 能與人類駕駛者產生共鳴的合作型自動駕駛汽車技術
能與人類駕駛者產生共鳴的合作型自動駕駛汽車技術
摘要
在開發出能夠讓這些智能智能體與人類共存的解決方案之前,自動駕駛汽車的廣泛采用不會成為現實。這包括安全有效地與人類駕駛的車輛交互,特別是在沖突和競爭場景中。 我們在之前關于社會意識導航的工作的基礎上,借用了心理學中的社會價值取向概念,即一個人對他人福利的重視程度,以誘導自動駕駛中的利他行為。與現有的明確模擬人類駕駛員行為并依靠他們的預期反應來創造合作機會的工作相比,我們的交感合作駕駛(SymCoDrive)范式訓練利他主義的智能體,在競爭性的駕駛場景中實現安全和平穩的交通流,只需通過經驗學習,無需任何明確協調。 由于這種利他行為,我們證明了安全性和交通水平指標的顯著改善,并得出重要的結論,智能體的利他主義水平需要適當的調整,因為過于利他的智能體也會導致次優交通流。
I.簡介
下一代交通系統將通過聯網的自動駕駛車輛變得更安全、更高效。車對車(V2V)通信使自動駕駛汽車(AVs)能夠構成一種大眾智能形式,克服單一智能體以分散方式規劃的局限性[1]。如果道路上的所有車輛都是連接和自動駕駛的,V2V可以讓它們協調和處理需要無私的復雜駕駛場景,例如,并入和退出高速公路,以及穿過十字路口[2]。
然而,由于自動駕駛汽車和人類駕駛汽車(HVs)的機動性和反應時間不同,它們共享的道路自然會成為競爭場景。與完全自動駕駛的情況相比,這里的HV和AV之間的協調并不那么直接,因為AV沒有明確的與人類協調的手段,因此需要在當地考慮到它們附近的其他HV和AV。 為了進一步闡述這一需求,假設圖1中描述的合并場景。合并車輛(HV或AV)在高速公路上面對一群混合的AV和HV,需要它們減速以便合并。
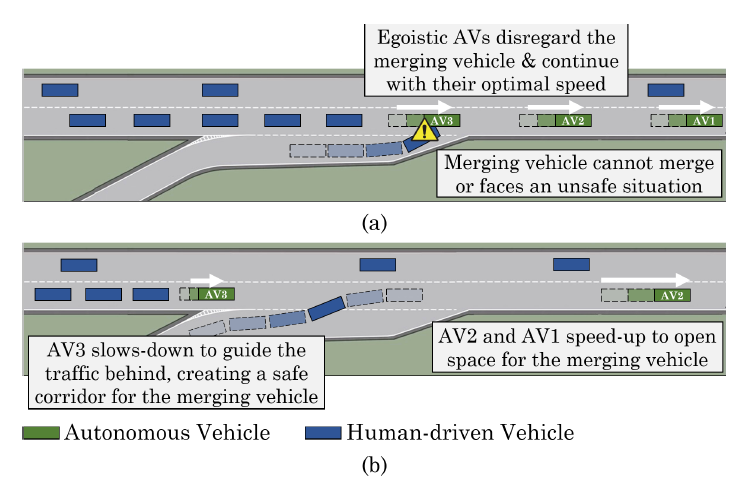
圖1:無縫和安全的高速公路并線需要所有的AV共同合作,并考慮到人類駕駛車輛的效用。 (上圖)利己主義的自動駕駛汽車只為自己的效用而優化,(下圖)利他主義的自動駕駛汽車在自己的福利上做出妥協,以顧及人類駕駛的車輛。
如果AVs自顧自地行動,那就得靠高速公路上的HVs來允許并線。由于人類的行為難以預測和不同,僅依靠人類駕駛員可能導致次優甚至不安全的情況。在這個特殊的例子中,假設是利己主義的AV,并線的車輛要么卡在并線匝道上,無法并線,要么等待HV,在不知道HV是否會減速的情況下冒險切入高速路。
另一方面,利他型自動駕駛汽車可以協同工作,引導高速公路上的交通,例如,如圖1(b)中AV3所做的那樣,通過減速后面的車輛,以實現無縫和安全的合并。這種利他主義的自動駕駛智能體可以在復雜的駕駛場景中創造出社會理想的結果,而不依賴于人類駕駛員的行為或對其進行假設。
自動駕駛汽車的利他行為可以通過量化每輛汽車將其他車輛(無論是HV還是AV)的效用納入其局部效用函數的意愿來形式化。這個概念被定義為社會價值取向(SVO),最近已從心理學文獻中被用于機器人和人工智能研究[3]。SVO決定了智能體人在他人面前表現出利己主義或利他主義的程度。
圖1(b)展示了AV的利他行為的一個例子,它們為合并的HV創造了一個安全的走廊,并實現了無縫合并。在混合自治的情況下,智能體要么是具有相同的SVO的同質性,要么可以直接獲得對方的SVO(通過V2V)。
然而,HV的效用和SVO是未知的,因為它們是主觀的和不穩定的,因此無法傳達給AV。
