


架構(gòu)探索和RTL綜合
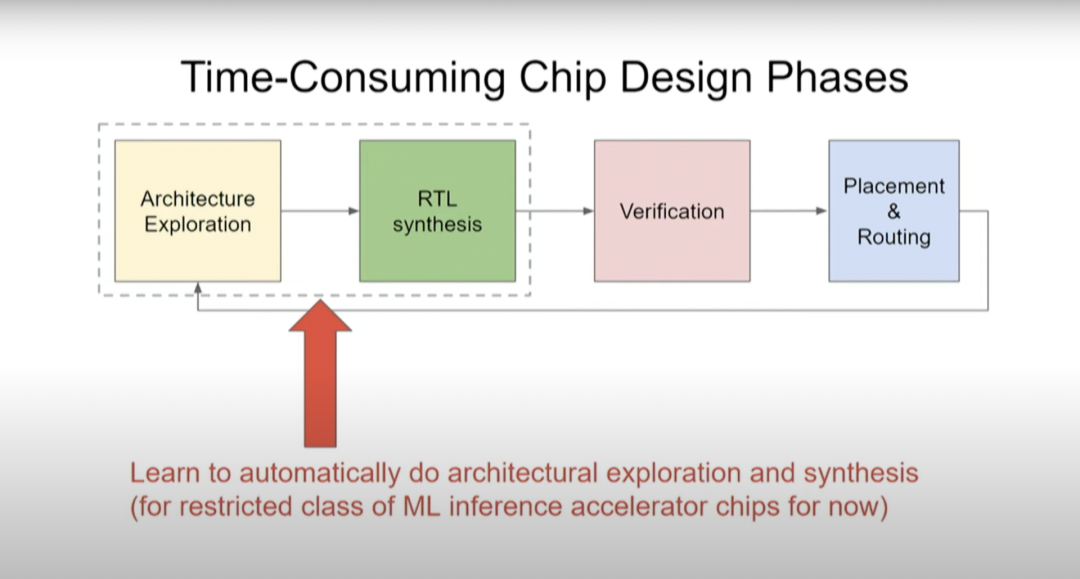
在芯片設(shè)計(jì)中,另一個(gè)比較耗時(shí)的方面是要清楚你究竟想要構(gòu)建何種設(shè)計(jì)。此時(shí)你需要做一些架構(gòu)探索(architectural exploration),然后做RTL綜合。目前計(jì)算機(jī)架構(gòu)師和其他芯片設(shè)計(jì)師等具有不同專業(yè)知識(shí)的人花費(fèi)大量時(shí)間來構(gòu)建他們真正想要的設(shè)計(jì),然后驗(yàn)證、布局和布線,那么我們可以學(xué)習(xí)自動(dòng)做架構(gòu)探索和綜合嗎?
現(xiàn)在我們正在研究的就是如何為已知的問題實(shí)行架構(gòu)探索。如果我們有一個(gè)機(jī)器學(xué)習(xí)模型,并且想要設(shè)計(jì)一個(gè)定制芯片來運(yùn)行這個(gè)模型,這個(gè)過程能否實(shí)現(xiàn)自動(dòng)化,并提出真正擅長(zhǎng)運(yùn)行該特定模型的優(yōu)秀設(shè)計(jì)。
關(guān)于這項(xiàng)工作,我們?cè)赼rXiv發(fā)表了論文《A Full-stack Accelerator Search Technique for Vision Applications》,它著眼于很多不同的計(jì)算機(jī)視覺模型。另外一個(gè)進(jìn)階版本的論文被ASPLOS大會(huì)接收了《A Full-stack Search Technique for Domain Optimized Deep Learning Accelerators》。
