") JVM入門(mén)之歷代垃圾回收器 2
JVM入門(mén)之歷代垃圾回收器 2
CMS收集器
全稱(chēng):Concurrent Mark Sweep
特點(diǎn)
- 「采用標(biāo)記-清除算法實(shí)現(xiàn)」 2.和Parallel 系列的收集器注重點(diǎn)不同:
Parallel 注重吞吐量CMS注重STW的停頓時(shí)間
工作流程
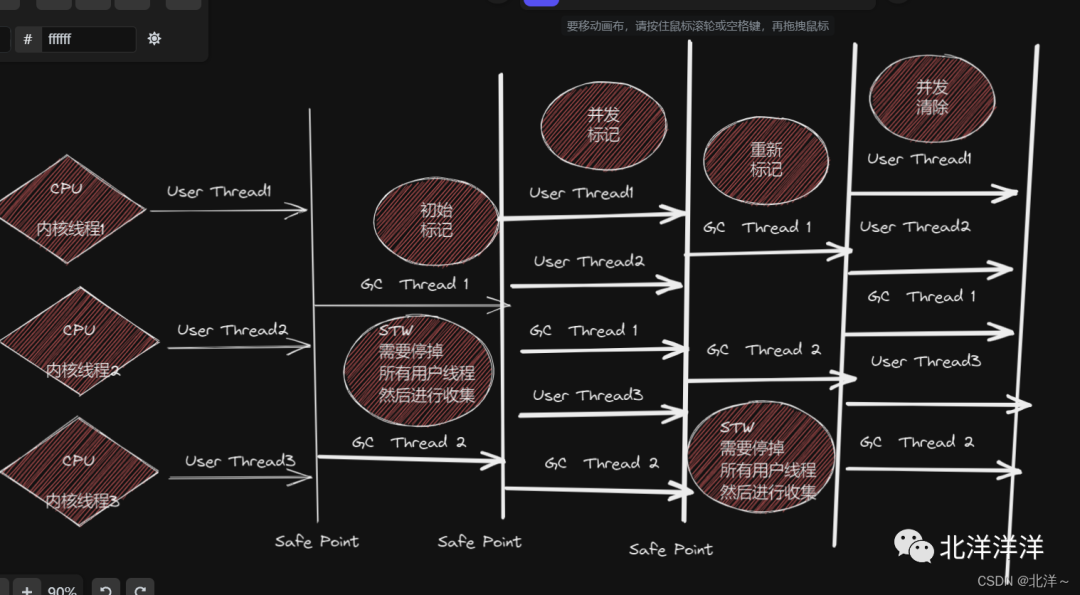
1.初始標(biāo)記
「CMS inital mark」
?
標(biāo)記GC Roots直接關(guān)聯(lián)的對(duì)象**「需要STW」**
?
2.并發(fā)標(biāo)記
CMS concurrent mark
?
根據(jù)上一步和GC Roots直接關(guān)聯(lián)的對(duì)象進(jìn)行遍歷整個(gè)堆里面的對(duì)象圖并進(jìn)行標(biāo)記,由于是并發(fā)的所以并 「不需要停頓用戶(hù)線程」 ,但是比較耗時(shí)因?yàn)楸闅v整個(gè)對(duì)象圖。
?
3.重新標(biāo)記
CMS remark
?
在并發(fā)標(biāo)記期間由于和用戶(hù)線程是并發(fā)的,所以這段期間用戶(hù)線程可能更新了引用,所以需要進(jìn)行一次修正(詳見(jiàn)上一篇文章中講到的 「增量更新」 ) 需要 「STW」 ,STW停頓時(shí)間比初始標(biāo)記時(shí)間長(zhǎng),但是并沒(méi)有并發(fā)標(biāo)記運(yùn)行時(shí)間長(zhǎng)
?
4.并發(fā)清除
?
清除刪掉被標(biāo)記為垃圾的對(duì)象,由于采用的是標(biāo)記-清除算法,所以并不需要移動(dòng)存活對(duì)象因此是可以并發(fā)的。(當(dāng)內(nèi)存碎片嚴(yán)重到不足以分配對(duì)象時(shí)其實(shí)還是需要進(jìn)行標(biāo)記-整理算法的,這個(gè)時(shí)候就會(huì)提前觸發(fā)FullGC。)
?
「注意」 :在并發(fā)階段產(chǎn)生的**“浮動(dòng)垃圾”**(并發(fā)時(shí)用戶(hù)線程產(chǎn)生的垃圾),需要等到下一次垃圾回收才能進(jìn)行清理;而且并發(fā)的時(shí)候需要預(yù)留一部分內(nèi)存空間供用戶(hù)線程使用,所以不能等到老年代完全用完在進(jìn)行清理。JDK5的默認(rèn)設(shè)置是當(dāng)老年代使用了65%的空間就會(huì)觸發(fā)GC。
G1 收集器
特點(diǎn)
思維方式的重大轉(zhuǎn)變:
?
