") BEV+Transformer對智能駕駛硬件系統(tǒng)有著什么樣的影響?
BEV+Transformer對智能駕駛硬件系統(tǒng)有著什么樣的影響?
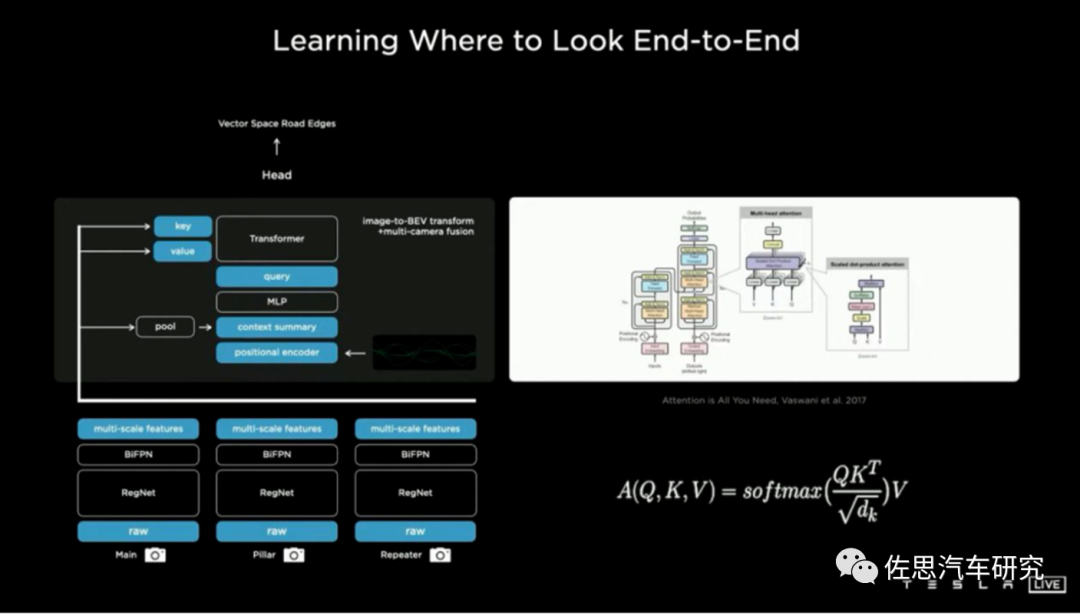
圖片來源:特斯拉
BEV+Transformer是目前智能駕駛領域最火熱的話題,沒有之一,這也是無人駕駛低迷期唯一的亮點,BEV+Transformer徹底終結(jié)了2D直視圖+CNN時代,BEV+Transformer對智能駕駛硬件系統(tǒng)有著什么樣的影響?背后的受益者又是誰?
先說結(jié)論。首先受益者是視覺系統(tǒng)廠家,車輛至少要增加4-6個攝像頭,不過目前新興造車企業(yè)都已經(jīng)準備好了這些硬件基礎,此外需要6-8個加串行芯片,2-3個解串行芯片,加串行與解串行的市場基本被德州儀器和ADI旗下的美信壟斷,美信獨占了中高端市場,這些芯片價格隨著像素的上升也大幅度增加,數(shù)量也增加了,最終成本幾乎與主SoC一樣價格,讓ADI業(yè)績大漲。
其次是英偉達這樣的強大數(shù)據(jù)訓練系統(tǒng)廠家,Transformer就是暴力美學,參數(shù)量動輒十億百億千億,萬億也不罕見,層數(shù)動輒上千層,根本不是老舊數(shù)據(jù)訓練中心能支撐的,需要大量購買英偉達或AMD的上萬美元級的訓練芯片。以前做訓練的RTX3090,現(xiàn)在只能做推理用了。毫無疑問這讓研發(fā)成本暴增。
再次是存儲系統(tǒng),Transformer模型體積驚人,動輒GB起,這需要芯片上的L2緩存大增,實際就是消耗大量的SRAM,對數(shù)據(jù)訓練中心和嵌入式系統(tǒng)來說就是芯片價格暴漲,如果用不起昂貴的SRAM,數(shù)據(jù)中心這一級也要用HBM。對推理的嵌入式系統(tǒng)來說,HBM的價格太高,消費級的汽車市場是無法接受的,只能退一步選擇LPDDR5或GDDR5/6,容量要大幅度增加,至少32GB起,成本自然也大幅增加。