現有的社會導航工作通過預測人類駕駛者的行為[4]并避免與他們發生沖突,或者依賴于人類自然愿意或可以被激勵合作的假設[5]。通過明確地對人類行為進行建模,智能體可以利用合作機會,以實現對人類和自動駕駛智能體都有利的社會目標。然而,由于受疲勞、分心和壓力的影響,模型的時間變化以及信念建模技術對其他智能體行為的可擴展性,人類行為的建模往往具有挑戰性,因此限制了上述方法的實用性。基于模型預測控制(MPC)的方法通常需要設計成本函數和集中協調器[6]。因此,它們不適合協同自動駕駛,因為中央協調是不可行的。
另一方面,數據驅動的解決方案,如強化學習,在混合自治多智能體系統中受到挑戰,主要是由于智能體在非穩定的環境中同時進化。
考慮到這些缺點,自動駕駛汽車中的利他主義概念可以分為自動駕駛智能體內部的合作和自動駕駛智能體與人類司機之間的共情。將這兩部分分開有助于我們分別探究它們對實現社會目標的影響。我們的主要觀點是,確定一個社會效用函數可以在分散的自動駕駛智能體中誘發利他主義,并激勵它們相互合作,在沒有明確協調或人類SVO信息的情況下共情人類司機。我們所依賴的核心區別思想是,自動駕駛汽車經過訓練,可以為所有車輛達到最佳解決方案,學會僅從經驗中隱式地建模人類的決策過程。我們研究利他型自動駕駛汽車在缺乏共情和合作的情況下會變成安全威脅的行為。
換句話說,我們在與圖1中描述的性質相似的場景中進行實驗,這些場景基本上要求所有智能體一起工作,任何一個智能體都不能單獨獲得成功。我們的主要貢獻有以下幾點:
● 我們提出了一個數據驅動的框架--交感合作駕駛(SymCoDrive),它結合了一個分散的獎勵結構來模擬合作和交感,并采用三維卷積深度強化學習(DRL)架構來捕捉駕駛數據中的時間信息,
● 我們展示了調整汽車中的利他主義水平如何導致不同的新興行為,并影響交通流和駕駛安全,
● 我們在高速公路合并場景中進行了實驗,并證明我們的方法與利己主義的自動駕駛智能體相比,能提高駕駛安全性和社會理想的行為。
II.相關工作
多智能體強化學習。多智能體強化學習(MARL)的一個主要挑戰是環境的非平穩性。Foerster等人提出一個新的學習規則來解決這個問題[7]。
此外,通過從經驗重放緩沖器中提取訓練樣本進行裝飾的想法變得過時了,可以采用重要性采樣的多智能體推導,從重放緩沖器中刪除過時的樣本[8]。Xie等人也試圖通過使用伙伴策略的潛在表征來緩解這一問題,以實現更可擴展的MARL和伙伴建模[9]。
Foerster等人提出的反事實多智能體(COMA)算法使用集中的批評者和分散的行動者來解決多智能體環境中的信用分配問題[10]。在集中控制的情況下,對環境具有完全可觀察性的深度Q網絡可以用來控制一組智能體的聯合行動[11]。在混合自治的背景下,現有的文獻側重于通過對自治智能體(或自治智能體和人類)之間互動的性質進行假設來解決合作和競爭問題[12]。與這些工作相反,我們假設部分可觀察性和分散的獎勵函數,并旨在訓練交感合作自動駕駛智能體,不假設人類的行為。
混合自動駕駛中的自動駕駛。人類的駕駛方式可以通過逆向RL或采用統計模型從示范中學習[5], [13], [14]。對人類駕駛行為進行建模,可以幫助自動駕駛汽車確定與人類創造合作和互動機會的潛力,以實現安全和高效的導航[15]。此外,人類駕駛員能夠通過觀察鄰近車輛軌跡的細微變化,直觀地預測它們的下一步行動,并在需要時利用預測結果主動行動。受到這一事實的啟發,Sadigh等人揭示了自動駕駛汽車如何利用人類的這種有遠見的行為來塑造和影響他們的行為。在宏觀層面上,之前的工作已經證明了在混合自動駕駛場景中出現的人類行為,并研究如何利用這些模式來控制和穩定交通流[16], [17]。與我們的主題密切相關的是,最近在社交機器人導航方面的工作顯示了與人類合作規劃和互動的潛力[4],[18],[19]。
III.
