 Python-mysql 深入
Python-mysql 深入
數據庫設計
**三范式
**
- 經過研究和對使用中問題的總結,對于設計數據庫提出了一些規范,這些規范被稱為范式 (Nomal Form),目前有跡可錄的共有8種范式,一般需要遵守3范式即可
- 第一范式(1NF) : 強調列的原子性,即列不能再分成其他幾列
- 舉例: 設計一個表,有 姓名、年齡,電話 字段,如果電話有 移動電話和固定電話,就不符合 這一范式。應這么設計: 姓名、年齡、移動電話、固定電話
- 第二范式(2NF) :基于1NF之后,另外表里面必須有一個主鍵; 沒有包含在主鍵中的列必須完全依賴于主鍵,而不能只依賴于主鍵的一部分
- 舉例: 設計一個訂單收貨地址表,有 訂單號、區域價、收貨記錄id、收貨人詳細地址、收貨人名稱, 這時的主鍵應為 (訂單號、收貨記錄id), 區域價 需要依賴主鍵(訂單號、收貨記錄id),而 收貨人名稱和收貨人詳細地址,則只需依賴(收貨記錄id),所以這不符合這一范式。 應這么設計:將訂單收貨地址表拆分成兩個, 訂單信息表、收貨地址信息表。訂單信息表的字段為(訂單號、收貨記錄id、區域價);收貨地址信息表(收貨記錄id、收貨人名稱、收貨人詳細地址)
- 第三范式(3NF) :基于2NF之后,另外非主鍵列必須直接依賴于主鍵,不能傳遞依賴,即不能存在 非主鍵A依賴非主鍵B,非主鍵B依賴主鍵的情況
- 舉例:設計一個訂單表,有 訂單號、訂單金額、下單時間、采購人ID、采購人名稱、采購人地址,主鍵是(訂單號)。 這里面 采購人名稱、采購人地址是直接依賴 采購人id,不是直接依賴主鍵。應這么設計: 拆分成 訂單表和 采購人信息表, 訂單表字段為(訂單號、訂單金額、下單時間、采購人ID),采購人信息表(采購人ID、采購人名稱、采購人地址)
Python與MySql交互
步驟
- 安裝模塊: 使用pip命令安裝pymysql
-
pip install pymysql
-
- 引入模塊: 在py文件中引入pymysql模塊
-
from pymysql import *
-
- Connection對象
- Cursor對象
- 用于執行sql語句,使用頻率最高的語句是 select、insert、update、delete
- 獲取Cursor對象:調用Connection對象的cursor()方法
-
cus=conn.cursor()
-
- Cursor對象的方法
- close() 關閉
- execute(self, query, args) 執行語句,接收的參數為sql語句本身和使用的參數列表,返回值為受影響的行數
- fetchone()執行查詢語句,獲取查詢結果集的第一行數據,返回一個元組
- fetchmany()執行查詢時,獲取所有結果行,每行是一個元組,再將這些元組放入一個元組中返回
- 對象的屬性
- rowcount只讀屬性,表示最近一次execute()執行后受影響的行數
- connection獲得當前連接對象
示例
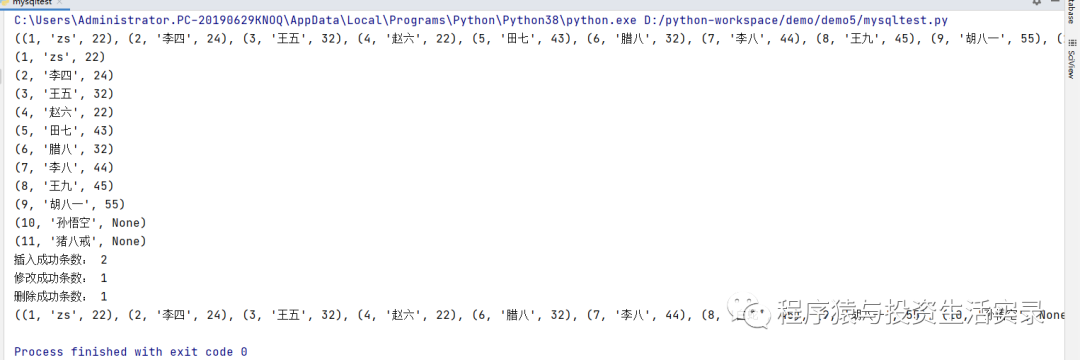
from pymysql import *
# 建立數據庫連接
conn=connect(host="localhost",port=3306,user="root",password="123456",database="python01",charset="utf8")
# 獲取Cursor對象
cursor=conn.cursor()
# 查詢數據表
cursor.execute("select *from person")
# 獲取所有結果集
lines=cursor.fetchall()
print(lines)
for line in lines:
print(line)
# 插入數據
count=cursor.execute("insert into person(id,name,age) values(12,'李天王',333),(13,'哪吒',222)")
print("插入成功條數:",count)