最后是數(shù)據(jù)搜集和標注,Transformer需要海量訓練數(shù)據(jù),越多越好,意味著智能駕駛廠家需要更多的數(shù)據(jù)采集車,數(shù)據(jù)采集設備,更多的數(shù)據(jù)處理人員,研發(fā)成本暴增。2D直視圖+CNN時代廠家累積起來的研發(fā)成果化為烏有,很多事情都要從頭做起,意味著以前的研發(fā)成果貶值嚴重。最終這一切都轉(zhuǎn)換為消費者頭上的成本,成本至少增加300%。
激光雷達和傳統(tǒng)AI芯片也將受到影響。首先是激光雷達,BEV+Transformer讓純視覺更加強大,接近以前激光雷達制造BEV的效果,廠家都一窩蜂地擁抱BEV+Transformer,冷落激光雷達。其次是推理用的AI芯片,之前的AI芯片大多是針對CNN的,對Transformer的適應性會比較差,畢竟Transformer是源自自然語言處理(NLP)的,數(shù)據(jù)的串行性很顯著,并行性不佳,這需要AI芯片做出對應的改變,并且是硬件上的改變,這可能意味著推倒重來,或者用更強的Host來對數(shù)據(jù)整形,也就是標量運算即CPU要加強,Cortex-A55恐怕是無法勝任的。
再有原本智能駕駛AI專用芯片都特別針對INT8精度,但Transformer簡單量化為8位后性能顯著下降,這主要是由于普通的激活函數(shù)量化策略無法覆蓋全部的取值區(qū)間。參數(shù)越多,量化后的效果就越差。引入BF16非常有必要,而以前設計的AI芯片大多沒考慮BF16。
我們來簡單了解一下BEV+Transformer,基于多視角攝像頭的3D目標檢測在鳥瞰圖下的感知(Bird's-eye-viewPerception, BEV Perception)吸引了越來越多的關注。一方面,將不同視角在BEV下統(tǒng)一表征是很自然的描述,方便后續(xù)規(guī)劃控制模塊任務;另一方面,BEV下的物體沒有圖像視角下的尺度(scale)和遮擋(occlusion)問題。
目前BEV+Transformer算法對比都是基于nuScenes數(shù)據(jù)集的,因為其訓練數(shù)據(jù)最多,在小尺寸的Kitti上,Transformer表現(xiàn)不如CNN。
