 數據湖是什么
數據湖是什么
1.為什么出現數據湖?
支撐業務的IT軟件系統最簡單的數據鏈路是:操作業務APP的界面或者調用其API接口,將交易數據記錄到關系型數據庫中。
說其簡單,是因為這樣的系統能夠支撐業務交易。業務APP上的每筆交易數據都會記錄在數據庫中。
這對業務交易員來說,已經足夠了。但對業務管理者來說,期望看到的是“自己關心的、宏觀的、能夠反應歷史變化的數據”,并且最好是可視化的界面,一目了然。
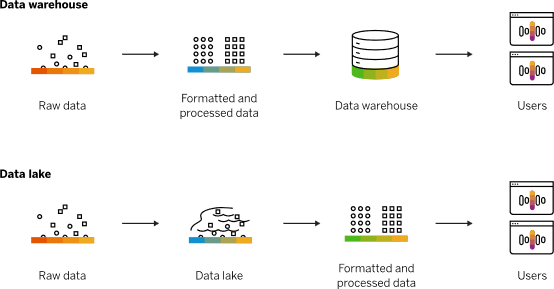
于是,“數據倉庫”出現了,它就是一個面向主題的、集成的、反映歷史變化的數據集合。
那么,數據是如何從業務數據庫到達數據倉庫的呢?
首先,要理解的是業務數據庫和數據倉庫的Schema(表結構)大部分情況下是不同的,前者用來記錄實時交易信息,后者用來記錄歷史匯總信息。
其次,表結構的不同,就需要進行數據處理的三板斧--“抽取、轉換和加載”,即Extract-Transform-Load,簡稱ETL。具體來說就是抽取管理者關心的(面向主題)、轉換數據、加載到數據倉庫中。
最后,根據業務規則,提取數據倉庫中的數據進行可視化提取與展示(報表)。
數據倉庫的使用思路是:業務管理者知道“自己關心哪些數據”,在創建數據倉庫時,便可以將這些數據提取并記錄下來。這樣,數據倉庫記錄的是經過加工過的數據,而非原始數據。
注意到數據倉庫的數據是結構化的。對于半結構化(CSVXMLJSON)和非結構化(e-mail文檔)的數據來說,也蘊含著有價值的信息,同樣需要分析,或者現在不知道怎么分析,也可以先存儲起來。
那么就需要有一種方法:不但可以存儲原始數據,也可以存儲結構化、半結構化、非結構 化的數據,并且還能支撐數據的分析。
時勢的呼喚下,“數據湖(Data Lake)”便產生了。
2.數據湖是什么?
數據湖是一個以原始格式存儲數據的存儲庫或系統。
“數據”可以是各種格式的,結構化、半結構化的、非結構化的。并且數據是未經加工的,像大自然的水,流入到“湖”中。也就是數據的存儲,無需像數據倉庫那樣事先設計Schema,也無需事先有明確的分析需求(有了想法,再延遲分析,稱為讀時模式Schema-On-Read)。
3.數據湖如何實現?
數據湖是一種方法論,探討如何以原始形態存儲各種格式的數據,并能支持后續的分析。
數據湖的開源實現有:Hadoop、Delta、Apache Iceberg 和 Apache Hudi。
-
數據庫
+關注
關注
7文章
3794瀏覽量
64362 -
數據鏈路
+關注
關注
0文章
25瀏覽量
8940 -
軟件系統
+關注
關注
0文章
62瀏覽量
9501 -
API接口
+關注
關注
1文章
84瀏覽量
10437
發布評論請先 登錄
相關推薦
數據湖是什么,它的快速搭建方法介紹
AWS數據湖怎么脫穎而出的
結合阿里云上的EMR JindoFS優化和實踐,數據湖怎么玩“加速”?
阿里云為什么要重構數據湖解決方案 主推下一代技術
阿里云宣布推出業內首個云原生企業級數據湖解決方案
虛擬化模型驅動的分布式數據湖架構設計
易華錄提出面向數據湖的數據安全治理框架
數據湖生態與數據智能峰會來襲 24日易華錄有約
如何將SAP歸檔數據合并到數據湖中
Azure Data Lake數據湖指南
數據湖真的能取代數據倉庫嗎?【SNP SAP數據轉型 】
什么是數據湖?數據湖和數據倉庫有什么區別?





 工商網監
工商網監
評論