

內聯函數是C語言從C++中借鑒過來的,適當的使用內聯函數可以提高程序的執行效率。本篇文章就來講解下內聯函數,趕緊來看下吧!
一、函數調用
在講內聯函數之前,我們需要先了解函數調用,而函數調用,又不得不說函數調用的開銷。
一個函數執行的時候,經常會調用另一個函數,比如執行函數A時,我們需要對一些數據進行處理,將運算結果暫存在R0寄存器,接著要調用另一個函數B,而函數B也用到了R0這個寄存器(用于保存函數的返回值),原本函數A暫存在R0寄存器的值就被改變了,這樣做肯定不行。
現代計算機系統的做法都是會在執行函數B之前,先把R0寄存器的值保存到堆棧中,函數B執行結束后,再將堆棧中的值恢復到R0寄存器中,然后函數A繼續執行,這樣對于數據處理就不會有任何問題了。
但是,函數調用卻消耗一定的時間進行切換,這段時間用來保存現場和恢復現場,大約相當于一兩條語句的執行時間,這就是函數調用帶來的開銷。
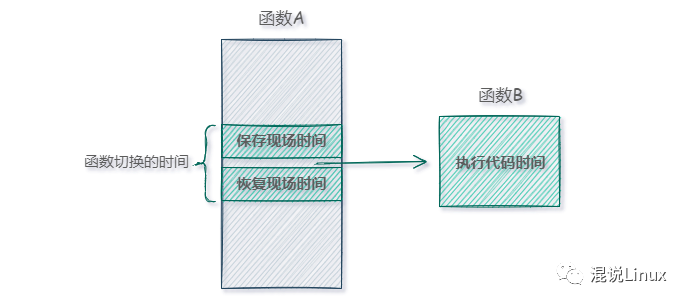
假如函數B很小,只有一兩行代碼,從上圖我們可以看出,真正只有函數B執行代碼的那段時間是對我們有用的,切換帶來的就是額外的成本開銷了,如果函數A里面多次調用函數B,那開銷就更明顯了。

二、內聯函數
函數B很小,又被頻繁的調用,可能函數調用的切換時間比函數內代碼的執行時間還長,這樣明顯劃不來,那么我們就可以將這個函數聲明為內聯(加上 inline),編譯器在編譯時,會把內聯函數的實現替換到每個調用內聯函數的地方(可以與宏函數做類比),在調用處將代碼展開,相當于自動將函數B的代碼在調用它的地方復制了一份副本,沒有了保護現場和恢復現場的時間,從而節省了函數調用的開銷。
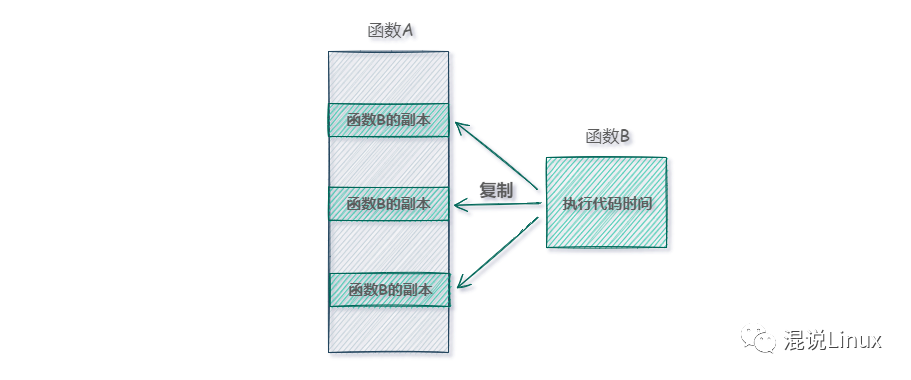
內聯函數一般要求如下:
1. 函數體積小,通常5行以內;
2. 被頻繁調用;
3. 函數內無復雜的實現,比如:while、for循環,switch,遞歸等;
4. 函數沒有包含靜態變量。
來看一個簡單的內聯函數的例子:
#includemain函數代碼在執行的時候是這樣的://將函數max_value聲明為inline inlineintmax_value(intx,inty) { return(x>y)?x:y; } intmain() { inta=1,b=2; intm; m=max_value(a,b); return0; }
intmain()
{
inta=1,b=2;
intm;
m=(1>2)?1:2;
return0;
}
內聯函數在調用處展開了。
在c++ 中定義在類里面的函數,默認情況下都是內聯的,比如下面這種情況:
#includeusingnamespacestd; classHunTalk_Linux { public: //默認是內聯函數 intmax_value(intx,inty) { return(x>y)?x:y; } }; intmain() { return0; }
注意:函數聲明為內聯,僅僅是對編譯器的建議,如果函數比較復雜,編譯器會將其看做普通函數。
三、內聯函數與宏
前面講到可以與宏函數做類比,那么就納悶了,為什么不直接定義一個宏,而是定義一個內聯函數?存在即合理,自然有它存在的道理,相對于宏,內聯函數提供了更好的方法:
參數類型檢查。編譯過程中,宏調用并不執行類型檢查,甚至連正常參數也不檢查,內聯函數雖然具有宏的展開特性,但其本質仍是函數,編譯器仍可以對其進行參數檢查,而宏就不具備這個功能。
在宏中的編譯錯誤很難發現,因為它們引用的是擴展的代碼,而不是程序員鍵入的。
便于調試。內聯函數代碼的調試信息通常比擴展的宏代碼更有用,它同樣可以支持斷點、單步......等調試功能。
接口封裝。有些內聯函數可以用來封裝一個接口,而宏不具備這個特性。
四、總結
引入內聯函數主要是解決一些頻繁調用的小函數造成額外時間開銷的問題,但是也要在符合一定內聯函數的情況下使用。
使用很多的內聯函數,每個調用該函數的地方都需要替換成函數體,代碼量就會增加,代碼量就會增加也同時帶來了潛在的編譯時間的增加。
算法里面有個概念叫空間換時間,就是使用內存占用更大的算法換取執行速度的提升,所以說適當的使用內聯函數可以提高程序的執行效率。
審核編輯:湯梓紅
-
計算機
+關注
關注
19文章
7598瀏覽量
89705 -
C語言
+關注
關注
180文章
7624瀏覽量
139516 -
C++
+關注
關注
22文章
2116瀏覽量
74519 -
內聯函數
+關注
關注
0文章
10瀏覽量
2279 -
函數調用
+關注
關注
0文章
19瀏覽量
2632
原文標題:C語言內聯函數,提升C技巧必備
文章出處:【微信號:混說Linux,微信公眾號:混說Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

Java之內聯函數_內聯函數的優缺點
C++語言入門教程之C++語言程序設計函數的詳細資料概述免費下載
C++基礎語法之inline 內聯函數
C++語法中的inline內聯函數詳解
C語言內聯函數





 工商網監
工商網監

評論