nuScenes與其他數(shù)據(jù)集的對比
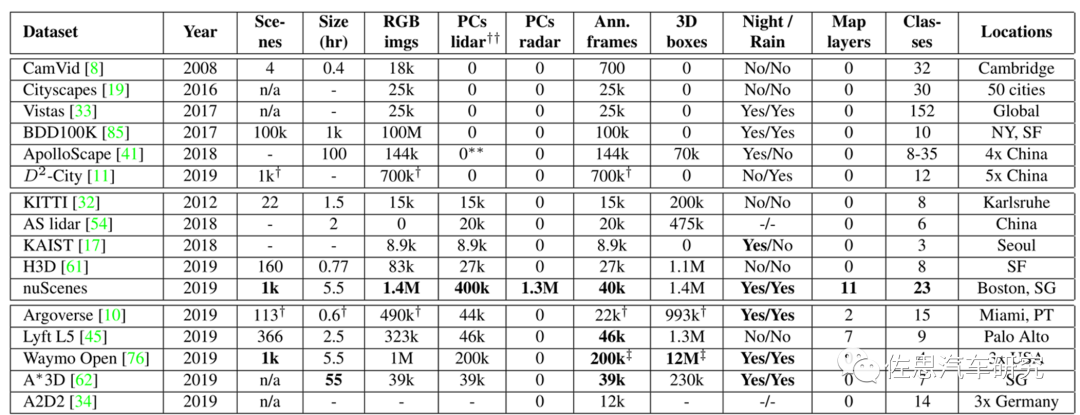
圖片來源:《nuScenes: A multimodal dataset for autonomous driving》
nuScenes是唯一有毫米波雷達的數(shù)據(jù)集。論文名稱《nuScenes:A multimodal dataset for autonomous driving》,這是智能駕駛領域最具影響力的數(shù)據(jù)集,完成于2019年3月,2020年7月推出nuScenes-lidarseg,nuTonomy提出的激光雷達點柱算法也是目前最常用的激光雷達算法。nuScenes-lidarseg則是激光雷達最完備的測試數(shù)據(jù)集,包含850個訓練場景,150個測試場景,驚人的14億標注點,4萬點云幀,32級分類。nuScenes目前由安波福與現(xiàn)代汽車的合資公司Motional維護。
BEV+Transformer基本概念
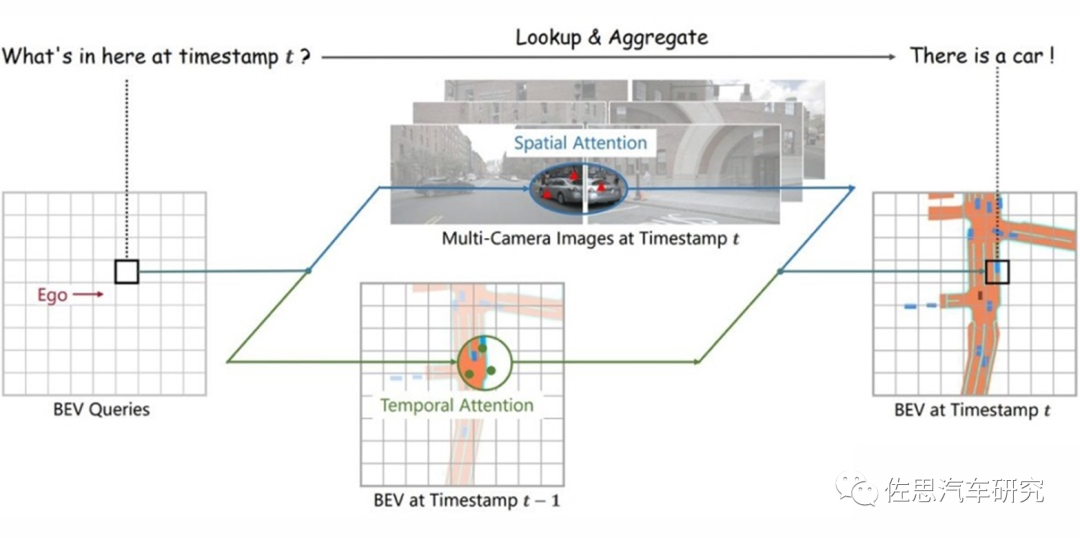
圖片來源:《BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via SpatiotemporalTransformers》
CNN時代,完全拋棄了時間序列,智能駕駛檢測的是圖片而非視頻,因此在靜止目標識別方面要差很多,也很難定位目標的具體位置,因為移動目標位置是變換的,需要加入時間序列變量。光流加入了時間序列變量,但是單目光流法效果很差,因為光流都是基于立體雙目或激光雷達發(fā)展而來的,特別是立體雙目,做光流尤其合適,奔馳是這方面的頂尖高手,開發(fā)了所謂6D視覺,其中光流就是另外3D的構(gòu)成,不僅能檢測目標的速度,還能推斷目標的時間序列位置。
