

什么是表達式
表達式就是一個計算過程,類似于如下:
output_mid=input1+input2 output=output_mid*input3
用圖形來表達就是這樣的.
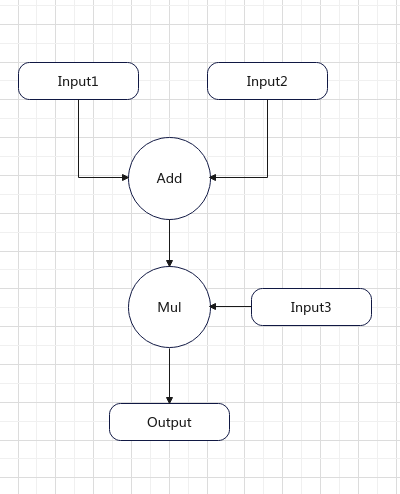
但是在PNNX的Expession Layer中給出的是一種抽象表達式,會對計算過程進行折疊,消除中間變量. 并且將具體的輸入張量替換為抽象輸入@0,@1等.對于上面的計算過程,PNNX生成的抽象表達式是這樣的.
add(@0,mul(@1,@2))抽象的表達式重新變回到一個方便后端執行的計算過程(抽象語法樹來表達,在推理的時候我們會把它轉成逆波蘭式)。
其中add和mul表示我們上一節中說到的RuntimeOperator, @0和@1表示我們上一節課中說道的RuntimeOperand. 這個抽象表達式看起來比較簡單,但是實際上情況會非常復雜,我們給出一個復雜的例子:
add(add(mul(@0,@1),mul(@2,add(add(add(@0,@2),@3),@4))),@5)
這就要求我們需要一個魯棒的表達式解析和語法樹構建功能.
我們的工作
詞法解析
詞法解析的目的就是將add(@0,mul(@1,@2))拆分為多個token,token依次為add ( @0 , mul等.代碼如下:
enumclassTokenType{
TokenUnknown=-1,
TokenInputNumber=0,
TokenComma=1,
TokenAdd=2,
TokenMul=3,
TokenLeftBracket=4,
TokenRightBracket=5,
};
structToken{
TokenTypetoken_type=TokenType::TokenUnknown;
int32_tstart_pos=0;//詞語開始的位置
int32_tend_pos=0;//詞語結束的位置
Token(TokenTypetoken_type,int32_tstart_pos,int32_tend_pos):token_type(token_type),start_pos(start_pos),end_pos(end_pos){
}
};
我們在TokenType中規定了Token的類型,類型有輸入、加法、乘法以及左右括號等.Token類中記錄了類型以及Token在字符串的起始和結束位置.
如下的代碼是具體的解析過程,我們將輸入存放在statement_中,首先是判斷statement_是否為空, 隨后刪除表達式中的所有空格和制表符.
if(!need_retoken&&!this->tokens_.empty()){
return;
}
CHECK(!statement_.empty())<
下面的代碼中,我們先遍歷表達式輸入
for(int32_ti=0;i
char c是當前的字符,當c等于字符a的時候,我們的詞法規定在token中以a作為開始的情況只有add. 所以我們判斷接下來的兩個字符必須是d和 d.如果不是的話就報錯,如果是i的話就初始化一個新的token并進行保存.
舉個簡單的例子只有可能是add,沒有可能是axc之類的組合.
elseif(c=='m'){
CHECK(i+1
同理當c等于字符m的時候,我們的語法規定token中以m作為開始的情況只有mul. 所以我們判斷接下來的兩個字必須是u和l. 如果不是的話,就報錯,是的話就初始化一個mul token進行保存.
}elseif(c=='@'){
CHECK(i+1
當輸入為ant時候,我們對ant之后的所有數字進行讀取,如果其之后不是操作數,則報錯.當字符等于(或者,的時候就直接保存為對應的token,不需要對往后的字符進行探查, 直接保存為對應類型的Token.
