 爬蟲的學習方法
爬蟲的學習方法
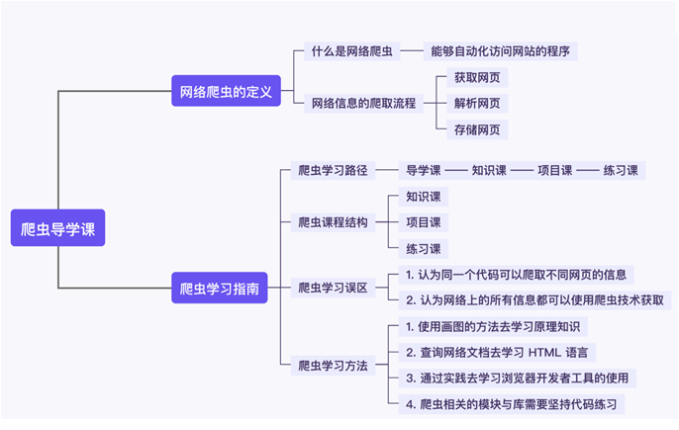
1. 網絡爬蟲的定義
1.1 爬蟲是什么?
爬蟲的本質就是模仿人類自動訪問網站的程序,你在瀏覽器中做的大部分動作基本都可以通過網絡爬蟲程序來實現。
網絡爬蟲指的是能夠自動化訪問網站的程序,其目的一般是提取和保存網頁信息。
爬蟲能做很多事,它結合數據分析可以做商業分析,還可以給應用程序的開發提供數據支持,比如:爬二手房成交均價是多少?節日期間酒店的價格…等等。
在數據量爆發式增長的互聯網時代,網站與用戶的溝通,本質上就是數據的交換。以百度為例,你在搜索的時候會發現每個搜索結果下面都有一個百度快照。
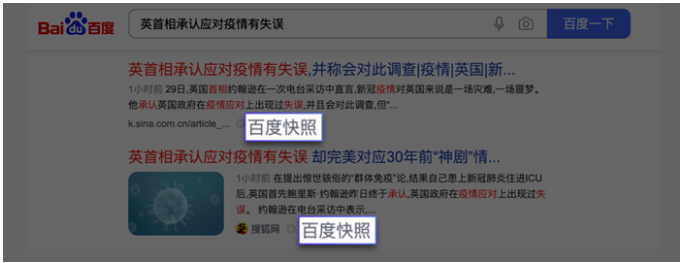
點擊百度快照,你會發現網址的開頭有 baidu 這個詞,也就是說這個網頁屬于百度。
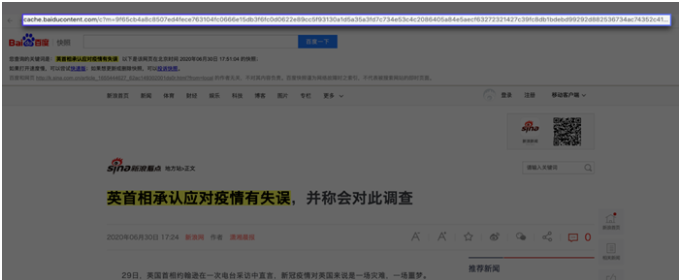
這是因為,百度這家公司會源源不斷地把千千萬萬個網站爬取下來,存儲在自己的服務器上。
你在百度搜索的本質就是在它的服務器上搜索信息,你搜索到的結果是一些超鏈接,在超鏈接跳轉之后你就可以訪問其它網站了。
1.2 網絡信息的爬取流程
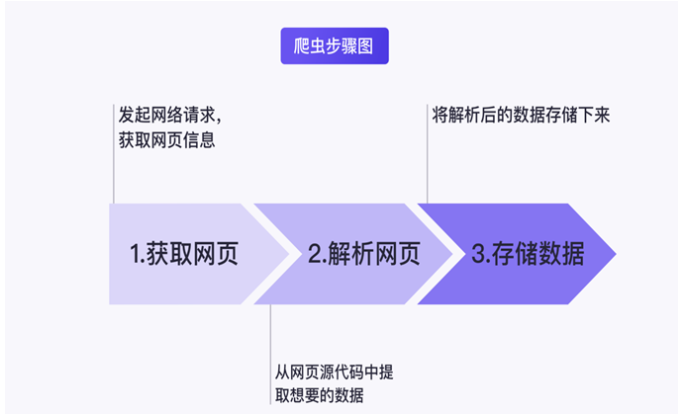
網絡爬蟲的流程主要可以分為三步,分別是:獲取網頁、解析網頁以及存儲數據。
獲取網頁,顧名思義就是獲取網頁信息,在網絡爬蟲技術中這里獲取的就是網頁源代碼。
解析網頁,指的是從網頁源代碼中提取想要的數據,由于網頁的結構有一定的規則,配合 Python 的一些第三方庫我們可以高效地從中提取網頁數據。
存儲數據,就是將數據存儲下來。
2. 學習指南
2.1 爬蟲學習路徑
2.2 爬蟲課程的學習誤區
誤區1:認為同一個代碼可以爬取不同網頁的信息。
爬蟲程序不是萬能鑰匙。不同網頁結構的爬蟲代碼也是不一樣的,我們要學習探索網頁結構,在各色各樣的網站中找到它的爬取方法。
誤區2:認為網絡上的所有信息都可以使用爬蟲技術獲取。
網絡上的信息并非都能隨意使用。濫用爬蟲程序可能會侵犯別人隱私,占用網站資源,甚至會觸犯法律風險,引發牢獄之災。在網絡世界中,有一個專門的 Robots 協議來規范爬蟲,維護網絡秩序。它可以告訴網絡爬蟲程序哪些內容是可以獲取的,哪些內容是不能獲取的。
