") 工業(yè)機(jī)器人抓取時(shí)如何去定位呢?
工業(yè)機(jī)器人抓取時(shí)如何去定位呢?
從機(jī)器視覺的角度,由簡入繁從相機(jī)標(biāo)定,平面物體檢測、有紋理物體、無紋理物體、深度學(xué)習(xí)、與任務(wù)/運(yùn)動(dòng)規(guī)劃結(jié)合等6個(gè)方面深度解析文章的標(biāo)題。
首先,我們要了解,機(jī)器人領(lǐng)域的視覺(Machine Vision)跟計(jì)算機(jī)領(lǐng)域(Computer Vision)的視覺有一些不同:機(jī)器視覺的目的是給機(jī)器人提供操作物體的信息。所以,機(jī)器視覺的研究大概有這幾塊:
1.物體識別(Object Recognition):在圖像中檢測到物體類型等,這跟 CV 的研究有很大一部分交叉;
2.位姿估計(jì)(Pose Estimation):計(jì)算出物體在攝像機(jī)坐標(biāo)系下的位置和姿態(tài),對于機(jī)器人而言,需要抓取東西,不僅要知道這是什么,也需要知道它具體在哪里;
3.相機(jī)標(biāo)定(Camera Calibration):因?yàn)樯厦孀龅闹皇怯?jì)算了物體在相機(jī)坐標(biāo)系下的坐標(biāo),我們還需要確定相機(jī)跟機(jī)器人的相對位置和姿態(tài),這樣才可以將物體位姿轉(zhuǎn)換到機(jī)器人位姿。
當(dāng)然,我這里主要是在物體抓取領(lǐng)域的機(jī)器視覺;SLAM 等其他領(lǐng)域的就先不講了。
由于視覺是機(jī)器人感知的一塊很重要內(nèi)容,所以研究也非常多了,我就我了解的一些,按照由簡入繁的順序介紹吧。
一. 相機(jī)標(biāo)定
這其實(shí)屬于比較成熟的領(lǐng)域。由于我們所有物體識別都只是計(jì)算物體在相機(jī)坐標(biāo)系下的位姿,但是,機(jī)器人操作物體需要知道物體在機(jī)器人坐標(biāo)系下的位姿。所以,我們先需要對相機(jī)的位姿進(jìn)行標(biāo)定。
內(nèi)參標(biāo)定就不說了,參照張正友的論文,或者各種標(biāo)定工具箱;
外參標(biāo)定的話,根據(jù)相機(jī)安裝位置,有兩種方式:
Eye to Hand:相機(jī)與機(jī)器人極坐標(biāo)系固連,不隨機(jī)械臂運(yùn)動(dòng)而運(yùn)動(dòng)
Eye in Hand:相機(jī)固連在機(jī)械臂上,隨機(jī)械臂運(yùn)動(dòng)而運(yùn)動(dòng)
兩種方式的求解思路都類似,首先是眼在手外(Eye to Hand)
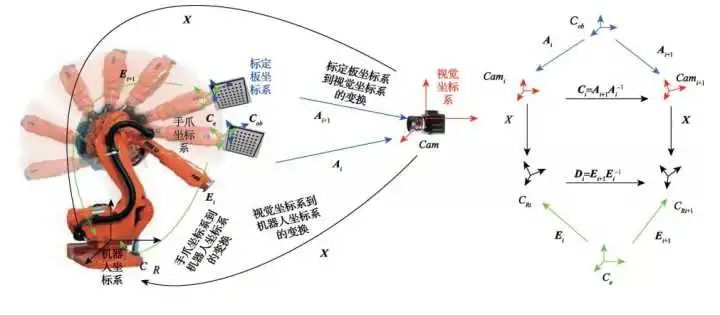
只需在機(jī)械臂末端固定一個(gè)棋盤格,在相機(jī)視野內(nèi)運(yùn)動(dòng)幾個(gè)姿態(tài)。由于相機(jī)可以計(jì)算出棋盤格相對于相機(jī)坐標(biāo)系的位姿A_i 、機(jī)器人運(yùn)動(dòng)學(xué)正解可以計(jì)算出機(jī)器人底座到末端抓手之間的位姿變化E_i 、而末端爪手與棋盤格的位姿相對固定不變。
這樣,我們就可以得到一個(gè)坐標(biāo)系環(huán) CX=XD
這種結(jié)構(gòu)的求解有很多方法,
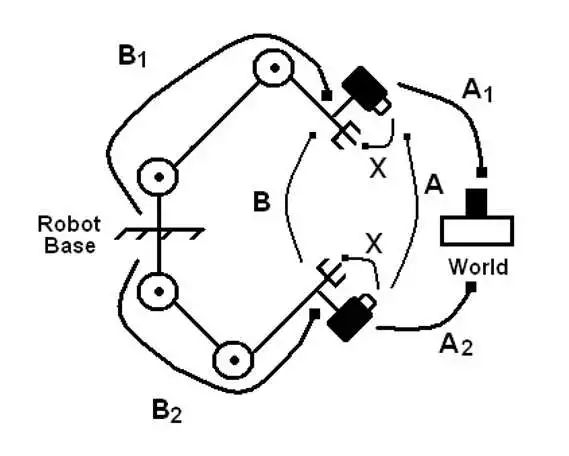
而對于眼在手上(Eye in Hand)的情況,也類似,在地上隨便放一個(gè)棋盤格(與機(jī)器人基座固連),然后讓機(jī)械臂帶著相機(jī)走幾個(gè)位姿,然后也可以形成一個(gè)AX=XB 的坐標(biāo)環(huán)。
二. 平面物體檢測
