 爆紅智能AI如何看待DPU
爆紅智能AI如何看待DPU
上線僅2個月,OpenAI的最新一代產品-AI聊天機器人ChatGPT月活用戶接近1億。
作為自然語言處理(NLP)領域的前沿研究成果之一,ChatGPT已成為AIGC里程碑式的產品。
這周我們也與ChatGPT聊了聊他/她對大規模預訓練背后所需資源的看法。
讓我們一起來看看ChatGPT的回答是否能讓你滿意呢?
強大的語言生成能力現在引起更多討論的是規模預訓練。在過去的很長一段時間里,許多的AI廠商都是通過本地設備來進行訓練的。
GPT-3所訓練的參數約為1750億個,這部分需要大量的算力,而目前我們已知ChatGPT導入了至少1萬顆英偉達高端GPU來訓練模型。
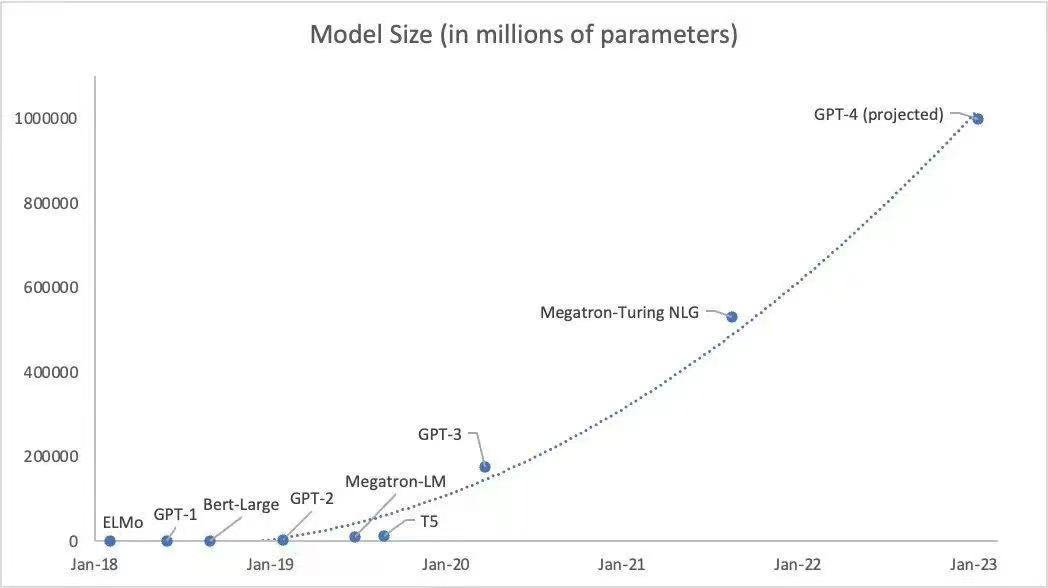

業界部分專家認為GPT-4訓練參數可能會達到100萬億個參數,如此大規模、長時間的GPU集群訓練任務,也對網絡互聯底座的性能、可靠性、成本等各方面都提出了極致的要求。
面對千億、萬億參數規模的大模型訓練,僅僅是單次計算迭代內梯度同步需要的通信量就高達TB量級。此外還有各種并行模式、加速框架引入的通信需求,使得傳統低速網絡的帶寬遠遠無法支撐GPU集群的高效計算,甚至成為了其中關鍵的瓶頸。
因此要充分發揮GPU計算資源的強大算力,必須構建一個全新的高性能網絡底座,用高速網絡的大帶寬來助推整個集群計算的高效率。
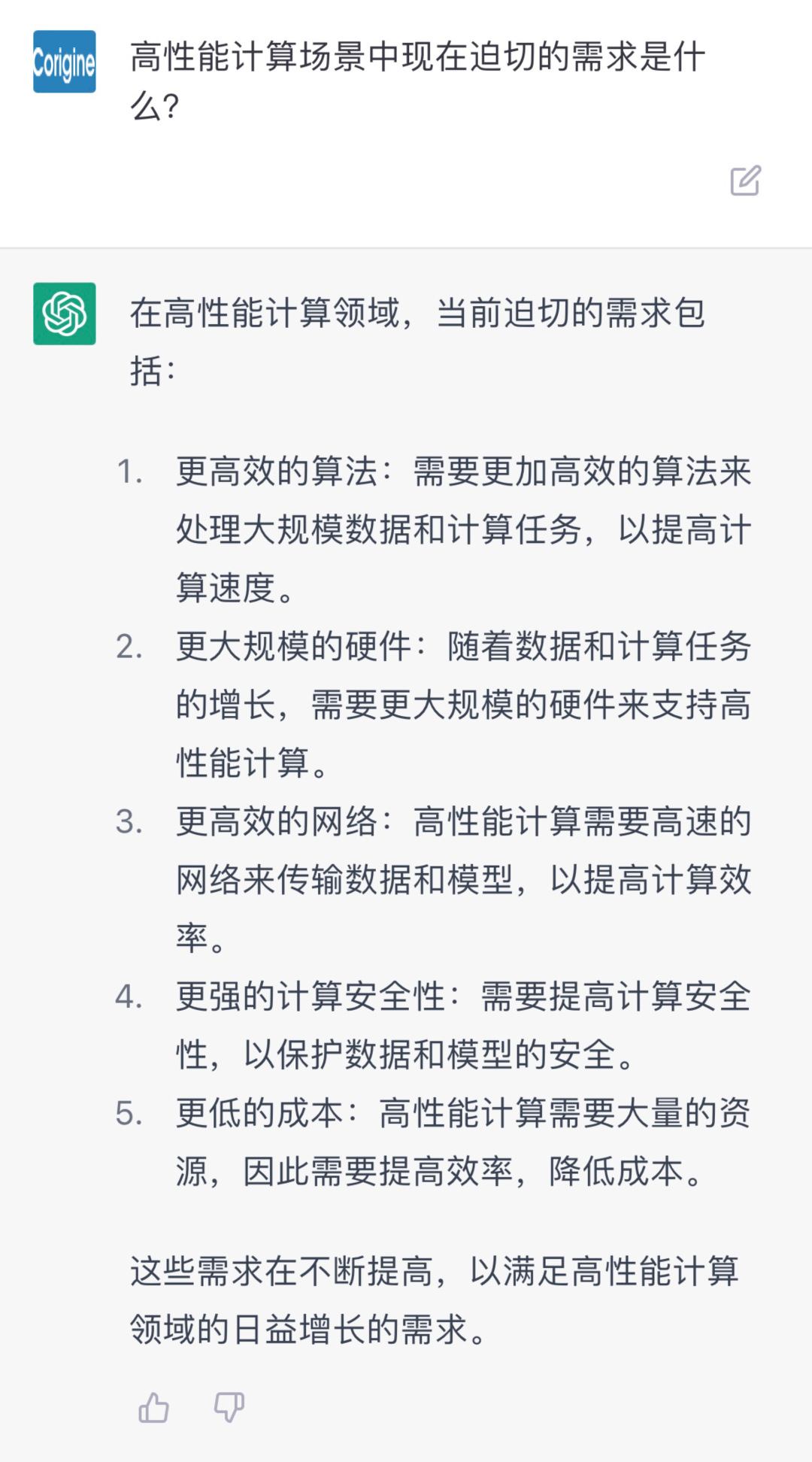