多車交互問題
部分可觀測隨機對策(POSG)。 我們用元組MG:= (Z,s, [Ai], [oi], P, [Ti])定義的隨機對策來描述i = 1時的多車交互問題。, N,其中Z是一個有限的智能體集合,s表示狀態空間,包括N個智能體可以采用的所有可能的形式。在給定時間,智能體接收到局部觀測oi:S→Oi,并基于隨機策略πi: Oi x Ai→[0,1]在動作空間ai ? Ai內采取動作。
因此,智能體過渡到一個新的狀態si,,該狀態是根據狀態轉換函數Pr(s, |s, a): S xA1 x ... xAN → S確定的,并獲得一個獎勵ri : S x Ai → R。目標是推導出一個最優策略π *,使無限時間范圍內未來獎勵的貼現總和最大化。
在部分可觀察隨機對策(POSG)中,狀態轉移和獎勵函數通常是未知的,智能體只能訪問與狀態相關的局部觀測。 采用多代理強化學習,獨立的MARL代理可以一起工作,克服單一代理的物理限制,并超越他們[20]。在多車問題中,通過一個集中的MARL控制器來控制車輛是相當直接的,該控制器對環境具有完全的可觀察性,并為所有車輛分配一個集中的聯合獎勵 (Vi, j : ri 三 rj )。然而,這樣的假設在現實世界的自動駕駛應用中是不可行的,我們更關注分散的情況,即車輛具有部分可觀察性,并且不知道對方的行動。在這種情況下,代理人之間的協調預計將來自于我們引入的分散的獎勵函數,該函數使用本地觀察來估計其他車輛的效用。
深度Q網絡(DQN)。Q-learning已被廣泛應用于具有大狀態空間的強化學習問題中,它定義了一個狀態值函數 Qπ (s, a) := 以得出最優策略 π * (s) = arg maxaQ* (s, a) 其中 γ∈ [0, 1) 是一個折扣系數。 DQN[21]使用一個具有權重w的神經網絡,通過執行小批量梯度下降步驟來估計狀態-行動價值函數,即 wi+1 = 其中損失函數被定義為,
而是對wi處梯度的估計,wo是目標網絡的權重,在訓練中得到定期更新。(s, a, r, s’) 的集合從經驗重放緩沖器中隨機抽取,以消除方程(1)中訓練樣本的相關性。當代理人的政策在訓練過程中發生變化時,這種機制就會出現問題。
IV.交感合作駕駛
高速公路合并情況。 我們的基本場景是一個高速公路的并線匝道,其中一個并線車輛(HV或AV)試圖加入一個HV和AV的混合排,如圖1所示。由于其固有的競爭性質,我們特別選擇了這種情況,因為合并車輛的局部效用與巡航車輛的效用是一致的。我們確保只有一個AV向合并的車輛讓步不會使合并成為可能,為了使合并發生,基本上所有的AV都需要一起工作。在圖1(b)中,AV3必須減速并引導后面的車輛,這些車輛也許無法看到并線的車輛,而AV2和AV1則加速,為并線的車輛打開空間。如果任何車輛不合作或自作主張,交通安全和效率就會受到影響。
形式主義。考慮一個如圖1所示的路段,其中有一組自主車輛Z,一組人類駕駛的車輛V,以及一個任務車輛M∈Z∪V,可以是AV或HV,并試圖并入高速公路。HVs通常有一個有限的感知范圍,受到遮擋和障礙物的限制。在自動駕駛汽車的情況下,盡管我們假設沒有明確的協調,也沒有關于其他智能體的行動的信息,但自主智能體通過V2V通信連接在一起,這允許它們共享自己的態勢感知。利用這種擴展的態勢感知,代理人可以擴大他們的感知范圍,克服遮擋和視線能見度的限制。因此,雖然每個AV對環境有獨特的局部觀察,但他們可以看到其擴展感知范圍內的所有車輛,即他們可以看到AV的一個子集,和HV的一個子集。
