 AMD要在CPU上堆疊DRAM內存,新一代捆綁銷售誕生?
AMD要在CPU上堆疊DRAM內存,新一代捆綁銷售誕生?
電子發燒友網報道(文/周凱揚)自從2.5D/3D封裝、Chiplet、異構集成等技術出現以來,CPU、GPU和內存之間的界限就已經變得逐漸模糊。單個SoC究竟集成了哪些邏輯單元和存儲單元,全憑借廠商自己的設計路線。這樣的設計其實為單芯片的能效比帶來了一輪新的攀升,但也極大地增加了開發難度。即便如此,還是有不少廠商在不遺余力地朝這個方向發展,最典型的莫過于AMD。
AMD的存儲堆疊之路
要說玩堆疊存儲,AMD確實是走得最靠前的一位,例如AMD如今在消費級和數據中心級別CPU上逐漸使用的3D V-Cache技術,就是直接將SRAM緩存堆疊至CPU上。將在今年正式落地的第四代EPYC服務器處理器,就采用了13個5nm/6nm Chiplet混用的方案,最高將L3緩存堆疊至了可怕的384MB。
在消費端,AMD的Ryzen 7 5800X3D同樣也以驚人的姿態出世,以超大緩存帶來了極大的游戲性能提升。即將正式發售的Ryzen 9 7950X3D也打出了128MB三級緩存的夸張參數,這些產品的出現可謂打破了過去CPU廠商拼時鐘頻率、拼核心數的僵局,讓消費者真切地感受到了額外的體驗提升。

MI300 APU / AMD
GPU也不例外,雖然AMD如今的消費級GPU基本已經放棄了HBM堆疊方案,但是在AMD的數據中心GPU,例如Instinct MI250X,卻依然靠著堆疊做到了128GB的HBM2e顯存,做到了3276.8GB/s的峰值內存帶寬。而下一代MI300,AMD則選擇了轉向APU方案,將CPU、GPU和HBM全部整合在一起,以新的架構沖擊Exascale級的AI世代。
其實這也是AMD收購Xilinx最大的收獲之一,早在十多年前Xilinx的3DIC技術也已經為多Die堆疊打下了基礎。在收購Xilinx之際,AMD也提到這次交易會擴張AMD在die堆疊、封裝、Chiplet和互聯技術上的開發能力。在完成Xilinx的收購后,也可以看出AMD在架構上的創新有了很大的飛躍。
在近期的ISSCC 2023上,AMD CEO蘇姿豐透露了他們的下一步野心,那就是直接將DRAM堆疊至CPU上。這里的堆疊并非硅中介層互聯、存儲單元垂直堆疊在一起的2.5D封裝方案,也就是如今常見的HBM統一內存方案,AMD提出的是直接將計算單元與存儲單元垂直堆疊在一起的3D混合鍵封裝方案。
CPU與DRAM垂直堆疊
主流服務器性能的提升速度,已經快要趕上過去的摩爾定律了。根據AMD統計的CPU供應商數據,每過2.4年主流服務器性能就會翻一倍。可限制其繼續發展的不再只是放緩的摩爾定律,還有內存上帶來的限制。內存墻這樣的性能瓶頸,不僅在限制CPU的性能發揮,同樣限制了GPU的性能發揮。
考慮到明面上解決這個問題的主力軍是存儲廠商,所以提出的大部分創新方案,例如存內計算等等,也都是創造算力更高的存儲器產品。蘇姿豐博士也指出,從她這個處理器從業者的角度來說,這一路線有些反常理,但從系統層面來說,她也可以理解該需求存在的意義。而AMD這次提出的方案,則是從計算芯片出發,將存儲器堆疊整合進去。

CPU與DRAM垂直堆疊 / AMD
從AMD給出的能量效率分析來看,DIMM這樣的片外內存訪問能量效率在12pj/bit左右,2.5D的HBM方案在3.5pj/bit左右,而3D垂直堆疊的鍵合方案卻可以做到0.2pj/bit,從而利用更低的功耗來做到大帶寬。況且由于計算單元和存儲單元的集成度更高了,傳輸的延遲必然也會有顯著的降低。
這套方案的出現意味著至少堆疊的內存容量足夠大,服務器CPU甚至可以省去DIMM內存插槽,進一步減小空間占用。但這套方案具體能做堆疊多少內存,AMD并沒有給出具體的數字,如果可堆疊的內存數量與如今的L3緩存一樣僅有數百兆的話,那帶來的性能提升很可能不值一提。
另外就是散熱問題,從AMD給出的示意圖來看,他們選擇了內存單元在上,計算單元在下的方案,這種3D架構很可能會對散熱產生一定負面作用,但性能損失會相對較少一些。比如MI300方案中,AMD就換成了CPU和GPU單元在上,緩存和互聯在下的方案。
捆綁銷售嫌疑?