以CPU+GPU的異構計算模型已經成為高性能計算領域中的主流計算架構。而高吞吐、低延時是高性能計算場景中最為迫切的應用需求。
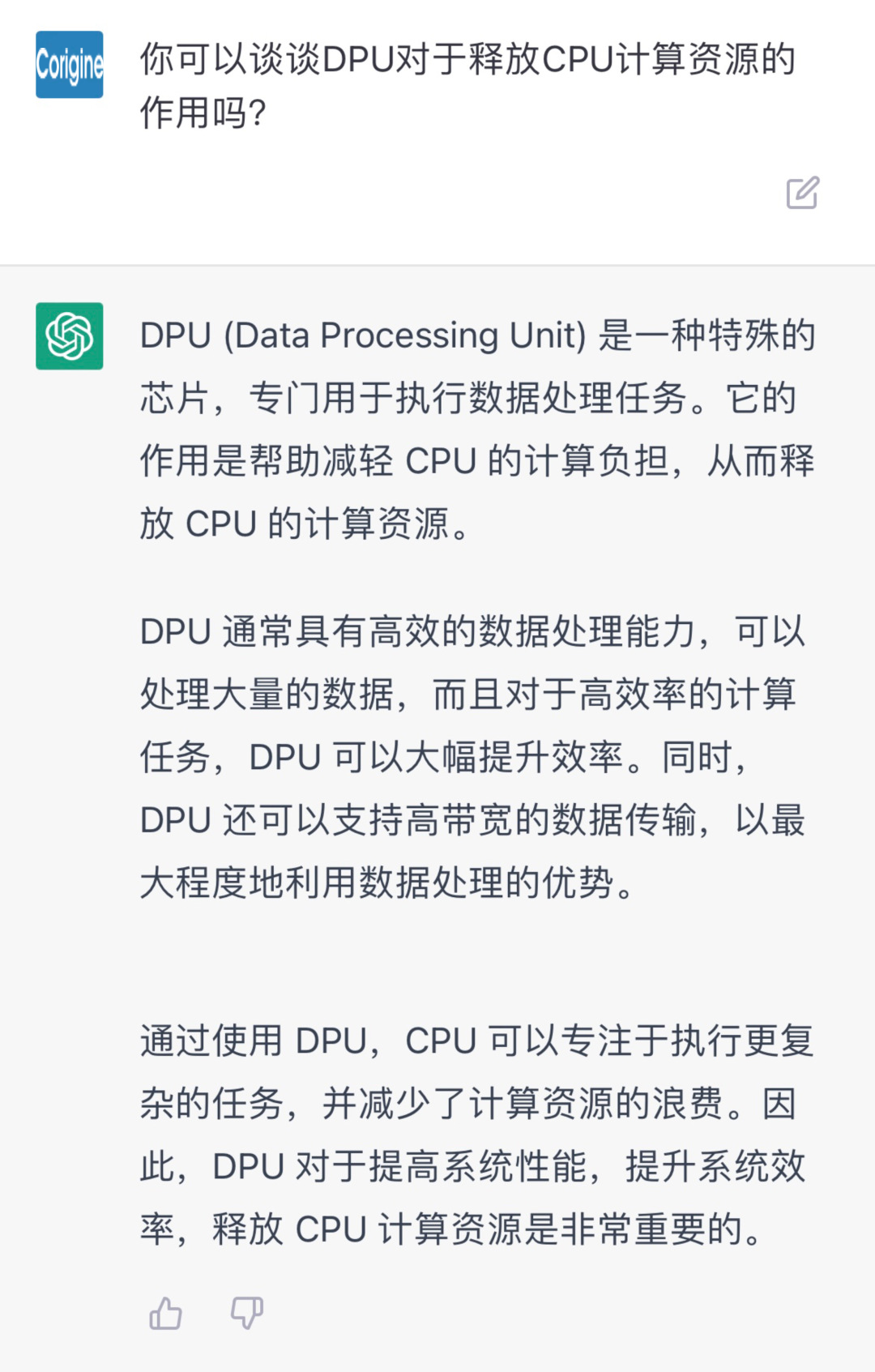
我們可以知道,GPUDirect RDMA是RDMA在異構計算場景中的應用延伸,使得GPU之間的通信不在依賴CPU轉發,從而進一步提升高性能計算場景中整體算力。
從DPU芯片的實現角度看,不同DPU廠商的核心競爭壁壘在于專用加速引擎的硬件實現上。由于DPU是數據中心中所有服務器的流量入口,并以處理報文的方式處理數據,在網絡芯片領域積累更多的廠商將更有優勢。
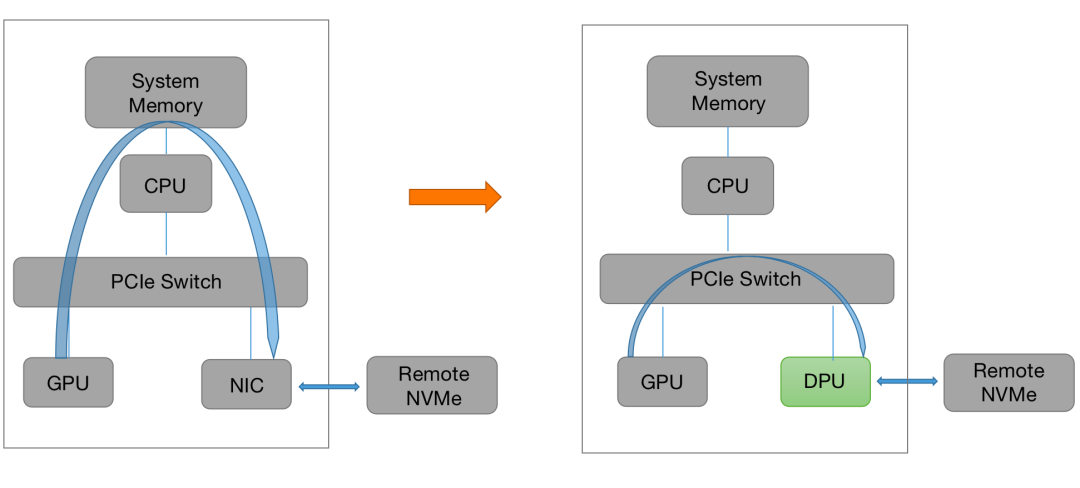
傳統的GPU在訪問存儲時,需要將數據先搬移到系統內存,再由系統內存搬移到目標設備。而采用DPU介入后可以繞過CPU,直接通過PCIe訪問遠端的NVMe設備,加速AI訓練,大大降低CPU的開銷。
在AI/ML領域的工作負載對于存儲系統的要求十分苛刻,目前此類應用已主要采用全閃存存儲,其中NVMe全閃存逐漸成為主流趨勢。同時存儲與前端應用主機的網絡存儲協議開始采用NVMe over Fabrics(NVMe-oF)。
NVMe-oF是一種存儲網絡協議,通過網絡將NVMe命令傳送到遠程NVMe子系統,以利用NVMe 全閃存的并行訪問和低延遲,該規范定義了一個協議接口,旨在與高性能fabric技術配合使用,包括通過實現RDMA技術的InfiniBand、RoCE v2、iWARP或TCP。