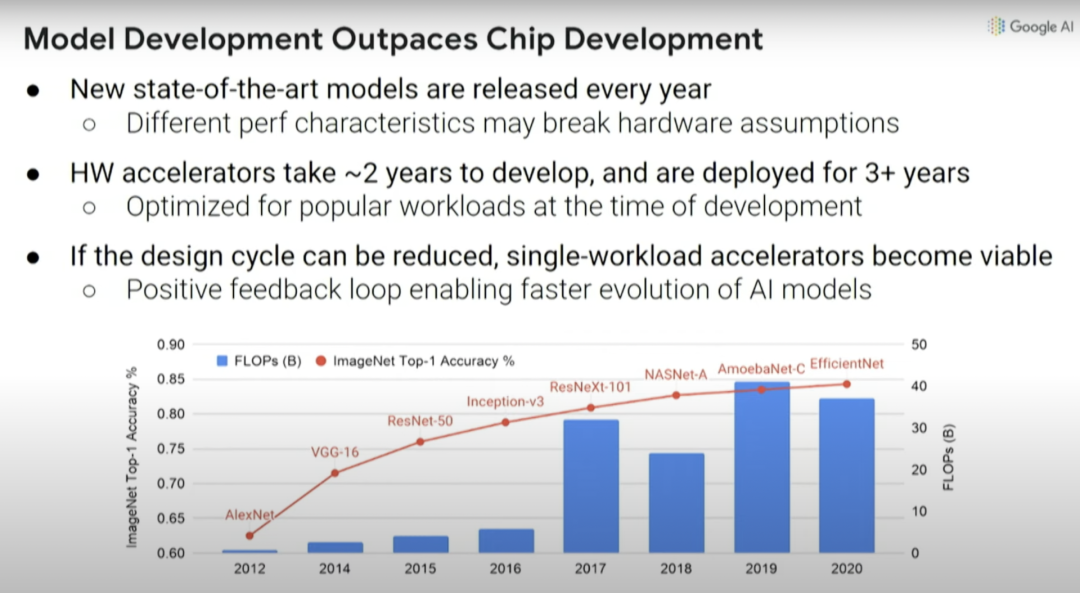
這里要解決的問題是:當(dāng)你設(shè)計(jì)一個(gè)機(jī)器學(xué)習(xí)加速器時(shí),需要考慮你想在哪個(gè)加速器上運(yùn)行什么樣的機(jī)器學(xué)習(xí)模型,而且這個(gè)領(lǐng)域的變化非常之快。
上圖中的紅線是指引入的不同計(jì)算機(jī)視覺模型,以及通過這些新模型實(shí)現(xiàn)的ImageNet識(shí)別準(zhǔn)確率提升。
但問題是,如果你在2016年想要嘗試設(shè)計(jì)一個(gè)機(jī)器學(xué)習(xí)加速器,那么你需要兩年時(shí)間來設(shè)計(jì)芯片,而設(shè)計(jì)出來的芯片三年后就會(huì)被淘汰。你在2016年做的決定將會(huì)影響計(jì)算,要保證在2018年-2021年高效運(yùn)行,這真的很難。比如在2016年推出了Inception-v3模型,但此后計(jì)算機(jī)視覺模型又有四方面的大改進(jìn)。
因此,如果我們能使設(shè)計(jì)周期變得更短,那么也許單個(gè)工作負(fù)載加速器能變得可用。如果我們能在諸多流程中實(shí)現(xiàn)自動(dòng)化,那么我們或許能夠得到正反饋循環(huán),即:縮短機(jī)器學(xué)習(xí)加速器的上市時(shí)間,使其能更適合我們當(dāng)下想要運(yùn)行的模型,而不用等到五年后。
4用機(jī)器學(xué)習(xí)探索設(shè)計(jì)空間
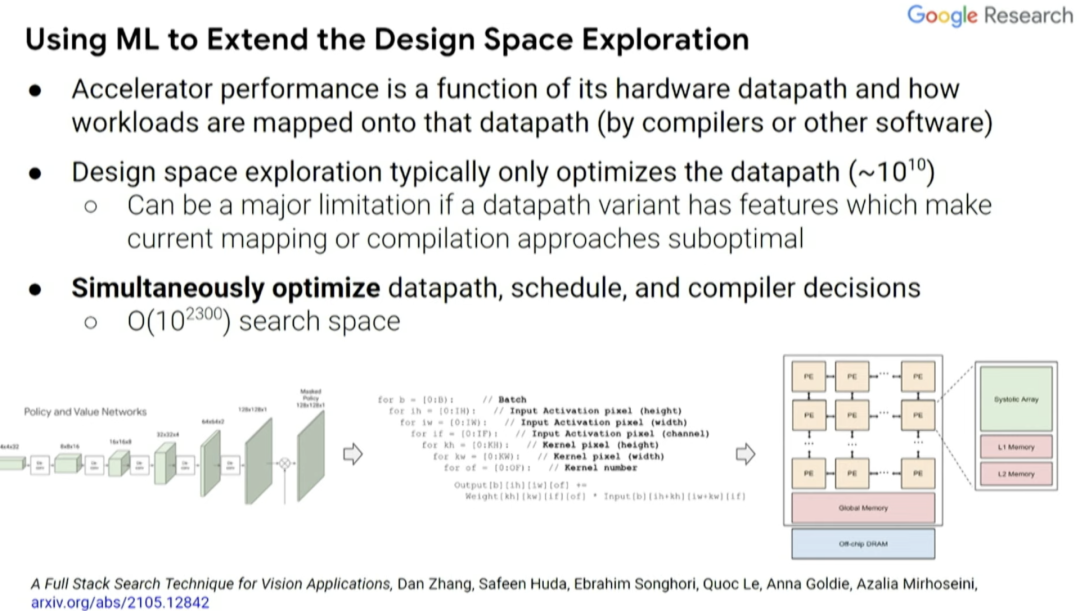