Transformer與CNN最大不同就是加入了時序信息,而BEV是一個空間概念,BEV+Transformer就是時空融合,時序信息對于自動駕駛感知任務十分重要,但現(xiàn)階段基于視覺的3D目標檢測方法并沒有很好地利用上這一非常重要的信息。時序信息一方面可以作為空間信息的補充,來更好地檢測當前時刻被遮擋的物體或者為定位物體的位置提供更多參考信息。另一方面就是對靜止目標的處理更加快速高效。
對于每一個位于(x,y)位置的BEV特征,我們可以計算其對應現(xiàn)實世界的坐標 x',y'。然后我們將BEV query進行l(wèi)ift操作,獲取在z軸上的多個3D points。有了3D points,就能夠通過相機內(nèi)外參獲取3Dpoints在view平面上的投影點。受到相機參數(shù)的限制,每個BEV query一般只會在1-2個view上有有效的投影點。
基于Deformable Attention,我們以這些投影點作為參考點,在周圍進行特征采樣,BEV query使用加權(quán)的采樣特征進行更新,從而完成了spatial空間的特征聚合。將BEV特征視為類似能夠傳遞序列信息的memory。每一時刻生成的BEV特征都從上一時刻的BEV特征獲取了所需的時序信息,這樣保證能夠動態(tài)獲取所需的時序特征,而非像堆疊不同時刻BEV特征那樣只能獲取定長的時序信息。
Transformer會瘋狂消耗內(nèi)存,內(nèi)存容量與輸入序列長度的平方成正比,與批大小成線性比例。一個vocab Embedding 的shape是(50304, 5120)。而對于每個parameter來說,其需要存儲:來自于FP32的weight以及Adam的(Embedding也是Adam更新),來自于前向時FP16的weight。注意,此處沒有grad的計算,因為Embedding layer的grad通常占用的很小,不像MatMul一樣。最終結(jié)果是3.6GB,每一層Transformer Encoder Model States消耗約6GB,Activation的batch_size每增加1消耗約1GB,Vocab Embedding Layer模型權(quán)重約消耗3.6GB。這是理論值,實際值比這大得多。
對于深度學習或者說人工智能運算,瓶頸就在存儲器,最簡單的解決辦法就是用HBM3內(nèi)存,HBM就是高寬帶。
