


依據客戶真實需求,定制下一代CPU是我們的工作之一,我們選擇做視頻轉碼的另一個原因,是為了設計更好滿足音視頻領域需求的下一代硬件。所以今天還會給大家介紹下一代CPU中關于編解碼的特殊指令,這些特殊指令可以加速編碼效率。
今天,我分享的內容分為三個章節。首先,使用英特爾豐富的工具鏈對視頻轉碼進行分析。我們作為硬件廠商,本身不做音視頻轉碼業務,但俗話說“弄斧要到班門”,所以我們首先對視頻轉碼的一些典型場景進行了微架構層面的分析,為后面的優化做好鋪墊。然后,介紹方案的核心思想,即如何重用一次編碼的信息來提高二次編碼的效率。之前提到,計算復雜度在轉碼里占了很大的成本,所以要從源頭上降低計算復雜度。最后,介紹SIMD指令集。SIMD的全稱是Single Instruction Multiple Data,意思是單指令多數據,表明一條指令可以同時操作多個數據。
01 視頻轉碼分析
首先,我們對視頻轉碼進行分析。
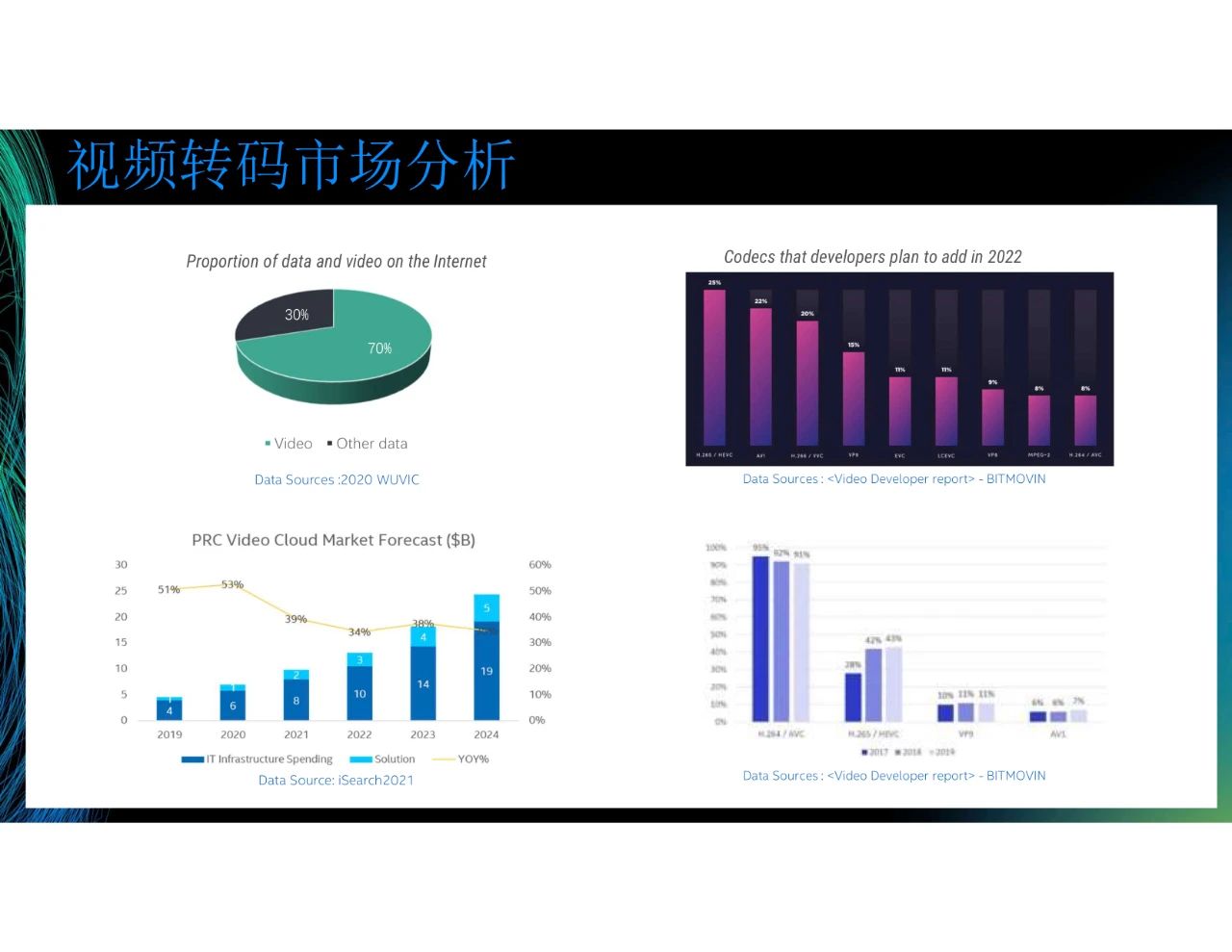
