 算法是指什么?算法概述
算法是指什么?算法概述
一、算法概述
算法是指解題方案的準確而完整的描述,是一系列解決問題、高度符合邏輯性、可執行性的指令集合,代表運用系統方法描述解決問題的策略機制。算法能夠對一定規范的輸入在有限時間內運行得到輸出。
算法中的指令描述的是計算過程,當其運行時能從初始狀態和初始輸入(初始輸入可能為空的)開始,經過一系列有限而清晰定義的狀態,最終產生輸出并終止于某一狀態。
不同的算法在解決相同問題所需時間、空間可能不同,即算法的效率不同。算法的優劣可通過解決相同問題所需的時間復雜度與空間復雜度衡量。
二、傳統算法與大數據算法
傳統的數據算法可被稱為數據分析,數據分析的目的在于對已有的數據進行描述性分析,其重點在于發現數據隱含的規律,進行商業分析和處理。
大數據時代的數據算法可被稱為數據科學,與數據挖掘和機器學習相關。
機器學習是交叉學科,機器學習涉及的學科包括概率論、統計學、逼近論、圖分析、算法復雜度理論等。機器學習主要研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,并重新組織已有的知識結構使之不斷改善自身性能。
大數據機器學習更強調學習是手段。機器學習成為一種支持和服務技術,基于機器學習對復雜多樣的數據進行深層次的分析和更高效地利用信息成為大數據機器學習研究的主要方向。所以,大數據機器學習逐漸向智能數據分析的方向發展,并已成為智能數據分析技術的重要組成部分。
大數據時代,數據體量以空前的速度增長,需要分析新類型數據也在不斷出現,新類型數據包括:文本理解、文本情感分析、圖像的檢索和理解、圖形和網絡等。數據體量快速增長和新類型數據不斷出現使得大數據機器學習和數據挖掘等智能計算技術在大數據智能化分析處理應用中具有重要作用。 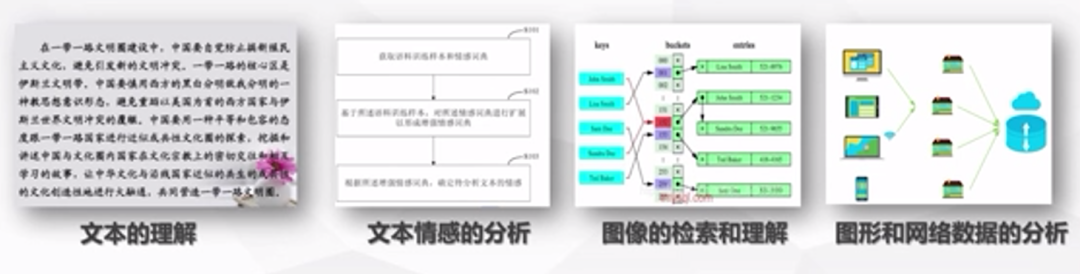
圖片來源:學堂在線《大數據導論》
三、機器學習算法
目前,主流的機器學習算法包括:監督學習和非監督學習。
(1)監督學習
監督學習是指從標記的訓練數據推斷某一功能的機器學習任務,訓練數據包括一套訓練示例。每套訓練示例均由一個輸入對象(通常為矢量)和一個期望的輸出值 (也稱為監督信號)組成。監督學習算法通過分析訓練示例(個人理解:需分析多套訓練示例),產生某種推斷功能,該推斷功能可以用于映射新示例。
監督學習包括:分類算法和回歸分析。
1)分類算法包括:自然貝葉斯、決策樹、隨機森林、神經網絡等。分類算法主要針對離散數據。
2)回歸類算法包括:線性回歸、邏輯回歸、支持向量機等。回歸類算法主要針對連續數據。
(2)非監督學習
非監督學習是指在沒有類別信息情況下,通過分析所研究對象大量樣本的據數,實現樣本分類的數據處理方法。
通過非監督式學習,可將樣本集劃分為若干個子集(類別),或將樣本集作為訓練樣本集,再通過監督學習方法進行分類器設計。
非監督學習包括:聚類算法、抽維算法。
1)聚類算法包括:距離聚類、快速聚類等。
2)抽維算法包括:主因子、典型相關等。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100836 -
機器學習
+關注
關注
66文章
8422瀏覽量
132710 -
大數據
+關注
關注
64文章
8894瀏覽量
137477
原文標題:大數據相關介紹(8)——算法
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深入解析ECC256橢圓曲線加密算法
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+內容簡介
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+介紹基礎硬件算法模塊
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+一本介紹基礎硬件算法模塊實現的好書
激光雷達在SLAM算法中的應用綜述
【BearPi-Pico H3863星閃開發板體驗連載】LZO壓縮算法移植
Pure path studio內能否自己創建一個component,來實現特定的算法,例如LMS算法?
請問GDE中的NR算法反應慢怎么解決?
Huffman壓縮算法概述和詳細流程
名單公布!【書籍評測活動NO.46】從算法到電路 | 數字芯片算法的電路實現
深度識別算法包括哪些內容
Camera算法集成實現指南
AC電機控制算法是什么





 工商網監
工商網監
評論