 詳細解讀Linux CPU的上下文切換過程
詳細解讀Linux CPU的上下文切換過程
我們都知道 Linux 是一個多任務操作系統,它支持的任務同時運行的數量遠遠大于 CPU 的數量。當然,這些任務實際上并不是同時運行的(Single CPU),而是因為系統在短時間內將 CPU 輪流分配給任務,造成了多個任務同時運行的假象。
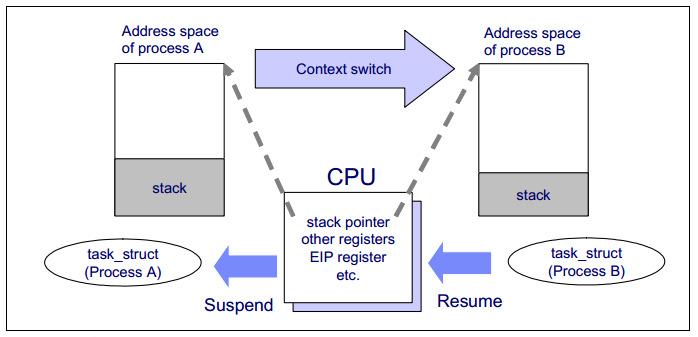
CPU 上下文(CPU Context)
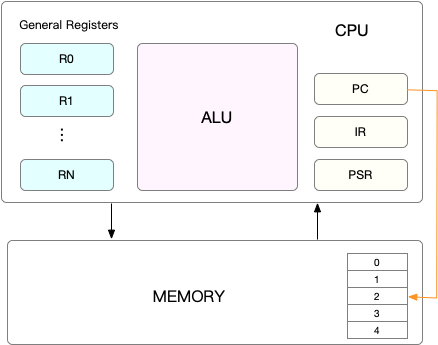
在每個任務運行之前,CPU 需要知道在哪里加載和啟動任務。這意味著系統需要提前幫助設置 CPU 寄存器和程序計數器。
CPU 寄存器是內置于 CPU 中的小型但速度極快的內存。程序計數器用于存儲 CPU 正在執行的或下一條要執行指令的位置。
它們都是 CPU 在運行任何任務之前必須依賴的依賴環境,因此也被稱為 “CPU 上下文”。如下圖所示:
知道了 CPU 上下文是什么,我想你理解CPU 上下文切換就很容易了。“CPU上下文切換”指的是先保存上一個任務的 CPU 上下文(CPU寄存器和程序計數器),然后將新任務的上下文加載到這些寄存器和程序計數器中,最后跳轉到程序計數器。
這些保存的上下文存儲在系統內核中,并在重新安排任務執行時再次加載。這確保了任務的原始狀態不受影響,并且任務似乎在持續運行。
CPU 上下文切換的類型
你可能會說 CPU 上下文切換無非就是更新 CPU 寄存器和程序計數器值,而這些寄存器是為了快速運行任務而設計的,那為什么會影響 CPU 性能呢?
在回答這個問題之前,請問,你有沒有想過這些“任務”是什么?你可能會說一個任務就是一個進程或者一個線程。是的,進程和線程正是最常見的任務,但除此之外,還有其他類型的任務。
別忘了硬件中斷也是一個常見的任務,硬件觸發信號,會引起中斷處理程序的調用。
因此,CPU 上下文切換至少有三種不同的類型:
進程上下文切換
線程上下文切換
中斷上下文切換
讓我們一一來看看。
進程上下文切換
Linux 按照特權級別將進程的運行空間劃分為內核空間和用戶空間,分別對應下圖中Ring 0和Ring 3的 CPU 特權級別的 。
內核空間(Ring 0)擁有最高權限,可以直接訪問所有資源。
用戶空間(Ring 3)只能訪問受限資源,不能直接訪問內存等硬件設備,它必須通過系統調用被陷入(trapped)內核中才能訪問這些特權資源。
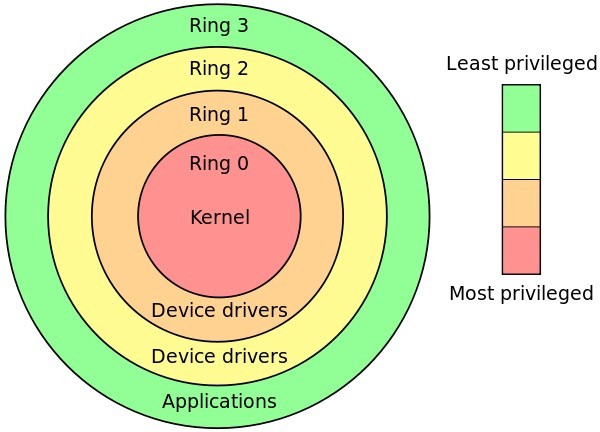
從另一個角度看,一個進程既可以在用戶空間也可以在內核空間運行。當一個進程在用戶空間運行時,稱為該進程的用戶態,當它落入內核空間時,稱為該進程的內核態。
從用戶態到內核態的轉換需要通過系統調用來完成。例如,當我們查看一個文件的內容時,我們需要以下系統調用:
open():打開文件
read():讀取文件的內容
write():將文件的內容寫入到輸出文件(包括標準輸出)
close():關閉文件
那么在上述系統調用過程中是否會發生 CPU 上下文切換呢?當然是的。
這需要先保存 CPU 寄存器中原來的用戶態指令的位置。接下來,為了執行內核態的代碼,需要將 CPU 寄存器更新到內核態指令的新位置。最后是跳轉到內核態運行內核任務。
那么系統調用結束后,CPU 寄存器需要恢復原來保存的用戶狀態,然后切換到用戶空間繼續運行進程。
因此,在一次系統調用的過程中,實際上有兩次 CPU 上下文切換。
但需要指出的是,系統調用進程不會涉及進程切換,也不會涉及虛擬內存等系統資源切換。這與我們通常所說的“進程上下文切換”不同。進程上下文切換是指從一個進程切換到另一個進程,而系統調用期間始終運行同一個進程。
系統調用過程通常被稱為特權模式切換,而不是上下文切換。但實際上,在系統調用過程中,CPU 的上下文切換也是不可避免的。
進程上下文切換 vs 系統調用
那么進程上下文切換和系統調用有什么區別呢?首先,進程是由內核管理的,進程切換只能發生在內核態。因此,進程上下文不僅包括虛擬內存、棧和全局變量等用戶空間資源,還包括內核棧和寄存器等內核空間的狀態。
