix Video Editor(右)編輯這個(gè)粗糙的視頻:即前面講到的,首先通過(guò)下采樣破壞視頻,添加噪聲。然后應(yīng)用微調(diào)的文本引導(dǎo)視頻擴(kuò)散模型,將視頻升級(jí)到最終的時(shí)間空間分辨率。
實(shí)驗(yàn)結(jié)果 視頻編輯:下圖中 Dreamix 將動(dòng)作改為舞蹈,并且外觀由猴子變?yōu)樾埽曨l中主體的基本屬性沒有變:

Dreamix 還可以生成與輸入視頻時(shí)間信息一致的平滑視覺修改,如下圖會(huì)滑滑板的小鹿:

圖像到視頻:當(dāng)輸入是一張圖像時(shí),Dreamix 可以使用其視頻先驗(yàn)添加新的移動(dòng)對(duì)象,如下圖中添加了在有霧的森林中出現(xiàn)一頭獨(dú)角獸,并放大。

小屋旁邊出現(xiàn)企鵝:

目標(biāo)驅(qū)動(dòng)視頻生成:Dreamix 還可以獲取顯示相同主題的圖像集合,并以該主題為運(yùn)動(dòng)對(duì)象生成新的視頻。如下圖是一條在葉子上蠕動(dòng)的毛毛蟲:

除了定性分析外,該研究還進(jìn)行了基線比較,主要是將 Dreamix 與 Imagen-Video、 Plug-and-Play (PnP) 兩種基線方法進(jìn)行對(duì)比。下表為評(píng)分結(jié)果:
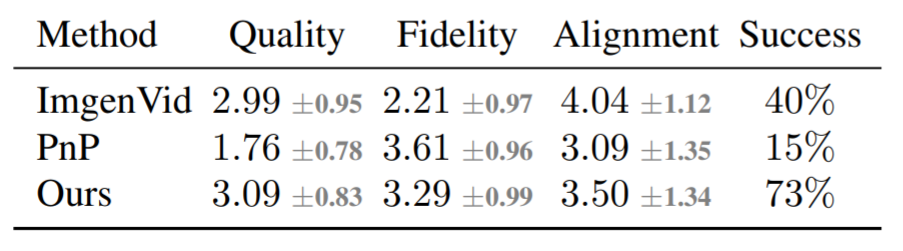
圖 8 展示了由 Dreamix 編輯的視頻和兩個(gè)基線示例:文本到視頻模型實(shí)現(xiàn)了低保真度的編輯,因?yàn)樗灰栽家曨l為條件。PnP 保留了場(chǎng)景,但不同幀之間缺乏一致性;Dreamix 在這三個(gè)目標(biāo)上都表現(xiàn)良好。

審核編輯 :李倩
-
視頻
+關(guān)注
關(guān)注
6文章
1942瀏覽量
72887 -
編輯器
+關(guān)注
關(guān)注
1文章
805瀏覽量
31163 -
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
521瀏覽量
10268
原文標(biāo)題:谷歌新作Dreamix:視頻擴(kuò)散模型是通用視頻編輯器,效果驚艷!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
圖紙編輯器的基本操作
擴(kuò)散模型的理論基礎(chǔ)

Vivado編輯器亂碼問(wèn)題
vim編輯器命令模式使用方法
vim編輯器如何使用
嵌入式學(xué)習(xí)-常用編輯器之Vim編輯器
常用編輯器之Vim編輯器
Sora還在PPT階段,“中國(guó)版Sora”已經(jīng)開放使用了!
TSMaster 中 Hex 文件編輯器使用詳細(xì)教程

谷歌發(fā)布全新視頻生成模型Veo與Imagen文生圖模型
OpenAI文生視頻模型Sora要點(diǎn)分析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論