
") 大模型參數(shù)達(dá)百萬億級別,AI商業(yè)化進(jìn)程加速!
大模型參數(shù)達(dá)百萬億級別,AI商業(yè)化進(jìn)程加速!
電子發(fā)燒友網(wǎng)報(bào)道(文/李彎彎)大模型,又稱為預(yù)訓(xùn)練模型、基礎(chǔ)模型等,大模型通常是在大規(guī)模無標(biāo)注數(shù)據(jù)上進(jìn)行訓(xùn)練,學(xué)習(xí)出一種特征和規(guī)則。近期火爆的ChatGPT,便是基于GPT大模型的一個自然語言處理工具。
從參數(shù)規(guī)模上看,AI大模型先后經(jīng)歷了預(yù)訓(xùn)練模型、大規(guī)模預(yù)訓(xùn)練模型、超大規(guī)模預(yù)訓(xùn)練模型三個階段,參數(shù)量實(shí)現(xiàn)了從億級到百萬億級的突破。從模態(tài)支持上看,AI大模型從支持圖片、圖像、文本、語音單一模態(tài)下的單一任務(wù),逐漸發(fā)展為支持多種模態(tài)下的多種任務(wù)。
AI大模型的發(fā)展歷程
AI大模型的發(fā)展,還要從2017年Vaswani等提出Transformer架構(gòu)說起,Transformer架構(gòu)的提出奠定了當(dāng)前大模型領(lǐng)域主流的算法架構(gòu)基礎(chǔ)。
2018年,谷歌提出了大規(guī)模預(yù)訓(xùn)練語言模型BERT,該模型是基于Transformer的雙向深層預(yù)訓(xùn)練模型,其參數(shù)首次超過3億規(guī)模;同年,OpenAI提出了生成式預(yù)訓(xùn)練Transformer模型GPT,大大地推動了自然語言處理領(lǐng)域的發(fā)展。此后,基于BERT的改進(jìn)模型、ELNet、RoBERTa、T5等大量新式預(yù)訓(xùn)練語言模型不斷涌現(xiàn),預(yù)訓(xùn)練技術(shù)在自然語言處理領(lǐng)域蓬勃發(fā)展。
2019年,OpenAI繼續(xù)推出15億參數(shù)的GPT-2,能夠生成連貫的文本段落,做到初步的閱讀理解、機(jī)器翻譯等。緊接著,英偉達(dá)推出了83億參數(shù)的Megatron-LM,谷歌推出了110億參數(shù)的T5,微軟推出了170億參數(shù)的圖靈Turing-NLG。
2020年,OpenAI推出了超大規(guī)模語言訓(xùn)練模型GPT-3,參數(shù)達(dá)到1750億,在兩年左右的時間實(shí)現(xiàn)了模型規(guī)模從億級到上千億級的突破,并能夠?qū)崿F(xiàn)作詩、聊天、生成代碼等功能。此后,微軟和英偉達(dá)在2020年10月聯(lián)手發(fā)布了5300億參數(shù)的MegatronTuring自然語言生成模型(MT-NLG)。
2021年1月,谷歌推出的Switch Transformer模型以高達(dá)1.6萬億的參數(shù)量成為史上首個萬億級語言模型;到2022年一大批大模型涌現(xiàn),比如Stability AI發(fā)布的文字到圖像的創(chuàng)新模型Diffusion,以及OpenAI推出的ChatGPT。
