 大數據系統包括哪些
大數據系統包括哪些
目前,主流的大數據平臺包括:Hadoop、Spark。
Hadoop是分布式(根據網絡資料理解:分布式與集中式相對應,對于大量數據計算,集中于一臺計算機中計算需耗費較長時間,通過將計算分布于多個計算機,節約整體計算時間)系統基礎架構。Hadoop的兩個功能包括:數據存儲(HDFS)、數據處理(MapReduce)。
Spark是專為大規模數據處理而設計的快速通用計算引擎。Spark不提供文件管理系統,沒有數據存儲功能;Spark的數據計算基于內存實現,數據處理速度快。
一、HDFS(分布式文件存儲)
數據通過HDFS放置于一個Hadoop集群中,Hadoop集群通常由幾臺至上千臺的計算機組成。根據課程介紹理解,百度公司最大的Hadoop集群已超過4000臺計算機。
數據在存儲于HDFS前,被分割成若干數據塊,每個數據塊儲存于一臺計算機中。不同Hadoop版本所分割的數據塊大小不同,Hadoop1.0版本中數據塊大小為64MB,Hadoop2.0版本中數據塊大小為128MB。Hadoop也可以設置數據塊大小(含個人理解)。
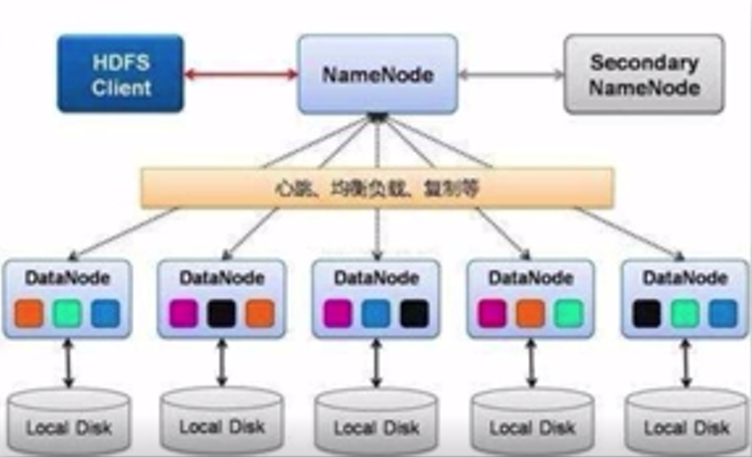
圖片來源:學堂在線《大數據導論》
二、MapReduce(分布式數據處理架構)
MapReduce是分布式計算框架。開發人員在運用MapReduce處理數據時,MapReduce將指定某一Map函數,將一組鍵值對(根據網絡資料理解:鍵值對可以根據一個值獲得對應的一個值)映射成一組新的鍵值對,并指定并發的Reduce函數,保證所有Map函數映射的結果可以進行Reduce規約(根據網絡資料理解:通過某一連接動作將所有元素匯總為一個結果的過程)運算。
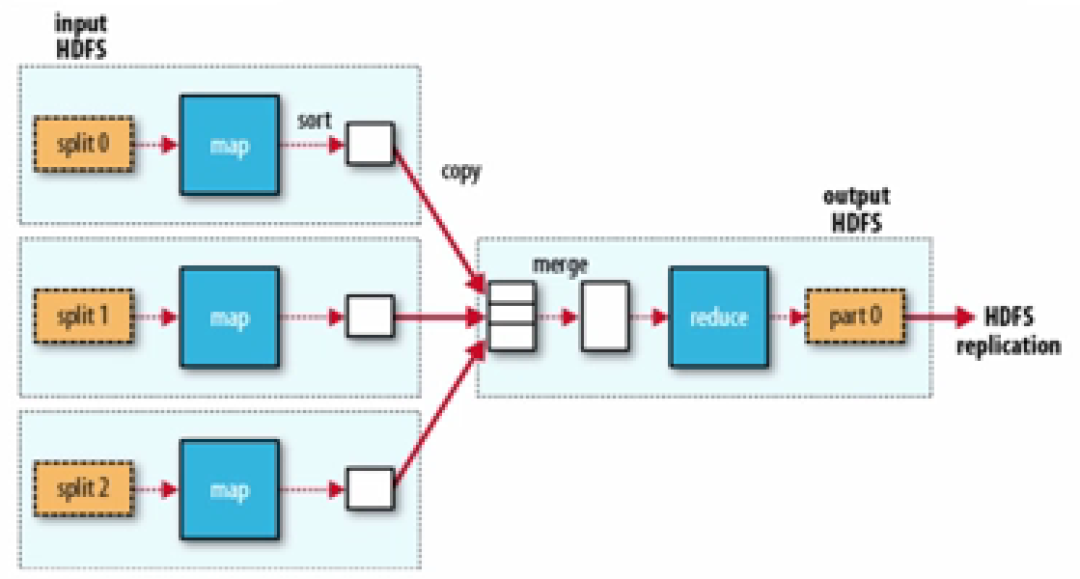
圖片來源:學堂在線《大數據導論》
在運用MapReduce框架編寫計算機程序時,開發人員只需考慮業務邏輯,不需考慮并行管理。
WordCount是統計文件夾所有文本中某一詞出現的次數。
其中,WordCount的Map函數程序代碼如下:
Map(K, V){
For each word w in V
Collect(w,1);
}
WordCount的Map函數中的K代表文本中的詞,WordCount的Map函數的功能是將文本中的每個詞與1建立鍵值對,即每個詞對應一個“1”。