所以進程上下文切換比系統調用要多出一步:
在保存當前進程的內核狀態和 CPU 寄存器之前,需要保存進程的虛擬內存、棧等;并加載下一個進程的內核狀態。
根據 Tsuna 的測試報告,每次上下文切換需要幾十納秒至微秒的 CPU 時間。這個時間是相當可觀的,尤其是在大量進程上下文切換的情況下,很容易導致 CPU 花費大量時間來保存和恢復寄存器、內核棧、虛擬內存等資源。這正是我們在上一篇文章中談到的,一個導致平均負載上升的重要因素。
那么,該進程何時會被調度/切換到在 CPU 上運行?其實有很多場景,下面我為大家總結一下:
當一個進程的 CPU 時間片用完時,它會被系統掛起,并切換到其它等待 CPU 運行的進程。
當系統資源不足(如內存不足)時,直到資源充足之前,進程無法運行。此時進程也會被掛起,系統會調度其它進程運行。
當一個進程通過 sleep函數自動掛起自己時,自然會被重新調度。
當優先級較高的進程運行時,為了保證高優先級進程的運行,當前進程會被高優先級進程掛起運行。
當發生硬件中斷時,CPU上的進程會被中斷掛起,轉而執行內核中的中斷服務程序。
了解這些場景是非常有必要的,因為一旦上下文切換出現性能問題,它們就是幕后殺手。
線程上下文切換
線程和進程最大的區別在于,線程是任務調度的基本單位,而進程是資源獲取的基本單位。
說白了,內核中所謂的任務調度,實際的調度對象是線程;而進程只為線程提供虛擬內存和全局變量等資源。所以,對于線程和進程,我們可以這樣理解:
當一個進程只有一個線程時,可以認為一個進程等于一個線程。
當一個進程有多個線程時,這些線程共享相同的資源,例如虛擬內存和全局變量。
此外,線程也有自己的私有數據,比如棧和寄存器,在上下文切換時也需要保存。
這樣,線程的上下文切換其實可以分為兩種情況:
首先,前后兩個線程屬于不同的進程。此時,由于資源不共享,切換過程與進程上下文切換相同。
其次,前后兩個線程屬于同一個進程。此時,由于虛擬內存是共享的,所以切換時虛擬內存的資源保持不變,只需要切換線程的私有數據、寄存器等未共享的數據。
顯然,同一個進程內的線程切換比切換多個進程消耗的資源要少。這也是多線程替代多進程的優勢。
中斷上下文切換
除了前面兩種上下文切換之外,還有另外一種場景也輸出 CPU 上下文切換的,那就是中斷。
為了快速響應事件,硬件中斷會中斷正常的調度和執行過程,進而調用中斷處理程序。
在中斷其他進程時,需要保存進程的當前狀態,以便中斷后進程仍能從原始狀態恢復。
與進程上下文不同,中斷上下文切換不涉及進程的用戶態。因此,即使中斷進程中斷了處于用戶態的進程,也不需要保存和恢復進程的虛擬內存、全局變量等用戶態資源。
另外,和進程上下文切換一樣,中斷上下文切換也會消耗 CPU。過多的切換次數會消耗大量的 CPU 資源,甚至嚴重降低系統的整體性能。因此,當您發現中斷過多時,需要注意排查它是否會對您的系統造成嚴重的性能問題。
問題排查
工具
vmstat ——是一個常用的系統性能分析工具,主要用來分析系統的內存使用情況,也常用來分析CPU上下文切換和中斷的次數。
pidstat ——vmstat只給出了系統總體的上下文切換情況,要想查看每個進程的詳細情況,就需要使用pidstat,加上-w,可以查看每個進程上下文切換的情況。
/proc/interrupts——/proc實際上是linux的虛擬文件系統用于內核空間和用戶空間的通信,/proc/interrupts是這種通信機制的一部分,提供了一個只讀的中斷使用情況。
perf stat 可以統計很多和 CPU 相關核心數據,比如 cache' miss,上下文切換,CPI 等。
實 戰
vmstat:
#每隔1秒輸出1組數據(需要Ctrl+C才結束) $vmstat1 procs-----------memory-------------swap-------io-----system--------cpu----- rbswpdfreebuffcachesisobiboincsussyidwast 600648742811824012927720000901913988301684000 8006487428118240129277200001019113923121684000 cs(contextswitch)是每秒上下文切換的次數 in(interrupt)每秒中斷的次數 r (Running or Runnnable)是就緒隊列的長度,也就是正在運行和等待CPU的進程數。 b(Blocked)則是處于不可中斷睡眠狀態的進程數 分析: 查看cs大小(實驗時cs驟升到百萬) 同時注意r列(實驗時為8),機器cpu為1,遠遠超過1,必然會有大量的CPU競爭 us和sy列,計算cpu使用率總和(實驗加起來快100%,其中sy高達84%,說明cpu主要被內核占用) in列,查看大小(實驗中驟升到一萬,說明中斷處理也是潛在的問題) 綜合可知,系統的就需隊列過長,也就是正在運行和等待CPU的進程數過多,導致了大量的上下文切換,而上下文切換導致了cpu占用率高
pidstat查看進程上下文切換情況:
#每隔1秒輸出1組數據(需要Ctrl+C才結束) #-w參數表示輸出進程切換指標,而-u參數則表示輸出CPU使用指標 $pidstat-w-u1 08:06:33UIDPID%usr%system%guest%wait%CPUCPUCommand 08:06:3401048830.00100.000.000.00100.000sysbench 08:06:340263260.001.000.000.001.000kworker/u4:2 08:06:33UIDPIDcswch/snvcswch/sCommand 08:06:340811.000.00rcu_sched 08:06:340161.000.00ksoftirqd/1 08:06:3404711.000.00hv_balloon 08:06:34012301.000.00iscsid 08:06:34040891.000.00kworker/1:5 08:06:34043331.000.00kworker/0:3 08:06:340104991.00224.00pidstat 08:06:34026326236.000.00kworker/u4:2 08:06:34100026784223.000.00sshd cswch 表示每秒自愿上下文切換的次數,是指進程無法獲取所需資源,導致的上下文切換,比如說,I/O,內存等系統資源不足時,就會發生自愿上下文切換。 nvcswch 表示每秒非自愿上下文切換的次數,則是指進程由于時間片已到等原因,被系統強制調度,進而發生的上下文切換。 分析: pidstat查看果然是sysbench導致了cpu達到100%,但上下文切換來自其他進程,包括非自愿上下文切換最高的pidstat,以及自愿上下文切換最高的kworker和sshd 但pidtstat輸出的上下文切換次數加起來才幾百和vmstat的百萬明顯小很多,現在vmstat輸出的是線程,而pidstat加上-t后才輸出線程指標 #每隔1秒輸出一組數據(需要Ctrl+C才結束) #-wt參數表示輸出線程的上下文切換指標 $pidstat-wt1 08:14:05UIDTGIDTIDcswch/snvcswch/sCommand ... 08:14:05010551-6.000.00sysbench 08:14:050-105516.000.00|__sysbench 08:14:050-1055218911.00103740.00|__sysbench 08:14:050-1055318915.00100955.00|__sysbench 08:14:050-1055418827.00103954.00|__sysbench ... pidstat子線程加一起就差不多百萬了。
看中斷——可排查是哪些中斷引起的(變化速度最快的):
#-d參數表示高亮顯示變化的區域 $watch-dcat/proc/interrupts CPU0CPU1 ... RES:24504315279697Reschedulinginterrupts ...