為了模擬混合自動駕駛場景,我們部署了一組混合的HVs和AVs在高速公路上巡航,目標是在保持安全的情況下使其速度最大化。人類和自主代理之間的對比是,人類只關心自己的安全,而利他主義的自主代理試圖為群體的安全和效率進行優化。社會價值取向衡量了代理人行為中的利他主義水平。為了系統地研究代理人和人類之間的互動,我們將SVO中的共情和合作概念解耦。具體而言,我們將智能體與人類之間的利他行為視為共情,將智能體之間的利他行為稱為合作。這個定義背后的一個理由是,這兩者在本質上是不同的,因為當人類不一定愿意幫助代理人時,同情行為可能是單方面。
然而,合作是一種對稱的品質,因為所有的AV都部署了相同的政策,正如我們在實驗中看到的,無論人類是否愿意合作,都可以實現群體的社會目標。
分散式的獎勵結構。代理人Ii∈Z收到的本地獎勵可以分解為:
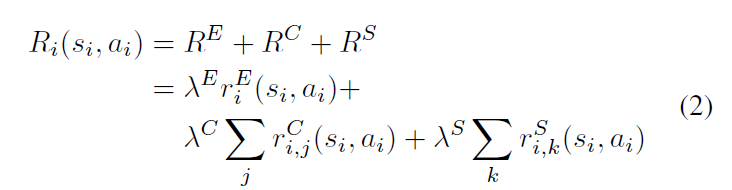
利他主義或利己主義的水平可以通過λE、λC和λS的系數來調整。方程(2)中的riE 分量表示當地的駕駛性能獎勵,這些獎勵來自于行駛距離、平均速度和加速變化的負成本,以促進車輛的平穩和高效的運動。合作獎勵項 ri,jC占觀察者代理的盟友的效用,即除Ii 之外的感知范圍內的其他AV。值得注意的是,Ii 只需要V2V信息來計算 RC 而不需要任何明確的協調或對其他代理的行動的了解。
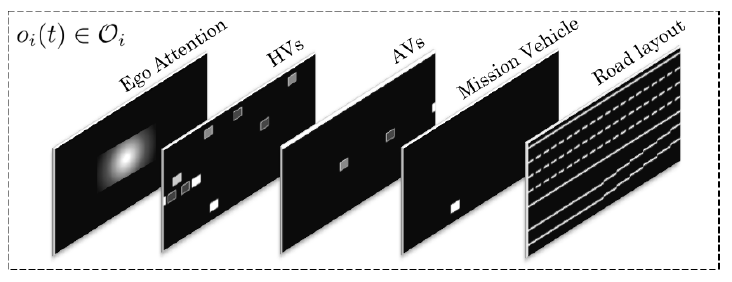
圖2:多通道速度圖的狀態表示將車輛的速度嵌入像素值中。
交感神經獎勵條款, ri,Sk 定義為:
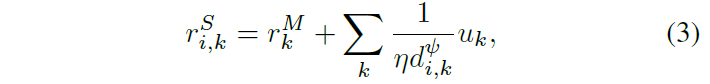
其中uk表示HV的效用,例如它的速度, di,k是觀察者自主代理和HV之間的距離,η和ψ是無尺寸系數。此外,在我們的駕駛場景中,特定的任務獎勵項 r kM代表合并機動的成功或失敗,形式為:

在訓練過程中,每個代理利用Deep RL對這個分散的獎勵函數進行優化,并學會在高速公路上行駛,并與盟友合作,創造出對AV和HV都有好處的社會理想形態。
狀態-空間和行動-空間。機器人導航問題可以從多個抽象層次來看待:從低層次的連續控制問題到高層次的元行動規劃。我們在這項工作中的目的是研究混合自動駕駛的智能體之間、智能體與人之間的交互以及行為方面的問題。因此,我們選擇一個更抽象的層次,將行動空間定義為一組離散的元行動ai∈Rn。
我們用兩種不同的局部狀態表示法進行實驗,以找到最適合我們問題的表示法。多通道速度圖表示法將AV和HV分成兩個通道,并將其相對速度嵌入像素值中。圖2說明了這種多通道表示法的一個例子。一個剪切的對數函數被用來將車輛的相對速度映射成像素值,因為它與線性映射相比顯示出更好的性能,即,
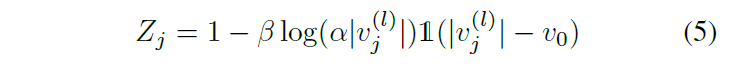
其中Zj 是狀態表示中第j輛車的像素值, v (l)是其在第k輛車視角下的相對Frenet縱向速度, 即,v0 是速度閾值,α 和 β 是無尺寸系數,1(.) 是Heaviside階梯函數。這種非線性映射更重視 |v(l)| 較小的相鄰車輛,幾乎忽略了比自我移動得更快或更慢的車輛。
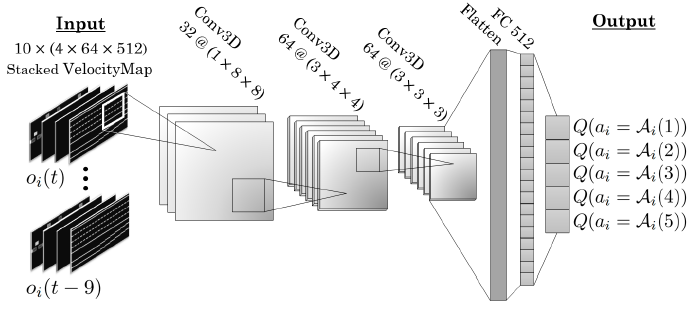
圖3:我們的三維卷積架構的深度Q網絡。
