") 一文解讀人工智能產(chǎn)業(yè)鏈
一文解讀人工智能產(chǎn)業(yè)鏈
近幾年來,人工智能行業(yè)飛速發(fā)展。麥肯錫預測人工智能可在未來十年為全球GDP增長貢獻1.2個百分點,為全球經(jīng)濟活動增加13萬億美元產(chǎn)值,其貢獻率可以與歷史上第一次“工業(yè)革命”中蒸汽機等變革技術的引入相媲美。
從產(chǎn)業(yè)鏈來看,人工智能可以分為技術支撐層、基礎應用層和產(chǎn)品層,各層面環(huán)環(huán)相扣,基礎層和支撐層提供技術運算的平臺、資源、算法,應用層的發(fā)展離不開基礎層和技術的應用。
人工智能產(chǎn)業(yè)鏈

資料來源:凱聯(lián)資本投研部
基礎層分為硬件和軟件。硬件即具備儲存、運算能力的芯片,以及獲取外部數(shù)據(jù)信息的傳感器;軟件則為用以計算的大數(shù)據(jù)。這里我們著重分析硬件部分的智能芯片。
1、智能芯片
按技術架構來看,智能芯片可分為通用類芯片(CPU、GPU、FPGA)、基于FPGA的半定制化芯片、全定制化ASIC芯片、類腦計算芯片(IBMTureNorth)。對于絕大多數(shù)智能需求來說,基于通用處理器的傳統(tǒng)計算機成本高、功耗高、體積大、速度慢,難以接受。因此以CPU、GPU、FPGA、ASIC和類腦芯片為代表的計算芯片以高性能計算能力被引入深度學習。
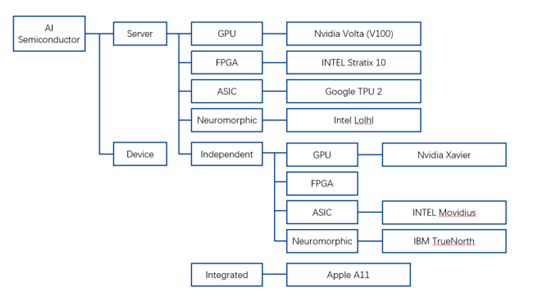
資料來源:谷歌,凱聯(lián)資本投研部
2017年各AI企業(yè)公開芯片數(shù)據(jù)
資料來源:中國科學院自動化研究所,凱聯(lián)資本投研部
(1)GPU