語法解析
當得到token數組之后,我們對語法進行分析,并得到最終產物抽象語法樹(不懂的請自己百度,這是編譯原理中的概念).語法解析的過程是遞歸向下的,定義在Generate_函數中.
structTokenNode{
int32_tnum_index=-1;
std::shared_ptrleft=nullptr;
std::shared_ptrright=nullptr;
TokenNode(int32_tnum_index,std::shared_ptrleft,std::shared_ptrright);
TokenNode()=default;
};
抽象語法樹由一個二叉樹組成,其中存儲它的左子節點和右子節點以及對應的操作編號num_index. num_index為正, 則表明是輸入的編號,例如@0,@1中的num_index依次為1和2. 如果num_index為負數則表明當前的節點是mul或者add等operator.
std::shared_ptrExpressionParser::Generate_(int32_t&index){
CHECK(indextokens_.size());
constautocurrent_token=this->tokens_.at(index);
CHECK(current_token.token_type==TokenType::TokenInputNumber
||current_token.token_type==TokenType::TokenAdd||current_token.token_type==TokenType::TokenMul);
因為是一個遞歸函數,所以index指向token數組中的當前處理位置.current_token表示當前處理的token,它作為當前遞歸層的第一個Token, 必須是以下類型的一種.
TokenInputNumber=0,
TokenAdd=2,
TokenMul=3,
如果當前token類型是輸入數字類型, 則直接返回一個操作數token作為一個葉子節點,不再向下遞歸, 也就是在add(@0,@1)中的@0和@1,它們在前面的詞法分析中被歸類為TokenInputNumber類型.
if(current_token.token_type==TokenType::TokenInputNumber){
uint32_tstart_pos=current_token.start_pos+1;
uint32_tend_pos=current_token.end_pos;
CHECK(end_pos>start_pos);
CHECK(end_pos<=?this->statement_.length());
conststd::string&str_number=
std::string(this->statement_.begin()+start_pos,this->statement_.begin()+end_pos);
returnstd::make_shared(std::stoi(str_number),nullptr,nullptr);
}
elseif(current_token.token_type==TokenType::TokenMul||current_token.token_type==TokenType::TokenAdd){
std::shared_ptrcurrent_node=std::make_shared();
current_node->num_index=-int(current_token.token_type);
index+=1;
CHECK(indextokens_.size());
//判斷add之后是否有(leftbracket
CHECK(this->tokens_.at(index).token_type==TokenType::TokenLeftBracket);
index+=1;
CHECK(indextokens_.size());
constautoleft_token=this->tokens_.at(index);
//判斷當前需要處理的lefttoken是不是合法類型
if(left_token.token_type==TokenType::TokenInputNumber
||left_token.token_type==TokenType::TokenAdd||left_token.token_type==TokenType::TokenMul){
//(之后進行向下遞歸得到@0
current_node->left=Generate_(index);
}else{
LOG(FATAL)<
如果當前Token類型是mul或者add. 那么我們需要向下遞歸構建對應的左子節點和右子節點.
例如對于add(@1,@2),再遇到add之后,我們需要先判斷是否存在left bracket, 然后再向下遞歸得到@1, 但是@1所代表的 數字類型,不會再繼續向下遞歸.
當左子樹構建完畢之后,我們將左子樹連接到current_node的left指針中,隨后我們開始構建右子樹.此處描繪的過程體現在current_node->left = Generate_(index);中.
index+=1;
//當前的index指向add(@1,@2)中的逗號
CHECK(indextokens_.size());
//判斷是否是逗號
CHECK(this->tokens_.at(index).token_type==TokenType::TokenComma);
index+=1;
CHECK(indextokens_.size());
//current_node->right=Generate_(index);構建右子樹
constautoright_token=this->tokens_.at(index);
if(right_token.token_type==TokenType::TokenInputNumber
||right_token.token_type==TokenType::TokenAdd||right_token.token_type==TokenType::TokenMul){
current_node->right=Generate_(index);
}else{
LOG(FATAL)<tokens_.size());
CHECK(this->tokens_.at(index).token_type==TokenType::TokenRightBracket);
returncurrent_node;
例如對于add(@1,@2),index當前指向逗號的位置,所以我們需要先判斷是否存在comma, 隨后開始構建右子樹.右子樹中的向下遞歸分析中得到了@2. 當右子樹構建完畢后,我們將它(Generate_返回的節點,此處返回的是一個葉子節點,其中的數據是@2) 放到current_node的right指針中.
串聯起來的例子
簡單來說,我們復盤一下add(@0,@1)這個例子.輸入到Generate_函數中, 是一個token數組.
add
(
@0
,
@1
)
Generate_數組首先檢查第一個輸入是否為add,mul或者是input number中的一種.
