 Google二進制編解碼技術之Protobuf 1
Google二進制編解碼技術之Protobuf 1
計算機網絡編程中一個非常基本的問題:該怎樣表示client與server之間交互的數據,在往下看之前先想一想這個問題。
共識與協議
這個問題可不像看上去的那樣簡單,因為client進程和server進程運行在不同的機器上,這些機器可能運行在不同的處理器平臺、可能運行在不同的操作系統、可能是由不同的編程語言編寫的,server要怎樣才能識別出client發送的是什么數據呢?就像這樣: client給server發送了一段數據:
client給server發送了一段數據:
0101000100100001
server怎么能知道該怎樣“解讀”這段數據呢?
顯然,client和server在發送數據之前必須首先達成某種關于怎樣解讀數據的共識,這就是所謂的 協議 。
這里的協議可以是這樣的:“將每8個比特為一個單位解釋為無符號數字”,如果協議是這樣的,那么server接收到這串二進制后就會將其解析為81(01010001)與33(00100001)。
當然,這里的協議也可以是這樣的:“將每8個比特為一個單位解釋為ASCII字符”,那么server接收到這串二進制后就將其解析為“Q!”。
可見,同樣一串二進制在不同的“上下文/協議”下有完全不一樣的解讀,這也是為什么計算機明明只認知0和1但是卻能處理非常復雜任務的根本原因,因為一切都可以編碼為0和1,同樣的我們也可以從0和1中解析出我們想要的信息,這就是所謂的編解碼技術。
實際上不止0和1,我們也可以將信息編碼為摩斯密碼(Morse code)等,只不過計算機擅長處理0和1而已。
扯遠了,回到本文的主題。
遠程過程調用:RPC
作為程序員我們知道,client以及server之間不會簡單傳遞一串數字以及字符這樣簡單,尤其在互聯網大廠后端服務這種場景下。
當我們在電商App搜索商品、打車App呼叫出租車以及刷短視頻時,每一次請求的背后在后端都涉及大量服務之間的交互,就像這樣:
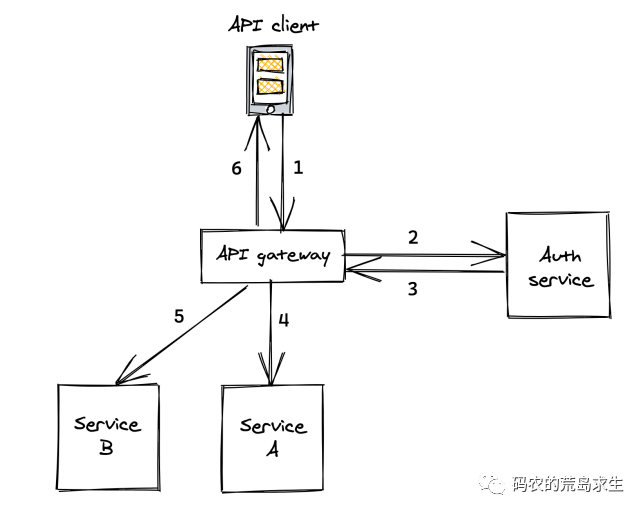
完成一次客戶端請求gateway這個服務要調用N多個下游服務,所謂調用是說A服務向B服務發送一段數據(請求),B服務接收到這段數據后執行相應的函數,并將結果返回給A服務。
只不過對于服務A來說并不想關心網絡傳輸這樣的底層細節,如果能像調用本地函數一樣調用遠程服務就好了,這就是所謂的RPC,經典的實現方式是這樣的:
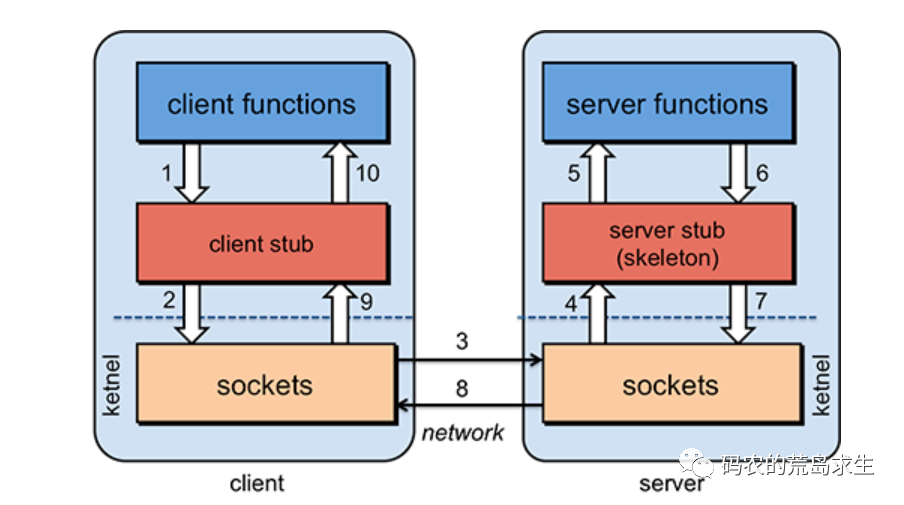
RPC對上層提供和普通函數一樣的接口,只不過在實現上封裝了底層復雜的網絡通信,RPC框架是當前互聯網后端的基石之一,很多所謂互聯網后端的職位無非就是在此基礎之上堆業務邏輯。
本文我們不關心其中的細節,這里我們只關心在網絡層client是怎樣對請求參數進行編碼、server怎樣對請求參數進行解碼的,也就是本文開頭提出的問題。
信息的編解碼
在思考怎樣進行編解碼之前我們必須意識到:
- client和server可能是用不同語言編寫的,你的編解碼方案必須通用且不能和語言綁定
- 編解碼方法的性能問題,尤其是對時間要求苛刻的服務
首先,我們最應該能想到的就是以純文本的形式來表示。
純文本從來都是一種非常有友好的信息載體,為什么?很簡單,因為人類(我們)可以直接看懂,就像這段:
{
"widget": {
"window": {
"title": "Sample Konfabulator Widget",
"name": "main_window",
"width": 500,
"height": 500
},
"image": {
"src": "Images/Sun.png",
"name": "sun1",
"hOffset": 250,
"vOffset": 250,
},
}
}
是不是很清晰,一目了然,只要我們實現約定好文本的結構(也就是語法),那么client和server就能利用這種文本進行信息的編碼以及解碼,不管client和server是運行在x86還是Arm、是32位的還是64位的、運行在Linux上還是windows上、是大端還是小端,都可以無障礙交流。
因此在這里,文本的語法就是一種協議。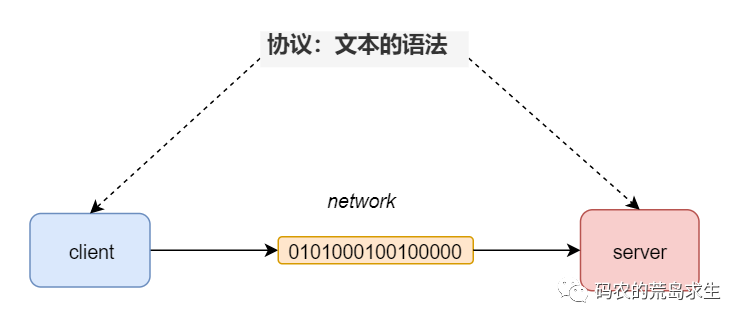 順便說一句, 你都規定好了文本的語法,實際上就相當于發明了一種語言 。
順便說一句, 你都規定好了文本的語法,實際上就相當于發明了一種語言 。
這里用來舉例用的語言就是所謂的Json,只不過json這種語言不是用來表示邏輯(代碼)而是用來存儲數據的。
Json就是這個老頭提出來的:
除了Json,另一種利用文本存儲數據的表示方法是XML,來一段感受下:
<note>
<to>Toveto>
<from>Janifrom>
<heading>Reminderheading>
<body>Don't forget me this weekend!body>
note>
