

訓練支撐許多現代人工智能(AI)工具的大型神經網絡都需要真實強大的計算能力。例如,OpenAI最先進的語言模型GPT-3訓練就需要驚人的10億億次運算,其計算時間耗資約500萬美元。工程師們認為他們已經找到了一種方法,通過使用不同的方式表示數字,進而減輕計算負擔。
早在2017年,當時在A*STAR計算資源中心和新加坡國立大學就職的約翰?古斯塔夫森(John Gustafson)以及在星際機器人與電腦公司任職的艾薩克?約莫托(Isaac Yonemoto)就開發了一種新的數字表示方法。這些數字稱為“posit”,他們提議將這些數字作為對目前使用的標準浮點算數處理器的改進表示。
現在,馬德里康普頓斯大學的一個研究團隊開發了首個可在硬件中實現posit標準的處理器內核,并表明,與使用標準浮點數字計算相比,基本計算任務的位對位(bit-for-bit)精度提高了4個數量級。他們在2022年9月的IEEE計算機算數研討會上發表了其研究結果。
“如今,摩爾定律似乎已開始衰落。”康普頓斯大學ArTeCS小組的研究生研究員大衛?馬拉森?金塔納(David Mallasén Quintana)說,“所以我們需要找到其他方法來提高機器的性能。其中一種方法就是改變我們的實數編碼方式,以及如何表示實數。”
用數字表示方法來突破極限的并非只有康普頓斯團隊。早在2022年9月,Arm、英特爾和英偉達就形成了一項技術規范,在機器學習應用程序中,使用8位浮點數字替代通常的32位或16位浮點數字,即使用短小、低精度的格式,以降低計算精度為代價,提高計算效率和內存使用率。
實數不能在硬件中完美表示,因為實數的數量是無限的。為了適應指定的位數,許多實數必須四舍五入。posit的優勢在于,這種方法表示數字的精度是沿著數軸分布的。在數軸中間,1和-1周圍,posit表示的精度比浮點的高。在數軸兩翼會逐漸出現較大的負數和正數,posit精度比浮點下降得更平穩。
古斯塔夫森說:“這與數字在計算中的自然分布相吻合。動態范圍是合適的,在需要更高精度時,它的精度可以滿足需求。浮點運算中有很多從來沒有用過的位串,這是一種浪費。”
posit之所以能實現1和-1周圍精度的提高,是因為該表示方法有一個額外組成部分。浮點數由3個部分組成:一個符號位(0為正,1為負),幾個“尾數”(小數)位表示二進制小數點后面的數,其余的位用來定義指數(2exp)。
posit保留了浮點數的所有組成部分,但添加了一個額外的“regime”部分,即指數的指數。regime的優點在于它的位長度可以變化。對于較小的數字,它可以只需要2位,為尾數留下更高的精度。這樣posit可以在1和-1周圍的“甜蜜點”位置實現更高的精度。
深度神經網絡通常使用被稱為權重的歸一化參數,因此它們是從posit獲益的完美候選者。許多神經網絡計算都由乘積累加運算組成。每次執行這種計算,每個求和都必須再次截斷,導致精度損失。采用posit,一個名為quire的專用寄存器能夠有效地執行累加步驟,減少精度損失。但目前的硬件應用的是浮點,而且到目前為止,在軟件中使用posit帶來的計算收益在很大程度上被格式轉換的損耗掩蓋了。