實(shí)際上,我們可以使用機(jī)器學(xué)習(xí)來探索設(shè)計(jì)空間。有兩個(gè)因素影響加速器性能,一是設(shè)計(jì)中內(nèi)置的硬件數(shù)據(jù)通道,二是工作負(fù)載如何通過編譯器而不是更高級(jí)別的軟件映射到該數(shù)據(jù)通道。通常,設(shè)計(jì)空間探索實(shí)際上只考慮當(dāng)前編譯器優(yōu)化的數(shù)據(jù)通道,而不是協(xié)同設(shè)計(jì)的編譯器優(yōu)化和優(yōu)化數(shù)據(jù)通道時(shí)可能會(huì)做的事。
因此,我們能否同時(shí)優(yōu)化數(shù)據(jù)通道、調(diào)度(schedule)和一些編譯器決策,并創(chuàng)建一個(gè)搜索空間,探索出你希望做出的共同設(shè)計(jì)的決策。這是一種覆蓋計(jì)算和內(nèi)存瓶頸的自動(dòng)搜索技術(shù),探索不同操作之間的數(shù)據(jù)通道映射和融合。通常,你希望能夠?qū)⑹挛锶诤显谝黄穑苊鈨?nèi)存?zhèn)鬏數(shù)拿看蝺?nèi)存負(fù)載中執(zhí)行更多操作。
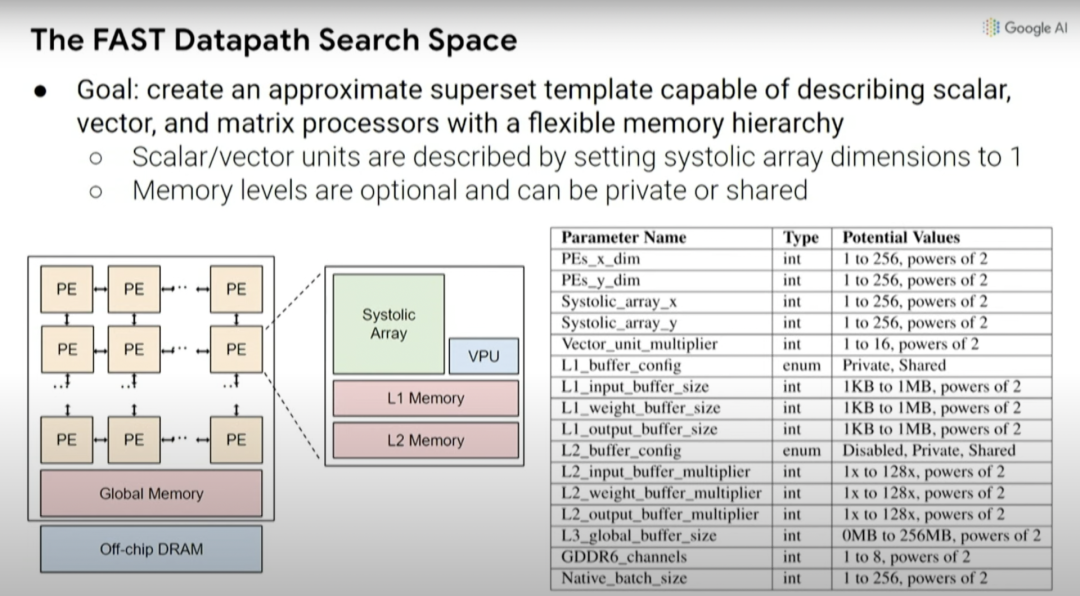
根本上說,我們?cè)跈C(jī)器學(xué)習(xí)加速器中可能做出的設(shè)計(jì)決策創(chuàng)建了一種更高級(jí)別的元搜索空間,因此,可以探索乘法的脈沖列陣(systolic array)在一維或二維情況下的大小,以及不同的緩存大小等等。
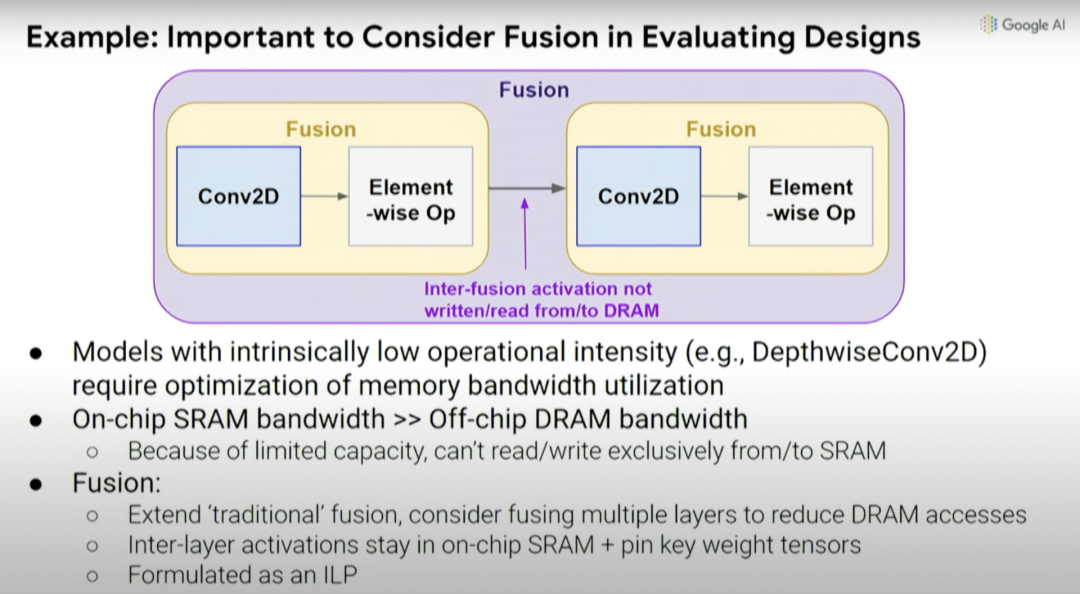