大規(guī)模數(shù)據(jù)量下,傳統(tǒng)CPU運算性能受限。遵循的是馮諾依曼架構,其核心就是:存儲程序,順序執(zhí)行。隨著摩爾定律的推進以及對更大規(guī)模與更快處理速度的需求的增加,CPU執(zhí)行任務的速度受到限制。GPU在計算方面具有高效的并行性。用于圖像處理的GPU芯片因海量數(shù)據(jù)并行運算能力,被最先引入深度學習。CPU中的大部分晶體管主要用于構建控制電路(如分支預測等)和Cache,只有少部分的晶體管來完成實際的運算工作。GPU 與 CPU 的設計目標不同,其控制電路相對簡單,而且對Cache的需求較小,所以大部分晶體管可以組成各類專用電路和多條流水線,使GPU的計算速度有了突破性的飛躍,擁有驚人的處理浮點運算的能力。
GPU與CPU結構對比
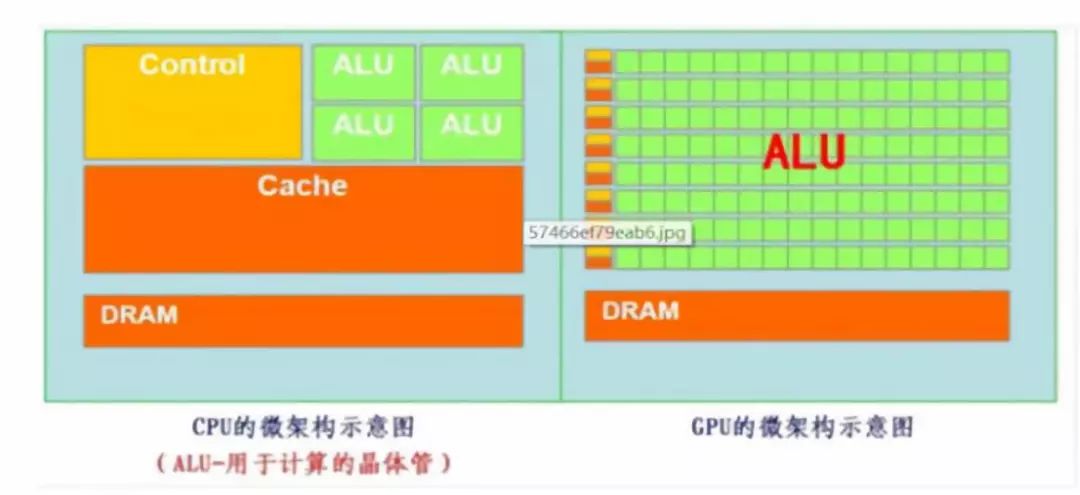
資料來源:谷歌,凱聯(lián)資本投研部
(2)FPGA
FPGA(可編程門陣列,F(xiàn)ield Programmable GateArray)是一種集成大量基本門電路及存儲器的芯片,最大特點為可編程。可通過燒錄FPGA配置文件來來定義這些門電路及存儲器間的連線,從而實現(xiàn)特定的功能。此外可以通過即時編程燒入修改內(nèi)部邏輯結構,從而實現(xiàn)不同邏輯功能。FPGA具有能耗優(yōu)勢明顯、低延時和高吞吐的特性。不同于采用馮諾依曼架構的CPU與GPU,F(xiàn)PGA 主要由可編程邏輯單元、可編程內(nèi)部連接和輸入輸出模塊構成。FPGA每個邏輯單元的功能和邏輯單元之間的連接在寫入程序后就已經(jīng)確定,因此在進行運算時無需取指令、指令譯碼,邏輯單元之間也無需通過共享內(nèi)存來通信。因此,盡管FPGA主頻遠低于CPU,但完成相同運算所需時鐘周期要少于CPU,能耗優(yōu)勢明顯,并具有低延時、高吞吐的特性。