我們從相關市場獲取了圖中的數據。第一張圖表示在2020年,視頻數據在互聯網數據占比70%。到現在,視頻數據在互聯網數據占比已超過80%。第二張圖是PRC Video Cloud Market Forecast,圖中呈增長趨勢。雖然目前共有云市場的增速減緩,但是視頻云的增長仍有很大潛力。回到轉碼本身,第三張圖和第四張圖來自Video Developer report。從第四張圖可以看到,在2019年,H.264仍是主流視頻編碼技術,90%以上仍使用H.264。其次,較多使用的是H.265,然后是VP9和AV1,H.265也在逐漸成為一種趨勢。第三張圖表示視頻編碼器開發人員計劃在2022年投入的情況。其中,投入最多的是H.265,然后是AV1,再然后是H.266,這三個協議正在成為主流編碼器協議,我們后續將基于這些主流編碼器進行開發。
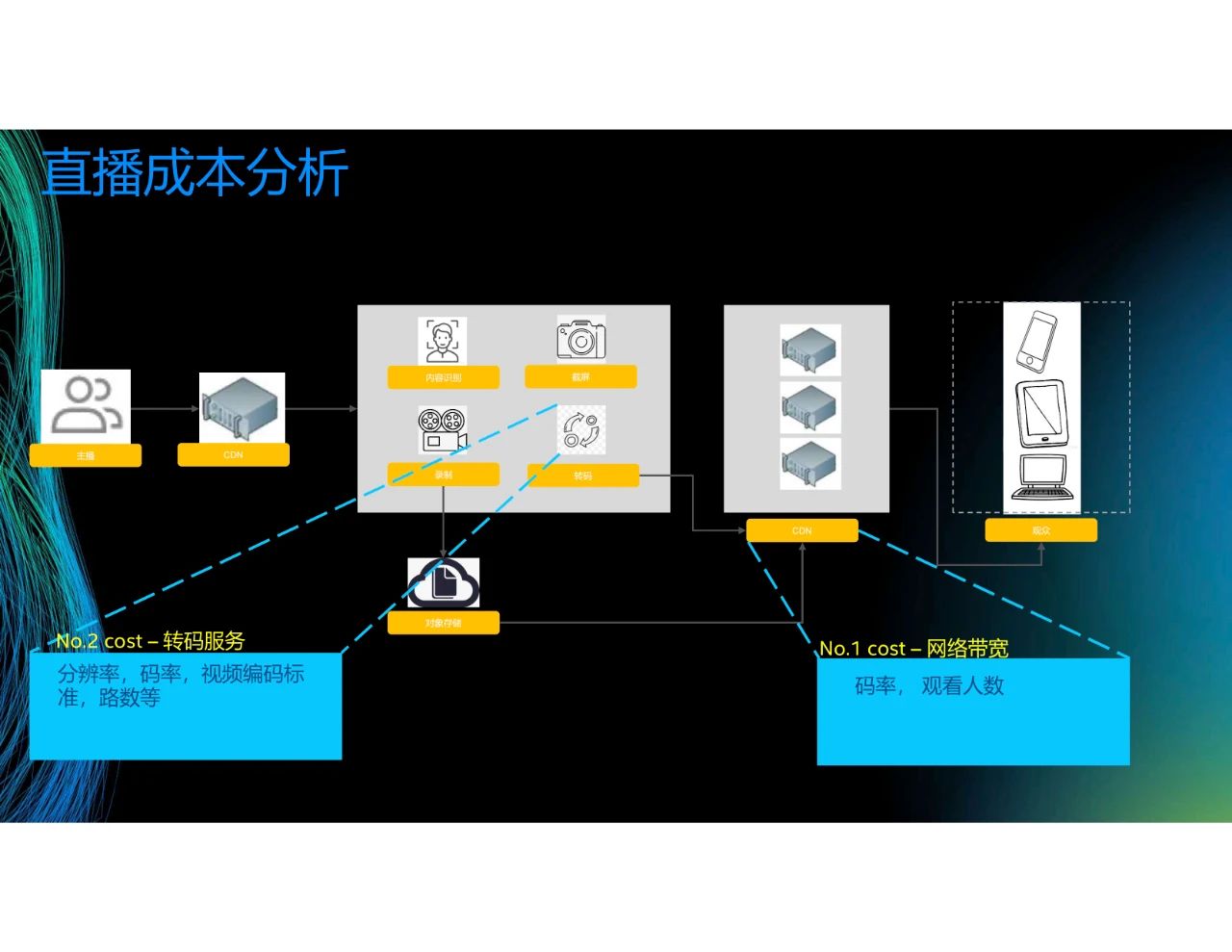
接下來進行直播成本分析。這是一張直播的結構圖,主播上傳內容到上行CDN,然后再發送到轉碼中心進行內容識別、截屏、錄制和轉碼,接著再分發到下行CDN。這個過程中,成本最大的是網絡帶寬和轉碼服務器。之前提到,網絡帶寬取決于觀看人數和碼率。舉個例子,觀看2M的視頻和觀看500K的視頻所需的網絡帶寬不同,1000個人同時觀看視頻和10個人同時觀看視頻所需的網絡帶寬也不同。轉碼服務取決于分辨率、碼率和視頻編碼標準等。