CHECK(current_token.token_type==TokenType::TokenInputNumber||
current_token.token_type==TokenType::TokenAdd||current_token.token_type==TokenType::TokenMul);
第一個輸入add,所以我們需要判斷其后是否是left bracket來判斷合法性, 如果合法則構建左子樹.
elseif(current_token.token_type==TokenType::TokenMul||current_token.token_type==TokenType::TokenAdd){
std::shared_ptrcurrent_node=std::make_shared();
current_node->num_index=-int(current_token.token_type);
index+=1;
CHECK(indextokens_.size());
CHECK(this->tokens_.at(index).token_type==TokenType::TokenLeftBracket);
index+=1;
CHECK(indextokens_.size());
constautoleft_token=this->tokens_.at(index);
if(left_token.token_type==TokenType::TokenInputNumber
||left_token.token_type==TokenType::TokenAdd||left_token.token_type==TokenType::TokenMul){
current_node->left=Generate_(index);
}
處理下一個token, 構建左子樹.
if(current_token.token_type==TokenType::TokenInputNumber){
uint32_tstart_pos=current_token.start_pos+1;
uint32_tend_pos=current_token.end_pos;
CHECK(end_pos>start_pos);
CHECK(end_pos<=?this->statement_.length());
conststd::string&str_number=
std::string(this->statement_.begin()+start_pos,this->statement_.begin()+end_pos);
returnstd::make_shared(std::stoi(str_number),nullptr,nullptr);
}
遞歸進入左子樹后,判斷是TokenType::TokenInputNumber則返回一個新的TokenNode到add token成為左子樹.
檢查下一個token是否為逗號,也就是在add(@0,@1)的@0是否為,
CHECK(this->tokens_.at(index).token_type==TokenType::TokenComma);
index+=1;
CHECK(indextokens_.size());
下一步是構建add token的右子樹
index+=1;
CHECK(indextokens_.size());
constautoright_token=this->tokens_.at(index);
if(right_token.token_type==TokenType::TokenInputNumber
||right_token.token_type==TokenType::TokenAdd||right_token.token_type==TokenType::TokenMul){
current_node->right=Generate_(index);
}else{
LOG(FATAL)<tokens_.size());
CHECK(this->tokens_.at(index).token_type==TokenType::TokenRightBracket);
returncurrent_node;
current_node->right=Generate_(index);///構建add(@0,@1)中的右子樹
Generate_(index)遞歸進入后遇到的token是@1 token,因為是Input Number類型所在構造TokenNode后返回.
if(current_token.token_type==TokenType::TokenInputNumber){
uint32_tstart_pos=current_token.start_pos+1;
uint32_tend_pos=current_token.end_pos;
CHECK(end_pos>start_pos);
CHECK(end_pos<=?this->statement_.length());
conststd::string&str_number=
std::string(this->statement_.begin()+start_pos,this->statement_.begin()+end_pos);
returnstd::make_shared(std::stoi(str_number),nullptr,nullptr);
}
至此, add語句的抽象語法樹構建完成.
structTokenNode{
int32_tnum_index=-1;
std::shared_ptrleft=nullptr;
std::shared_ptrright=nullptr;
TokenNode(int32_tnum_index,std::shared_ptrleft,std::shared_ptrright);
TokenNode()=default;
};
在上述結構中, left存放的是@0表示的節點, right存放的是@1表示的節點.
一個復雜點的例子
我們提出這個例子是為了讓同學更加透徹的理解Expression Layer, 我們舉一個復雜點的例子:
add(mul(@0,@1),@2),我們將以人工分析的方式去還原詞法和語法分析的過程.
例子中的詞法分析
我們將以上的這個輸入劃分為多個token,多個token分別為
add | left bracket| |mul|left bracket|@0|comma|@1|right bracket| @2 |right bracket
例子中的語法分析
在ExpressionParser::Generate_函數對例子add(mul(@0,@1),@2),如下的列表為token 數組.
add
(
mul
(
@0
,
@1
)
,
@2
)
index = 0, 當前遇到的token為add, 調用層為1
index = 1, 根據以上的流程,我們期待add token之后的token為left bracket, 否則就報錯. 調用層為1
**開始遞歸調用,構建add的左子樹.**從層1進入層2
index = 2, 遇到了mul token. 調用層為2.
index = 3, 根據以上的流程,我們期待mul token之后的token是第二個left bracket. 調用層為2.