如前所述,考慮編譯器優(yōu)化與硬件設(shè)計(jì)的協(xié)同設(shè)計(jì)也很重要,因?yàn)槿绻J(rèn)編譯器不會(huì)更改,就無法真正利用處理器中底層設(shè)計(jì)單元的變化。實(shí)際上,不一定要考慮特定設(shè)計(jì)的所有效果和影響。
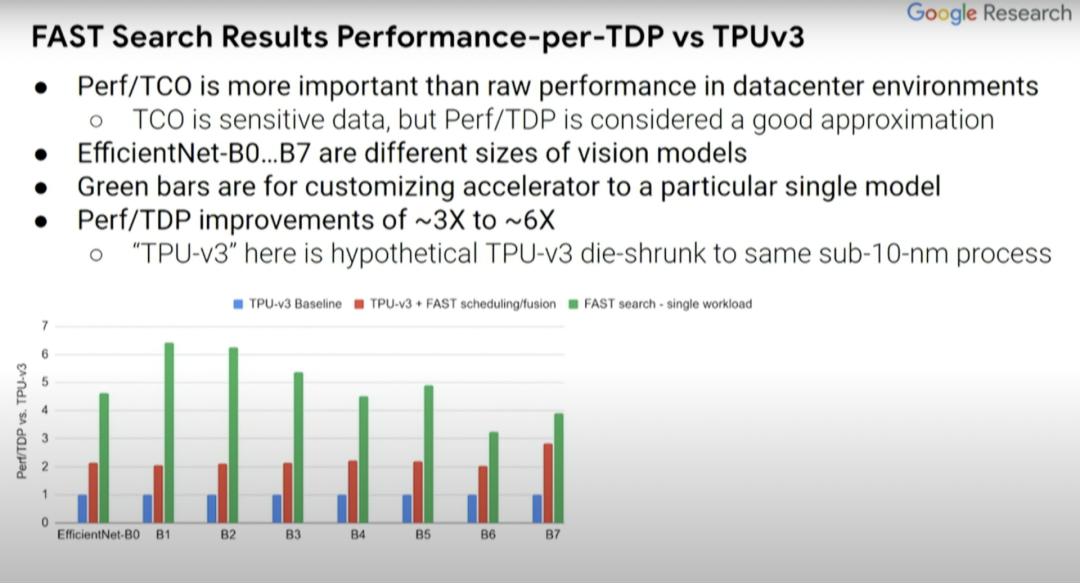
接下來看看這種方式產(chǎn)生的一系列結(jié)果,將這些結(jié)果與TPUv3芯片的baseline(上圖藍(lán)條)進(jìn)行比較。實(shí)際上這是假定型TPUv3芯片,其中模擬器已停止了運(yùn)行。我們已經(jīng)將其縮小到了sub-10納米工藝。我們還將研究TPUv3的軟件效用,以及共同探索在設(shè)計(jì)空間中的編譯器優(yōu)化。
紅條和藍(lán)條表示的內(nèi)容是一致的,但一些探索過的編譯器優(yōu)化不一定在藍(lán)條中得以體現(xiàn),而這里的綠條則表示的是為單一計(jì)算機(jī)視覺模型定制的假定型設(shè)計(jì)。EfficientNet-B0...B7表示相關(guān)但規(guī)模不同的計(jì)算機(jī)視覺模型。與藍(lán)條baseline相比,(綠條的)Perf/TDP的改進(jìn)大約在3到6倍之間。
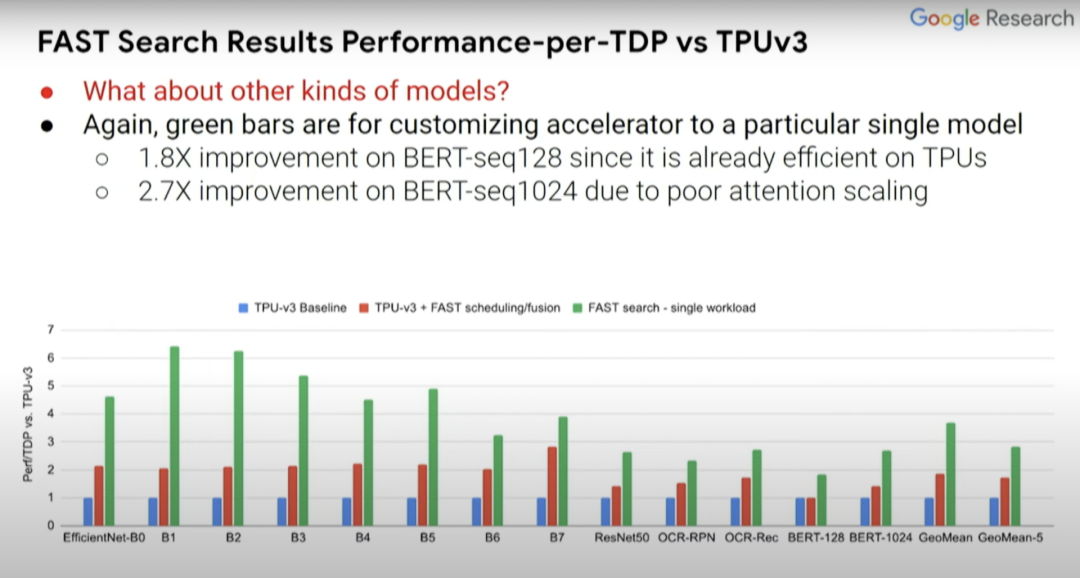
那么除EfficientNet-B0...B7外,其他模型的情況如何?在此前所述的ASPLOS論文中提出更廣泛的模型集,尤其是那些計(jì)算機(jī)視覺以外的BERT-seq 128和BERT-seq 1024等NLP模型。