在消費級領域,其實CPU與內存捆綁銷售已經不是什么新鮮事了,就拿蘋果的M系列芯片為例。自打蘋果轉向Arm陣營,推出M系列芯片后,Mac生態的定制空間就基本只存在于購買前了,雖然華強北的大神們依然能夠找到一些方式來擴展固態硬盤閃存,但內存基本就與SoC徹底綁定了,用戶只能忍受高昂的容量定價,才不會在高負載工作時出現內存不夠用的窘境。
可在服務器市場,已經有了相當成熟的DIMM內存生態,甚至未來還有CXL內存虎視眈眈,AMD這套“捆綁銷售”的方案究竟能否收獲良好的市場反響我們無從得知,很明顯這對內存模組廠商是存在一定威脅的。但話又說回來,AMD這套方案并沒有徹底斷絕擴展內存的可能性,在需要超大容量的內存池時,依然可以選擇傳統的擴展方案,而不是死磕堆疊內存的方案。
AMD的方案更像是給到了一個片上高速方案,從當下的工藝來看,應該還難以實現大容量的堆疊。所以在CPU上垂直堆疊DRAM,更像是AMD的另一套負載加速方案。畢竟根據蘇姿豐博士的說法,AMD也很清楚現有的3D V-Cache SRAM堆疊方案只能提高特定負載的性能,DRAM堆疊方案的性能加速覆蓋面無疑要更廣一些。
寫在最后
其實ChatGPT這樣的應用出現,不僅帶動了一波GPU訂單量的狂飆,也讓HBM、DDR5這些大帶寬的內存有了用武之地,讓人們終于看到了打破內存墻的應用價值,而不只是將其視為一個徒增成本的性能瓶頸。
而AMD雖然提出了將內存堆疊至CPU上的技術路線,也并沒有放棄對其他方案的考量,比如他們也在和三星展開HBM2上的存算一體研究。如果AMD選擇將CPU堆疊內存與存算一體結合在一起的話,或許會給其數據中心產品帶來更大的優勢。
AMD的存儲堆疊之路
要說玩堆疊存儲,AMD確實是走得最靠前的一位,例如AMD如今在消費級和數據中心級別CPU上逐漸使用的3D V-Cache技術,就是直接將SRAM緩存堆疊至CPU上。將在今年正式落地的第四代EPYC服務器處理器,就采用了13個5nm/6nm Chiplet混用的方案,最高將L3緩存堆疊至了可怕的384MB。
在消費端,AMD的Ryzen 7 5800X3D同樣也以驚人的姿態出世,以超大緩存帶來了極大的游戲性能提升。即將正式發售的Ryzen 9 7950X3D也打出了128MB三級緩存的夸張參數,這些產品的出現可謂打破了過去CPU廠商拼時鐘頻率、拼核心數的僵局,讓消費者真切地感受到了額外的體驗提升。
MI300 APU / AMD
GPU也不例外,雖然AMD如今的消費級GPU基本已經放棄了HBM堆疊方案,但是在AMD的數據中心GPU,例如Instinct MI250X,卻依然靠著堆疊做到了128GB的HBM2e顯存,做到了3276.8GB/s的峰值內存帶寬。而下一代MI300,AMD則選擇了轉向APU方案,將CPU、GPU和HBM全部整合在一起,以新的架構沖擊Exascale級的AI世代。
其實這也是AMD收購Xilinx最大的收獲之一,早在十多年前Xilinx的3DIC技術也已經為多Die堆疊打下了基礎。在收購Xilinx之際,AMD也提到這次交易會擴張AMD在die堆疊、封裝、Chiplet和互聯技術上的開發能力。在完成Xilinx的收購后,也可以看出AMD在架構上的創新有了很大的飛躍。
在近期的ISSCC 2023上,AMD CEO蘇姿豐透露了他們的下一步野心,那就是直接將DRAM堆疊至CPU上。這里的堆疊并非硅中介層互聯、存儲單元垂直堆疊在一起的2.5D封裝方案,也就是如今常見的HBM統一內存方案,AMD提出的是直接將計算單元與存儲單元垂直堆疊在一起的3D混合鍵封裝方案。
CPU與DRAM垂直堆疊
主流服務器性能的提升速度,已經快要趕上過去的摩爾定律了。根據AMD統計的CPU供應商數據,每過2.4年主流服務器性能就會翻一倍。可限制其繼續發展的不再只是放緩的摩爾定律,還有內存上帶來的限制。內存墻這樣的性能瓶頸,不僅在限制CPU的性能發揮,同樣限制了GPU的性能發揮。