WordCount的Reduce函數程序代碼如下:
Reduce(K.V[]){
int count=0;
For each v in V
count+= v;
Collect(K,count);
}
WordCount的Reduce函數將經過WordCount的Map函數處理的相同詞對應的“1”求和,得出某一詞的出現的次數。
該WordCount示例中,Map和Reduce函數的具體運行如圖一所示:
首先,所有數據被整理成單行數據,圖一流程圖中具有三個節點(個人理解:節點可被認為是計算機),圖一中的三行數據被分行輸入到三個節點中。
然后,Map函數運行,將每個詞與1建立鍵值對。
Map函數運行結束后,Shuffle過程運行,Shuffle過程是MapReduce內設過程,可將具有相同詞的鍵值對中的“1”集合至一個List(列表)中。如圖一所示,因為“Bear”一詞出現了兩次,所以經過Shuffle過程后,“Bear”所對應的List為(1,1)。
最后,Reduce函數運行,將Shuffle過程所生成的List求和,完成對某一詞出現的次數統計。
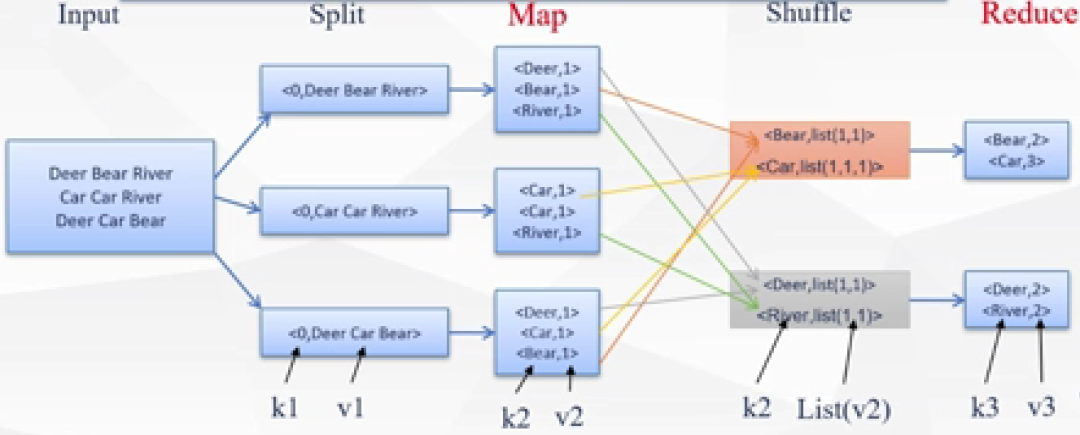
圖一,圖片來源:學堂在線《大數據導論》
審核編輯:劉清
-
數據存儲
+關注
關注
5文章
970瀏覽量
50894 -
HDFS
+關注
關注
1文章
30瀏覽量
9588 -
大數據系統
+關注
關注
0文章
7瀏覽量
1875
原文標題:大數據相關介紹(9)——大數據系統(上)
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
緩存對大數據處理的影響分析
ADS1675最大數據吞吐率是是多少?
raid 在大數據分析中的應用
智慧城市與大數據的關系
基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能
使用CYW20829的BLE進行最大數據發送應用,BLE丟失數據如何解決?
大數據在軍事方面的應用
多通道數據采集系統的工作原理包括什么
大數據分析平臺網站
大數據在軍事方面的應用有哪些
CYBT-343026傳輸大數據時會丟數據的原因?
簡析大數據技術下智能充電樁在網絡系統中的應用





 工商網監
工商網監
評論