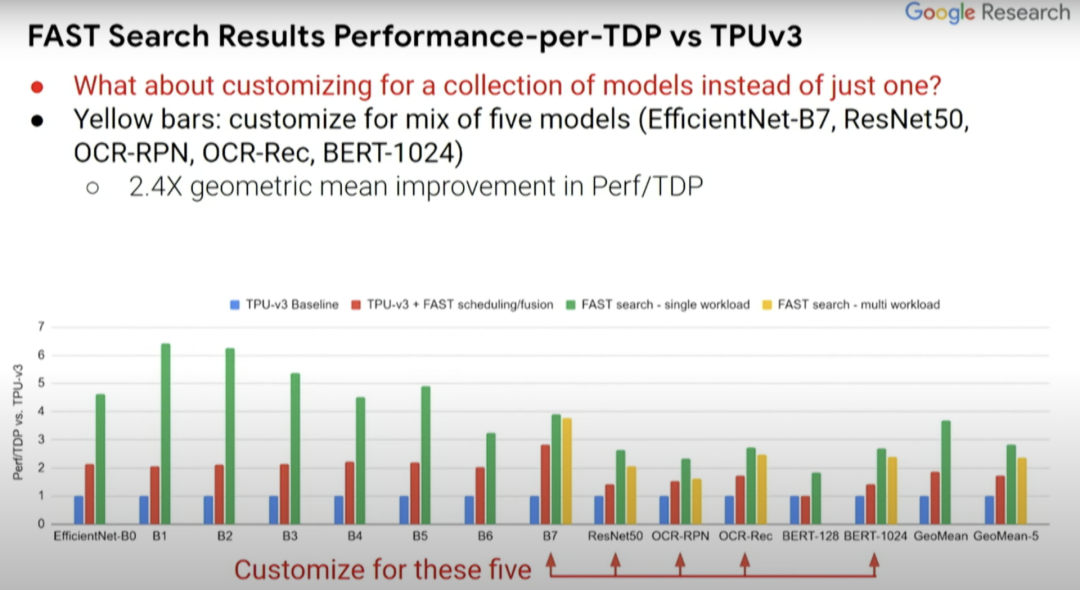
實(shí)際上,定制化芯片不只是適用于單個(gè)機(jī)器學(xué)習(xí)模型,而是使其適用于一組機(jī)器學(xué)習(xí)模型。你可能不想使你的加速器芯片設(shè)計(jì)僅針對(duì)某一項(xiàng)任務(wù),而是想涵蓋你所關(guān)注的那一類任務(wù)。
上圖的黃條代表為五種不同模型設(shè)計(jì)的定制化芯片,而我們想要一個(gè)能同時(shí)運(yùn)行這五種模型(紅色箭頭所指)的芯片,然后就能看出其性能能達(dá)到何種程度。可喜的是,從中可以看到,黃條(單一負(fù)載)并不比綠條(多負(fù)載)的性能低多少。所以你實(shí)際上可以得到一個(gè)非常適合這五種模型的加速器設(shè)計(jì),這就好比你對(duì)其中任何一個(gè)模型都進(jìn)行了優(yōu)化。它的效果可能不是最好的,但已經(jīng)很不錯(cuò)了。
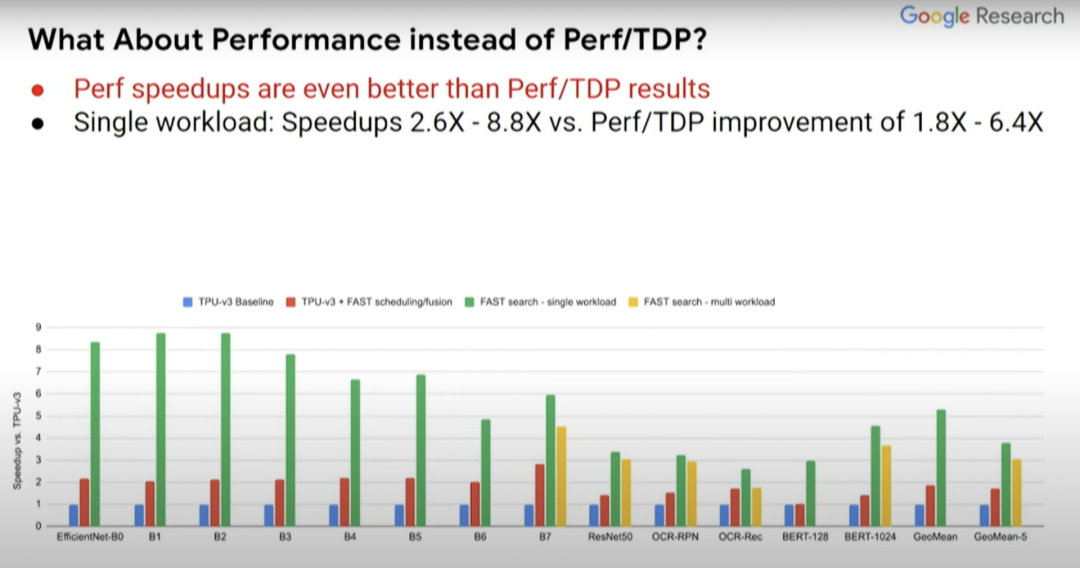
而且,如果你關(guān)注的點(diǎn)是性能而非Perf/TDP,得到的結(jié)果實(shí)際上會(huì)更好。所以結(jié)果如何取決于你關(guān)注的是什么,是絕對(duì)性能還是每瓦性能?在Perf//TDP指標(biāo)中,性能結(jié)果甚至提升了2.6到8.8倍,而非Perf/TDP指標(biāo)下的1.8到6.4倍。
因此,我們能夠針對(duì)特定工作負(fù)載進(jìn)行定制和優(yōu)化,而不用構(gòu)建更多通用設(shè)備。我認(rèn)為這將會(huì)帶來顯著改進(jìn)。如果能縮短設(shè)計(jì)周期,那么我們將能以一種更自動(dòng)化的方式用定制化芯片解決更多問題。
