 淺析卷積降維與池化降維的對比
淺析卷積降維與池化降維的對比
**1 **問題
在學習深度學習中卷積網絡過程中,有卷積層,池化層,全連接層等等,其中卷積層與池化層均可以對特征圖降維,本次實驗針對控制其他層次一致的情況下,使用卷積降維與池化降維進行對比分析,主要是看兩種降維方式對精度的影響以,以及損失值的大小。與此同時還可以探究不同維度下對精度是否有影響。
**2 **方法
這里是所有的代碼,每次只需要更改網絡的模型,即使用卷積層,使其降維的維度最后是1x1、7x7、14x14,需要更改三次,其次是使用池化層降維,最后也需要達到1x1、7x7、14x14,這三種維度。
| import torchvision
from torchvision.transforms import ToTensor, transforms
from torch.utils.data import DataLoader
from torch import nn
import torch
from time import *
import xlwt
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
創建一個新的類繼承nn.Module
class MyNet(nn.Module):
(5.2) 定義網絡有哪些層,這些層都作為成員變量
def init (self):
super(). init ()
卷積
in_channels輸入 out_channels輸出 kernel_size 卷積核 stride 步長
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1, )
[-,16,28,28] [B, C, H, W] batch channel height weight
self.max_pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1, )
self.max_pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=4, stride=2, padding=1, )
self.max_pool3 = nn.MaxPool2d(2)
[-,32,28,28]
全連接
self.fc = nn.Linear(in_features=32 * 14 * 14, out_features=10)
(5.3) 定義數據在網絡中的流動
x - 1x28x28 CxHxW C表示通道數,H表示圖像高度,W表示圖像寬度
def forward(self, x):
x = torch.relu(self.conv1(x))
x = self.max_pool1(x)
x = torch.relu(self.conv2(x))
x = self.max_pool2(x)
x = torch.relu(self.conv3(x))
x = self.max_pool3(x)
x = torch.flatten(x, 1) #! 默認從0維開始拉伸 如果不設置1的話 會吧batch也拉伸進去
[B, C, H, W]
拉伸 C H W
out = torch.relu(self.fc(x))
return out
訓練網絡
loss_list: 統計每個周期的平均loss
def train(dataloader, net, loss_fn, optimizer):
size = len(dataloader.dataset)
epoch_loss = 0.0
batch_num = len(dataloader)
net.train()
精度=原預測正確數量/總數
correct = 0
一個batch一個batch的訓練網絡
for batch_idx, (x, y) in enumerate(dataloader):
--->
x, y = x.to(device), y.to(device) # 在GPU上運行x,y
pred = net(x)
loss = loss_fn(pred, y)
基于loss信息利用優化器從后向前更新網絡全部參數
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
if batch_idx % 100 == 0:
print(f'batch index:, loss:') # item()方法將單個tensor轉化成數字
print(f'[ {batch_idx + 1 :>5d} / {batch_num :>5d} ] loss: {loss.item()}')
統計一個周期的平均loss
avg_loss = epoch_loss / batch_num
avg_accuracy = correct / size
return avg_accuracy, avg_loss
驗證and評估
def test_and_val(dataloader, net, loss_fn):
size = len(dataloader.dataset)
batch_num = len(dataloader)
correct = 0
losses = 0