FPGA結構圖
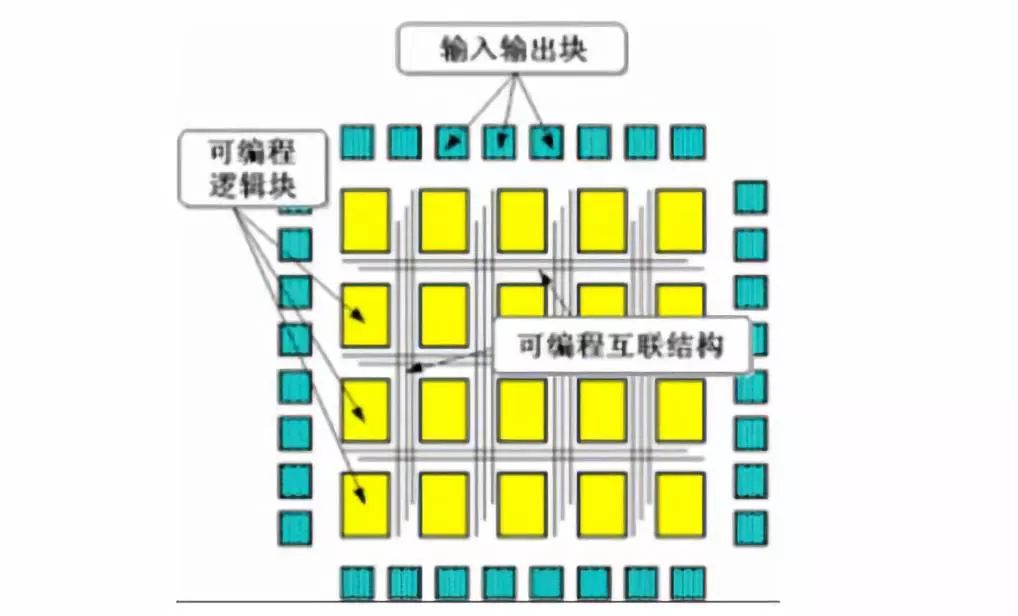
資料來源:谷歌,凱聯(lián)資本投研部
(3)ASIC
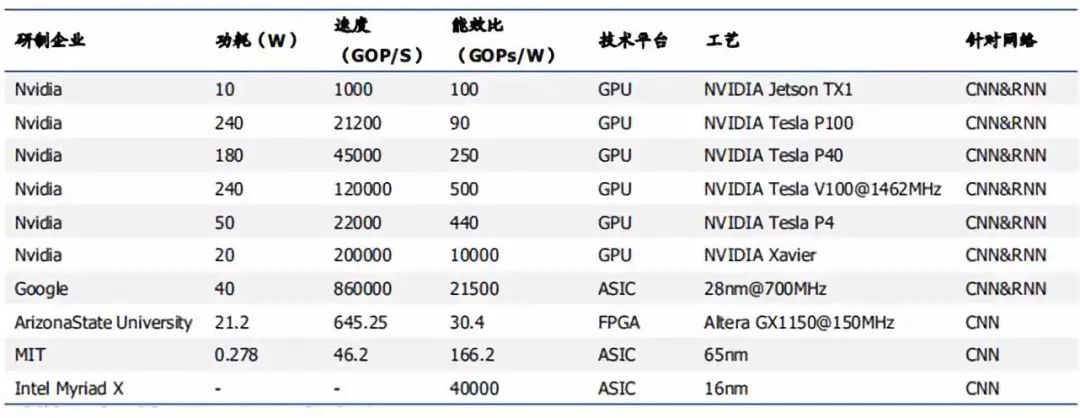
ASIC 芯片是專用定制芯片,為實現(xiàn)特定要求而定制的芯片。除了不能擴展以外,在功耗、可靠性、體積方面都有優(yōu)勢,尤其在高性能、低功耗的移動端。谷歌的TPU、寒武紀的GPU,地平線的BPU都屬于ASIC芯片。谷歌的TPU比CPU和GPU的方案快30-80倍,與CPU和GPU相比,TPU把控制縮小了,因此減少了芯片的面積,降低了功耗。其缺點在于開發(fā)周期長、投入成本大,一般公司難以承擔。
張量處理器(tensor processing unit,TPU)是Google為機器學習定制的專用芯片(ASIC),專為Google的深度學習框架TensorFlow而設計。與GPU相比,TPU采用低精度(8 位)計算,以降低每步操作使用的晶體管數(shù)量。降低精度對于深度學習的準確度影響很小,但卻可以大幅降低功耗、加快運算速度。Google在2016年首次公布了TPU。2017年公布第二代TPU,并將其部署在Google云平臺之上,第二代TPU的浮點運算能力高達每秒180 萬億次。
AI芯片主要性能對比
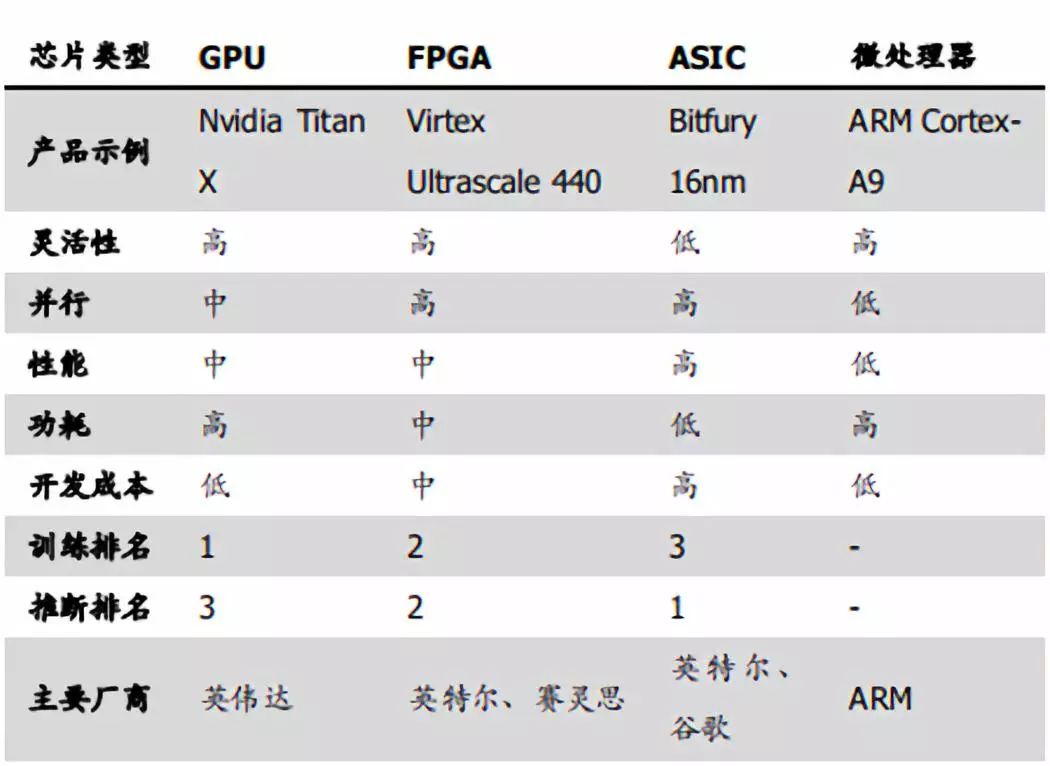
資料來源:學術論文,凱聯(lián)資本投研部
2、智能芯片架構
架構創(chuàng)新是解決成本不斷上漲的關鍵。隨著市場對芯片計算能力的需求提高,芯片制造工藝也在不斷提高,與之而來的是芯片制造成本不斷漲高,解決這個問題的關鍵則是架構創(chuàng)新。目前 AI 芯片主要架構有CPU+GPU、CPU+FPGA、CPU+ASIC等。