NVMe-oF是一種使用NVMe協議將訪問擴展到遠程存儲系統的非易失性存儲器(NVM)設備的方法。這使得前端接口能夠連接到存儲系統中,擴展到大量NVMe設備,并延長數據中心內可以訪問NVMe子系統的距離。NVMe-oF的目標是顯著改善數據中心網絡延遲,并為遠程NVMe設備提供近似于本地訪問的延遲,目標為10us。
我們知道AI對計算的需求非常大,目前主流的AI加速還是以GPU、FPGA和一些專門的AI芯片等為主。在GPU、AI芯片用于AI計算之前都是CPU承擔計算的任務,CPU的效率難以滿足需求,從而產生CPU+GPU+ASIC的異構計算。隨著DPU的出現,這種異構計算的發展更加徹底,可以更大提供并行處理能力,適合大規模計算的發展。
支持Chiplet技術的超異構算力芯片,伴隨著AI/ML的發展將會得到更好的應用,而支持Die-To-Die互聯技術將能夠提供互聯其他AI芯片和算力單元的巨大能力,擺脫一直以來PCIe發展的限制。 ??拿芯啟源自身舉例,以支持高級AI為主要目標之一的芯啟源最新的DPU芯片,其架構中就應用Chiplet技術。不僅提升了自有智能網卡的性能,通過支持與第三方芯片的Die-To-Die互聯,還可以集成更多的特定專業領域的芯片,比如AI訓練中的GPU芯片。
雖然PCIe非常的標準,但是帶寬非常有限的,PCIe Gen3的理論帶寬是32GB/s,PCIe Gen4的理論帶寬是64GB/s,而實測帶寬大概分別是24GB/s和48GB/s。