我們又增加了三個通道,嵌入了1)道路布局,2)強調自我位置的注意力圖,以及3)任務車輛。
另一個候選方案是占用網格表示,它直接將信息嵌入一個3維的張量oi ∈ Oi的元素中。從理論上講,這種表示與之前的VelocityMap非常相似,它們的對比是占用網格刪除了形狀和視覺特征,如邊緣和角落,并直接向網絡提供稀疏數字。更具體地說,考慮一個大小為W x H x F的張量,其中第n個通道是一個W x H矩陣,被定義為:
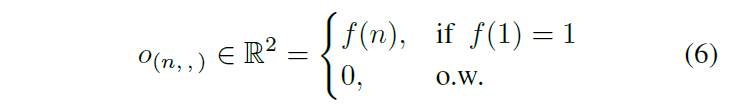
其中 f = [p,l, d, v(l), v (d) , sin δ, cos δ] 是特征集, p 是顯示車輛存在的二元變量, l 和 d 是相對的Frenet坐標,v (l) 和 v (d) 是相對的Frenet速度,δ是相對于全球基準測量的偏航角。
用深度MARL進行訓練。我們用Toghi等人、Mnih等人和Egorov等人在文獻中提出的3種現有架構作為我們的Q-learning問題的函數近似器進行實驗[11]、[21]、[22]。此外,我們還實現了一個三維卷積網絡,捕捉到了訓練情節中的時間依賴性,如圖3所示。我們網絡的輸入是10個VelocityMap觀測值的堆棧,即一個10 x (4 x 512 x 64)張量,它捕獲了劇情中的最后10個時間步驟。第五節至第七節對這些架構的性能進行了比較。
我們離線訓練單個神經網絡,并將學習到的策略部署到所有代理中,以便實時分布式獨立執行。為了解決MARL中的非平穩性問題,以半順序的方式訓練智能體,如圖4所示。每個代理被單獨訓練了k次,而其盟友w-的政策被凍結。然后,新的政策,w+,被傳播給所有代理,以更新他們的神經網絡。此外,受[23]的啟發,我們采用了一種新的經驗重放機制來補償我們高度傾斜的訓練數據。
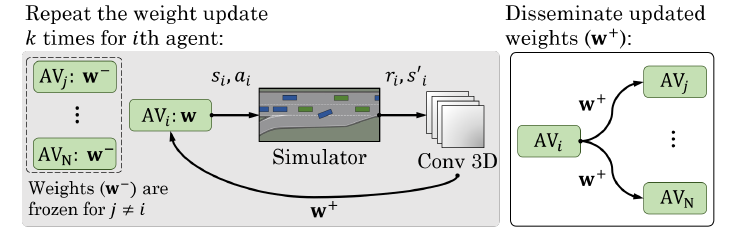
圖4:多智能體訓練和政策傳播過程。
一個訓練情節在語義上可以分為兩個部分,在筆直的高速公路上巡航和高速路并線。后者與前者在體驗重放緩沖中的比例很小,因為后者只發生在每集的短時間內。因此,從經驗回放緩沖區中統一取樣會導致與高速公路合并有關的訓練樣本太少。相反,我們將一個樣本從緩沖區抽出的概率設定為與它最后得到的獎勵和它與道路上合并點的空間距離成正比。平衡傾斜的訓練數據集是計算機視覺和機器學習中的常見做法,在我們的MARL問題上似乎也是有益的。
V.實驗與測試
A.駕駛模擬器的設置
我們定制了一個OpenAI Gym環境[24]來模擬高速路的駕駛和并線場景。在我們的模擬器框架中,運動學自行車模型描述車輛的運動,并使用閉環比例積分微分(PID)控制器將元動作轉換為低水平的轉向和加速度控制信號。特別是,我們選擇一組n=5的抽象動作作為 ai ∈ Ai = [左車道,空閑,右車道,加速,減速]T 。作為自動駕駛領域的一種常見做法,我們用Frenet-Serret坐標框架來表達路段和車輛的運動,這有助于我們將道路曲率從方程中剔除,并將控制問題分解為橫向和縱向部分。在我們的模擬環境中,HV的行為受Treiber等人和Kesting等人提出的橫向和縱向驅動模型支配[25], [26]。
為了確保我們所學政策的泛化能力,我們從一個剪切過的高斯分布中抽取所有車輛的初始位置,其平均值和方差經過調整,以確保初始化模擬落入我們所期望的合并場景配置。在測試階段,我們進一步隨機調整車輛的速度和初始位置,以探測代理處理未見過的和更具挑戰性的情況的能力。