主流AI處理器的制程和架構
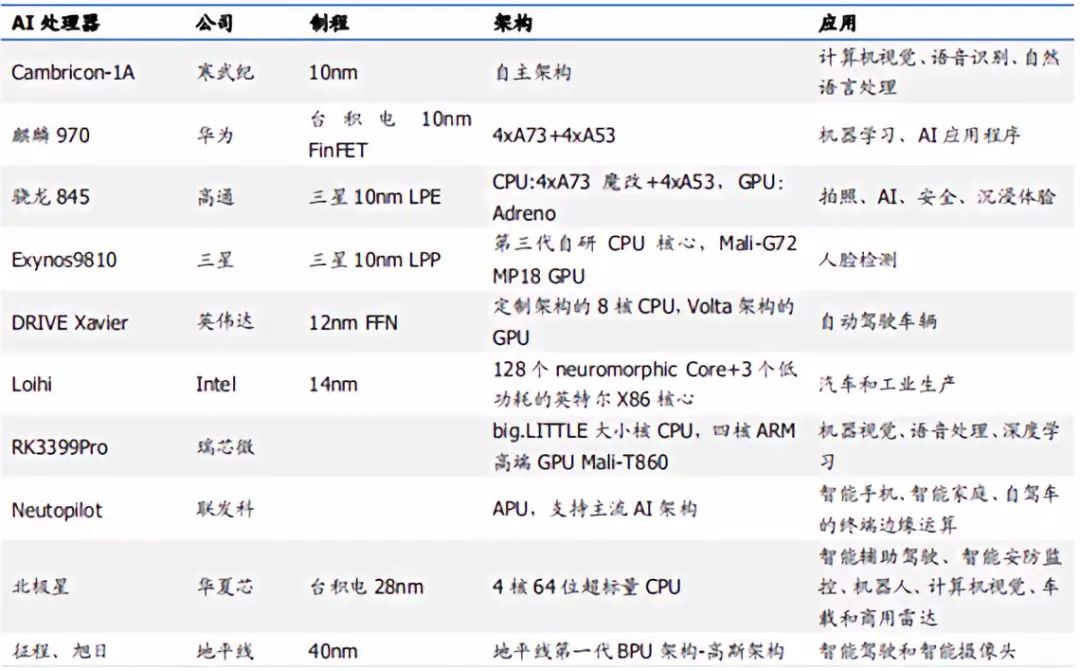
資料來源:電子發(fā)燒友,凱聯(lián)資本投研部
3、智能芯片的應用
深度學習主要分為訓練和推斷兩個環(huán)節(jié):在數(shù)據(jù)訓練(training)階段,大量的標記或者未標記的數(shù)據(jù)被輸入深度神經(jīng)網(wǎng)絡中進行訓練,隨著深度神經(jīng)網(wǎng)絡模型層數(shù)的增多,與之相對應的權重參數(shù)成倍的增長,從而對硬件的計算能力有著越來越高的需求,此階段的設計目標是高并發(fā)高吞吐量。
推斷(inference)則分為兩大類——云側推斷與端側推斷,云側推斷推斷不僅要求硬件有著高性能計算,更重要的是對于多指令數(shù)據(jù)的處理能力。就比如Bing搜索引擎同時要對數(shù)以萬計的圖片搜索要求進行識別推斷從而給出搜索結果;端側推斷更強調(diào)在高性能計算和低功耗中尋找一個平衡點,設計目標是低延時低功耗。
因此從目前市場需求來看,人工智能芯片可以分為三個類別:
1) 用于訓練(training)的芯片:主要面向各大AI企業(yè)及實驗室的訓練環(huán)節(jié)市場。目前被業(yè)內(nèi)廣泛接受的是“CPU+GPU”的異構模式,由于AMD在通用計算以及生態(tài)圈構建方面的長期缺位,導致了在深度學習GPU加速市場 NVIDIA一家獨大。面臨這一局面,谷歌今年發(fā)布TPU2.0 能高效支持訓練環(huán)節(jié)的深度網(wǎng)絡加速。我們在此后進行具體分析;