考慮到明面上解決這個問題的主力軍是存儲廠商,所以提出的大部分創新方案,例如存內計算等等,也都是創造算力更高的存儲器產品。蘇姿豐博士也指出,從她這個處理器從業者的角度來說,這一路線有些反常理,但從系統層面來說,她也可以理解該需求存在的意義。而AMD這次提出的方案,則是從計算芯片出發,將存儲器堆疊整合進去。
CPU與DRAM垂直堆疊 / AMD
從AMD給出的能量效率分析來看,DIMM這樣的片外內存訪問能量效率在12pj/bit左右,2.5D的HBM方案在3.5pj/bit左右,而3D垂直堆疊的鍵合方案卻可以做到0.2pj/bit,從而利用更低的功耗來做到大帶寬。況且由于計算單元和存儲單元的集成度更高了,傳輸的延遲必然也會有顯著的降低。
這套方案的出現意味著至少堆疊的內存容量足夠大,服務器CPU甚至可以省去DIMM內存插槽,進一步減小空間占用。但這套方案具體能做堆疊多少內存,AMD并沒有給出具體的數字,如果可堆疊的內存數量與如今的L3緩存一樣僅有數百兆的話,那帶來的性能提升很可能不值一提。
另外就是散熱問題,從AMD給出的示意圖來看,他們選擇了內存單元在上,計算單元在下的方案,這種3D架構很可能會對散熱產生一定負面作用,但性能損失會相對較少一些。比如MI300方案中,AMD就換成了CPU和GPU單元在上,緩存和互聯在下的方案。
捆綁銷售嫌疑?
在消費級領域,其實CPU與內存捆綁銷售已經不是什么新鮮事了,就拿蘋果的M系列芯片為例。自打蘋果轉向Arm陣營,推出M系列芯片后,Mac生態的定制空間就基本只存在于購買前了,雖然華強北的大神們依然能夠找到一些方式來擴展固態硬盤閃存,但內存基本就與SoC徹底綁定了,用戶只能忍受高昂的容量定價,才不會在高負載工作時出現內存不夠用的窘境。
可在服務器市場,已經有了相當成熟的DIMM內存生態,甚至未來還有CXL內存虎視眈眈,AMD這套“捆綁銷售”的方案究竟能否收獲良好的市場反響我們無從得知,很明顯這對內存模組廠商是存在一定威脅的。但話又說回來,AMD這套方案并沒有徹底斷絕擴展內存的可能性,在需要超大容量的內存池時,依然可以選擇傳統的擴展方案,而不是死磕堆疊內存的方案。
AMD的方案更像是給到了一個片上高速方案,從當下的工藝來看,應該還難以實現大容量的堆疊。所以在CPU上垂直堆疊DRAM,更像是AMD的另一套負載加速方案。畢竟根據蘇姿豐博士的說法,AMD也很清楚現有的3D V-Cache SRAM堆疊方案只能提高特定負載的性能,DRAM堆疊方案的性能加速覆蓋面無疑要更廣一些。
寫在最后
其實ChatGPT這樣的應用出現,不僅帶動了一波GPU訂單量的狂飆,也讓HBM、DDR5這些大帶寬的內存有了用武之地,讓人們終于看到了打破內存墻的應用價值,而不只是將其視為一個徒增成本的性能瓶頸。
而AMD雖然提出了將內存堆疊至CPU上的技術路線,也并沒有放棄對其他方案的考量,比如他們也在和三星展開HBM2上的存算一體研究。如果AMD選擇將CPU堆疊內存與存算一體結合在一起的話,或許會給其數據中心產品帶來更大的優勢。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
amd
+關注
關注
25文章
5466瀏覽量
134095 -
DRAM
+關注
關注
40文章
2311瀏覽量
183447
發布評論請先 登錄
相關推薦
佰維存儲發布新一代LPDDR5X內存與DDR5內存模組
近日,存儲領域的領先企業佰維存儲推出了其新一代高效能內存——LPDDR5X。這款內存產品采用了先進的1bnm制程工藝,相較于上一代產品,其數據傳輸速率有了顯著提升,高達8533Mbps
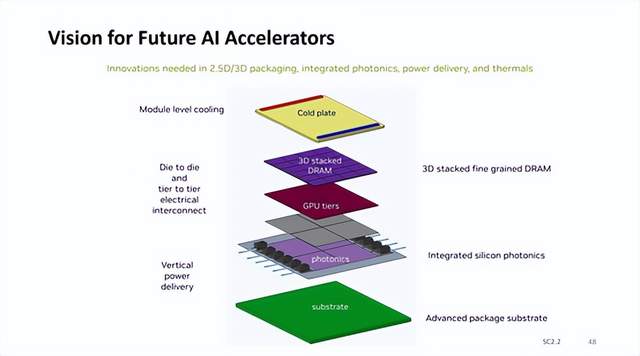