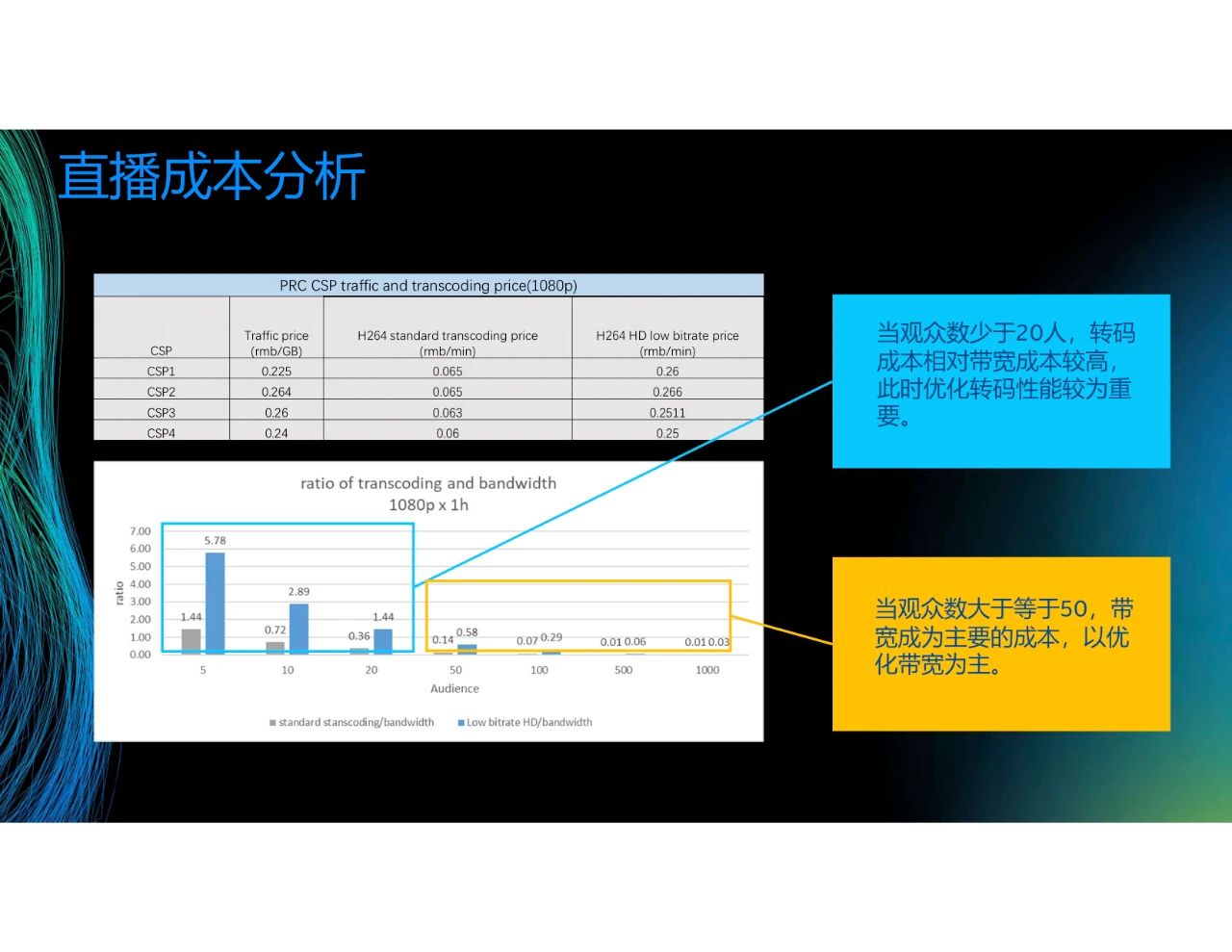
我們對頭部的互聯網廠商進行了分析。如第一張圖所示,主要有兩個成本,一個是Traffic price,即帶寬成本,另一個是轉碼成本。第二張圖表示直播一小時內,轉碼和帶寬的比例,圖的橫軸是觀看人數,縱軸是轉碼和帶寬費用的比例。可以看到,當觀眾數大于等于50時,帶寬成為主要的成本。舉個例子,頂級流量主播的一場直播的帶寬成本要幾百萬,此時轉碼成本只有幾千塊,相對帶寬成本幾乎可以忽略。但對于數量眾多的小主播來講,觀眾數可能只有十幾個,此時的帶寬較低,所以轉碼成本成為主要的成本。針對這兩種情況,在帶寬成本較大時,我們以優化帶寬為主,在轉碼成本較大時,我們以優化轉碼速度/轉碼性能為主。
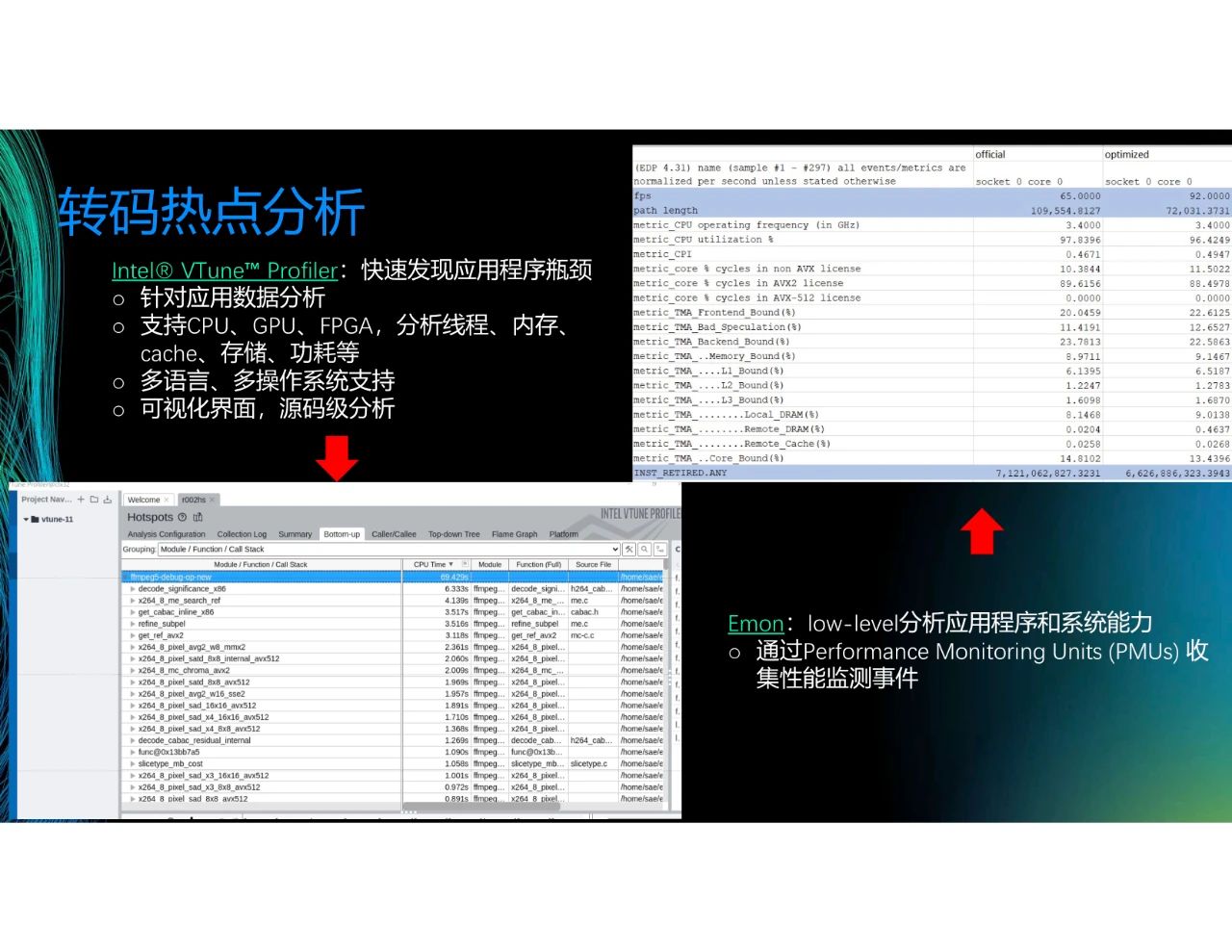