在國內(nèi),大模型研究發(fā)展迅速。2021年,商湯發(fā)布了書生(INTERN)大模型,擁有100億的參數(shù)量;2021年4月,華為云聯(lián)合循環(huán)智能發(fā)布盤古NLP超大規(guī)模預(yù)訓(xùn)練語言模型,參數(shù)規(guī)模達(dá)1000億,聯(lián)合北京大學(xué)發(fā)布盤古α超大規(guī)模預(yù)訓(xùn)練模型,參數(shù)規(guī)模達(dá)2000億。
同年4月,阿里達(dá)摩院發(fā)布270億參數(shù)的中文預(yù)訓(xùn)練語言模型PLUG,聯(lián)合清華大學(xué)發(fā)布參數(shù)規(guī)模達(dá)到 1000億的中文多模態(tài)預(yù)訓(xùn)練模型M6;7月,百度推出ERNIE 3.0知識增強(qiáng)大模型,參數(shù)規(guī)模達(dá)到百億;10月,浪潮信息發(fā)布約2500億的超大規(guī)模預(yù)訓(xùn)練模型“源 1.0”;12月,百度推出ERNIE 3.0 Titan模型,參數(shù)規(guī)模達(dá)2600億。
2022 年,基于清華大學(xué)、阿里達(dá)摩院等研究成果以及超算基礎(chǔ)實(shí)現(xiàn)的“腦級人工智能模型”八卦爐(BAGUALU)完成建立,其模型參數(shù)規(guī)模突破了174萬億個。可以看到,目前大模型參數(shù)規(guī)模最高已經(jīng)達(dá)到百萬億級別。
大模型研究的重要意義
當(dāng)前人工智能正處在可以用到好用的落地階段,但目前仍處于商業(yè)落地早期,主要面臨著場景需求碎片化、人力研發(fā)和應(yīng)用計(jì)算成本高、長尾場景數(shù)據(jù)較少導(dǎo)致模型訓(xùn)練精度不夠、模型算法從實(shí)驗(yàn)室場景到真實(shí)場景效果差距大等行業(yè)痛點(diǎn)。
大模型具備大規(guī)模和預(yù)訓(xùn)練的特點(diǎn),一方面有良好的通用性、泛化性,能夠解決傳統(tǒng)AI應(yīng)用中門檻高、部署難的問題,另一方面可以作為技術(shù)底座,支撐智能化產(chǎn)品及應(yīng)用落地。
過去很多年,雖然各大科技公司不斷推出較大規(guī)模的模型,然而直到去年生成式AI逐漸走向商業(yè)化,以及去年底今年初OpenAI推出的ChatGPT爆火,AI大模型才真正迎來發(fā)展的轉(zhuǎn)折點(diǎn)。美國國家工程院外籍院士、北京智源人工智能研究院理事張宏江此前表示,ChatGPT和AIGC,技術(shù)爆火背后,代表著人工智能(AI)大模型進(jìn)入一個新的技術(shù)范式,也是第三波AI浪潮經(jīng)過十幾年發(fā)展之后一個非常重要的拐點(diǎn)。
張宏江認(rèn)為,它其實(shí)代表著從以前各自研發(fā)專用小模型到研發(fā)超大規(guī)模通用智能模型的一個范式轉(zhuǎn)變。這個轉(zhuǎn)變的重要意義在于:通過這種比較先進(jìn)的算法架構(gòu),盡可能多的數(shù)據(jù),匯集大量算力,集約化的訓(xùn)練達(dá)模式,從而供大量用戶使用。