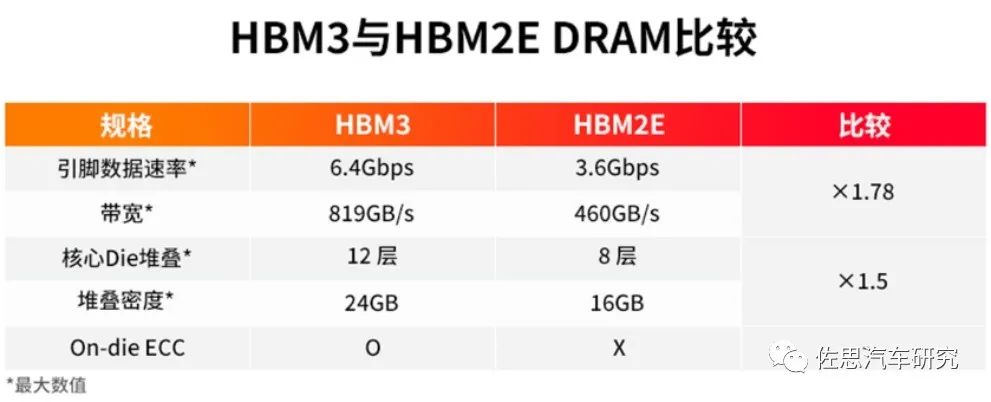
圖片來源:SK Hynix
高性能AI芯片必用HBM,而HBM有三個缺點,一是價格昂貴,每GB成本大約20-40美元,至少8GB起售;二是必須使用2.5D封裝,成本進一步增加;三是功耗增加不少。
HBM的成本還不是最高的,最高的成本是SRAM,也就是L2緩存,無論是訓練還是推理,都要用到,容量越大越好,它的速度比HBM要高許多,成本要高更多。AI芯片當然要用先進工藝,臺積電N4即4納米工藝,這種工藝如果做SRAM并不會提高密度,4N工藝下每MB的SRAM成本大約40-50美元,也有人估計是近100美元。
現(xiàn)在我們來構(gòu)建一套BEV+Transformer,首選至少需要新增6個攝像頭,為什么不能用360環(huán)視的攝像頭,很簡單,360環(huán)視用的都是魚眼鏡頭,水平FOV一般是195度,其有效距離一般不超過5米,大部分都是在3米甚至2米內(nèi)。做BEV至少需要20米的側(cè)向有效距離。此外,360環(huán)視攝像頭的安裝高度偏低,做BEV,高度越高越好,最好是車頂。
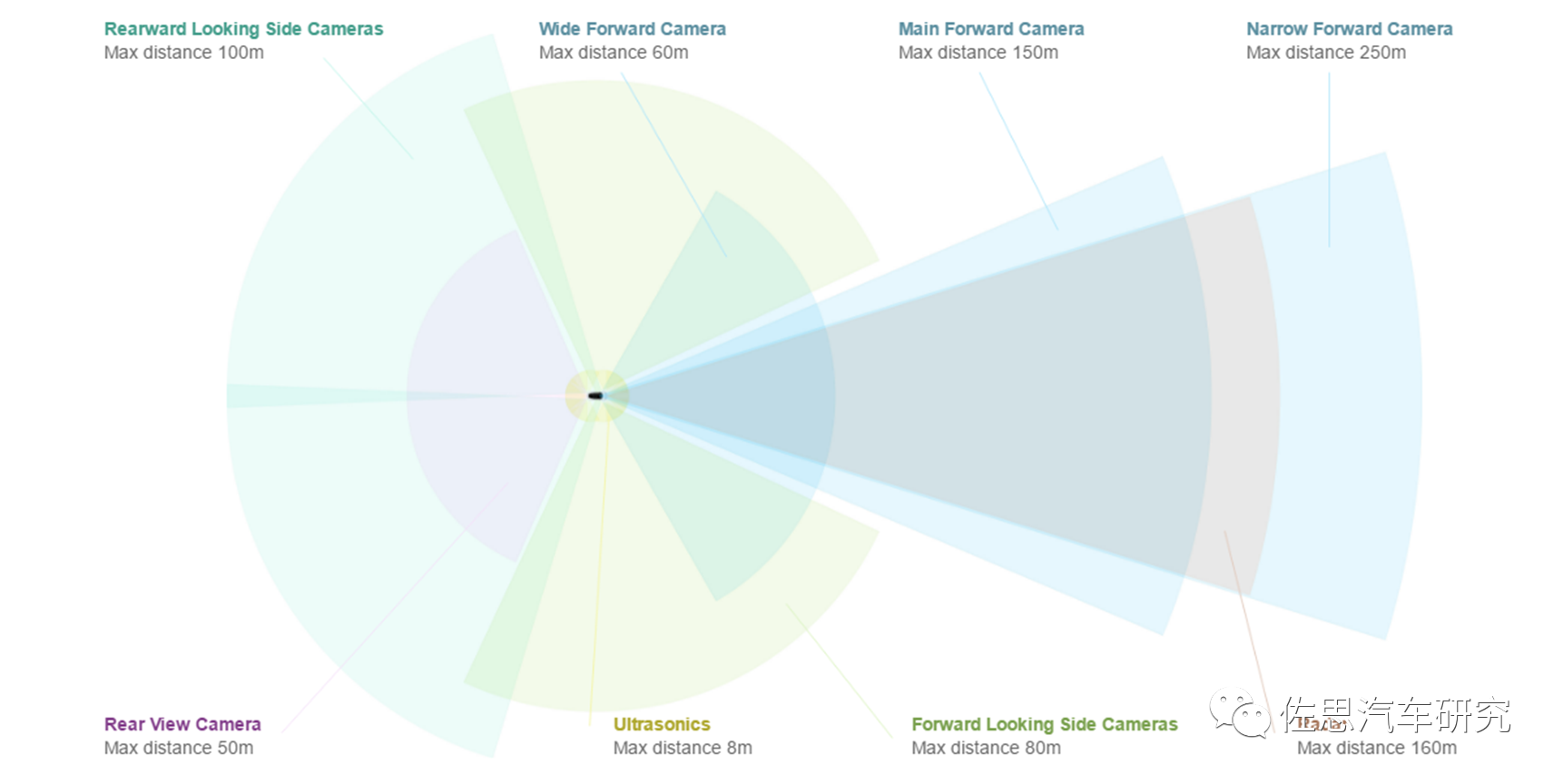
圖片來源:特斯拉
特斯拉是8個攝像頭,前面3個,F(xiàn)OV分別是35度、50度、120度,側(cè)方A柱和B柱各2個,前側(cè)攝像頭的FOV據(jù)說是90度,后側(cè)攝像頭的FOV推測是80度,后攝像頭FOV推測是130度,像素都是130萬像素。2023或2024年的HW4.0是7個,前面從三個變成兩個,35度FOV的攝像頭取消,50度FOV的攝像頭像素增加到536萬,就是索尼的IMX490做傳感器,其余6個攝像頭升級為200萬像素。
攝像頭的有效距離與像素數(shù)、安裝高度成正比,與水平FOV成反比。中國車特別是新興造車勢力一貫采用800萬像素。因此800萬像素攝像頭6個,像素比較高,F(xiàn)OV就可以寬一點,側(cè)向和后向都用120度,前向還是45度或50度。這需要8個加串行芯片,一般是MAX9295,4個解串行芯片,一般是MAX9296或MAX96712,MAX96712目前非常火爆,2倍甚至3倍高價都拿不到貨。光這12個解串行芯片估計就要近150美元,差不多1000人民幣。