在AI訓練中,每完成一輪計算,都要同步更新一次參數,也就是權系數。模型規模越大,參數規模一般也會更大,這樣算力芯片的效率會收到PCIe架構的限制,支持更高能力層次的互聯技術講徹底解決帶寬限制和瓶頸,極大提升單節點計算效率。
和ChatGPT聊了那么多,最后再讓我們來看看他/她對于DPU應用了解多少呢?

審核編輯 :李倩
-
AI
+關注
關注
87文章
30747瀏覽量
268899 -
DPU
+關注
關注
0文章
357瀏覽量
24169 -
chiplet
+關注
關注
6文章
431瀏覽量
12585
原文標題:爆紅智能AI如何看待DPU ChatGPT這樣說
文章出處:【微信號:corigine,微信公眾號:芯啟源】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI智能網卡在AI網絡中的作用
紅魔9S Pro+ AI游戲手機實力如何
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
人工智能ai4s試讀申請
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
紅魔9S Pro系列AI游戲手機正式發布
DPU技術賦能下一代AI算力基礎設施
明天線上見!DPU構建高性能云算力底座——DPU技術開放日最新議程公布!
發布行業首款AI大模型三攝智能鎖,全系列產品AI加持,螢石2024春季新品發布會很AI






 工商網監
工商網監
評論