大模型的發(fā)展很可能會改變信息產(chǎn)業(yè)的格局,改變以前作坊式AI開發(fā)模式,把AI應(yīng)用帶入基于互聯(lián)網(wǎng)、云計(jì)算的大規(guī)模智能云階段。
小結(jié)
雖然過去十幾年人工智能技術(shù)發(fā)展迅速,然而在近幾年卻遇到了一些技術(shù)瓶頸和商業(yè)化難題。而大模型的發(fā)展和普及,尤其是通過大模型+微調(diào)的新技術(shù)開發(fā)范式,人工智能將能夠更好的在各種場景中實(shí)現(xiàn)應(yīng)用,當(dāng)然大模型的訓(xùn)練和推理對算力等也提出了很高的要求,因此大模型的研究最終能夠如何推進(jìn)人工智能產(chǎn)業(yè)的發(fā)展,還需要產(chǎn)業(yè)鏈各環(huán)節(jié)的共同努力。
從參數(shù)規(guī)模上看,AI大模型先后經(jīng)歷了預(yù)訓(xùn)練模型、大規(guī)模預(yù)訓(xùn)練模型、超大規(guī)模預(yù)訓(xùn)練模型三個階段,參數(shù)量實(shí)現(xiàn)了從億級到百萬億級的突破。從模態(tài)支持上看,AI大模型從支持圖片、圖像、文本、語音單一模態(tài)下的單一任務(wù),逐漸發(fā)展為支持多種模態(tài)下的多種任務(wù)。
AI大模型的發(fā)展歷程
AI大模型的發(fā)展,還要從2017年Vaswani等提出Transformer架構(gòu)說起,Transformer架構(gòu)的提出奠定了當(dāng)前大模型領(lǐng)域主流的算法架構(gòu)基礎(chǔ)。
2018年,谷歌提出了大規(guī)模預(yù)訓(xùn)練語言模型BERT,該模型是基于Transformer的雙向深層預(yù)訓(xùn)練模型,其參數(shù)首次超過3億規(guī)模;同年,OpenAI提出了生成式預(yù)訓(xùn)練Transformer模型GPT,大大地推動了自然語言處理領(lǐng)域的發(fā)展。此后,基于BERT的改進(jìn)模型、ELNet、RoBERTa、T5等大量新式預(yù)訓(xùn)練語言模型不斷涌現(xiàn),預(yù)訓(xùn)練技術(shù)在自然語言處理領(lǐng)域蓬勃發(fā)展。
2019年,OpenAI繼續(xù)推出15億參數(shù)的GPT-2,能夠生成連貫的文本段落,做到初步的閱讀理解、機(jī)器翻譯等。緊接著,英偉達(dá)推出了83億參數(shù)的Megatron-LM,谷歌推出了110億參數(shù)的T5,微軟推出了170億參數(shù)的圖靈Turing-NLG。
2020年,OpenAI推出了超大規(guī)模語言訓(xùn)練模型GPT-3,參數(shù)達(dá)到1750億,在兩年左右的時間實(shí)現(xiàn)了模型規(guī)模從億級到上千億級的突破,并能夠?qū)崿F(xiàn)作詩、聊天、生成代碼等功能。此后,微軟和英偉達(dá)在2020年10月聯(lián)手發(fā)布了5300億參數(shù)的MegatronTuring自然語言生成模型(MT-NLG)。
