 ?如何提高HPC SoC的可靠性、可用性和可維護性級別
?如何提高HPC SoC的可靠性、可用性和可維護性級別
在大型數據中心和超級計算機的領域,高性能計算 (HPC) 已經變得相當普遍,并且在某些情況下,在我們的日常生活中必不可少。正因為如此,可靠性、可用性和可維護性(reliability, availability, and serviceability,或稱RAS),是更多 HPC SoC 設計人員應該熟悉的概念。
RAS 聽起來像是一個不言自明的術語,但在涉及 HPC SoC 時它真正涉及什么?數據中心運營商長期與客戶保持服務水平協議,以保證系統正常運行時間。RAS 補充了這些協議,現在可以得到新技術的支持,最終產生可操作的見解。在這篇最初發表于“從芯片到軟件”博客上的文章中,您將了解為什么芯片生命周期管理 (SLM)、嵌入式監控 IP 以及正確的設計和驗證工具可以在您的HPC 設計中實現高水平 RAS。
3個關鍵的高性能計算組件
家庭安全門鈴或建筑物監控系統捕獲的視頻片段、財務和業務運營建模、科學和醫學研究、增強現實和虛擬現實等應用都需要依賴 HPC。隨著我們的設備和系統收集的數據激增、AI 驅動的分析、大量計算資源的可用性以及云的融合,使快速獲得有用、可操作的見解成為可能,使 HPC 成為許多領域不可或缺的一部分。它與 1940 年代第一臺超級計算機出現時相比,應用范圍更廣。
當今典型的 HPC 基礎設施由三個關鍵要素組成:計算、網絡和存儲。每個都需要一定水平的性能、延遲、電源效率、可擴展性、生產力和安全性。讓我們仔細看看每個元素:
計算由 CPU 和 GPU、加速器、片上網絡 (NoC) 和計算服務器組成。這是進行高性能數據處理的地方。復雜的多核甚至多芯片系統架構、具有快速訪問的大內存、高帶寬 I/O 接口、電源/冷卻管理和安全性是其關鍵特性。片內監控和分析還可以支持 RAS 目標。
網絡由交換機和路由器、適配器、網橋、中繼器、網絡接口卡(如 SmartNIC)以及光學和電氣互連組成。該元素提供高性能連接,理想情況下具有高吞吐量、低延遲、能源效率、可配置性和可擴展性、實時監控和報告以及安全性。調試功能、前向糾錯 (FEC) 和 IP 可以支持 RAS 要求。
存儲包括固態驅動器 (SSD) 或硬盤驅動器 (HDD)、存儲區域網絡 (SAN) 和網絡附加存儲 (NAS)。理想情況下,存儲元件應提供高帶寬存儲、減少數據傳輸能量和延遲、靈活性、可擴展性、可靠性和安全性。內置自測試 (BIST)、糾錯碼 (ECC) 和冗余等功能可以促進高水平的 RAS。
有兩種主要類型的 HPC 系統:同類機器和混合機器。同類機器只有 CPU。相比之下,混合動力車同時擁有 GPU 和 CPU,其中 GPU 運行任務而 CPU 監督計算。
HPC 集群可以由大量服務器組成,其中計算集群的總物理尺寸、能源使用或熱輸出可能成為一個嚴重的問題。此外,還需要在服務器之間進行專用通信,這對于集群來說有些獨特。
由于微小的設計差異乘以集群中的服務器數量會帶來巨大的收益,因此我們看到了針對 HPC 優化的服務器設計的出現。有時,這些是針對大型公共 Web 運營商(例如搜索引擎公司)的設計,它們在 HPC 集群中提供類似的優勢。但是,它們也可以提供僅適合 HPC 用戶的功能。例如,如果系統設計為以不同方式提供集群互連,則可能會顯著減少布線。
通過片內監控和分析獲得可操作的見解
HPC 的實用性在于它能夠處理海量數據(PB 甚至 zettabytes)并實時(或接近實時)運行復雜模型。不用說,只要 HPC 系統出現故障,就會導致資金損失和業務中斷。任務關鍵型應用程序的影響變得更加陡峭。在高級節點,使用大型單片芯片或復雜架構(如多芯片),可以滿足 RAS 要求并變得更具挑戰性。
