

(1)可靠性高。Hadoop具有多個工作數據副本,確保可針對失敗的節點(個人理解:一個節點可理解為一臺計算機或服務器)進行重新分布處理。
(2)擴展性高。Hadoop可擴展至數干節點。
(3)效率高。Hadoop以并行方式工作,處理數據速度快。
(4)成本低。與一體機、商用數據倉庫等對比,Hadoop是開源的,項目的軟件成本因此降低。
二、Hadoop的生態系統構成
(1)HDFS是一種分布式文件系統,運行于大型商用機集群,HDFS為Hadoop提供高可靠性的底層存儲支撐。
(2)MapReduce是一種分布式數據處理模式和執行環境,為Hadoop提供高性能計算能力。
(3)HBase位于結構化存儲層(根據網絡資料理解:HBase位于類似windows系統中多層級文件夾的結構中),是一個分布式的列存儲數據庫。
(4)Zookecper是一個分布式的、高可用性的協調服務,提供分布式鎖(根據百度百科:分布式鎖是控制分布式系統間同步訪問共享資源的方式)等基本服務,用于構建分布式應用,為Hadoop提供了穩定服務和failover機制(根據網絡資料理解:failover機制是失效轉移機制,當主要組件由于失效或預定關機時間原因而無法工作時,該機制將系統組件的功能轉移至二級系統組件)。
(5)Hive是一個建立于Hadoop基礎之上的數據倉庫,它提供在Hadoop文件中用于數據整理、特殊查詢、分析存儲的數據集工具。
(6)Pig是一種數據流語言和運行環境,用于檢索大的數據集,可簡化Hadoop常見工作任務。
(7)Sqoop為HBasc提供了方便的RDBMS(根據百度百科:關系數據庫管理系統)數據導入功能,可較為方便地將傳統數據庫數據遷移至HBase中。
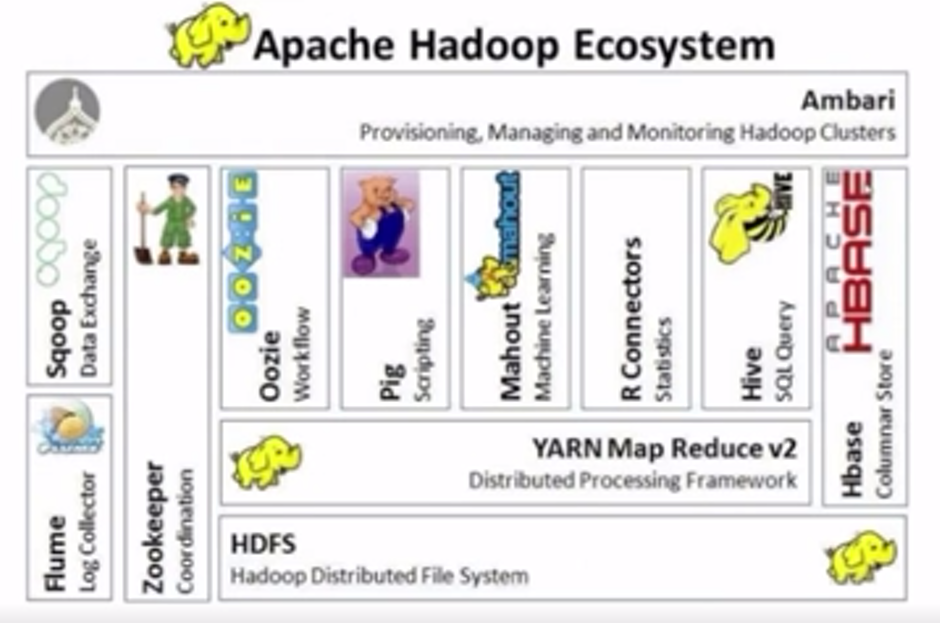 圖片來源:學堂在線《大數據導論》
圖片來源:學堂在線《大數據導論》
三、Spark介紹
Spark是另一種大數據系統,由一系列解決不同種類問題的系統和編程庫構成。下文以APACHE Spark為例,介紹Spark。
APACHE Spark由Spark SQL、Spark Streaming、MLlib、GraphX組成。
Spark SQL可以通過編寫SQL程序的方式處理數據。因為Spark所有計算依賴于內存,中途計算結果不會被存儲,所以Spark的一個優勢是數據處理速度快,但同時,Spark對內存的要求較高。
Spark Streaming可實現數據流計算(根據百度百科理解:因為數據的價值隨著時間的流逝而降低,傳統的數據庫管理系統無法快速且無法持續的處理大量且不斷更新的大數據,所以產生了可實現數據一出現就處理的數據流計算)。
GraphX是圖計算框架(根據網路資料理解:圖計算框架是在大數據中高效計算、存儲、管理圖數據的框架)。
四、Spark的優點
(1)Spark基于內存的迭代計算,計算速度快。
(2)Spark引入RDD(彈性分布式數據集:可將RDD視為一個對象,所有的數據處理均封裝于此對象中),容錯性高。
(3)Spark可提供更多的數據集操作類型,數據處理能力更強。數據集操作類型可分為Transformations和Actions兩類(根據網絡資料:Transformations可提供包括Map函數等操作,Actions可提供包括Reduce函數等操作)。
(4)Spark可支持更多編程語言,包括:Scala(根據網絡資料:類似java的編程語言)、Java、Python、R。
編輯:黃飛
-
Hadoop
+關注
關注
1文章
90瀏覽量
16313 -
HDFS
+關注
關注
1文章
31瀏覽量
9814 -
大數據
+關注
關注
64文章
8947瀏覽量
139288
原文標題:大數據相關介紹(10)——大數據系統(下)
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄


大數據hadoop入門之hadoop家族產品詳解
STM32單片機基礎01——初識 STM32Cube 生態系統 精選資料分享
STM32Cube生態系統更新
IT的生態系統概述
基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能





 工商網監
工商網監

評論