

大數據常見處理流程包括:原始數據采集、數據清洗、數據存儲、統計分析、存儲至數據倉庫、數據導出、導入數據庫、數據可視化。
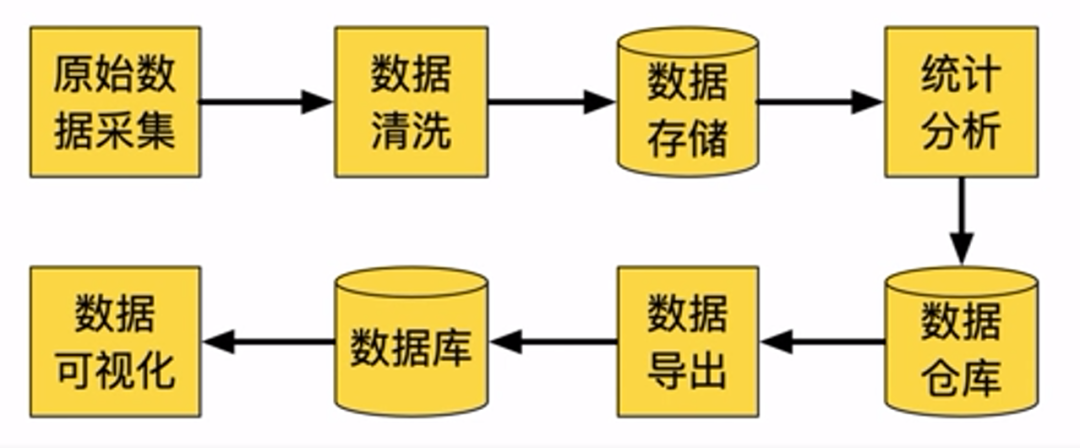
圖片來源:學堂在線《大數據導論》
一、原始數據采集
原始數據采集的方式包括:爬蟲程序采集、應用數據采集。
爬蟲程序采集可在互聯網中爬取需要的數據。
應用數據采集是指通過集群或分布式部署方式,將應用程序的日志文件存儲于多個服務器中,再將日志文件數據集中存儲。
二、數據清洗和數據存儲
因為采集的數據中包含不符合要求的數據,如格式沖突的數據、漏項的數據、錯誤的數據等,所以需要數據清洗將不符合要求的數據去除。
數據清洗過程可以較簡單,也可以較復雜。可以通過向數據缺失位置添加某值的方式簡單完成數據清洗(含個人理解);也可以通過復雜的機器學習模型清洗數據。
數據清洗可借助ETL軟件(根據百度百科:ETL是數據倉庫技術)。一般,數據被清洗后,數據量較大,無法存儲于計算機內存中,因此,需將數據存儲于HDFS(數據存儲)中或其他大數據存儲方式中。
三、統計分析和數據倉庫
統計分析可通過選擇合適統計分析工具完成。可使用MapReduce技術實現并行統計分析,也可使用Hive數據倉庫(Hive數據倉庫具有數據整理、特殊查詢、分析存儲功能)、Python、R等進行統計分析。
統計分析的難點不在于選擇統計分析工具,而在于需求和分析對象。個人理解:具體的需求和分析對象多樣導致統計分析不能簡單地以某一方式解決所有統計分析問題。
統計分析結束后,數據可被存儲于數據倉庫中,可使用Hive數據倉庫搭建所需的數據倉庫。數據倉庫的數據不能直接向用戶呈現。
四、數據導出和數據庫
因為數據倉庫的數據不能直接向用戶呈現,所以需要將數據從數據倉庫導出,并將數據導入數據庫中以實現數據可視化。數據導出可使用Sqoop(Sqoop可提供數據導入功能)。
數據庫一般為關系型數據庫。
五、數據可視化
數據可視化的目標是使數據可被直觀展示,傳統圖形化展示方式種類較多(根據網絡資料理解:傳統圖形化展示方式包括條形圖、排列圖、餅圖、環(huán)形圖等)。大數據新型可視化方式包括:氣泡圖、數據畫像、地圖涂色等。
六、大數據應用案例
下文介紹Hadoop自帶的MapReduce應用案例WordCount,WordCount可統計文件的詞頻。