net.eval()
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = net(x)
loss = loss_fn(pred, y)
losses += loss.item()
correct += (pred.argmax(1) == y).type(torch.int).sum().item()
accuracy = correct / size
avg_loss = losses / batch_num
print(f'The Accuracy =%')
return accuracy, avg_loss
if name == 'main':
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0.1307, 0.3081)])
(0) 測試機器是否支持GPU
data_train_acc = []
data_train_loss = []
data_val_acc = []
data_val_loss = []
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
batch_size = [32,64,128,256]
batch_size = [64]
train_all_ds = torchvision.datasets.MNIST(root="data", download=True, train=True, transform=transform, )
將訓練集劃分為訓練集+驗證集
train_ds, val_ds = torch.utils.data.random_split(train_all_ds, [50000,10000])
test_ds = torchvision.datasets.MNIST(root="data", download=True, train=False, transform=transform, )
for each in range(len(batch_size)):
train_loader = DataLoader(dataset=train_ds,batch_size=batch_size[each], shuffle=True,)
val_loader = DataLoader(dataset=val_ds,batch_size=batch_size[each],)
test_loader = DataLoader(dataset=test_ds,batch_size=batch_size[each],)
(5) 網絡的輸入、輸出以及測試網絡的性能(不經過任何訓練的網絡)
net = MyNet().to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
loss_fn = torch.nn.CrossEntropyLoss()
(6)訓練周期
begin_time = time()
train_accuracy_list = []
train_loss_list = []
val_accuracy_list = []
val_loss_list = []
epoch = 10
for t in range(epoch):
print(f"Epoch {t + 1}")
train_accuracy, train_loss = train(train_loader, net, loss_fn, optimizer)
train_accuracy_list.append(train_accuracy)
train_loss_list.append(train_loss)
print(f'Epoch {t + 1 :<2d} Train Acc = {train_accuracy * 100 :.2f}% || Epoch {t + 1} Train Loss = {train_loss}')
val_accuracy, val_loss = test_and_val(val_loader, net, loss_fn)
val_accuracy_list.append(val_accuracy)
val_loss_list.append(val_loss)
print(f'Epoch {t + 1 :<2d} Val Acc = {val_accuracy * 100 :.2f}% || Epoch {t + 1} Val Loss = {val_loss}')
print(f'Best_Train_Acc =% || Best_Val_Acc =%')
data_train_acc.append(train_accuracy_list)
data_train_loss.append(train_loss_list)
data_val_acc.append(val_accuracy_list)
data_val_loss.append(val_loss_list)
data_set = [data_train_acc,data_train_loss,data_val_acc,data_val_loss]
