 如何使用VGG網絡進行MNIST圖像分類
如何使用VGG網絡進行MNIST圖像分類
**1 **問題
VGG網絡由牛津大學的Oxford Visual Geometry Group于2015年提出。從誕生之后就收到了學界的廣泛關注。

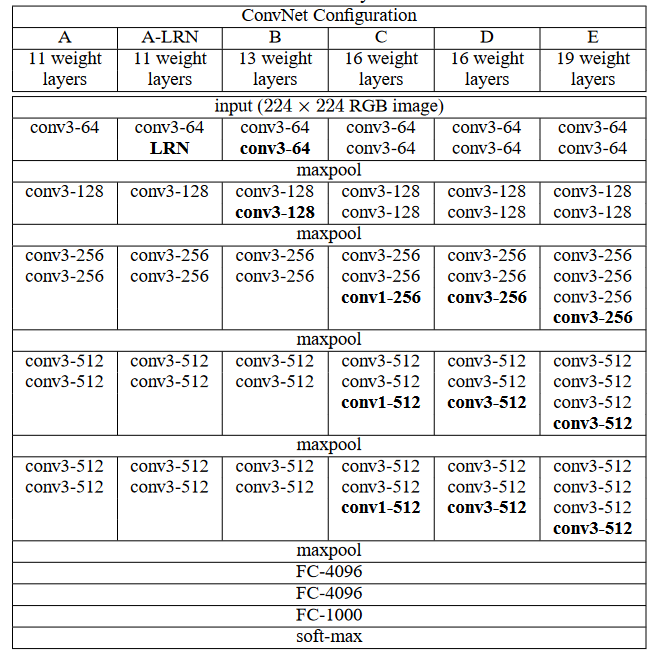
VGG網絡,可以應用在人臉識別、圖像分類等方面。VGG有兩種結構,分別為16層和19層。具體結構在其文獻做了詳細表述,如下圖所示。
為了學習VGG網絡,本組擬采用配置A在MNIST數據集上進行圖像分類實驗。
**2 **方法
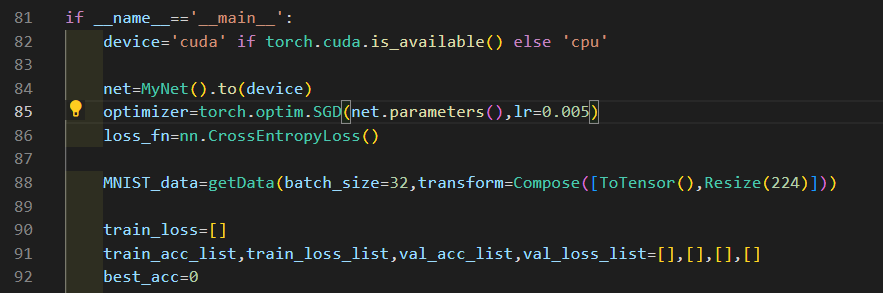