G1之前的收集器都是分代收集的思想,根據(jù)不同的代采用不同的GC:新生代(Minor GC),老年代(Major GC),整個(gè)JAVA堆(Full GC)。
?
但是GC是根據(jù)哪塊內(nèi)存中垃圾數(shù)量多回收效益最大來(lái)區(qū)分的,面向的是堆內(nèi)存中的任意一塊內(nèi)存來(lái)組成回收集(Collection Set)進(jìn)行回收。
實(shí)現(xiàn)
?
基于Region的堆內(nèi)存布局來(lái)實(shí)現(xiàn)該回收過(guò)程。不再以固定大小及固定數(shù)量來(lái)劃分分代區(qū)域,而是把連續(xù)的堆內(nèi)存區(qū)域進(jìn)行劃分為各自獨(dú)立大小相等的區(qū)域(Region),每一個(gè)Region都可以根據(jù)需要扮演新生代中的Enen空間,Survivor空間,或者老年代。收集器根據(jù)扮演不同角色的Region采用不同策略去處理。
?
Region中有一類(lèi)特殊的Humongous區(qū)域,專(zhuān)門(mén)用來(lái)存儲(chǔ)大對(duì)象。
G1認(rèn)為一個(gè)對(duì)象的大小超過(guò)了一個(gè)Region空間的一半就認(rèn)為該對(duì)象是大對(duì)象,如果超過(guò)了整個(gè)Region空間的超大對(duì)象將會(huì)被存放在連續(xù)的Humongous Region中,因此該區(qū)域一般會(huì)被作為老年代看待。
優(yōu)點(diǎn)
「1.建立可預(yù)測(cè)的停頓時(shí)間模型」 :由于采用的是Region,因此回收單元作為Region即每次回收都是Region大小的整數(shù)倍。
G1會(huì)跟蹤Region區(qū)域里面垃圾堆,計(jì)算出價(jià)值(回收所獲得的空間大小以及回收所需時(shí)間的經(jīng)驗(yàn)值),接著在后臺(tái)維護(hù)一個(gè)優(yōu)先級(jí)列表,根據(jù)用戶(hù)設(shè)置的允許停頓時(shí)間來(lái)進(jìn)行回收價(jià)值最大的Region區(qū)域。也就是“Garbage First” 的由來(lái)。
「2.內(nèi)存碎片」 整體上采用的是標(biāo)記-整理,但是在兩個(gè)Region中實(shí)際上還是采用的復(fù)制算法,所以不會(huì)出現(xiàn)內(nèi)存碎片問(wèn)題。
缺點(diǎn)
「1.浪費(fèi)額外內(nèi)存來(lái)維護(hù)收集器工作」
跨代引用避免全堆掃描之前說(shuō)過(guò)是采用 「記憶集」 的方式來(lái)解決,在G1中也一樣。每個(gè)Region中都有自己的記憶集 「但是」 在G1中每個(gè)Region除了需要記錄別的Region指向自己的指針,還需要標(biāo)記這些指針?lè)謩e在哪些卡頁(yè)范圍內(nèi)。其實(shí)本質(zhì)上說(shuō)是哈希表,Key是別的Region的起始地址,Value是一個(gè)集合存儲(chǔ)的元素是卡表的索引號(hào)。因此實(shí)現(xiàn)起來(lái)比原有的記憶集要復(fù)雜,而且Region的數(shù)量比之前的分代數(shù)量要多得多,所以記憶集的維護(hù)占用了更高的內(nèi)存
?
G1至少要耗費(fèi)大約相當(dāng)于JAVA堆容量的10%到20%來(lái)存儲(chǔ)維持收集器正常工作
?
