

介紹
使用 Kubernetes 時,內存不足 (OOM) 錯誤和 CPU 節流是云應用程序中資源處理的主要難題。
這是為什么?
云應用程序中的 CPU 和內存要求變得越來越重要,因為它們與您的云成本直接相關。
通過 limits 和 requests ,您可以配置 pod 應如何分配內存和 CPU 資源,以防止資源匱乏并調整云成本。
如果節點沒有足夠的資源, Pod 可能會通過搶占或節點壓力被驅當一個進程運行內存不足 (OOM) 時,它會被終止,因為它沒有所需的資源。
如果 CPU 消耗高于實際限制,進程將開始節流。
但是,如何主動監控 Kubernetes Pod 到達 OOM 和 CPU 節流的距離有多近?
Kubernetes OOM
Pod 中的每個容器都需要內存才能運行。
Kubernetes limits 是在 Pod 定義或 Deployment 定義中為每個容器設置的。
所有現代 Unix 系統都有一種方法來終止進程,以防它們需要回收內存。這將被標記為錯誤 137 或OOMKilled.
State:Running Started:Thu,10Oct20191113+0200 LastState:Terminated Reason:OOMKilled ExitCode:137 Started:Thu,10Oct20191103+0200 Finished:Thu,10Oct20191111+0200
此退出代碼 137 表示該進程使用的內存超過允許的數量,必須終止。
這是 Linux 中存在的一個特性,內核oom_score為系統中運行的進程設置一個值。此外,它允許設置一個名為 oom_score_adj 的值,Kubernetes 使用該值來允許服務質量。它還具有一個 OOM Killer功能,它將審查進程并終止那些使用比他們應該使用上限更多的內存的進程。
請注意,在 Kubernetes 中,進程可以達到以下任何限制:
在容器上設置的 Kubernetes Limit。
在命名空間上設置的 Kubernetes ResourceQuota。
節點的實際內存大小。
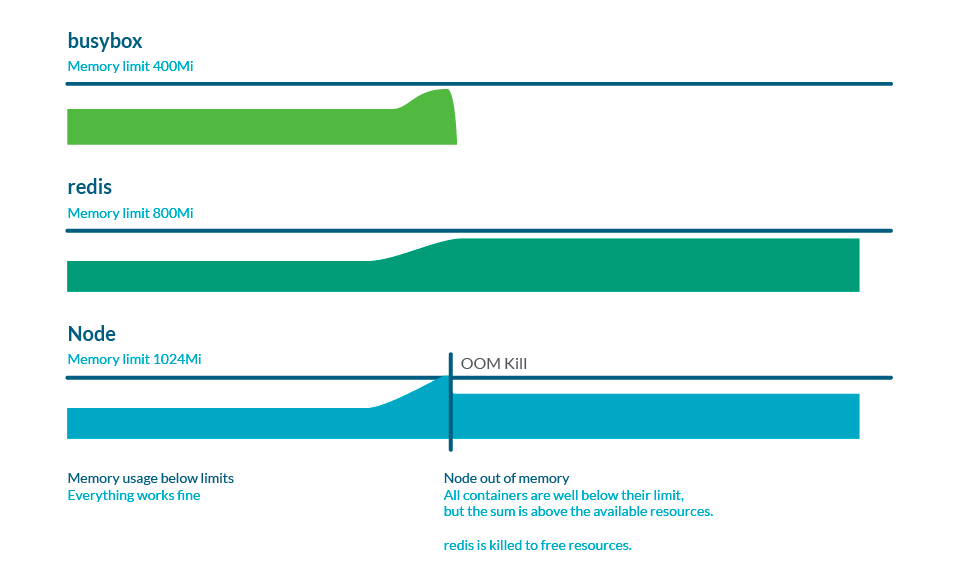
內存過量使用
Limits 可以高于 requests,因此所有限制的總和可以高于節點容量。這稱為過度使用,這很常見。實際上,如果所有容器使用的內存都比請求的多,它可能會耗盡節點中的內存。這通常會導致一些 pod 被殺死以釋放一些內存。
監控 Kubernetes OOM
在 Prometheus 中使用 node exporter 時,有一個指標稱為node_vmstat_oom_kill. 跟蹤 OOM 終止發生的時間很重要,但您可能希望在此類事件發生之前提前了解此類事件。
相反,您可以檢查進程與 Kubernetes 限制的接近程度:
(sumby(namespace,pod,container) (rate(container_cpu_usage_seconds_total{container!=""}[5m]))/sumby (namespace,pod,container) (kube_pod_container_resource_limits{resource="cpu"}))>0.8
Kubernetes CPU 節流
CPU 節流 是一種行為,當進程即將達到某些資源限制時,進程會變慢。
與內存情況類似,這些限制可能是:
在容器上設置的 Kubernetes Limit。
在命名空間上設置的 Kubernetes ResourceQuota。
節點的實際CPU大小。
想想下面的類比。我們有一條有一些交通的高速公路,其中:
CPU 就是路。
車輛代表進程,每個車輛都有不同的大小。
多條通道代表有多個核心。
一個 request 將是一條專用道路,如自行車道。這里的節流表現為交通堵塞:最終,所有進程都會運行,但一切都會變慢。