接下來,介紹幾款好用的英特爾的工具。首先是V-Tune,是一個可以快速發現應用程序瓶頸的可視化的工具。左下圖展示了一個例子,可以看到,我們可以知道轉碼里每個函數占用的CPU時間,雙擊就可進入code,精確定位哪行code的占比較高,所以可以清楚地知道熱點函數在哪里。我們支持CPU、GPU和FPGA,也支持多語言和多操作系統。V-Tune的優點是直觀,缺點是會為系統帶來一定的負擔。
另一個工具是Emon,其用于low-level層面的數據抓取。Emon的優點是可以直接抓取Performance Monitoring Units(PMUs),即寄存器的值,因此功率消耗較少。觀察右上圖,可以知道CPU的利用率、AVX指令集的使用比例,也可以知道該函數是Backend_Bound還是Frontend_Bound。因此,可以清楚知道系統的問題在哪里。
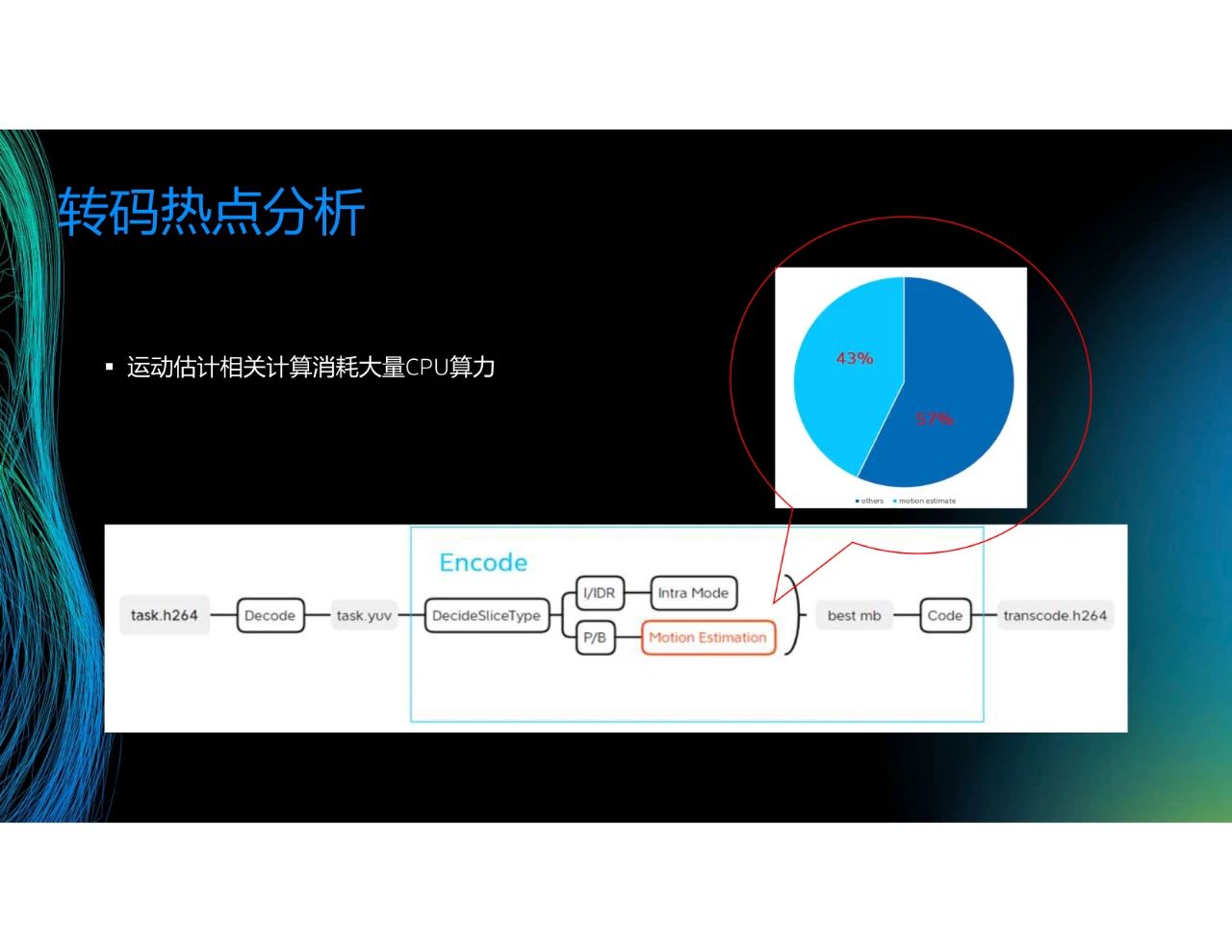
利用剛才介紹的工具,可以估計轉碼消耗的算力。可以看到,在某一個轉碼場景里,編碼過程中的運動估計(Motion Estimation)占比超過40%,但不同的場景情況有所不同,舉個例子,將8K的數據轉換成360P的數據時,解碼消耗的算力大于轉碼消耗的算力。在大部分情況下,若考慮幀決策等,運動估計的占比將超過50%,因此這成為了我們關注的熱點。