「2.不僅用到寫(xiě)后屏障還用到了寫(xiě)前屏障」
上一小點(diǎn)中已經(jīng)講到維護(hù)卡表是需要進(jìn)行添加寫(xiě)后屏障來(lái)完成更新卡表的操作的,但是G1還用到了寫(xiě)前屏障:由于使用的是原始快照來(lái)保證可以進(jìn)行并發(fā)標(biāo)記的基礎(chǔ),對(duì)比與增量更新來(lái)說(shuō)雖然能夠減少最終標(biāo)記的停頓時(shí)間,但是相比于收集器,這款收集器不僅采用了寫(xiě)前屏障也采用了寫(xiě)后屏障導(dǎo)致最終的效率降低
工作流程
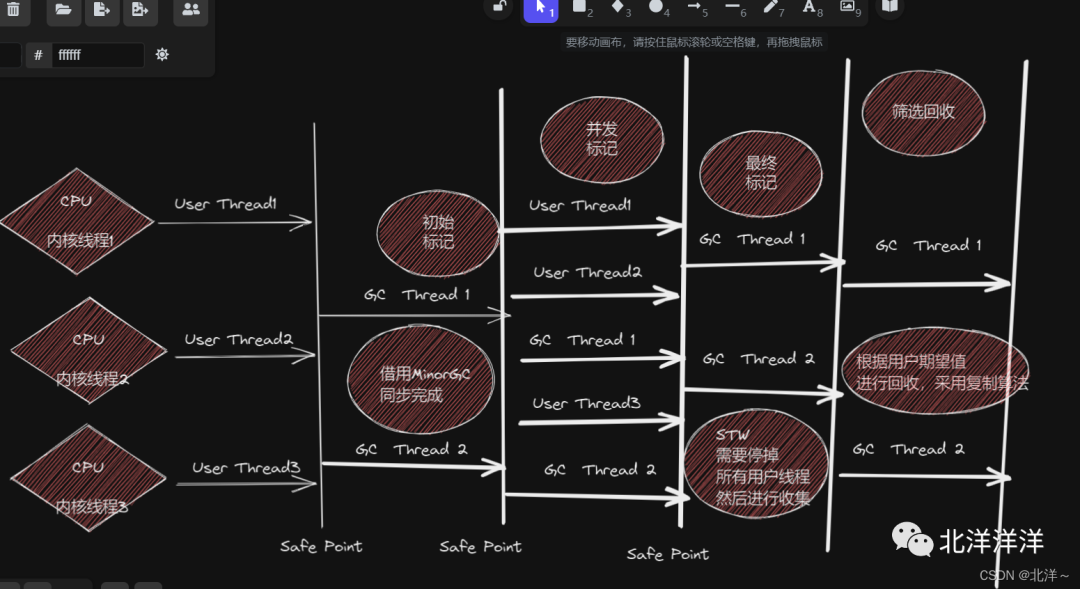
與之前不同的是 「最后一處」 ,這個(gè)步驟需要進(jìn)行 「更新Region的統(tǒng)計(jì)數(shù)據(jù),對(duì)所有的Region的回收價(jià)值和成本進(jìn)行排序,然后根據(jù)用戶(hù)設(shè)定的期望停頓時(shí)間進(jìn)行決定選擇哪幾個(gè)Region構(gòu)成回收集,然后將一部分的Region中存活對(duì)象復(fù)制到另外一個(gè)空的Region空間中,隨后進(jìn)行清理掉整個(gè)舊的Region空間」 。是不是復(fù)制算法(針對(duì)與Region來(lái)說(shuō)),因?yàn)樯婕皩?duì)象移動(dòng),所以需要 「暫停用戶(hù)線程」 。
總結(jié)
到此,如果讀者之前閱讀過(guò)筆者之前的關(guān)于垃圾回收器講解的文章,其實(shí)已經(jīng)對(duì)現(xiàn)在大多數(shù)垃圾回收器機(jī)制和實(shí)現(xiàn)原理了解的差不多了,讀者有興趣可以自行去看Shenandoah收集器和ZGC收集器,本文不在敘述,主要確實(shí)文章內(nèi)容有點(diǎn)太長(zhǎng)了哈哈。后面的文章將不在分析垃圾回收器的知識(shí),但是還是會(huì)更新關(guān)于JVM的文章。
-
GC
+關(guān)注
關(guān)注
0文章
9瀏覽量
17083 -
cms
+關(guān)注
關(guān)注
0文章
59瀏覽量
10964 -
JVM
+關(guān)注
關(guān)注
0文章
158瀏覽量
12220 -
收集器
+關(guān)注
關(guān)注
0文章
30瀏覽量
3134
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
固態(tài)硬盤(pán)垃圾回收方法
Jvm垃圾回收機(jī)制及性能調(diào)優(yōu)實(shí)戰(zhàn)
帶顏色的JVM垃圾回收三色標(biāo)記法
詳解JVM的垃圾回收算法和垃圾回收器
JVM入門(mén)之歷代垃圾回收器 1
JVM入門(mén)之關(guān)于GC的擴(kuò)展知識(shí)1

JVM入門(mén)之關(guān)于GC的擴(kuò)展知識(shí)2

JVM入門(mén)之垃圾回收算法

詳細(xì)解析JVM中的垃圾回收機(jī)制
垃圾收集器的JVM參數(shù)配置
jvm參數(shù)的設(shè)置和jvm調(diào)優(yōu)
jvm配置的mx
智能垃圾回收箱控制系統(tǒng)硬件設(shè)計(jì)

智能垃圾回收箱功能實(shí)驗(yàn)
從原理聊JVM(一):染色標(biāo)記和垃圾回收算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論