file = xlwt.Workbook('encoding = utf-8') # 設置工作簿編碼
sheet1 = file.add_sheet('數據', cell_overwrite_ok=True) # 創建sheet工作表
要寫入的列表的值
name = ['train_acc_batch','train_loss_batch','val_acc_batch','val_loss_batch']
for one in range(len(data_set)):
data = data_set[one]
id = name[one]
for i in range(len(data)):
for j in range(len(data[i])):
sheet1.write(j, i, data[i][j]) # 寫入數據參數對應 行, 列, 值
file.save(f'CNN1_CH_.xls') # 保存.xls到當前工作目錄
print(f'Best_Train_Acc = {max(train_accuracy_list) * 100 :.2f}%, Best_Val_Acc = {max(val_accuracy_list) * 100 :.2f}%')
test_accuracy,_ = test_and_val(test_loader, net, loss_fn)
print(f'Test Acc = {test_accuracy * 100}%')
end_time = time()
print('Time Consumed:',end_time-begin_time) |
卷積降維與池化降維對精度的影響
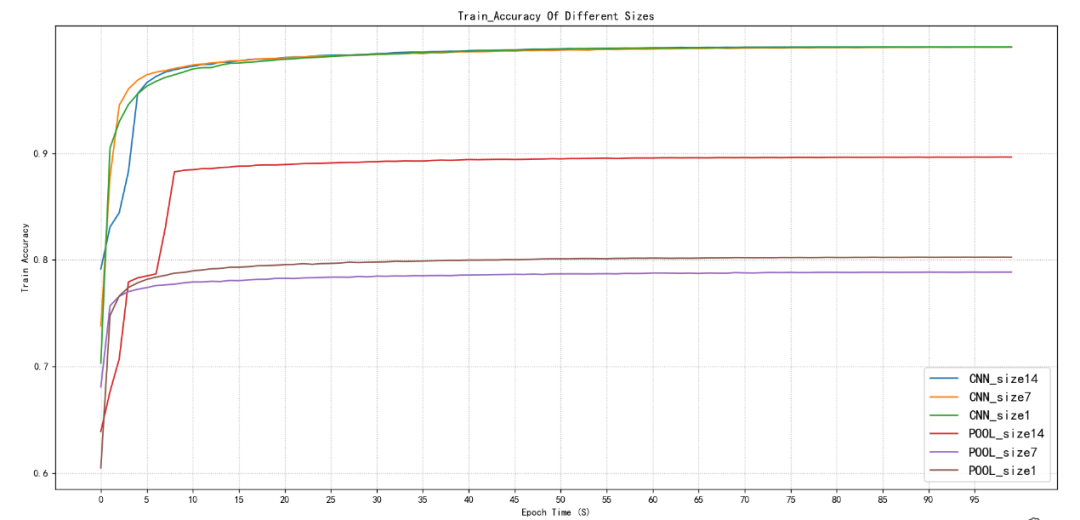
圖2.1訓練集精度對比

圖2.2驗證集精度對比
如圖2.1和圖2.2所示在使用卷積降維的情況下無論特征圖尺寸在14x14、7x7、1x1在訓練集下,精度最開始都是從80%多在10個周期以后均能達到99%左右,最終預測精度能達到99.99%,并且在10個周期以后就達到99%,再訓練90個周期就是緩慢的從99%到99.99%幾乎接近1的精度了。訓練集也是如此,10個周期左右達到98%,最后穩定在98.40%左右。
池化降維,無論訓練集還是驗證集在14x14、7x7,1x1在首次只有60%多的準確率,在14x14的尺寸下,池化降維可以接近90%的準確率,大致在88%-89%,7x7、1x1均只能達到78%-79%左右,并且都是在10個周期左右趨于穩定,只有小幅波動。

圖2.3訓練集損失值對比
卷積降維與池化降維對損失值****的影響
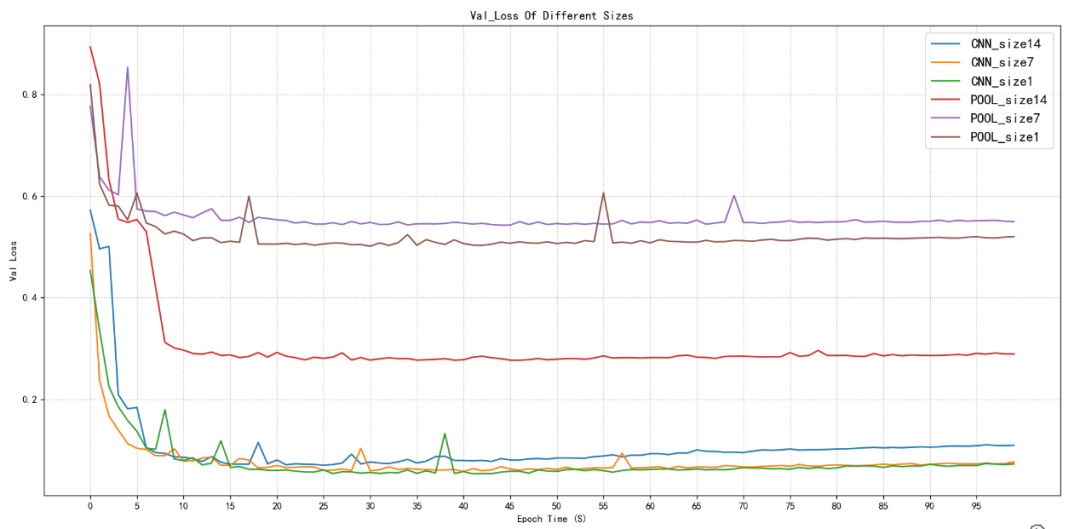
圖2.4驗證集損失值對比
如圖2.3和2.4所示,卷積降維訓練集與驗證集的損失值在首次就能達到池化降維的最小值,并且卷積降維隨著訓練次數的增加還在持續減小,幾乎能夠達到0.00幾的損失值,最后穩定在這附近波動,代表預測值與真實值之間的差距非常小,幾乎接近。
然后池化降維首次就是0.8-0.9左右,隨著訓練次數增加最低值也就只有0.5-0.6左右。但是池化降維在14x14尺寸下其損失值可以相對于在池化降維下7x7、1x1的尺寸下較小一些,可以達到0.3左右的損失值。
**3 **結語
針對卷積降維和池化降維,這里是對特征圖14x14、7x7、1x1進行了精度對比和損失值對比的分析,最終得出在對于降維的方法使用下,卷積降維效果更佳,但需要人為去計算出該卷積出來的特征圖大小,但是池化可以直接很簡單的得出特征圖大小,這是其中一個區別,也是池化特征的一個優點。但是對于實驗結果的效果,卷積降維要更好與池化降維的。能夠使訓練集精度達到99.99%,驗證集精度達到98.40%左右。這是卷積降維的優點所在。
在本次實驗中,得出的最后的結論是,卷積降維對于結果精度要優于池化降維,但是卷積降維需要人為來計算卷積后的特征圖大小,從而去更改卷積層的參數,有時候較為麻煩。池化降維則可以輕易的得出想要的特征圖大小。
對于本次實驗只是比較了特征圖14x14、7x7、1x1,這三個尺寸對于精度的影響不同。還可以試著比較訓練花費時間。以及不同尺寸是否對結果有什么影響。這次實驗數據也有不同尺寸的結果,我也同時對比了一下在卷積層最后不同的尺寸對于精度的影響,最后發現只有前10個周期有一點區別,最終均能達到最優的效果,但是為了計算量的減少,在同等結果的情況下,尺寸小那么更節省時間吧。
-
卷積
+關注
關注
0文章
95瀏覽量
18527 -
深度學習
+關注
關注
73文章
5507瀏覽量
121272 -
卷積網絡
+關注
關注
0文章
42瀏覽量
2183
發布評論請先 登錄
相關推薦
求助,SVM分類時要不要先進行PCA降維呢?
基于圖嵌入和最大互信息組合的降維
降維空時自適應處理研究
基于圖論的人臉圖像數據降維方法綜述
基于Wasserstein距離概率分布模型的非線性降維算法
【連載】深度學習筆記10:三維卷積、池化與全連接
如何使用自適應嵌入的半監督多視角特征實現降維的方法概述
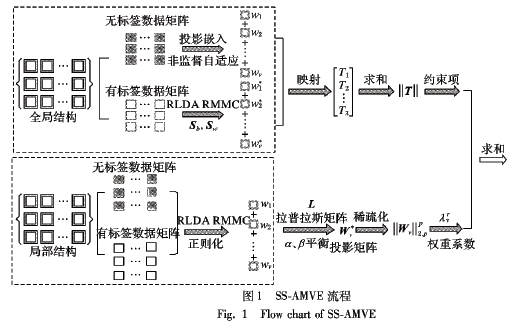
由淺入深的對其降維原理進行了詳細總結
如何使用FPGA實現高光譜圖像奇異值分解降維技術





 工商網監
工商網監
評論