觀察一段時間后,可以發現變化最快的是重新調度中斷(RES, REScheduling interrupt)。這種中斷類型表明處于空閑狀態的 CPU 被喚醒以調度新的任務運行。所以這里的中斷增加是因為太多的任務調度問題,這和前面上下文切換次數的分析結果是一致的。
現在回到最初的問題,每秒多少次上下文切換是正常的?
這個值實際上取決于系統本身的 CPU 性能。如果系統的上下文切換次數比較穩定的話,幾百到一萬應該是正常的。但是,當上下文切換次數超過10000,或者切換次數快速增加時,很可能是出現了性能問題。
perf stat 可以排查系統上下文切換速率變化:
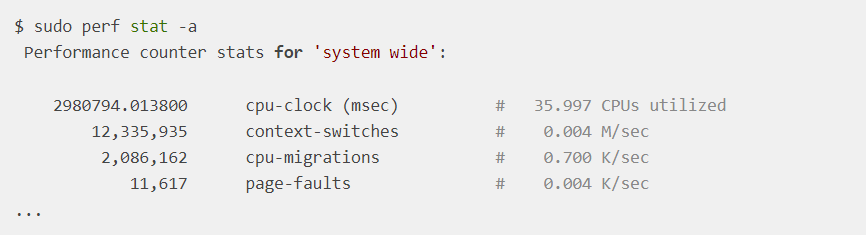
可以觀察 context-switcehes 數據的變化,有沒有突增,可以發現一些異常想象。
場 景
根據調度策略,將 CPU 時間劃片為對應的時間片,當時間片耗盡,當前進程必須掛起。
資源不足的,在獲取到足夠資源之前進程掛起。
進程 sleep 掛起進程。
高優先級進程導致當前進度掛起。
硬件中斷,導致當前進程掛起。
小 結
CPU 上下文切換,是保證 Linux 系統正常工作的核心功能之一,一般情況下不需要我們特別關注。
但過多的上下文切換,會把 CPU 時間消耗在寄存器,內核棧以及虛擬內存等數據的保存和恢復上,從而縮短進程真正運行的時間,導致系統的整體性能大幅下降。
自愿上下文切換變多了,說明進程都在等待資源,有可能發生了 I/O 等其他問題。
非自愿上下文切換變多了,說明進程都在被強制調度,也就是都在爭搶 CPU,說明 CPU 的確成了瓶頸。
中斷次數變多了,說明 CPU 被中斷處理程序占用,還需要通過查看 /proc/interrupts 文件來分析具體的中斷類型。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10878瀏覽量
212167 -
Linux
+關注
關注
87文章
11319瀏覽量
209830 -
計數器
+關注
關注
32文章
2256瀏覽量
94700
原文標題:詳細解讀 Linux CPU的上下文切換過程
文章出處:【微信號:嵌入式情報局,微信公眾號:嵌入式情報局】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
編寫一個任務調度程序,在上下文切換后遇到了一些問題求解
關于進程上下文、中斷上下文及原子上下文的一些概念理解
BT堆棧上下文切換
ucos上下文該怎么切換?
討論ARM mbed OS(RTX) 的上下文切換
rt-thread上下文切換函數的意義在哪?
中斷中的上下文切換詳解
CPU上下文切換的詳細資料講解
如何分析Linux CPU上下文切換問題
Linux CPU上下文切換
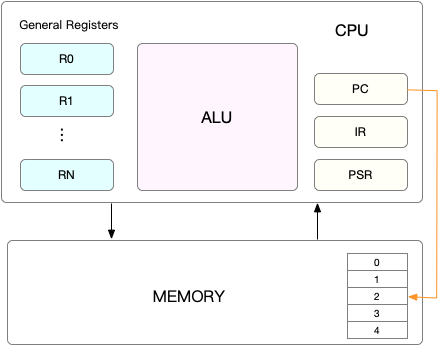
Linux技術:什么是cpu上下文切換






 工商網監
工商網監
評論