處理器系統(tǒng),運算量巨大,非4個頂配Orin莫屬,僅此一項大約1200美元。理論上算力足夠了,但實際瓶頸在存儲,需要強大的存儲器,GDDR6或LPDDR5是首選。
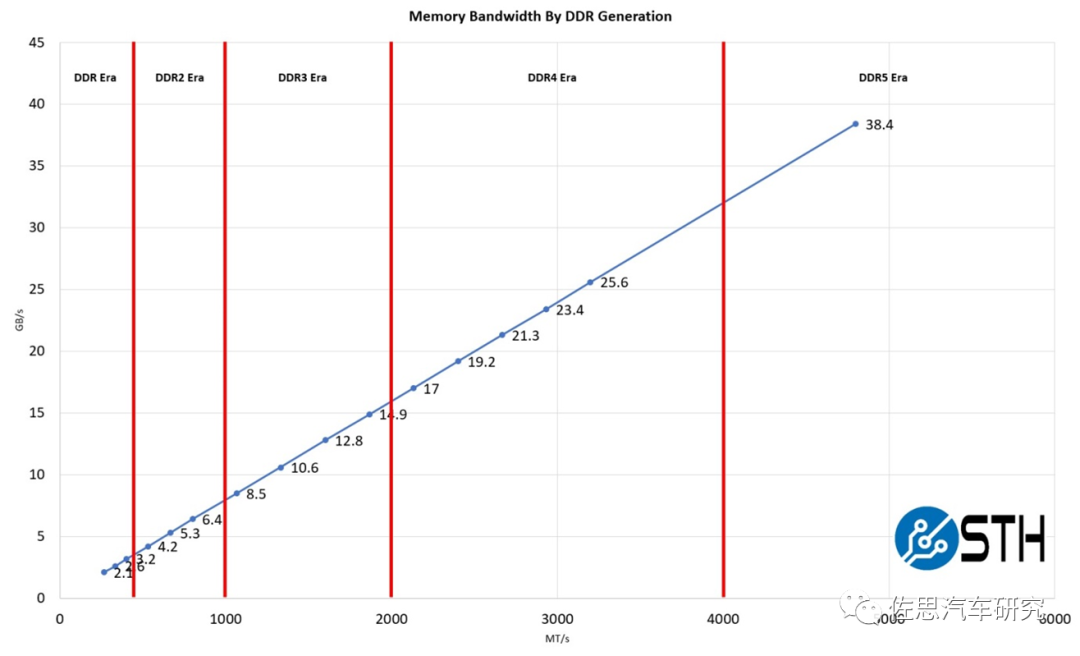
圖片來源:STH
DDR5性能提升不少,如上圖,英偉達頂配Orin推薦的是64GB的256bit LPDDR5,帶寬有204.8GB/s。4個Orin需要256GBLPDDR5,目前48GB LPDDR4報價是35美元,256GB LPDDR5估計要200美元。GDDR6價格會更高,估計要300美元。
BEV+Transformer的根源是特斯拉,特斯拉自然是不用激光雷達的。迄今為止,研究BEV+Transformer的絕大部分都是純視覺,Waymo、地平線和國內(nèi)的毫末智行加入了激光雷達。與攝像頭比,線數(shù)再高的激光雷達都是稀疏點云數(shù)據(jù),兩者的query特征差別較大,雖然說BEV更適合傳感器前融合,但激光雷達的作用明顯弱化,核心還是攝像頭,純視覺與加了激光雷達的傳感器高級融合,實際差別不大,這與激光雷達領域大量使用點柱算法也有關系,激光雷達的深度信息完全沒有發(fā)揮,等于是一個能在黑夜工作的加強版的攝像頭。反倒是那些8線或16線甚至4線的激光雷達效果更好。
再來看AI芯片,目前智能駕駛領域的AI芯片都是以CNN為核心的,基本都是設計針對INT8即整數(shù)8位精度的,在Transformer時代很難有所作為,需要重新設計,且重要性下降,與GPU比差距拉大了。最關鍵一點,時間序列是矢量,Transformer是浮點矢量矩陣乘法累加運算,浮點運算與整數(shù)運算差異巨大,GPU最初就是專門為浮點運算而生的。AI推理專用芯片幾乎都不考慮浮點運算。AI芯片做浮點運算時,效率會直線下降。
Swin Transformer的模型結(jié)構(gòu)