02重用運動矢量等信息提高轉碼效率和質量
接下來,介紹方案的核心思想。
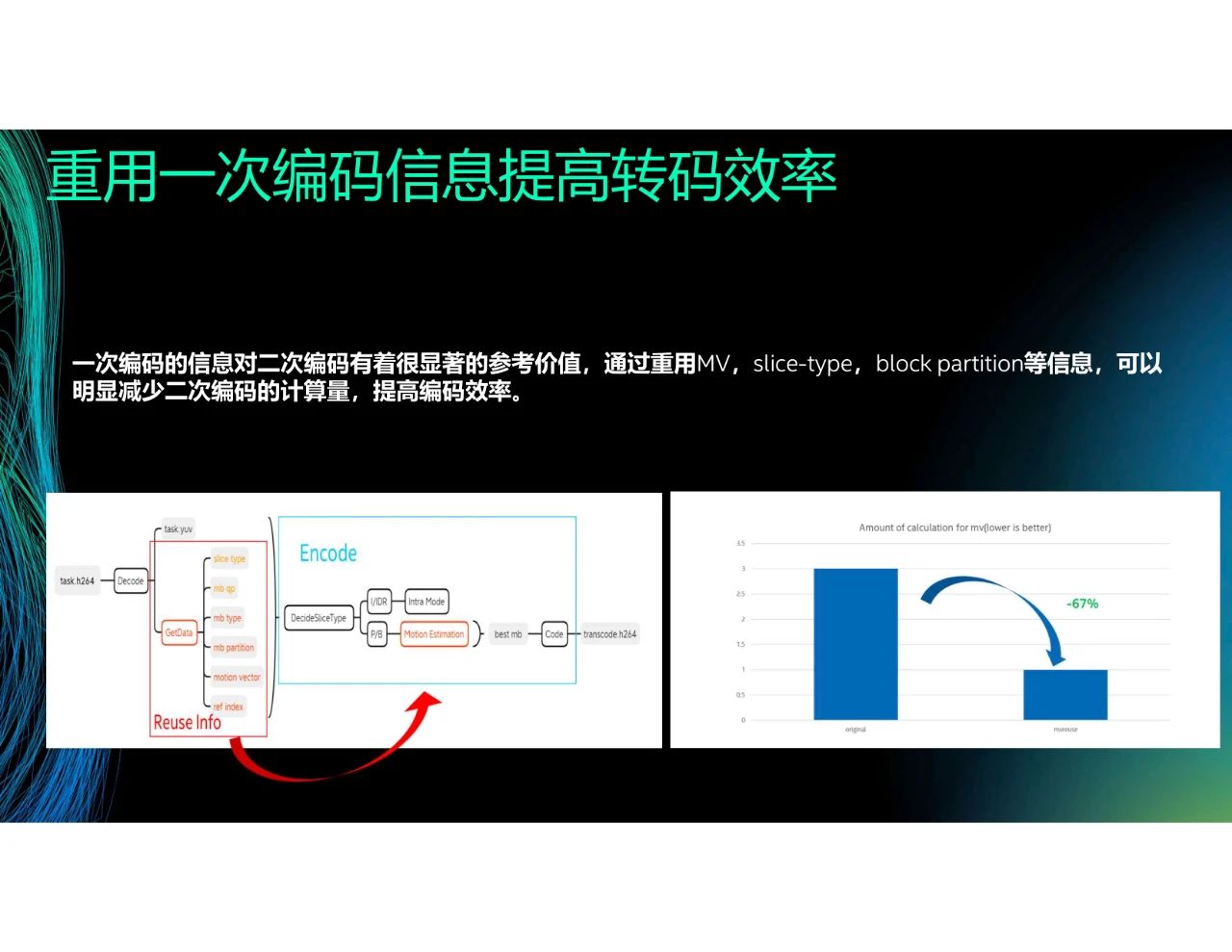
我們現在考慮轉碼,比如將H.264或H.265轉換成H.266或AV1。在一次編碼時,我們可以獲得slice type、mb qp和mb partition等信息。在現在的編解碼方式中,解碼之后這些信息就會被舍棄。而我們的核心思想是,在二次編碼中重用一次編碼的信息。通過粗略計算,在大部分場景下,重用一次編碼信息可以減少大約67%的運算量。
對于這種思路,大家可能有很多問題。比如,當幀率或分辨率在轉碼前后發生變化時,會不會出現一些新的問題。因此,雖然方案的原理比較直接,但實際應用時需要解決很多“并發癥”。特別是,我們要考慮如何一方面提升轉碼速度,另一方面保證轉碼質量,否則轉碼質量不好,即使轉碼速度很快,也不能投入實用。
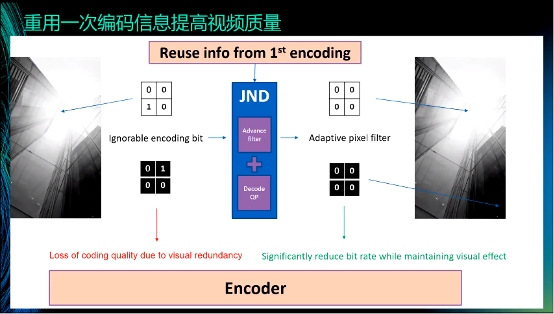