這是目前工業(yè)流水線上最常見的場景。目前來看,這一領(lǐng)域?qū)σ曈X的要求是:快速、精確、穩(wěn)定。所以,一般是采用最簡單的邊緣提取+邊緣匹配/形狀匹配的方法;而且,為了提高穩(wěn)定性、一般會通過主要打光源、采用反差大的背景等手段,減少系統(tǒng)變量。
目前,很多智能相機(jī)(如 cognex)都直接內(nèi)嵌了這些功能;而且,物體一般都是放置在一個(gè)平面上,相機(jī)只需計(jì)算物體的(x,y,θ)T 三自由度位姿即可。
另外,這種應(yīng)用場景一般都是用于處理一種特定工件,相當(dāng)于只有位姿估計(jì),而沒有物體識別。
當(dāng)然,工業(yè)上追求穩(wěn)定性無可厚非,但是隨著生產(chǎn)自動(dòng)化的要求越來越高,以及服務(wù)類機(jī)器人的興起。對更復(fù)雜物體的完整位姿(x,y,z,rx,ry,rz)T 估計(jì)也就成了機(jī)器視覺的研究熱點(diǎn)。
三.有紋理的物體
機(jī)器人視覺領(lǐng)域是最早開始研究有紋理的物體的,如飲料瓶、零食盒等表面帶有豐富紋理的都屬于這一類。
當(dāng)然,這些物體也還是可以用類似邊緣提取+模板匹配的方法。但是,實(shí)際機(jī)器人操作過程中,環(huán)境會更加復(fù)雜:光照條件不確定(光照)、物體距離相機(jī)距離不確定(尺度)、相機(jī)看物體的角度不確定(旋轉(zhuǎn)、仿射)、甚至是被其他物體遮擋(遮擋)。
幸好有一位叫做 Lowe 的大神,提出了一個(gè)叫做 SIFT (Scale-invariant feature transform)的超強(qiáng)局部特征點(diǎn):
Lowe, David G. "Distinctive image features from scale-invariant keypoints."International journal of computer vision 60.2 (2004): 91-110.
具體原理可以看上面這篇被引用 4萬+ 的論文或各種博客,簡單地說,這個(gè)方法提取的特征點(diǎn)只跟物體表面的某部分紋理有關(guān),與光照變化、尺度變化、仿射變換、整個(gè)物體無關(guān)。
因此,利用 SIFT 特征點(diǎn),可以直接在相機(jī)圖像中尋找到與數(shù)據(jù)庫中相同的特征點(diǎn),這樣,就可以確定相機(jī)中的物體是什么東西(物體識別)。
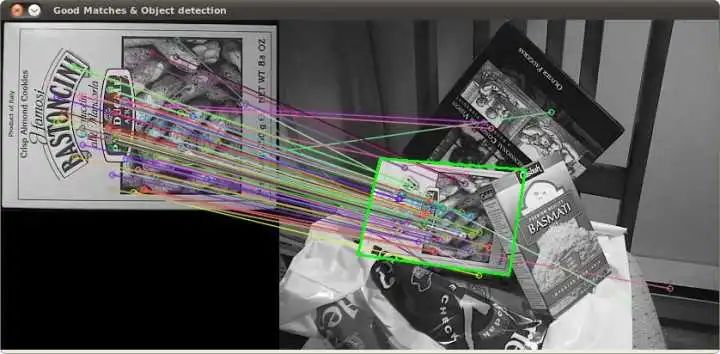
對于不會變形的物體,特征點(diǎn)在物體坐標(biāo)系下的位置是固定的。所以,我們在獲取若干點(diǎn)對之后,就可以直接求解出相機(jī)中物體與數(shù)據(jù)庫中物體之間的單應(yīng)性矩陣。
如果我們用深度相機(jī)(如Kinect)或者雙目視覺方法,確定出每個(gè)特征點(diǎn)的 3D 位置。那么,直接求解這個(gè) PnP 問題,就可以計(jì)算出物體在當(dāng)前相機(jī)坐標(biāo)系下的位姿。
當(dāng)然,實(shí)際操作過程中還是有很多細(xì)節(jié)工作才可以讓它真正可用的,如:先利用點(diǎn)云分割和歐氏距離去除背景的影響、選用特征比較穩(wěn)定的物體(有時(shí)候 SIFT 也會變化)、利用貝葉斯方法加速匹配等。
而且,除了 SIFT 之外,后來又出了一大堆類似的特征點(diǎn),如 SURF、ORB 等。
四. 無紋理的物體
好了,有問題的物體容易解決,那么生活中或者工業(yè)里還有很多物體是沒有紋理的:
我們最容易想到的就是:是否有一種特征點(diǎn),可以描述物體形狀,同時(shí)具有跟 SIFT 相似的不變性?