使用他們用現場可編程門陣列(FPGA)合成的新硬件,康普頓斯團隊對32位浮點和32位posit的計算進行并列比較。
該團隊還將結果與更精確但計算成本較高的64位浮點格式的結果進行比較,對結果的精度進行評估。對于矩陣乘法(神經網絡訓練中固有的一連串乘積累加)的精度,posit比浮點運算驚人地提高了4個數量級。
該團隊還發現,提高精度并沒有以計算時間為代價,只是芯片使用面積和功耗略有增加。
盡管提高數字精度是不可否認的,但確切地說,它對訓練GPT-3等大型AI有怎樣的影響還有待觀察。
馬拉森說:“posit可能會提高訓練速度,因為在訓練的過程中不會丟失太多信息。但這些事我們還不知道。有人已經在軟件中試過了,現在也要在我們的硬件中試一下。”
其他團隊正在研究實現自己的硬件,促進posit的使用。“這正是我所希望的,它被瘋狂地接受了。”古斯塔夫森說,“posit數字格式爆火,正在使用posit的有幾十個團隊,公司和大學的團隊都有。”
審核編輯:劉清
-
處理器
+關注
關注
68文章
19775瀏覽量
233222 -
人工智能
+關注
關注
1804文章
48559瀏覽量
245754 -
深度神經網絡
+關注
關注
0文章
62瀏覽量
4665 -
OpenAI
+關注
關注
9文章
1200瀏覽量
8563
原文標題:新的數字表示方法將改進AI數學運算
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Deepseek海思SD3403邊緣計算AI產品系統
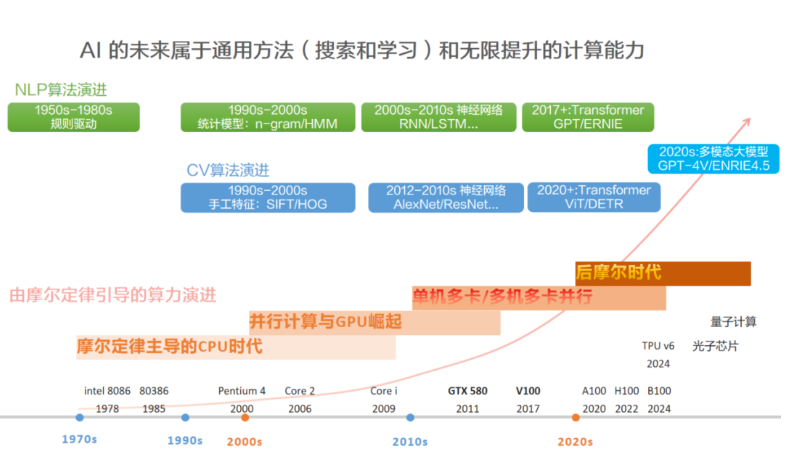
AI演進的核心哲學:使用通用方法,然后Scale Up!
(專家著作,建議收藏)電機的數學研究方法
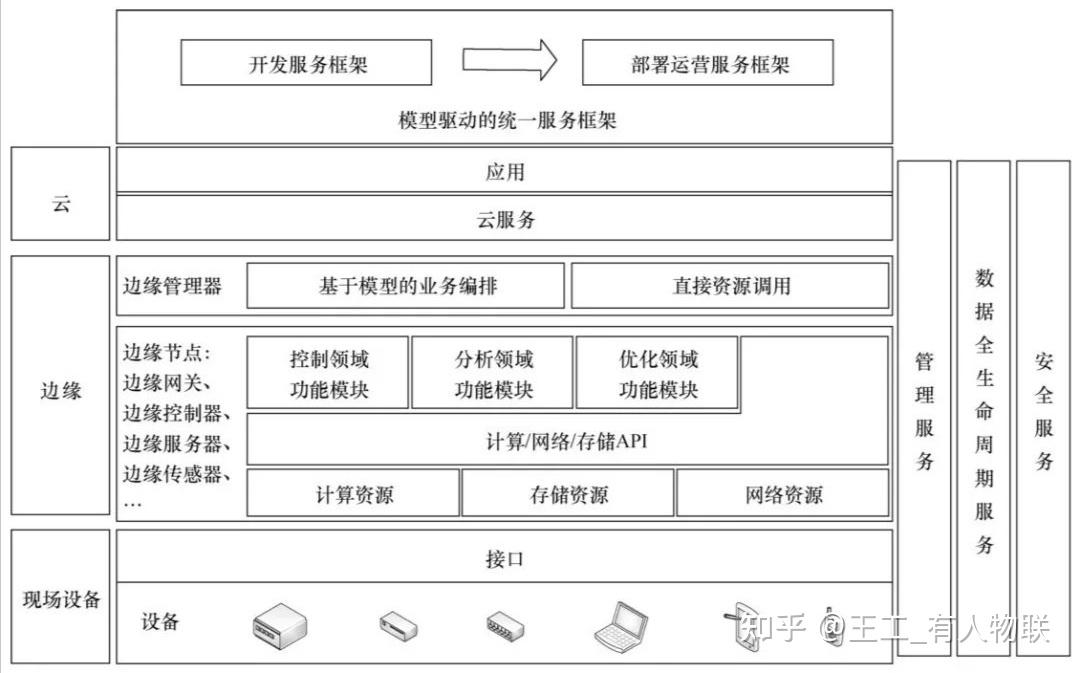
什么是邊緣計算網關?深度解析邊緣計算網關的核心技術與應用場景
Banana Pi 發布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發
貼片電感的感值代碼與讀取方法

數字萬用表的使用方法詳細圖解
AI賦能邊緣網關:開啟智能時代的新藍海
智慧交通AI監控視頻分析應用方案






 工商網監
工商網監

評論