英偉達AI加速器新藍圖:集成硅光子I/O,3D垂直堆疊 DRAM 內存
加速器設計的愿景。 英偉達認為未來整個 AI 加速器復合體將位于大面積先進封裝基板之上,采用垂直供電,集成硅光子 I/O 器件,GPU 采用多模塊設計,3D 垂直堆疊 DRAM 內存,并在模塊內直接整合
AMD發布新一代AI芯片MI325X
在舊金山舉辦的Advancing AI 2024大會上,AMD正式推出了其新一代AI芯片——GPU AMD Instinct MI325X。這款芯片的發布標志著AMD在人工智能領域邁出
主板自檢cpu和內存燈一直來回閃
當你遇到主板自檢時CPU和內存燈一直來回閃爍的情況,這通常意味著硬件檢測過程中存在問題。這個問題可能涉及到多個方面,包括硬件故障、BIOS設置錯誤、兼容性問題等。 1. 硬件故障 1.1 CP
三星積極研發LLW DRAM內存,劍指蘋果下一代XR設備市場
近日,韓媒ZDNet Korea報道,三星電子正全力投入到低延遲寬I/O(LLW DRAM)內存的研發中,旨在為未來蘋果Vision Pro之后的下一代頭戴式顯示器(XR設備)訂單做好充分準備。這
三星與海力士引領DRAM革新:新一代HBM采用混合鍵合技術
在科技日新月異的今天,DRAM(動態隨機存取存儲器)作為計算機系統中的關鍵組件,其技術革新一直備受矚目。近日,據業界權威消息源透露,韓國兩大DRAM芯片巨頭——三星和SK海力士,都將在新一代
美光科技發布新一代GDDR7顯存
在近日舉行的臺北國際電腦展上,美國存儲芯片巨頭美光科技正式發布了其新一代GDDR7顯存。這款新型GPU顯卡內存基于美光的1βDRAM架構,將內存
AMD重磅發布新一代AI PC芯片
AMD CEO蘇姿豐于近日在臺北國際電腦展(COMPUTEX)上亮相,首次發布了AMD Zen 5系列的下一代高效能運算CPU——“Ryze
超微發布新款AMD H13代CPU服務器產品
超微(Supermicro)近日宣布推出全新AMD H13代CPU服務器產品系列,再度鞏固其在人工智能、云技術、存儲和5G/邊緣計算領域的領先地位。此次新品在性能和效率上均實現了卓越平
SK海力士HBM4E內存2025年下半年采用32Gb DRAM裸片量產
值得注意的是,目前全球三大內存制造商都還未開始量產1c nm(第六代10+nm級)制程DRAM內存顆粒。早前報道,三星電子與SK海力士預計今年內實現1c nm
華碩微星發布AGESA固件更新,確認兼容AMD新一代Ryzen處理器
近日,華碩與微星先后對 AMD 600 系列主板推出AGESA固件更新,確認了其兼容“下一代AMD Ryzen CPU”的能力;技嘉亦證實,下一代
JEDEC發布:GDDR7 DRAM新規范,專供顯卡與GPU使用
三星電子和SK海力士計劃在今年上半年量產下一代顯卡用內存GDDR7 DRAM,這是用于圖形處理單元(GPU)的最新一代高性能內存。
發表于 03-18 10:35
?713次閱讀

瀾起科技:DDR5第三子代RCD芯片將隨新一代CPU平臺規模出貨
將隨著支持內存速率6400MT/S的新一代服務器CPU平臺的發布而開始規模出貨。此外,DDR5第四子代RCD芯片的工程樣片已經送樣給主要的內存廠商進行評估。
DRAM合約價一季度漲幅預計13~18%,移動設備DRAM引領市場
據DRAM產品分類顯示,PC DRAM方面,DDR5訂單需求未得到充分滿足,買方預期DDR4價格將進一步上漲,這激發了備貨需求。盡管新一代設備向DDR5轉型,但對于DDR4采購量增幅不
深度解析HBM內存技術
HBM作為基于3D堆棧工藝的高性能DRAM,打破內存帶寬及功耗瓶頸。HBM(High Bandwidth Memory)即高帶寬存儲器,通過使用先進封裝(如TSV硅通孔、微凸塊)將多個DRAM芯片進行






 工商網監
工商網監
評論