開始遞歸調用用來構建mul token的左子樹.
index = 4, 遇到@0,進入遞歸調用,進入層3, 但是因為操作數都是葉子節點,構建好之后就直接返回了,得到mul token的左子節點.放在mul token的left 指針上.
index = 5, 我們希望遇到一個逗號,否則就報錯mul(@0,@1)中中間的逗號.調用層為2.
index = 6, 遇到@2,進入遞歸調用,進入層3, 但是因為操作數是葉子節點, 構建好之后就直接返回到2,得到mul token的右子節點.
index = 7, 我們希望遇到一個右括號,就是mul(@1,@2)中的右括號.調用層為2.
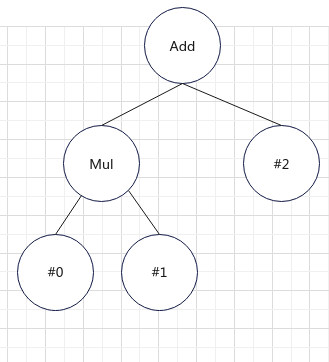
到現在為止mul token已經構建完畢,返回形成add token的左子節點,add token的left指針指向構建完畢的mul樹. 返回到調用層1.
...
add token開始構建right token,但是因為@2是一個輸入操作數,所以直接遞歸就返回了,至此得到add的右子樹,并用right指針指向.
所以構建好的抽象語法樹如圖:
實驗部分
需要完成test/tet_expression.cpp下的expression3函數
TEST(test_expression,expression3){
usingnamespacekuiper_infer;
conststd::string&statement="add(@0,div(@1,@2))";
ExpressionParserparser(statement);
constauto&node_tokens=parser.Generate();
ShowNodes(node_tokens);
}
staticvoidShowNodes(conststd::shared_ptr&node){
if(!node){
return;
}
ShowNodes(node->left);
if(node->num_indexnum_index==-int(kuiper_infer::TokenAdd)){
LOG(INFO)<num_index==-int(kuiper_infer::TokenMul)){
LOG(INFO)<num_index;
}
ShowNodes(node->right);
}
TEST(test_expression,expression1){
usingnamespacekuiper_infer;
conststd::string&statement="add(mul(@0,@1),@2)";
ExpressionParserparser(statement);
constauto&node_tokens=parser.Generate();
ShowNodes(node_tokens);
}
最后會打印抽象語法樹的中序遍歷:
Couldnotcreateloggingfile:Nosuchfileordirectory
COULDNOTCREATEALOGGINGFILE20230115-223854.21496!I202301152254.86322621496test_main.cpp:13]Starttest...
I202301152254.86348021496test_expression.cpp:23]NUM:0
I202301152254.86348821496test_expression.cpp:20]MUL
I202301152254.86349221496test_expression.cpp:23]NUM:1
I202301152254.86349721496test_expression.cpp:18]ADD
I202301152254.86350221496test_expression.cpp:23]NUM:2
如果語句是一個更復雜的表達式 add(mul(@0,@1),mul(@2,@3))
我們的單元測試輸出為:
I202301152222.08662723767test_expression.cpp:23]NUM:0
I202301152222.08663523767test_expression.cpp:20]MUL
I202301152222.08663923767test_expression.cpp:23]NUM:1
I202301152222.08664423767test_expression.cpp:18]ADD
I202301152222.08664923767test_expression.cpp:23]NUM:2
I202301152222.08665323767test_expression.cpp:20]MUL
I202301152222.08665823767test_expression.cpp:23]NUM:3
審核編輯:劉清
-
編程語法
+關注
關注
0文章
7瀏覽量
6968 -
深度學習
+關注
關注
73文章
5550瀏覽量
122376 -
Index
+關注
關注
0文章
5瀏覽量
3803
原文標題:自制深度學習推理框架-第7節-計算圖中的表達式
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

什么是正則表達式?正則表達式如何工作?哪些語法規則適用正則表達式?
shell正則表達式學習
請問labview如何計算字符串的正表達式?
防范表達式的失控

Python正則表達式的學習指南

Python正則表達式指南
Lambda表達式詳解
C語言的表達式






 工商網監
工商網監

評論