Kubernetes 中的 CPU 進程
CPU 在 Kubernetes 中使用 shares 處理。每個 CPU 核心被分成 1024 份,然后使用 Linux 內核的 cgroups(控制組)功能在所有運行的進程之間分配。
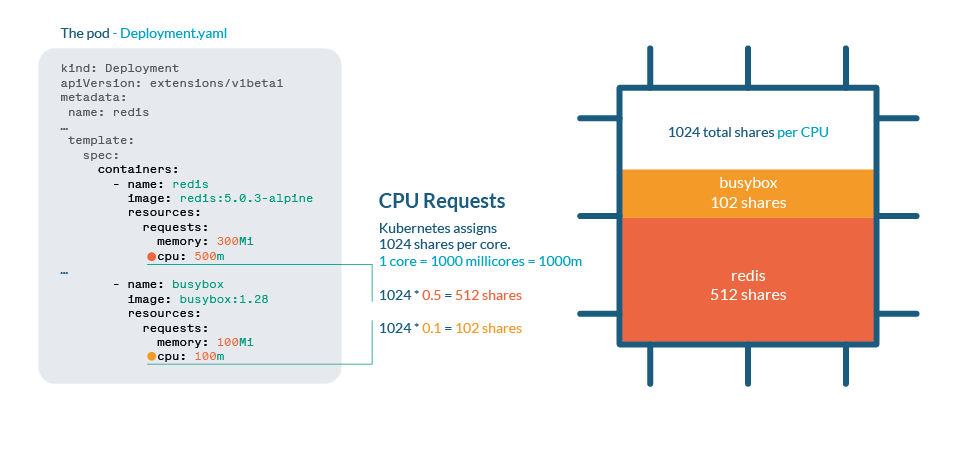
如果 CPU 可以處理所有當前進程,則不需要任何操作。如果進程使用超過 100% 的 CPU,那么份額就會到位。與任何 Linux Kernel 一樣,Kubernetes 使用 CFS(Completely Fair Scheduler)機制,因此擁有更多份額的進程將獲得更多的 CPU 時間。
與內存不同,Kubernetes 不會因為節流而殺死 Pod。
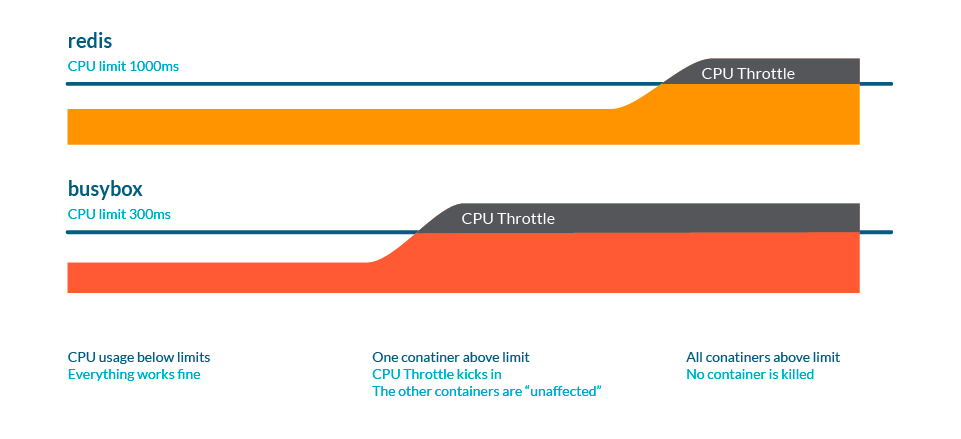
可以在 /sys/fs/cgroup/cpu/cpu.stat 中查看 CPU 統計信息
CPU 過度使用
正如我們在 限制和請求一文 中看到的,當我們想要限制進程的資源消耗時,設置限制或請求很重要。然而,請注意不要將請求總數設置為大于實際 CPU 大小,因為這意味著每個容器都應該有一定數量的 CPU。
監控 Kubernetes CPU 節流
您可以檢查進程與 Kubernetes 限制的接近程度:
(sumby(namespace,pod,container)(rate(container_cpu_usage_seconds_total
{container!=""}[5m]))/sumby(namespace,pod,container)
(kube_pod_container_resource_limits{resource="cpu"}))>0.8
如果我們想跟蹤集群中發生的節流量,cadvisor 提供container_cpu_cfs_throttled_periods_total和container_cpu_cfs_periods_total. 有了這兩個,你就可以輕松計算出所有 CPU 周期的 throttling 百分比。
最佳實踐
注意 limits 和 requests
限制是在節點中設置最大資源上限的一種方法,但需要謹慎對待這些限制,因為您可能最終會遇到一個進程被限制或終止的情況。
做好被驅逐的準備
通過設置非常低的請求,您可能認為這會為您的進程授予最少的 CPU 或內存。但是kubelet會首先驅逐那些使用率高于請求的 Pod,因此您將它們標記為第一個被殺死!
如果您需要保護特定 Pod 免遭搶占(當kube-scheduler需要分配新 Pod 時),請為最重要的進程分配優先級。
節流是無聲的敵人
通過設置不切實際的限制或過度使用,您可能沒有意識到您的進程正在受到限制,并且性能受到影響。主動監控您的 CPU 使用率并了解您在容器和命名空間中的實際限制。
審核編輯:劉清
-
cpu
+關注
關注
68文章
11031瀏覽量
215938 -
Unix系統
+關注
關注
0文章
15瀏覽量
9780 -
LINUX內核
+關注
關注
1文章
317瀏覽量
22176 -
CFS
+關注
關注
0文章
7瀏覽量
9109
原文標題:圖解 K8S OOM 和 CPU 節流
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
OpenStack與K8s結合的兩種方案的詳細介紹和比較
如何使用kubernetes client-go實踐一個簡單的與K8s交互過程
關于K8s最詳細的解析
Docker不香嗎為什么還要用K8s
簡單說明k8s和Docker之間的關系
K8S集群服務訪問失敗怎么辦 K8S故障處理集錦

mysql部署在k8s上的實現方案
k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres
什么是K3s和K8s?K3s和K8s有什么區別?
k8s生態鏈包含哪些技術
跑大模型AI的K8s與普通K8s的區別分析
k8s云原生開發要求






 工商網監
工商網監

評論