2) 用于云側推斷(inferenceoncloud)的芯片:在云端推斷環(huán)節(jié),GPU不再是最優(yōu)的選擇,取而代之的是,目前 3A(阿里云、Amazon、微軟 Azure)都紛紛探索“云服務器+FPGA”模式替代傳統(tǒng)CPU以支撐推斷環(huán)節(jié)在云端的技術密集型任務。但是以谷歌TPU為代表的ASIC也對云端推斷的市場份額有所希冀;
3) 用于端側推斷(inferenceondevice)的芯片:未來在相當一部分人工智能應用場景中,要求終端設備本身需要具備足夠的推斷計算能力,而顯然當前ARM等架構芯片的計算能力,并不能滿足這些終端設備的本地深度神經(jīng)網(wǎng)絡推斷,業(yè)界需要全新的低功耗異構芯片,賦予設備足夠的算力去應對未來越發(fā)增多的人工智能應用場景。我們預計在這個領域的深度學習的執(zhí)行將更多的依賴于ASIC。
-
FPGA
+關注
關注
1630文章
21761瀏覽量
604386 -
人工智能
+關注
關注
1792文章
47443瀏覽量
239020 -
智能芯片
+關注
關注
0文章
138瀏覽量
25255
原文標題:人工智能產(chǎn)業(yè)鏈深度解讀(基礎層)
文章出處:【微信號:CADCAM_beijing,微信公眾號:智能制造IMS】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
啟明云端攜手文心大模型,共探人工智能新紀元

嵌入式和人工智能究竟是什么關系?
58大新質(zhì)生產(chǎn)力產(chǎn)業(yè)鏈圖譜






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論