2.3 爬蟲學習方法
在爬蟲課程中將深入學習一些 Python 模塊與庫的使用,除此之外還會學習大量的網絡請求、爬蟲的原理知識以及工具使用。
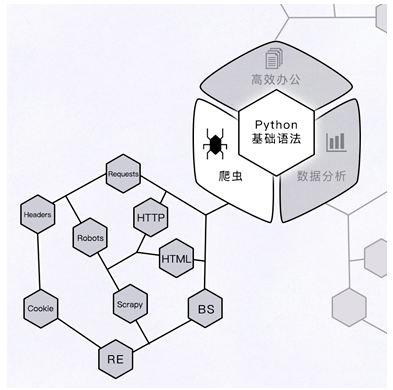
【學習方法】
1. 使用畫圖的方法去學習網絡原理
爬蟲的本質是通過程序模仿人類上網的過程,你必須了解一些基本的網絡原理才能寫好爬蟲程序。
對于這些網絡原理,你更需要的是去理解,而不是死記硬背。當你感覺理解起來很痛苦時,你可以動手將你的理解畫出來。
比如網絡請求,它指的是我們從瀏覽器點開一個網絡鏈接再到我們看到實際網頁這一過程中的工作原理。這些工作原理如下圖:
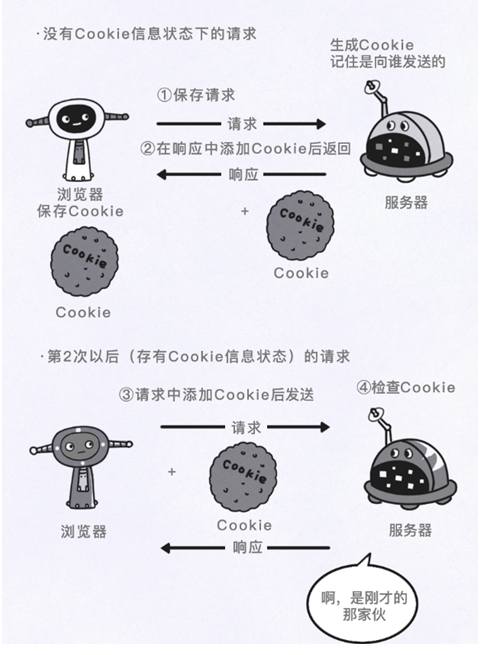
以上圖為例,這一方法并不需要什么繪畫技巧,重要的是將你的想法畫出來,以此來加深你對這一知識點的印象。
2. 查詢網絡文檔去學習 HTML 語言
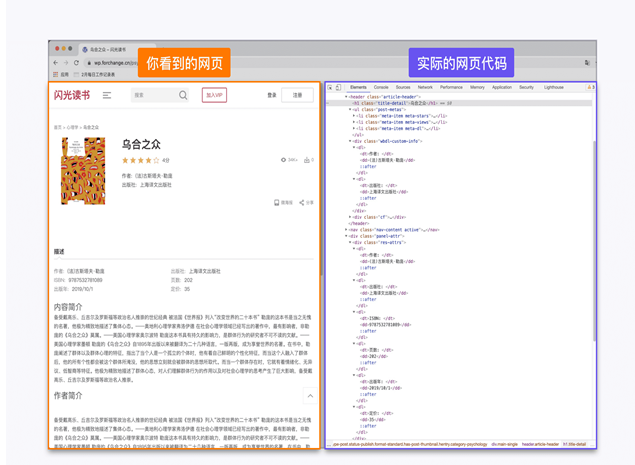
由于爬蟲獲取的信息大部分都是網頁的源代碼,這些源代碼基本都是使用 HTML 語言編寫的,所以 HTML 語言對于爬蟲的學習十分重要。對于HTML只需要簡單理解 HTML 語言的標簽結構,遇到不熟悉的標簽再去網上查詢即可滿足爬蟲對于 HTML 語言掌握水平的要求。
3. 通過實踐去學習瀏覽器開發者工具的使用
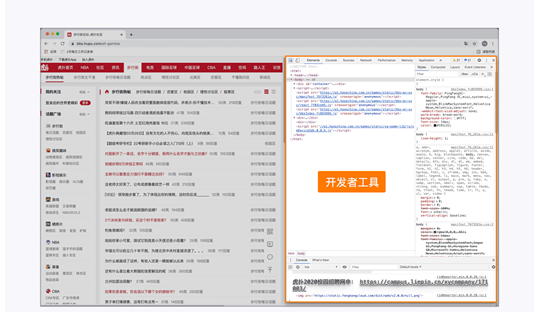
上圖展示的是瀏覽虎撲網時,打開瀏覽器開發者工具查看網頁元素。這部分的學習專注于實踐,因為幾乎所有的瀏覽器都有開發者工具,我們可以在日常網上沖浪的時候打開它,熟悉基本操作。
4. 爬蟲相關的模塊與庫需要堅持代碼練習
對于 Python 模塊與庫的知識,要通過練習、實操的方式熟悉這些代碼。
【總結】
end
-
瀏覽器
+關注
關注
1文章
1022瀏覽量
35330 -
程序
+關注
關注
117文章
3785瀏覽量
81005 -
爬蟲
+關注
關注
0文章
82瀏覽量
6867
發布評論請先 登錄
相關推薦
MCU的學習方法
快速的學習方法?
深度討論集成學習方法,解決AI實踐難題






 工商網監
工商網監
評論