不幸的是,據(jù)我了解,目前沒有這種特征點(diǎn)。
所以,之前一大類方法還是采用基于模板匹配的辦法,但是,對匹配的特征進(jìn)行了專門選擇(不只是邊緣等簡單特征)。
這里,我介紹一個(gè)我們實(shí)驗(yàn)室之前使用和重現(xiàn)過的算法 LineMod:
Hinterstoisser, Stefan, et al. "Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes." Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011.
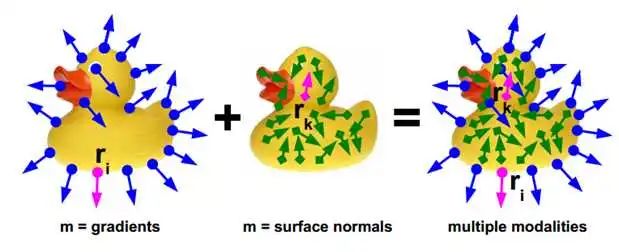
簡單而言,這篇論文同時(shí)利用了彩色圖像的圖像梯度和深度圖像的表面法向作為特征,與數(shù)據(jù)庫中的模板進(jìn)行匹配。
由于數(shù)據(jù)庫中的模板是從一個(gè)物體的多個(gè)視角拍攝后生成的,所以這樣匹配得到的物體位姿只能算是初步估計(jì),并不精確。
但是,只要有了這個(gè)初步估計(jì)的物體位姿,我們就可以直接采用 ICP 算法(Iterative closest point)匹配物體模型與 3D 點(diǎn)云,從而得到物體在相機(jī)坐標(biāo)系下的精確位姿。

當(dāng)然,這個(gè)算法在具體實(shí)施過程中還是有很多細(xì)節(jié)的:如何建立模板、顏色梯度的表示等。另外,這種方法無法應(yīng)對物體被遮擋的情況。(當(dāng)然,通過降低匹配閾值,可以應(yīng)對部分遮擋,但是會造成誤識別)。
針對部分遮擋的情況,我們實(shí)驗(yàn)室的張博士去年對 LineMod 進(jìn)行了改進(jìn),但由于論文尚未發(fā)表,所以就先不過多涉及了。
五.深度學(xué)習(xí)
由于深度學(xué)習(xí)在計(jì)算機(jī)視覺領(lǐng)域得到了非常好的效果,我們做機(jī)器人的自然也會嘗試把 DL 用到機(jī)器人的物體識別中。
首先,對于物體識別,這個(gè)就可以照搬 DL 的研究成果了,各種 CNN 拿過來用就好了。在 2016 年的『亞馬遜抓取大賽』中,很多隊(duì)伍都采用了 DL 作為物體識別算法。
然而, 在這個(gè)比賽中,雖然很多人采用 DL 進(jìn)行物體識別,但在物體位姿估計(jì)方面都還是使用比較簡單、或者傳統(tǒng)的算法。似乎并未廣泛采用 DL。如周博磊所說,一般是采用 semantic segmentation network 在彩色圖像上進(jìn)行物體分割,之后,將分割出的部分點(diǎn)云與物體 3D 模型進(jìn)行 ICP 匹配。
當(dāng)然,直接用神經(jīng)網(wǎng)絡(luò)做位姿估計(jì)的工作也是有的,如這篇:
Doumanoglou, Andreas, et al. "Recovering 6d object pose and predicting next-best-view in the crowd." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
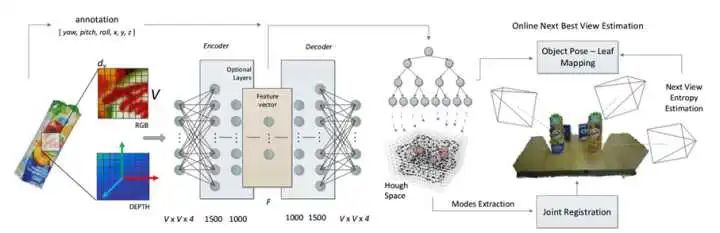