當(dāng)前的一大挑戰(zhàn)是,如果了解下為新問題構(gòu)建新設(shè)計(jì)的固定成本,就會(huì)發(fā)現(xiàn)固定成本還很高,因此不能廣泛用于解決更多問題。但如果我們能大幅降低這些固定成本,那么它的應(yīng)用面將會(huì)越來越廣。
5
總結(jié)
我認(rèn)為,在計(jì)算機(jī)芯片的設(shè)計(jì)過程中,機(jī)器學(xué)習(xí)將大有作為。
如果機(jī)器學(xué)習(xí)在合適的地方得以正確應(yīng)用,那么在學(xué)習(xí)方法(learning approaches)和機(jī)器學(xué)習(xí)計(jì)算的加持下,芯片設(shè)計(jì)周期能不能縮短,只需要幾個(gè)人花費(fèi)幾周甚至幾天完成呢?我們可以用強(qiáng)化學(xué)習(xí)使得與設(shè)計(jì)周期有關(guān)的流程實(shí)現(xiàn)自動(dòng)化,我認(rèn)為這是一個(gè)很好的發(fā)展方向。
目前人們正通過一組或多組實(shí)驗(yàn)來進(jìn)行測(cè)驗(yàn),并基于其結(jié)果來決定后續(xù)研發(fā)方向。如果這個(gè)實(shí)驗(yàn)過程能實(shí)現(xiàn)自動(dòng)化,并且能獲取滿足該實(shí)驗(yàn)正常運(yùn)行的各項(xiàng)指標(biāo),那么我們完全有能力實(shí)現(xiàn)設(shè)計(jì)周期自動(dòng)化,這也是縮短芯片設(shè)計(jì)周期的一個(gè)重要方面。