舉個例子說明如何重用一次編碼的信息來提高視頻質量。JND是一種感知編碼技術,在左上的圖中,四個block中只有左下的block的值為1,其余block的值為0。但對于人眼來說,可以忽略數值1,即四個block的值可以都為0。這是JND的核心思想:過濾人眼感觸不到的信息。對此,經典的方法是使用雙邊濾波器等進行過濾,但這些方法都是無差別的濾波,容易造成“誤傷”。而現在由于掌握一次編碼信息,我們知道哪些信息可以被平滑,哪些信息必須保留,通過設置權重的方式來進行“區別對待”。這樣做可以帶來兩個好處,一是可以提高主觀視覺的質量,二是在限定碼率的情況下,可以將碼率用在刀刃上,大幅度地提高客觀質量。比如,將一個原碼率是50Mbps的視頻轉碼為2Mbps的視頻,采用我們的方式就可以較大地提高質量。
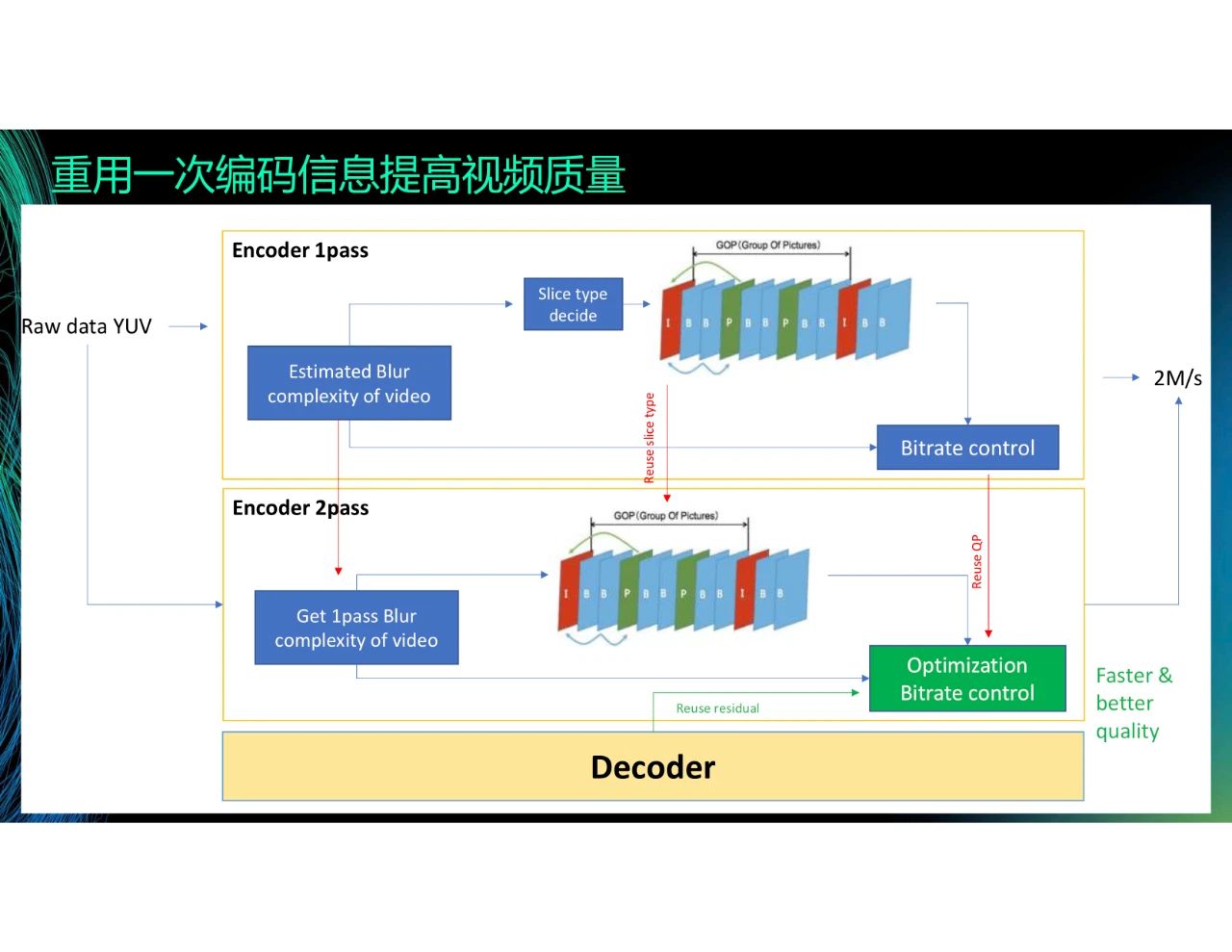
另一種方式是使用一次編碼的殘差。在H.264和H.265里,有two-path的算法,但這個算法通常不被使用。這是因為,雖然經過一次編碼可以掌握大概的信息,并且在此基礎上二次編碼的結果更精準,編碼質量更高且碼率更低,但是這會大幅度地增加計算量,推高轉碼成本和延遲。為了解決這個問題,我們直接重用一次編碼的信息來實現類似二次編碼的效果。