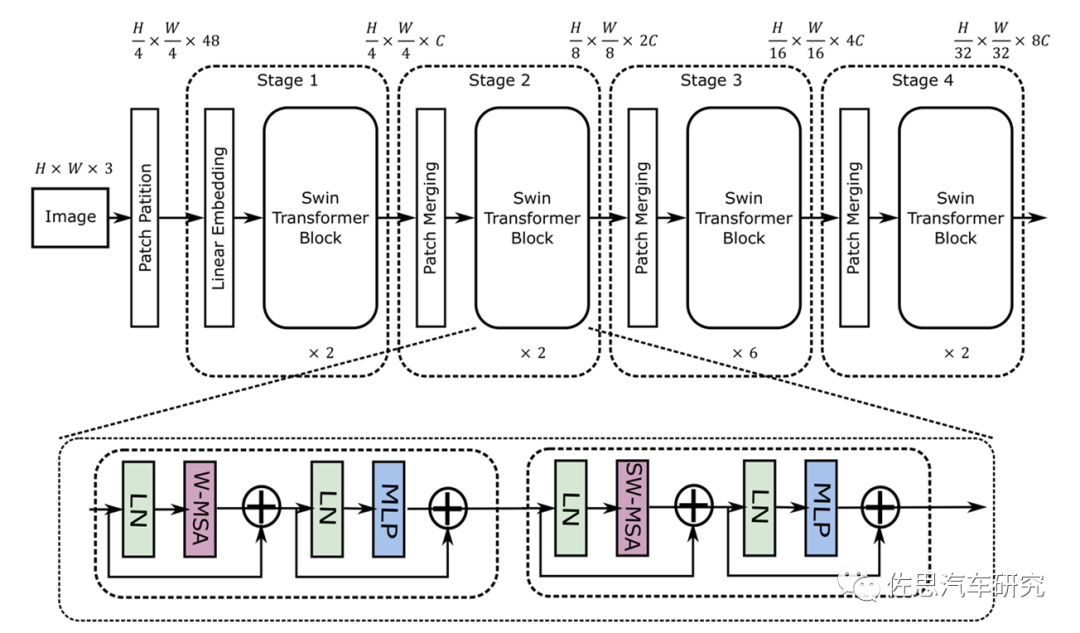
圖片來源:《MaxViT: Multi-Axis VisionTransformer》
從圖上就能看出其采用了4*4卷積矩陣,而CNN是3*3,這就意味著目前的AI芯片有至少33%的效率下降。再者就是其是矢量與矩陣的乘法,這會帶來一定的浮點矢量運算。假設高和寬都為112,窗口大小為7,C為128,那么未優(yōu)化的浮點計算是:4*112*112*128*128+2*112*112*112*112*128=41GFLOP/s。大部分AI芯片如特斯拉的FSD和谷歌的TPU,未考慮這種浮點運算。不過華為和高通都考慮到了,英偉達就更不用說了,GPU天生就是針對浮點運算的。
英偉達在新一代GPU中特別增加了Transformer引擎,Transformer引擎的秘訣在于它能夠在訓練神經(jīng)網(wǎng)絡的每個步驟中動態(tài)選擇神經(jīng)網(wǎng)絡中每一層所需的精度。最不精確的單元,即8位浮點,可以加快計算速度,但如果這是下一層所需的精度,則可以為下一層生成16位或32位和。不過,Hopper更進一步。
它的8浮點單元可以使用兩種形式的8位數(shù)字中的任何一種進行矩陣數(shù)學運算。標準的16位浮點格式(IEEE 754-2008)需要5位指數(shù)和10位尾數(shù)以及符號位。為了減少數(shù)據(jù)存儲要求和加速機器學習,英偉達和谷歌更喜歡bfloat-16,它用三位尾數(shù)換取一個附加指數(shù),使其范圍與32位數(shù)字相同。
bf16是最適合Transformer的格式。英偉達的Transformer引擎可以協(xié)調(diào)動態(tài)范圍和準確度,比如浮點8位,大動態(tài)范圍可以使用5位指數(shù)和2位尾數(shù)(E5M2),或者當精度是關鍵時,可以使用4位指數(shù)和3位尾數(shù)(E4M3)。
CNN的權(quán)重模型通常不超過20MB,而Transformer則輕松超過1000MB也就是1GB。以前CNN時代,AI芯片還可以勉強放下權(quán)重模型,而Transformer時代則絕無可能,存儲器的重要性進一步上升,AI芯片的地位下降,GPU的優(yōu)勢更加明顯。