# 修改表數據
count=cursor.execute("update person set name='白蛇' where id=8")
print("修改成功條數:",count)
# 刪除表數據
count=cursor.execute("delete from person where id=5")
print("刪除成功條數:",count)
# 修改數據表后,需要提交
conn.commit()
# 再次查詢數據表
cursor.execute("select *from person")
print(cursor.fetchall())
# 關閉Cursor對象,關閉數據庫連接
cursor.close()
conn.close()
**輸出結果
**
MySQL高級
**視圖
**
- 視圖就是一條 SELECT 語句執行后返回的結果集 ,所以我們在創建視圖的時候,主要的工作就落在了SELECT查詢語句上
- 視圖是對若干張基本表的引用,一張虛表,查詢語句執行的結果,不存儲具體的數據(基本表數據發生了改變,視圖也會跟著改變)
定義視圖
- 建議以 v_ 開頭
create view 視圖名稱 as select 語句;
查看視圖
- 查看表會將所有的視圖也列出來
show tables;
使用視圖
- 視圖的用途就是查詢
select * from v_person
刪除視圖
drop view 視圖名稱;
視圖的作用
- 提高了重用性,就像是一個函數
- 創建視圖的源數據被修改了,視圖中的數據也會被修改,與windows的快捷方式很像(對數據庫重構,卻不影響程序的運行)
- 提高了安全性,可以對不同的用戶
- 讓數據更加清晰
示例
# 創建視圖, 查詢訂單與訂單收貨 信息表,生成一個虛擬表(視圖)
create view v_order_info as SELECT a.order_no,a.order_price,b.receive_name,b.receive_phone FROM `order` a, order_receive b where a.order_no=b.order_no;
# 查看視圖的內容
SELECT * from v_order_info;

**事務
**
- 所謂事務,它是一個操作序列,這些操作要么都執行成功,要么都執行失敗, 是一個不可分割的工作單位。
- 舉例:銀行轉賬,第一次轉100,第二次轉200,都放到一個事務里面,要么全部轉成功,要么都失敗
事務的四大特性(ACID)
- 原子性
- 強調事務不可分割,整個事務中的所有操作要么全部成功,要么全部失敗
- 一致性
- 事務的執行的前后數據的完整性保持一致,即上面轉賬的例子中,如果轉了一半的錢,系統崩潰了,但是事務最終沒有提交,那么在事務中做的修改也不會保存到數據庫中
- 隔離性
- 一個事務執行的過程中,不應該受到其它事務的干擾
- 持久性
- 一旦事務提交,則其所做的修改會永久保存到數據庫
**事務的命令
**
- 表的引擎類型必須是 innodb類型才可以使用事務,這是mysql表的默認引擎
- 開啟事務
- 開啟事務后執行修改命令,變更會維護到本地緩存中,而不維護到物理表中
-
begin; 或者 start transaction;
- 提交事務
- 將緩存中的數據變更維護到物理表中
-
commit;
- 回滾事務
- 放棄緩存中變更的數據
-
rollback;
- 注意
- 默認修改數據的sql語句會自動觸發事務(開啟與提交),即 insert、update、delete 語句
- 一般在sql語句中手動開啟事務的原因是:可以進行多次數據的修改,如果成功則一起成功,否則一起失敗
**示例
**
BEGIN;
# 修改person表,id=1 的名稱 (此語句執行后,由于沒有提交,別的查詢語句查詢時,不會查到修改的數據)
update person set name='小白' where id=1;
# 提交事務,這個語句執行后,數據表中的名稱變更為 小白
COMMIT;
事務隔離級別要解決的問題
- 臟讀