2021年1月,谷歌推出的Switch Transformer模型以高達(dá)1.6萬億的參數(shù)量成為史上首個萬億級語言模型;到2022年一大批大模型涌現(xiàn),比如Stability AI發(fā)布的文字到圖像的創(chuàng)新模型Diffusion,以及OpenAI推出的ChatGPT。
在國內(nèi),大模型研究發(fā)展迅速。2021年,商湯發(fā)布了書生(INTERN)大模型,擁有100億的參數(shù)量;2021年4月,華為云聯(lián)合循環(huán)智能發(fā)布盤古NLP超大規(guī)模預(yù)訓(xùn)練語言模型,參數(shù)規(guī)模達(dá)1000億,聯(lián)合北京大學(xué)發(fā)布盤古α超大規(guī)模預(yù)訓(xùn)練模型,參數(shù)規(guī)模達(dá)2000億。
同年4月,阿里達(dá)摩院發(fā)布270億參數(shù)的中文預(yù)訓(xùn)練語言模型PLUG,聯(lián)合清華大學(xué)發(fā)布參數(shù)規(guī)模達(dá)到 1000億的中文多模態(tài)預(yù)訓(xùn)練模型M6;7月,百度推出ERNIE 3.0知識增強(qiáng)大模型,參數(shù)規(guī)模達(dá)到百億;10月,浪潮信息發(fā)布約2500億的超大規(guī)模預(yù)訓(xùn)練模型“源 1.0”;12月,百度推出ERNIE 3.0 Titan模型,參數(shù)規(guī)模達(dá)2600億。
2022 年,基于清華大學(xué)、阿里達(dá)摩院等研究成果以及超算基礎(chǔ)實(shí)現(xiàn)的“腦級人工智能模型”八卦爐(BAGUALU)完成建立,其模型參數(shù)規(guī)模突破了174萬億個。可以看到,目前大模型參數(shù)規(guī)模最高已經(jīng)達(dá)到百萬億級別。
大模型研究的重要意義
當(dāng)前人工智能正處在可以用到好用的落地階段,但目前仍處于商業(yè)落地早期,主要面臨著場景需求碎片化、人力研發(fā)和應(yīng)用計(jì)算成本高、長尾場景數(shù)據(jù)較少導(dǎo)致模型訓(xùn)練精度不夠、模型算法從實(shí)驗(yàn)室場景到真實(shí)場景效果差距大等行業(yè)痛點(diǎn)。
大模型具備大規(guī)模和預(yù)訓(xùn)練的特點(diǎn),一方面有良好的通用性、泛化性,能夠解決傳統(tǒng)AI應(yīng)用中門檻高、部署難的問題,另一方面可以作為技術(shù)底座,支撐智能化產(chǎn)品及應(yīng)用落地。
過去很多年,雖然各大科技公司不斷推出較大規(guī)模的模型,然而直到去年生成式AI逐漸走向商業(yè)化,以及去年底今年初OpenAI推出的ChatGPT爆火,AI大模型才真正迎來發(fā)展的轉(zhuǎn)折點(diǎn)。美國國家工程院外籍院士、北京智源人工智能研究院理事張宏江此前表示,ChatGPT和AIGC,技術(shù)爆火背后,代表著人工智能(AI)大模型進(jìn)入一個新的技術(shù)范式,也是第三波AI浪潮經(jīng)過十幾年發(fā)展之后一個非常重要的拐點(diǎn)。