不僅是智能駕駛,所謂AI的發(fā)展方向就是模型體積越來越龐大,參數(shù)量越來越多,就像劣幣驅(qū)逐良幣一樣,這樣硬件會不斷迭代,成本也會越來越高。
審核編輯:劉清
-
激光雷達
+關注
關注
970文章
4064瀏覽量
190924 -
SRAM編程
+關注
關注
0文章
2瀏覽量
5965 -
HBM
+關注
關注
0文章
393瀏覽量
14903 -
LPDDR5
+關注
關注
2文章
89瀏覽量
12205 -
智能駕艙
+關注
關注
0文章
15瀏覽量
3917
原文標題:BEV+Transformer對無人駕駛硬件體系的巨大改變
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
什么是物聯(lián)網(wǎng)智能路燈? 智慧路燈是什么?什么樣的智慧路燈更滿足現(xiàn)代需求

ads1198輸出的TESTP-PACE-OUT1,TESTN-PACE-OUT2是什么樣的信號?
《具身智能機器人系統(tǒng)》第1-6章閱讀心得之具身智能機器人系統(tǒng)背景知識與基礎模塊
淺析基于自動駕駛的4D-bev標注技術

什么樣的電阻柜用于風電光伏項目
自動駕駛中一直說的BEV+Transformer到底是個啥?

如何選擇智能駕駛輔助系統(tǒng)
IP地址與智能家居能夠碰撞出什么樣的火花呢?
代碼整潔之道-大師眼中的整潔代碼是什么樣

端到端必然是高階自駕的未來

長電科技車載芯片先進封裝方案推動BEV+Transformer擴大應用
RADIO與RFWAKEUP具體功能是什么樣的,如何把系統(tǒng)從低功耗模式喚醒的?
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
黑芝麻智能開發(fā)多重亮點的BEV算法技術 助力車企高階自動駕駛落地






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論