相對Json來說是不是就沒那么容易看懂了,Json出現后在web領域逐漸取代了XML。
當兩段數據量很少的時候——就像瀏覽器和服務端的交互,Json可以工作的非常好,這個場景就是這里: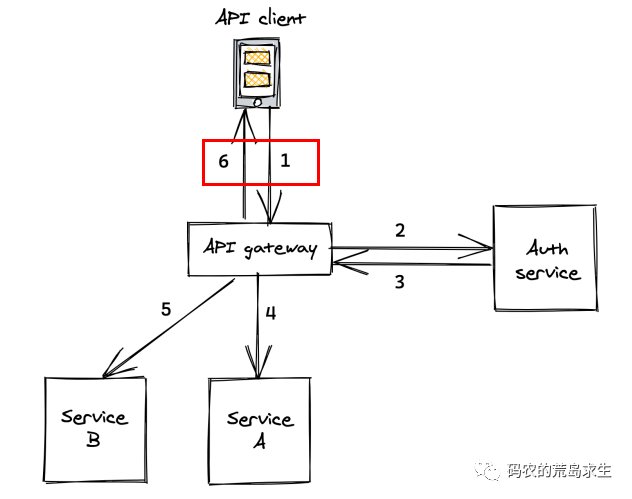 在這里是json的天下。
在這里是json的天下。
但對于后端服務之間的交互來說就不一樣了,后端服務之間的RPC調用可能會傳輸大量數據,如果全部用純文本的形式來表示數據那么不管是網絡帶寬還是性能可能都會差強人意。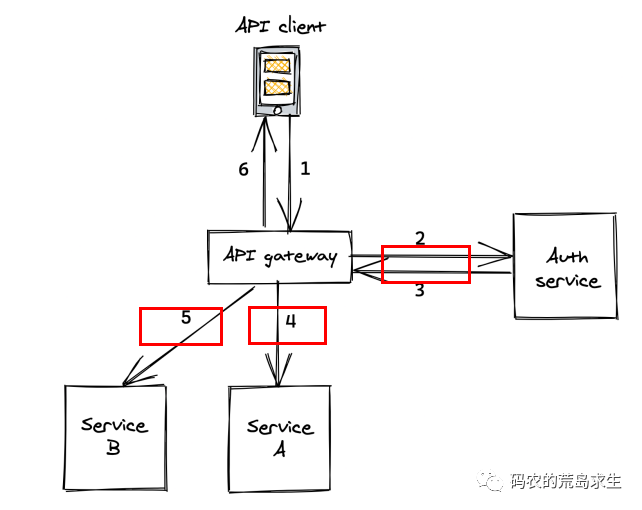
在這種場景下,Json并不是最好的選項,主要原因之一就在于性能以及數據的體積。
我們知道,文本表示對人類是最友好的,對機器來說則不是這樣,對機器來說最好的還是01二進制。
那么有沒有二進制的編碼方法嗎?答案是肯定的,這就是當前互聯網后端中流行的protobuf,Google公司開源項目。
那么protobuf有什么神奇之處嗎?
假設client端想給server端傳輸這樣一段信息:“我有一個id,其值為43”,那么在XML下是這樣表示的:
<id>43id>
數一數這這段數據占據了多少字節,很顯然是11字節;
而如果用json來表示呢?
{"id":43}
數一數這段數據占據了多少字節,顯然是9字節;
而如果用protobuf來表示呢? 是這樣的:
// 消息定義
message Msg {
optional int32 id = 1;
}
// 實例化
Msg msg;
msg.set_id(43);
其中Msg的定義看上去比Json和XML更加復雜了,但這些只是給人看的,這些還會被protbuf進一步處理,最終被編碼為:
082b
也就是0x08與0x2b,這占據了多少字節呢?答案是2字節。
從json的9字節到protobuf的2字節,數據大小減少了4倍多,數據量的減少意味著:
- 更少的網絡帶寬
- 更快的解析速度
那么protobuf是怎樣做到這一點的呢?
-
計算機
+關注
關注
19文章
7489瀏覽量
87868 -
Server
+關注
關注
0文章
90瀏覽量
24029 -
網絡編程
+關注
關注
0文章
71瀏覽量
10074
發布評論請先 登錄
相關推薦
探討2對4二進制解碼器及4到16二進制解碼器配置

二進制數的運算規則
什么是二進制計數器,二進制計數器原理是什么?
二進制電平,什么是二進制電平
二進制解碼器到底是什么






 工商網監
工商網監
評論