B.計算詳情
使用NVIDIA Tesla V100 GPU和Xeon 6126 CPU @ 2.60GHz,SymCoDrive的PyTorch實現中的一次訓練迭代需要大約440ms。我們多次重復訓練過程,以確保所有運行都收斂到類似的新興行為和政策。在我們的硬件上,為15,000個情節訓練Conv3D網絡大約花了33小時。
政策執行頻率被設定為1Hz,在測試階段對網絡進行在線查詢大約需要10ms。我們花了大約4650個GPU小時來調整神經網絡和獎勵系數,以達到我們實驗的目的。
C.自主變量
我們進行了一組實驗,研究獎勵功能中的共情和合作部分如何影響自動駕駛智能體的行為和總體安全/效率指標。我們將圖1中的任務車輛合并車輛的情況與人類駕駛的任務車輛的雙場景進行比較。我們定義了2x4環境,其中任務車是AV或HV,其他自動駕駛智能體遵循自我主義、只合作、只共情或共情合作的目標:
● HV+E.任務載體是由人驅動的,自動駕駛智能體的行為是自我主義的,
● HV+C.任務車是由人類驅動的,自動駕駛智能體的獎勵中只有合作部分(RC),
●HV+S.任務車是由人驅動的,自動駕駛智能體只有共情(RS)元素,
●HV+SC.任務車是由人類驅動的,自動駕駛智能體的獎勵中既有同情(RS),也有合作(RC )的成分。
●AV+E/C/S/SC.與上述情況類似,不同的是任務車輛是自動駕駛的。
D.依賴性措施
我們實驗的性能可以從效率和安全方面來衡量。每輛車在模擬過程中的平均行駛距離是衡量效率的交通水平。發生碰撞的事件的百分比表明政策的安全性。計算沒有撞車和成功任務(并入高速公路)的場景數量,可以讓我們了解到我們的解決方案的整體效率。
E.假設
我們研究了三個關鍵假設:
●H1.在缺乏合作和共情的情況下,HV將無法安全地并入高速公路。因此,與HV+C和HV+E相比,我們預計HV+SC的性能會更好。
●H2.一輛自動駕駛任務車只需要它的盟友利他主義就能成功合并。我們不希望看到AV+SC和AV+C方案之間有明顯的差異;但是,我們假設它們都會優于AV+E。
●H3.調整代理人的利他主義水平會導致不同的新興行為,這些行為對效率和安全的影響是不同的。提高利他主義的水平可能會弄巧成拙,因為它會危及智能體學習基本駕駛技能的能力。
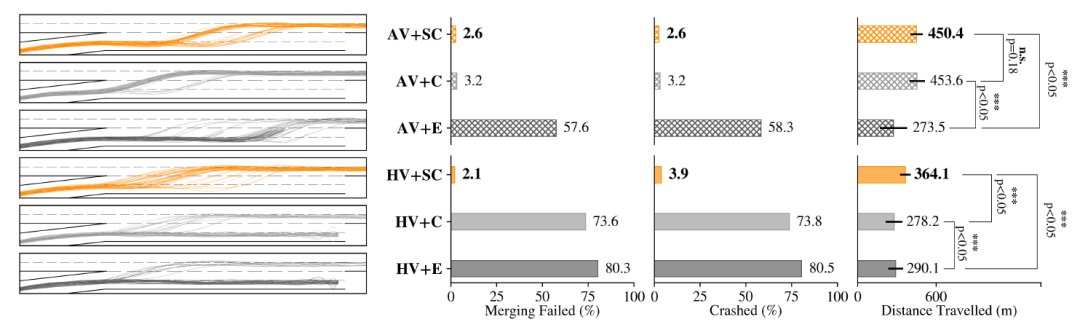
圖5:利己型、純合作型和富有共情心的合作型自動代理之間的比較,以及它們如何與自動(上)或人類駕駛(下)的任務車輛進行交互。左側顯示了一組采樣任務車輛的軌跡,與V-C節中定義的6個實驗設置有關。
F.結果
我們在隨機初始化的場景中訓練SymCoDrive代理15,000集,使用小標準偏差,并在3000個測試集中以4倍大的初始化范圍平均性能指標,以確保我們的代理不會在所見的訓練集中過度擬合。
1) 合作與共情:為了檢驗我們的假設H1,我們將重點放在人類駕駛任務車輛的場景,即HV+E, HV+C和HV+SC。圖5中的最后一行說明了我們對這些場景的觀察結果。很明顯,在獎勵功能中整合合作和共情元素(SC)的智能體比單純合作(C)或利己(E)的智能體表現出更好的性能。這種洞察力也反映在最右下方測量車輛平均行駛距離的柱狀圖中。由于公平和高效的交通流,HV+SC情景下的車輛顯然能成功行駛更遠的距離,而在HV+C和HV+E情景下,失敗的并線嘗試和可能發生的碰撞使性能惡化。圖5中最左邊的一欄是一組采樣的任務車輛軌跡的可視化。很明顯,在大多數事件中,合作的交感智能體成功地合并到高速公路上,而其他(C)和(E)智能體的大多數嘗試都失敗了。圖6通過比較從HV+E場景中提取的一組任務車輛軌跡和從HV+SC場景中提取的軌跡,為我們的討論提供了進一步的直觀認識。顯然,合作的交感主體使合并成功,而其他利己主義和單純合作的主體則無法做到這一點,這支持了我們的假設H1。