03SIMD指令集加速轉碼熱點函數
最后,介紹如何用SIMD指令集加速轉碼熱點函數。
至強服務器平臺SIMD指令集經迭代了很多代,大家比較熟知的比如AVX2,AVX512等。第二代至強可擴展平臺在AVX512的基礎上支持了INT8數據精度,第三代支持BF16指令集,2023年初量產的第四代平臺的AI性能在BF16和INT8上較上一代提升了8倍,其中加入了AMX 指令集,也可以理解為在CPU內部有一塊硬件加速器。比如INT8的算力,一顆CPU的性能接近200T,很多以前在CPU上無法完成的運算現在都成為可能。

最后介紹一個例子,說明如何使用SIMD指令集優化視頻編碼。在H.264中有一個大小為16×16的宏塊,需要對其求和或平方和,那么如何用avx512對其進行加速呢?需要執行以下幾步。首先,將16個int8的數據載入到mm128寄存器中。然后,將int8數據轉換成int32,這是因為有時候運算結果為負數,而int8無法表示負數。接著,將16個int32數據水平相加,這需要消耗0.5個指令周期,而手動計算則需要8次計算,因此極大地提高了效率。最后,將16個int32平方后再水平相加。經過這樣的處理,性能可提高16倍或8倍(若為一條指令則提高16倍,若為兩條指令則提高8倍)。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3814瀏覽量
138197 -
編解碼
+關注
關注
1文章
145瀏覽量
20129 -
SIMD
+關注
關注
0文章
36瀏覽量
10551 -
視頻轉碼
+關注
關注
0文章
14瀏覽量
7627
原文標題:基于運動矢量重用的轉碼優化
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
主控CPU全能選手,英特爾至強6助力AI系統高效運轉

一片主板可以有多少路CPU?

走進連接器界‘摩斯密碼’特殊編碼丨L、T、S解讀

CPU怎么降頻 bios中如何把cpu調低頻率
CPU(中央處理器)的概念、結構特點和在系統中的地位

如何提高編碼器的工作效率與作用
編碼器在機器人技術中的應用 編碼器在傳感器系統中的作用
如何限制容器可以使用的CPU資源






 工商網監
工商網監

評論