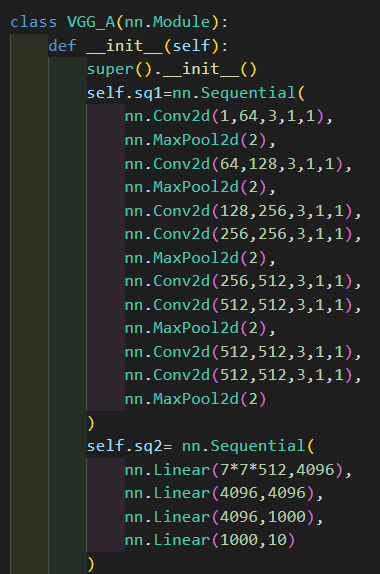
首先MNIST的數據大小為28*28,需要進行resize才能作為VGG網絡的輸入;同時,本次實驗只需要進行10分類,因此將網絡本身的最后一層原做1000分類的soft-max層移除,替換為FC-10。網絡實現代碼如下:
獲取數據后進行resize操作:
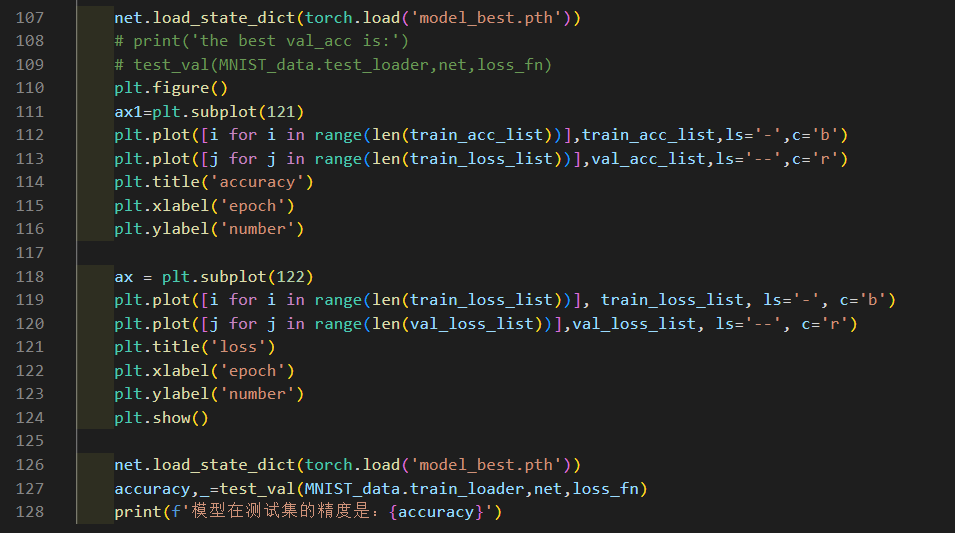
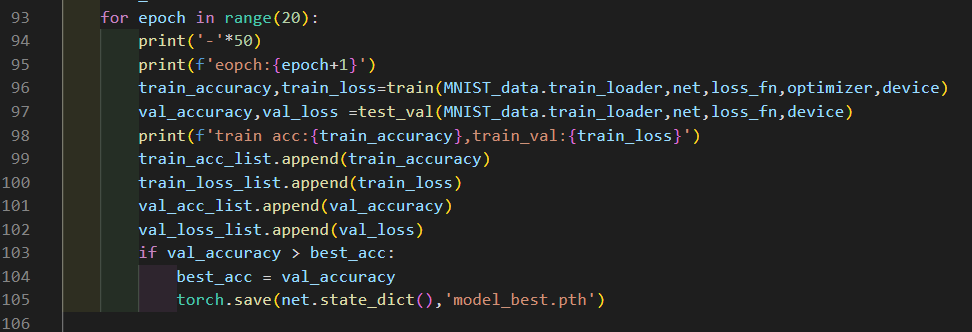
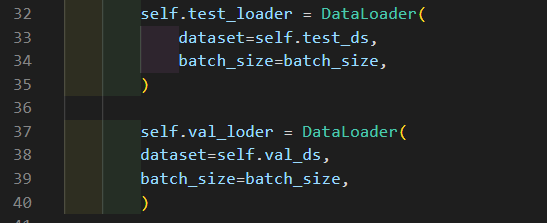
實驗部分代碼如下:
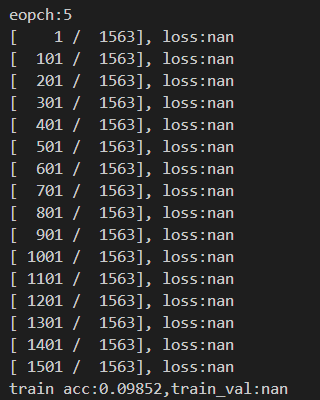