(1)啟動Hadoop系統服務,需啟動HDFS與Yarn服務(根據百度百科:Yarn是新的Hadoop資源管理器,是通用資源管理系統)。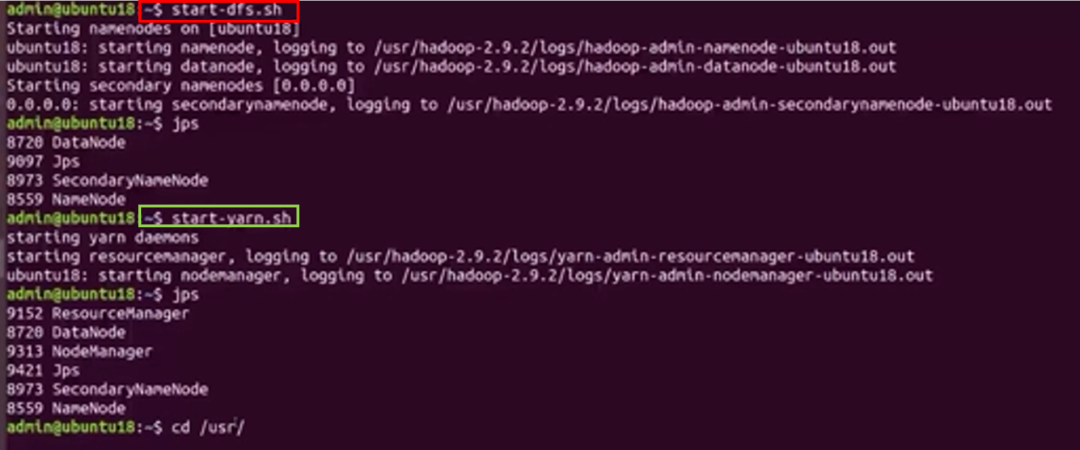
圖中紅框內命令為HDFS啟動命令,綠框內命令為Yarn服務啟動命令,圖片來源:根據學堂在線《大數據導論》資料制作
(2)檢查Hadoop安全模式是否為“OFF”狀態(tài),如果Hadoop安全模式的狀態(tài)為“ON”,則只能讀取HDFS中的數據,不能向HDFS中寫入數據。
(3)準備需要處理的數據,即查看文本文件中的內容。
圖中紅框內命令為查看文件內容命令,綠框內為文件中的內容,圖片來源:根據學堂在線《大數據導論》資料制作
(4)執(zhí)行WordCount應用程序。WordCount的具體命令是hadoopjar hadoopmapreduce-examples-2.9.2.jarwordcount 被統計文件的目錄名與文件名 統計結果輸出文件目錄名與文件名。
圖中紅框內為WordCount應用程序統計結果輸出文件的內容,圖片來源:根據學堂在線《大數據導論》資料制作
審核編輯:劉清
-
數據庫
+關注
關注
7文章
3889瀏覽量
65684 -
機器學習
+關注
關注
66文章
8484瀏覽量
133968 -
python
+關注
關注
56文章
4823瀏覽量
86037 -
HDFS
+關注
關注
1文章
31瀏覽量
9815
原文標題:大數據相關介紹(11)——大數據應用的開發(fā)流程
文章出處:【微信號:行業(yè)學習與研究,微信公眾號:行業(yè)學習與研究】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
基于RV1126開發(fā)板的AI算法開發(fā)流程
基于RV1126開發(fā)板的AI算法開發(fā)流程

大數據與云計算是干嘛的?
工程大數據平臺
緩存對大數據處理的影響分析
ADS1675最大數據吞吐率是是多少?
raid 在大數據分析中的應用
emc技術在大數據分析中的角色
智慧城市與大數據的關系
電機控制方案開發(fā)流程
基于Kepware的Hadoop大數據應用構建-提升數據價值利用效能
使用CYW20829的BLE進行最大數據發(fā)送應用,BLE丟失數據如何解決?
迪文串口屏ModBus開發(fā)流程






 工商網監(jiān)
工商網監(jiān)

評論