這是本次演講的部分參考文獻(xiàn)以及相關(guān)論文,主要涉及機(jī)器學(xué)習(xí)在芯片設(shè)計(jì)和計(jì)算機(jī)系統(tǒng)優(yōu)化中的應(yīng)用。

機(jī)器學(xué)習(xí)正在很大程度上改變?nèi)藗儗?duì)計(jì)算的看法。我們想要的是一個(gè)可以從數(shù)據(jù)和現(xiàn)實(shí)世界中學(xué)習(xí)的系統(tǒng),其計(jì)算方法與傳統(tǒng)的手工編碼系統(tǒng)完全不同,這意味著我們要采取新方式,才能創(chuàng)建出我們想要的那種計(jì)算設(shè)備和芯片。同時(shí),機(jī)器學(xué)習(xí)也對(duì)芯片種類和芯片設(shè)計(jì)的方法論產(chǎn)生了影響。
我認(rèn)為,加速定制化芯片設(shè)計(jì)過程中應(yīng)該將機(jī)器學(xué)習(xí)視為一個(gè)非常重要的工具。那么,到底能否將芯片設(shè)計(jì)周期縮短到幾天或者幾周呢?這是可能的,我們都應(yīng)該為之奮斗。
-
計(jì)算機(jī)
+關(guān)注
關(guān)注
19文章
7667瀏覽量
90879 -
芯片設(shè)計(jì)
+關(guān)注
關(guān)注
15文章
1088瀏覽量
55686 -
硬件設(shè)計(jì)
+關(guān)注
關(guān)注
18文章
434瀏覽量
45213 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8505瀏覽量
134690
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論