張宏江認(rèn)為,它其實(shí)代表著從以前各自研發(fā)專用小模型到研發(fā)超大規(guī)模通用智能模型的一個范式轉(zhuǎn)變。這個轉(zhuǎn)變的重要意義在于:通過這種比較先進(jìn)的算法架構(gòu),盡可能多的數(shù)據(jù),匯集大量算力,集約化的訓(xùn)練達(dá)模式,從而供大量用戶使用。
大模型的發(fā)展很可能會改變信息產(chǎn)業(yè)的格局,改變以前作坊式AI開發(fā)模式,把AI應(yīng)用帶入基于互聯(lián)網(wǎng)、云計(jì)算的大規(guī)模智能云階段。
小結(jié)
雖然過去十幾年人工智能技術(shù)發(fā)展迅速,然而在近幾年卻遇到了一些技術(shù)瓶頸和商業(yè)化難題。而大模型的發(fā)展和普及,尤其是通過大模型+微調(diào)的新技術(shù)開發(fā)范式,人工智能將能夠更好的在各種場景中實(shí)現(xiàn)應(yīng)用,當(dāng)然大模型的訓(xùn)練和推理對算力等也提出了很高的要求,因此大模型的研究最終能夠如何推進(jìn)人工智能產(chǎn)業(yè)的發(fā)展,還需要產(chǎn)業(yè)鏈各環(huán)節(jié)的共同努力。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報(bào)投訴
-
AI
+關(guān)注
關(guān)注
87文章
33701瀏覽量
274438 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1585瀏覽量
8700
發(fā)布評論請先 登錄
相關(guān)推薦
熱點(diǎn)推薦
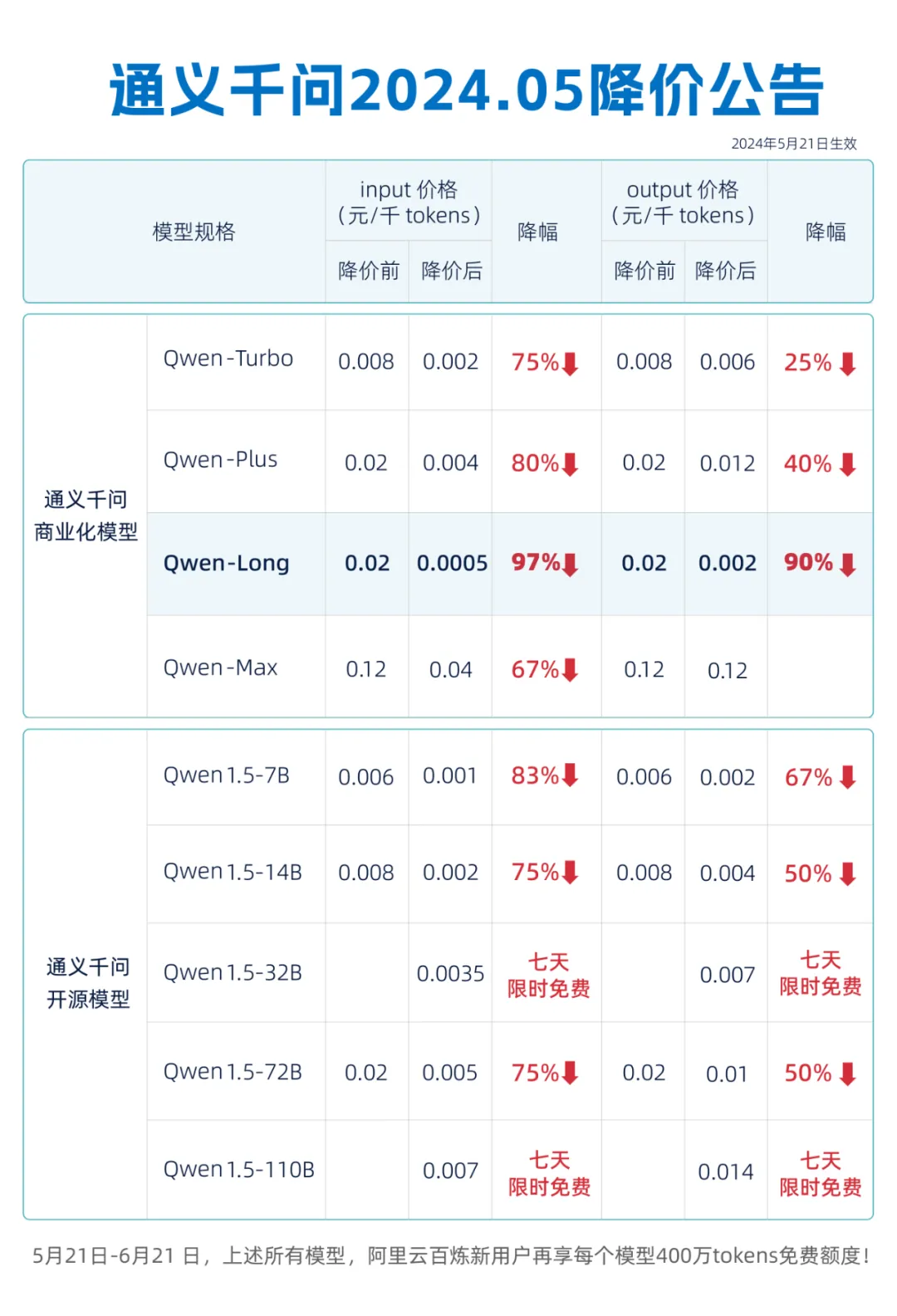
免費(fèi)時代到來!價格戰(zhàn)帶領(lǐng)AI大模型走出商業(yè)化困局?
試用。 ? 大模型進(jìn)入免費(fèi)時代 ? 5月21日,阿里云宣布通義千問4款商業(yè)化模型和5款開源模型大降價,其中GPT-4級別的主力
Gupshup加速企業(yè)AI應(yīng)用進(jìn)程
Gupshup-Gupshup推出預(yù)構(gòu)建、行業(yè)訓(xùn)練有素的多模態(tài)AI代理,加速企業(yè)AI應(yīng)用進(jìn)程 印度尼西亞雅加達(dá)2025年2月14日?/美通社/ -- 全球領(lǐng)先的對話式
DeepSeek大模型受行業(yè)熱捧,加速AI應(yīng)用迭代
趨勢反映出DeepSeek大模型在AI領(lǐng)域的強(qiáng)大影響力。通過接入DeepSeek,這些機(jī)構(gòu)能夠獲取更先進(jìn)的AI技術(shù)支持,從而提升其產(chǎn)品的智能化水平和競爭力。 機(jī)構(gòu)表示,隨著
DeepSeek大模型攜手廣和通,加速AI普惠化進(jìn)程
近期,國產(chǎn)大模型DeepSeek憑借其開放性、低訓(xùn)練成本以及端側(cè)部署的顯著優(yōu)勢,迅速嶄露頭角,成為增速最為迅猛的AI應(yīng)用之一。這一突破性進(jìn)展,為AI技術(shù)的普惠化應(yīng)用開辟了新路徑。 值得
政策與技術(shù)并行,共推Robotaxi商業(yè)化進(jìn)程?