根據手頭應用程序的重要性,系統可以構建備份,以在發生故障時提供冗余。除了冗余之外,您還可以在系統和芯片級別做更多的事情來滿足 RAS 目標。這就是 SLM 發揮重要作用的地方,它提供智能、自動化的片內監控 IP 和方法,以在系統生命周期的每個階段生成可操作的見解。
幾十年來,設計人員一直在將監視器和傳感器嵌入到他們的芯片中。但是,該技術已經發展到現在可以提供更準確的數據。這樣可以更好地了解設備的實時環境、結構和功能狀況。示例包括工藝變化和電壓供應的監控,以及時序裕度的準確測量等。
由于嵌入式和基于云的分析,以及統一 SLM 解決方案的可用性,設計團隊將能夠建立一個連續的、實時的設備硅健康狀況圖,而不僅僅是在設計期間,在生產階段以及現場操作期間。他們可以更好地了解根本原因并立即進行調試和修復,從而降低成本和潛在危害。SLM 可以解決的問題包括晶體管老化和延遲故障。要了解這帶來的好處,請考慮一顆有缺陷的衛星。通常情況下,從實驗室取回修復后的電路板安裝到衛星上可能需要數周的時間,將其長時間停用以進行故障排除和維修。通過SLM技術在現場進行故障檢測和故障修復。
看看數據中心,我們可以看到另一個突出 SLM 如何促進滿足 RAS 要求的示例。
在芯片層面,現場遠程調試的能力對于超大規模數據中心的團隊來說至關重要。SLM 提供遠程遙測和監控使這成為可能。
在系統級別,精確的時鐘節流(SLM 的另一項功能)對于最大化數據吞吐量和 CPU、GPU 和 AI 引擎利用率至關重要。
在數據中心級別,使用 SLM 工具監控服務器性能、網絡擁塞和磁盤利用率是檢測和預測數據中斷的關鍵,這可以增加正常運行時間。
在超大規模級別,團隊可以利用 SLM 來最大限度地減少片上熱和電源壓力,從而提高可靠性。
對于 die-to-die 高速接口,SLM 提供信號完整性監控,連同接口完整性冗余,有助于確保小芯片設計的穩健性。
概括
一個端到端的解決方案將設計校準分析、片內監控和系統性能優化等一切結合在一起,而不是一組互不關聯的單點工具,可以使解決 RAS 目標的過程更加無縫。
鑒于現在依賴 HPC 的應用程序范圍越來越廣,保持這些系統的高水平可靠性、可用性和可服務性是一個全面的關鍵考慮因素。實現最佳 RAS 水平以支持從流媒體視頻到氣候變化建模的一切是保持數字化、智能化萬物世界高速運行的另一個重要因素。
-
soc
+關注
關注
38文章
4173瀏覽量
218423 -
SSD
+關注
關注
21文章
2863瀏覽量
117490 -
HPC
+關注
關注
0文章
316瀏覽量
23807
原文標題:?如何提高 HPC SoC 的可靠性、可用性和可維護性級別?
文章出處:【微信號:ICViews,微信公眾號:半導體產業縱橫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
半導體封裝的可靠性測試及標準
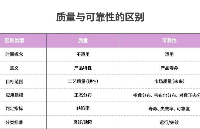
如何提高CAN總線的傳輸可靠性
UPS電源的安全性和可靠性分析
PCB高可靠性化要求與發展——PCB高可靠性的影響因素(上)
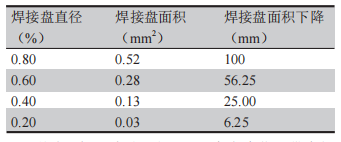

如何提高RS485通信的可靠性?

基于可靠性設計感知的EDA解決方案

汽車功能安全與可靠性的關系

請問FATFS文件系統可靠性如何?
如何提高分布式大屏控制系統的穩定性和可靠性
如何確保IGBT的產品可靠性
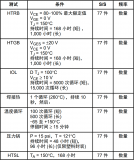
IGBT的可靠性測試方案
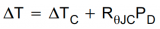





 工商網監
工商網監
評論