當務之急是對有自動駕駛任務車輛的場景重復上述實驗,因為人們可以認為HV+C和HV+E中失敗的任務和碰撞是由于我們為HV選擇的駕駛員模型的不足。為了準確地解決這一論點,圖5的最上面一行顯示了AV+E、AV+C和AV+SC的方案。首先,通過對兩種以自我為主體的場景,即AV+E和HV+E的比較,發現自動駕駛任務車輛的行為更具創造性,并探索了與公路合并的不同方式,因此AV+E的軌跡樣本比HV+E更廣泛。
接下來,比較利己主義的自動駕駛任務車和人類驅動的任務車在碰撞和合并失敗方面的表現,顯示自動駕駛代理通常更有能力找到一種方法來合并到人類和利己主義代理的隊列中。然而,它仍然在超過一半的合并嘗試中失敗。圖5驗證了我們的假設H2,因為我們可以觀察到,在代理中只增加一個合作部分,即AV+C方案,使任務車輛幾乎在所有的嘗試中都能并入高速公路。在AV+SC中加入共情元素,可以略微提高安全性,因為它激勵智能體注意那些沒有與他們發生直接碰撞風險的人類。我們認為合作是共情的促成因素,并沒有在只有同情的環境中進行任何實驗,因為其結果可以從(SC)和(C)的比較中推斷出來。2) 調整利他主義和新興行為:為了研究假設H3,我們訓練了一組智能體,并改變它們的獎勵系數,即 λE , λC , λS , 以調整它們的共情和合作水平。回顧在圖1中描述的駕駛場景,我們特別見證了代理人中兩個關鍵的新興行為。強烈同情心的代理人在接受訓練時,λS /(λC +λE )的比例很高,自然會把人類的利益放在首位,而不是自己的利益。圖7顯示了從兩個場景中提取的一組快照,其中包括強共情代理和弱共情代理。
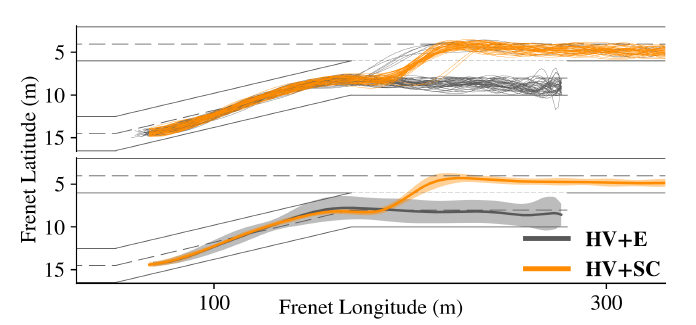
圖6:一組合并車輛的樣本軌跡顯示,與HV+E中的失敗嘗試相比,HV+SC中的合并嘗試大多成功。
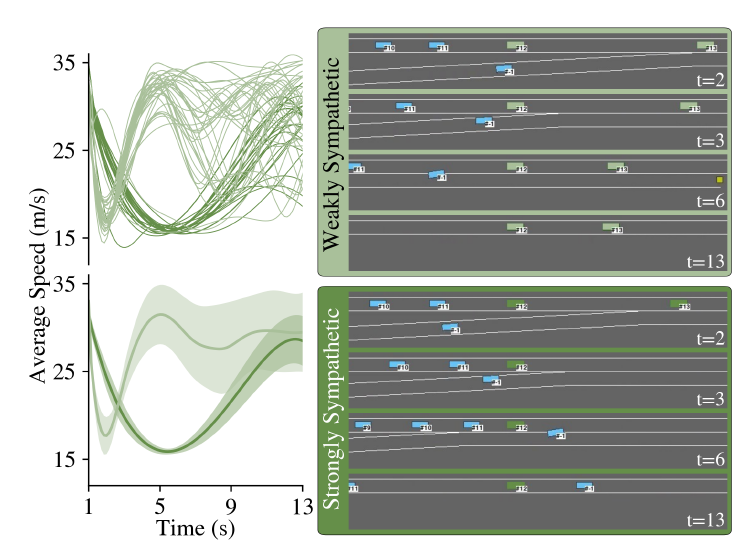
圖7:比較弱交感和強交感的自主代理。(左) "引導型AV"(考慮圖1(b)中的AV3)的速度曲線和(右)樣本快照。
一個強交感智能體(考慮圖1(b)中的AV3)會放慢速度并阻止后面的車輛群,以確保任務車輛獲得安全的合并路徑。另一方面,弱交感智能體最初會剎車以減緩后面的車輛,然后優先考慮自己的利益,加速并超過任務車輛。盡管這兩種行為都能使任務車輛成功合并,但圖7中智能體的速度分布描述了強烈共情的智能體如何在其行駛距離(速度曲線下的面積)上妥協,以最大化任務車輛的安全性。
在這一觀察的激勵下,我們徹底研究了調整方程(2)中的獎勵系數對SymCoDrive代理的性能所產生的影響。如圖8所示,我們從經驗上觀察到,在關心他人和自私自利之間存在一個最佳點,最終使群體中的所有車輛受益。
G.深度網絡和泛化
我們對第四節中介紹的網絡結構進行了訓練,并檢驗了它們對初始化隨機性范圍更廣的測試事件的概括能力,圖9顯示了網絡的訓練性能。