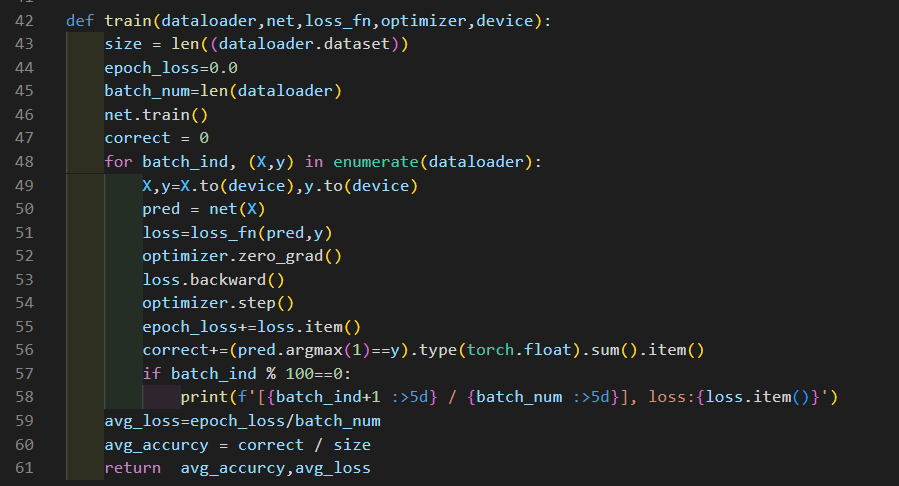
實驗結果:
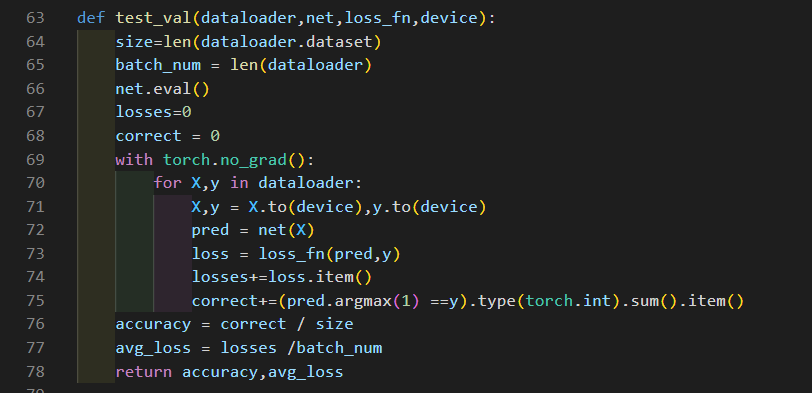
**3 **結語
VGG主要工作是證明了增加網絡的深度能夠在一定程度上影響網絡最終的性能,從本次實驗也可以看出,短時間少周期的訓練并不能使得如此龐大的網絡擁有很好的效果,而在比較小的網絡如LeNet-5這樣的網絡上往往幾個周期就能得到較高的精度。遺憾的是因為實驗設備性能限制,網絡的運行速度很慢,受限于內存大小,BatchSize的大小受限,最大只能到32,沒有充足的調整空間。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
人臉識別
+關注
關注
76文章
4048瀏覽量
83266 -
圖像分類
+關注
關注
0文章
95瀏覽量
12076 -
vgg
+關注
關注
1文章
11瀏覽量
5286
發布評論請先 登錄
相關推薦
一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
學習方法來對高血壓的四個階段進行分類。這里采用的分類方法是:Alexnet、Resnet -50、VGG-16和新的模型:AvgPool_VGG
發表于 05-11 20:01
《DNK210使用指南 -CanMV版 V1.0》第四十七章 MNIST實驗
,并分別構造并初始化了用于MNIST手寫數字識別的KPU對象。然后便是在一個循環中不斷地獲取攝像頭輸出的圖像,在對圖像進行預處理后,將圖像送
發表于 11-19 10:30
計算機視覺必讀:區分目標跟蹤、網絡壓縮、圖像分類、人臉識別
深度學習目前已成為發展最快、最令人興奮的機器學習領域之一。本文以計算機視覺的重要概念為線索,介紹深度學習在計算機視覺任務中的應用,包括網絡壓縮、細粒度圖像分類、看圖說話、視覺問答、圖像
發表于 06-08 08:00
基于Brushlet和RBF網絡的SAR圖像分類
針對SAR圖像紋理特征豐富的特點,本文提出一種新的SAR圖像分類方法:通過提取Brushlet變換的能量及相位信息作為SAR圖像的紋理特征,然后輸入徑向基函數RBF
發表于 12-18 16:20
?20次下載

利用DCNN融合特征對遙感圖像進行場景分類
)、OverFeatL 3種深度卷積神經網絡(DCNN)提取的融合特征進行遙感圖像場景分類方法。通過利用利用3種DCNN提取的歸一化的融合特征進行
發表于 01-10 16:05
?2次下載
如何使用復雜網絡描述進行圖像深度卷積的分類方法介紹
為了在不增加較多計算量的前提下,提高卷積網絡模型用于圖像分類的正確率,提出了一種基于復雜網絡模型描述的圖像深度卷積
發表于 12-24 16:40
?4次下載
基于特征交換的卷積神經網絡圖像分類算法
與同類標簽特征圖進行交換,充分融合有限的圖像特征,以解決圖像識別中樣本不足的問題。實驗結果表明,該算法對標注數據的依賴性較低且有效提升了網絡識別準確率,適用于數據量較小的
發表于 03-22 14:59
?27次下載


基于卷積神經網絡的人臉圖像美感分類案例
摘要:針對復雜環境下人臉圖像美感分類準確率低的問題,給出一種適用于人臉圖像美感分類的網絡模型F-Net。該模型以LeNet-5為基礎
發表于 07-19 14:38
?0次下載





 工商網監
工商網監
評論