- 臟讀指的是讀到了其他事務未提交的數據,未提交意味著這些數據可能會回滾,也就是可能最終不會存到數據庫中,也就是不存在的數據。讀到了并一定最終存在的數據,這就是臟讀
- 舉例: 小明的媳婦給小明打500塊錢買衣服,但是不小心按成了1000塊,事務還沒有提交,小明這時查到卡里有1000元,小明的媳婦發現不對后就回滾了事務,這時小明卡里的錢就沒了
- 不可重復讀
- 不可重復讀指的是在同一事務內,不同的時刻讀到的同一批數據可能是不一樣的,可能會受到其他事務的影響,比如其他事務改了這批數據并提交了
- 舉例: 小明卡里有1000元,買了衣服準備結賬(事務開啟),這時他媳婦將小明卡里的錢轉出來了,收費系統提示卡里面沒錢了,小明郁悶了。同一事務內相同的查詢語句,出現了不同的結果就是不可重復讀
- 幻讀
- 幻讀是針對數據插入(INSERT)操作來說的。假設事務A對某些行的內容作了更改,但是還未提交,此時事務B插入了與事務A更改前的記錄相同的記錄行,并且在事務A提交之前先提交了,而這時,在事務A中查詢,會發現好像剛剛的更改對于某些數據未起作用,但其實是事務B剛插入進來的,讓用戶感覺很魔幻,感覺出現了幻覺,這就叫幻讀。
- 舉例:小明某天花了1000元錢消費,他媳婦查看了當天的消費記錄(全表掃描,事務開啟),看到確實花了1000元,就在這時,小明又花了1000元買了件衣服,并提交了事務,當他媳婦打印消費清單時(事務提交),發現花了2000元,以為出現了幻覺,這就是幻讀
事務的隔離級別
- SQL 標準定義了四種隔離級別,MySQL 全都支持。這四種隔離級別分別是:
- 讀未提交(READ UNCOMMITTED)
- 讀已提交(READ COMMITTED)
- 可重復讀(REPEATABLE READ)
- 串行化(SERIALIZABLE)
- 從上往下,隔離強度逐漸增強,性能逐漸變差。采用哪種隔離級別要根據系統需求權衡決定,其中, 可重復讀是 MySQL 的默認級別 。
- 事務隔離其實就是為了解決上面提到的臟讀、不可重復讀、幻讀這幾個問題,下面展示了 4 種隔離級別對這三個問題的解決程度
| 隔離級別 | 臟讀 | 不可重復讀 | 幻讀 |
|---|---|---|---|
| 讀未提交 | 可能 | 可能 | 可能 |
| 讀已提交 | 不可能 | 可能 | 可能 |
| 可重復讀 | 不可能 | 不可能 | 可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
- 索引是一種特殊的文件 (InnoDB 數據表上的索引是表空間的一個組成部分),它們包含著對數據表里面所有記錄的引用指針。通俗來講,索引就好比一本書前面的目錄,能加快數據查詢的速度
- 索引的目的在于提高查詢效率,可以類比字典
索引的使用
- 查看索引
show index form 表名;
- 創建索引
ALTER TABLE 表名
ADD UNIQUE INDEX 索引名 (字段) USING BTREE ;
- 刪除索引
ALTER TABLE 表名
DROP INDEX 索引名;
示例
-
**創建一個數據表,并插入99萬條記錄,用作測試索引
**
CREATE TABLE `test_index` (
`id` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
from pymysql import *
# 建立數據庫連接
conn=connect(host="localhost",port=3306,user="root",password="123456",database="python01",charset="utf8")
# 獲取Cursor對象
cursor=conn.cursor()
for i in range(100000):
cursor.execute("insert into test_index(id,name) values (%d,'testindex')" %i)
# 修改數據表后,需要提交
conn.commit()