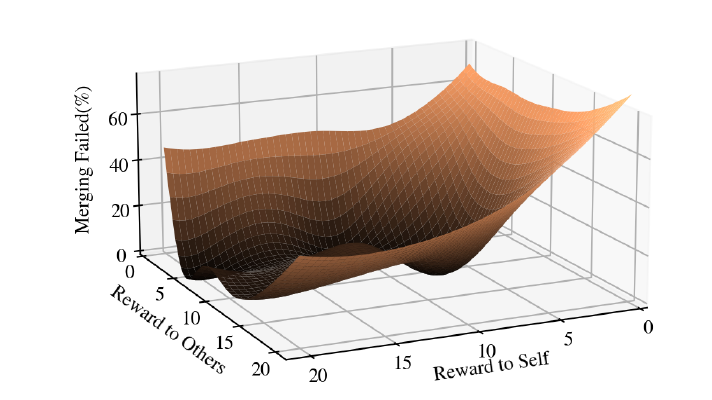
圖8:調整自主智能體的SVO表明,在關心他人和自私之間存在一個最佳點,最終有利于群體中的所有智能體。
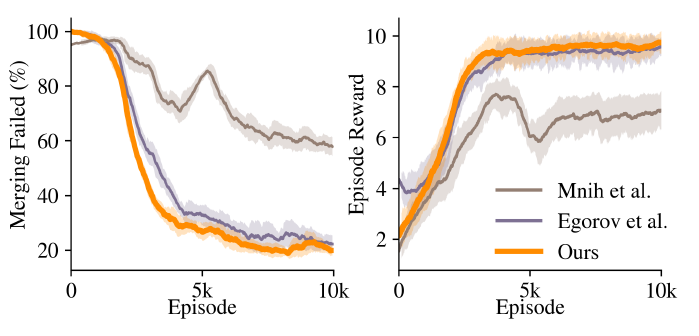
圖9:三種基準網絡結構的訓練性能。
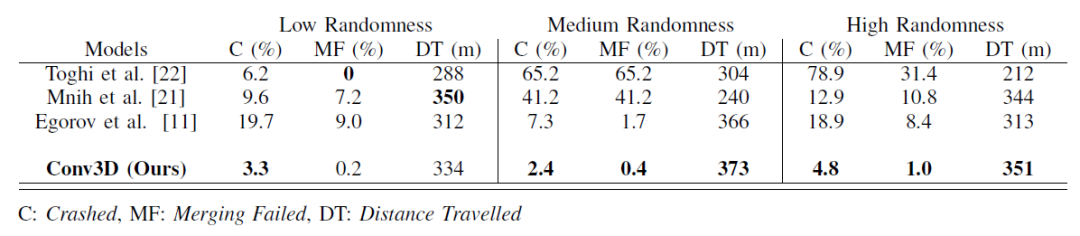
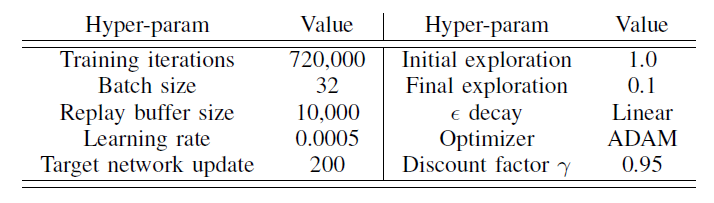
當在初始化隨機性范圍與訓練相同的情節中進行測試時,所有網絡都表現出可接受的性能。然而,當隨機范圍增加,代理人面臨與他們在訓練期間看到的不同的情節時,他們的表現迅速下降,如表I所述。雖然其他網絡在訓練過程中表現出色,但我們的Conv3D架構在更多樣化的測試場景中明顯優于他們。我們得出的結論是,使用VelocityMaps和我們的Conv3D架構,智能體學會了處理更復雜的看不見的駕駛場景。表二列出了我們用來訓練Conv3D架構的超參數。
公式(6)中定義的占用網格狀態空間表示,在我們的特定駕駛問題中,與VelocityMap表示相比,在所有神經網絡架構中表現出較差的性能。我們推測,這是因為占用網格表示沒有受益于VelocityMap狀態表示中嵌入的道路布局和視覺線索。
我們前面討論的所有實驗都是用VelocityMap表示的,除非另有說明。在調優VelocityMaps之后,我們得出結論,在狀態表示中集成一個硬的自我注意映射并沒有顯著的增強,并決定放棄這個通道,將通道的數量減少到4個。取而代之的是,我們將速度地圖的中心與自我對齊,使30%的觀察框反映自我后面的范圍,其余的顯示前面的范圍。我們注意到這個參數在訓練收斂和產生的行為中起著重要的作用,因為它使智能體能夠在任務車輛和其他車輛接近之前看到它們。
VI.結束語
我們解決了在混合自動駕駛環境中的自動駕駛問題,在這種環境中,自動駕駛車輛與人類駕駛的車輛進行互動。我們在MARL框架中加入了合作共鳴的獎勵結構,并訓練出相互合作的智能體,共情人類駕駛的車輛,因此與自我訓練的智能體相比,在競爭性的駕駛場景中,如高速公路并線,表現出更高的性能。
表一:相關架構的性能比較。隨著隨機程度的增加,我們的Conv3D架構表現優于其他架構,智能體面臨著與他們在訓練期間看到的不同的情節。
表二:我們的Conv3DQ網的超參數列表
局限性和未來的工作。我們目前的獎勵結構包括一個手工制作的標記,這取決于駕駛場景,例如,合并或退出高速公路。考慮到不同的駕駛事件,這個標記也可以從交互數據中學習,從而減少對特定任務獎勵項的需求。我們認為合并場景代表了我們觀察到的許多常見交互場景,包括其他需要兩個智能體調節速度和相互協調的行為,例如退出高速公路。我們只在相同的場景中對訓練和測試代理進行了實驗,并沒有在不同的場景中對它們進行交叉驗證。我們希望在未來將這項工作擴展到其他場景。我們相信,給定足夠大的訓練數據,智能體有望在一般駕駛場景中學習相同的利他行為。
審核編輯 :李倩
-
函數
+關注
關注
3文章
4333瀏覽量
62684 -
智能體
+關注
關注
1文章
152瀏覽量
10586 -
自動駕駛
+關注
關注
784文章
13836瀏覽量
166521
原文標題:能與人類駕駛者產生共鳴的合作型自動駕駛汽車技術
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論