高級別自動駕駛的發(fā)展離不開政策與技術(shù)的雙重驅(qū)動。政府對“車路云一體化”建設(shè)的支持推動了基礎(chǔ)設(shè)施的完善,同時高級別自動駕駛的監(jiān)管體系逐步完善,為自動駕駛商業(yè)化

AI大模型與傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
多個神經(jīng)網(wǎng)絡(luò)層組成,每個層都包含大量的神經(jīng)元和權(quán)重參數(shù)。 傳統(tǒng)機(jī)器學(xué)習(xí) :模型規(guī)模相對較小,參數(shù)數(shù)量通常只有幾千到幾百萬個,模型結(jié)構(gòu)相對簡單
英偉達(dá)Blackwell可支持10萬億參數(shù)模型AI訓(xùn)練,實(shí)時大語言模型推理
、NVLink交換機(jī)、Spectrum以太網(wǎng)交換機(jī)和Quantum InfiniBand交換機(jī)。 ? 英偉達(dá)稱,Blackwell擁有6項(xiàng)革命性技術(shù),可支持多達(dá)10萬億參數(shù)的模型進(jìn)行
英偉達(dá)震撼發(fā)布:全新AI模型參數(shù)規(guī)模躍升至80億量級
8月23日,英偉達(dá)宣布,其全新AI模型面世,該模型參數(shù)規(guī)模高達(dá)80億,具有精度高、計(jì)算效益大等優(yōu)勢,適用于GPU
小鵬匯天獲1.5億美元B1輪融資,加速飛行汽車商業(yè)化進(jìn)程
小鵬匯天近日宣布成功完成1.5億美元的B1輪融資,并同步啟動B2輪融資計(jì)劃,標(biāo)志著公司在飛行汽車領(lǐng)域的研發(fā)與商業(yè)化進(jìn)程邁入新階段。此次融資不僅為小鵬匯天提供了堅(jiān)實(shí)的資金保障,更將助力其加速推進(jìn)飛行汽車的研發(fā)、規(guī)模量產(chǎn)及市場布局。
蘿卜快跑爆火的背后,美格智能如何助力無人車商業(yè)化?
無人車商業(yè)化進(jìn)程已經(jīng)邁入加速賽,美格智能將繼續(xù)堅(jiān)持研發(fā)投入,與產(chǎn)業(yè)伙伴共同構(gòu)建面向智能汽車產(chǎn)業(yè)的新質(zhì)生產(chǎn)力,助力無人車商業(yè)化加速發(fā)展!
蘿卜快跑爆火的背后,美格智能如何助力無人車商業(yè)化?
無人車商業(yè)化進(jìn)程已經(jīng)邁入加速賽,美格智能將繼續(xù)堅(jiān)持研發(fā)投入,與產(chǎn)業(yè)伙伴共同構(gòu)建面向智能汽車產(chǎn)業(yè)的新質(zhì)生產(chǎn)力,助力無人車商業(yè)化加速發(fā)展!

ai大模型和ai框架的關(guān)系是什么
AI大模型和AI框架是人工智能領(lǐng)域中兩個重要的概念,它們之間的關(guān)系密切且復(fù)雜。 AI大模型的定義和特點(diǎn)
如祺出行香港成功上市,加速自動駕駛商業(yè)化進(jìn)程
近日,廣汽集團(tuán)旗下智慧出行平臺如祺出行在香港聯(lián)合交易所(聯(lián)交所)隆重舉行上市儀式,標(biāo)志著其正式踏入資本市場的新征程,股票代碼定為09680.HK。這一里程碑事件不僅彰顯了如祺出行在出行服務(wù)領(lǐng)域的深厚積累與強(qiáng)勁實(shí)力,更為其未來在自動駕駛技術(shù)商業(yè)化道路上的加速奔跑注入了強(qiáng)大動
大模型應(yīng)用商業(yè)化落地關(guān)鍵:給企業(yè)帶來真實(shí)的業(yè)務(wù)價值
過去的AICon全球人工智能開發(fā)與應(yīng)用大會上,InfoQ采訪了在大模型應(yīng)用領(lǐng)域的領(lǐng)跑企業(yè)數(shù)勢科技創(chuàng)始人兼CEO黎科峰博士,交流大模型商業(yè)化落地的可行性路徑,為行業(yè)提供啟發(fā)。 大模型在T

進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級芯片
計(jì)算工作負(fù)載、釋放百億億次計(jì)算能力和萬億參數(shù)人工智能模型的全部潛力提供關(guān)鍵基礎(chǔ)。
NVLink釋放數(shù)萬億參數(shù)
發(fā)表于 05-13 17:16





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論