# 關閉Cursor對象,關閉數據庫連接
cursor.close()
conn.close()
- 開啟運行時間監測
set profiling=1
- 在整個表中查找 id=88888的記錄
SELECT * from test_index where id=88888;
- 查看執行時間
show profiles;
- 為id字段添加索引
ALTER TABLE `test_index`
ADD UNIQUE INDEX `idx_id` (`id`) USING BTREE ;
- 添加索引后再次查詢
SELECT * from test_index where id=88888;
- 再次查看執行時間
show PROFILES;
最終結果

注意
-
**建立太多的索引會影響更新和插入數據的速度,因為它需要同樣更新每個索引文件,對于一個經常更新和插入的表格,沒有必要為一個很少使用的where子句單獨建立索引。 **
-
**建立索引會占用磁盤空間
**
MySQL的主從
- 定義
- 主從同步使用數據可以從一個服務器上復制到其它服務器上,在復制數據時,一個服務充當主服務器(master),其余的服務器充當從服務器(slave),因為復制是異步進行的,所以從服務器不需要一直連接主服務器,從服務器甚至可以通過撥號斷斷續續地連接主服務器,通過配置文件可以指定復制所有的數據庫、某個數據庫、甚至某個數據上的某個表
- 主從同步的好處
- 通過增加從服務器來提高數據庫的性能,在主服務器上執行寫入和更新,在從服務器上向外提供讀功能,可以動態的調整從服務器的數量,從而調整整個數據庫的性能。
- 提高數據的安全性,因為數據復制到了從數據庫,如果一旦主服務器掛掉了,可以使用從服務器上的數據
- 在主服務器上生成實時數據,在從服務器上分析這些數據,從而提高服務器的性能
- 主從同步機制
- Mysql服務器之間的主從同步是基于二進制日志機制,主服務器使用二進制日志來記錄數據庫的變動情況,從服務器通過讀取和執行該日志文件來保持和主服務器的數據一致性
- 在使用二進制日志時,主服務器的所有操作都會被記錄下來,然后從服務器會接收到該日志的一個副本。從服務器可以指定執行該日志文件中的哪一類事件(比如只插入數據或只更新數據)。默認會執行日志中的所有語句

- 配置主從同步的基本步驟
- 在主服務器上,必須開啟二進制日志機制和配置一個獨立的ID
- 在每一個服務器上,配置一個唯一的ID,創建一個用來專門復制主服務器數據的賬號
- 在開始復制進程前,在主服務器上記錄二進制文件的位置信息
- 如果在開始復制之前,數據庫中已經有數據,就必須先創建一個數據快照(可以使用mysqldump導出數據庫,或者直接復制數據文件)
- 配置從服務器要連接的主服務器的ip地址和登陸授權,二進制日志文件名和位置
- 詳細配置主從同步方法
- 主和從的身份可以自己指定,我將虛擬機centOs中的Mysql作為主服務器,將window中的mysql作為從服務器,在主從設置之前,要保證centOs與windows間的網絡能互通
- 如果 在設置主從同步前,主服務器上已有大量數據,可以使用mysqldump進行數據備份并還原到從服務器上實現數據復制
- 在主服務器上執行命令進行備份
-
mysqldump -uroot -pmysql --all-databases --lock-all-tables > /tmp/master_data.sql - 說明
- -u:用戶名
- -p:密碼
- --all-databases:表示導出所有數據庫
- --lock-all-tables:執行操作時鎖住所有表,防止操作時數據被修改
- /tmp/master_data.sql:導出文件存放的位置
-
- 在從服務器上讀取剛在主服務器上生存的數據文件
-
mysql -uroot -p密碼 新數據庫名 < master_data.sql
-
- 編寫mysqld的配置文件,設置Log_bin和server-id (注:把#刪除)
-
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf -
log_bin = var/log/mysql/mysql-bin.log server-id = 1 - 重啟mysql服務
-
server mysql restart
-
- 登陸主服務器中的Mysql,創建用于從服務器同步數據使用的賬號
-
mysql -uroot -p密碼 -
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' identified by 'slave'; -
FLUSH PRIVILEGES;
-
- 獲取主服務器二進制日志信息
-
SHOW MASTER STARTS;
-
- 配置從服務器的mysqld文件,server-id與主服務器不一致即可,然后重新啟動
- 在從服務器進入mysql中執行以下命令
-
change master to master_host='主服務器ip地址' ,master_user=’slave',master_password='slave',master_log_file='mysql-bin.000006',master_log_pos=590 - 注:以上配置的master_log_file 和 master_log_pos 可通過在主服務器上進入mysql輸入以下命令查看
-
show master status;
-
- 開啟同步,查看同步狀態(進入mysql,執行以下命令)
-
start slave; -
show slave status \\G; - **在顯示的信息中看到 Slave_IO_Runnig: YES 和 Slave_SQL_Running:YES 就表示同步成功 **
- 注: 如果沒有顯示YES,說明沒配置成功,原因可能是 從命令中的 change master中的配置沒配置好,要仔細檢查
-
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據庫
+關注
關注
7文章
3822瀏覽量
64506 -
規范
+關注
關注
0文章
46瀏覽量
16336 -
MySQL
+關注
關注
1文章
817瀏覽量
26623
發布評論請先 登錄
相關推薦
Python存儲數據詳解
在Python開發中,數據存儲、讀取是必不可少的環節,而且可以采用的存儲方式也很多,常用的方法有json文件、csv文件、MySQL數據庫、Redis數據庫以及Mongdb數據庫等。1. json
發表于 03-29 15:47
Python+Django+Mysql實現在線電影推薦系統
Python+Django+Mysql實現在線電影推薦系統(基于用戶、項目的協同過濾推薦算法)一、項目簡介1、開發工具和實現技術pycharm2020professional版本,python
發表于 01-03 06:35
如何使用Python操作MySQL數據庫
使用Python進行MySQL的庫主要有三個,Python-MySQL(更熟悉的名字可能是MySQLdb),PyMySQL和SQLAlchemy。

如何使用python將txt文件導入到mysql的應用實例
實現思想: 1、python 自動完成在txt 文件中加入自定義標簽(簡單的txt 文件可以不需要) ,2、python 自動完成將含有自定義標簽的txt 文件導入到mysql。除了原始txt 文件
發表于 09-09 17:50
?12次下載

python程序里如何鏈接MySQL數據庫
在python程序里,如何鏈接MySQL數據庫? 連接MYSQL需要3步 1、安裝 必須先安裝MySQL驅動。和PHP不一樣,Python只
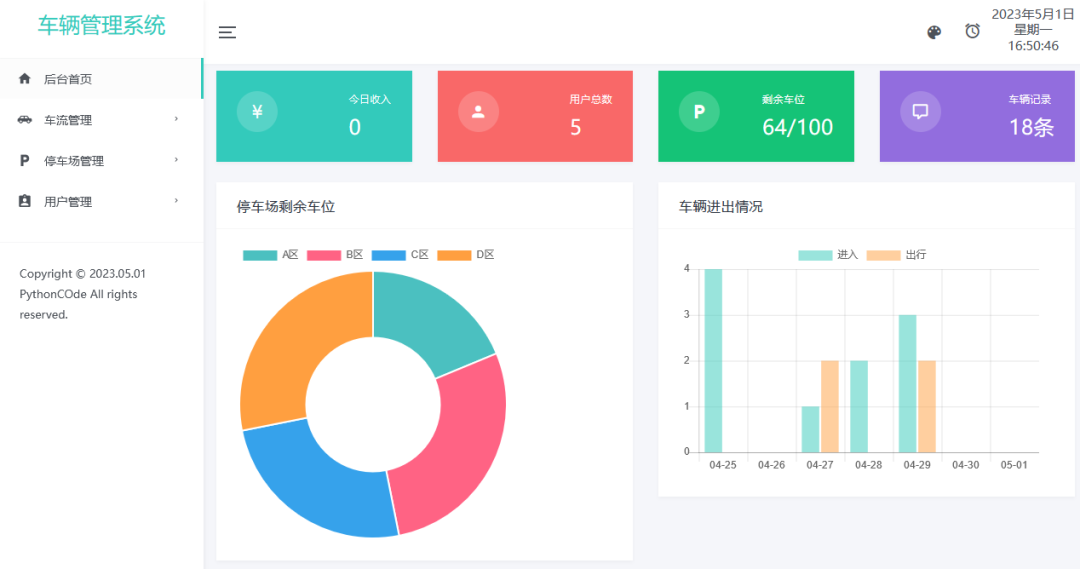
Python基于Flask+MySQL的車輛管理系統
基于Python+Django+MySQL的車輛管理系統,采用Echart構建圖表,支持一鍵切換顏色主題,通過連接數據庫獲取車輛信息。
發表于 06-07 15:21
?757次閱讀





 工商網監
工商網監
評論