它的方法大概是這樣:對于一個(gè)物體,取很多小塊 RGB-D 數(shù)據(jù)(只關(guān)心一個(gè)patch,用局部特征可以應(yīng)對遮擋);每小塊有一個(gè)坐標(biāo)(相對于物體坐標(biāo)系);然后,首先用一個(gè)自編碼器對數(shù)據(jù)進(jìn)行降維;之后,用將降維后的特征用于訓(xùn)練Hough Forest。
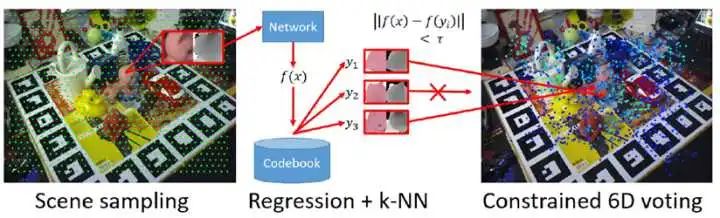
六. 與任務(wù)/運(yùn)動(dòng)規(guī)劃結(jié)合
這部分也是比較有意思的研究內(nèi)容,由于機(jī)器視覺的目的是給機(jī)器人操作物體提供信息,所以,并不限于相機(jī)中的物體識別與定位,往往需要跟機(jī)器人的其他模塊相結(jié)合。
我們讓機(jī)器人從冰箱中拿一瓶『雪碧』,但是這個(gè) 『雪碧』 被『美年達(dá)』擋住了。
我們?nèi)祟惖淖龇ㄊ沁@樣的:先把 『美年達(dá)』 移開,再去取 『雪碧』 。
所以,對于機(jī)器人來說,它需要先通過視覺確定雪碧在『美年達(dá)』后面,同時(shí),還需要確定『美年達(dá)』這個(gè)東西是可以移開的,而不是冰箱門之類固定不可拿開的物體。
當(dāng)然,將視覺跟機(jī)器人結(jié)合后,會引出其他很多好玩的新東西。由于不是我自己的研究方向,所以也就不再班門弄斧了。
審核編輯:劉清
-
機(jī)器視覺
+關(guān)注
關(guān)注
161文章
4369瀏覽量
120282 -
工業(yè)機(jī)器人
+關(guān)注
關(guān)注
91文章
3360瀏覽量
92624 -
pnp
+關(guān)注
關(guān)注
11文章
297瀏覽量
51775 -
SLAM
+關(guān)注
關(guān)注
23文章
423瀏覽量
31822
原文標(biāo)題:工業(yè)機(jī)器人抓取時(shí)如何定位
文章出處:【微信號:indRobot,微信公眾號:工業(yè)機(jī)器人】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
什么是工業(yè)機(jī)器人
工業(yè)機(jī)器人經(jīng)典好書籍——《工業(yè)機(jī)器人》
《工業(yè)機(jī)器人》,蔣剛編著的,附下載。
工業(yè)機(jī)器人應(yīng)用廣泛
【MYD-CZU3EG開發(fā)板試用申請】基于機(jī)器視覺的工業(yè)機(jī)器人抓取工作站
【瑞芯微RK1808計(jì)算棒試用申請】基于機(jī)器視覺的工業(yè)機(jī)器人抓取工作站
工業(yè)機(jī)器人與視覺實(shí)訓(xùn)平臺介紹
工業(yè)機(jī)器人與智能視覺系統(tǒng)應(yīng)用實(shí)訓(xùn)平臺介紹
ZN-1AI工業(yè)機(jī)器人與智能視覺系統(tǒng)應(yīng)用實(shí)訓(xùn)平臺介紹
機(jī)器人搬運(yùn)碼垛工作站介紹
工業(yè)機(jī)器人應(yīng)用編程考核設(shè)備分享
工業(yè)機(jī)器人視覺裝配實(shí)訓(xùn)平臺實(shí)驗(yàn)
機(jī)器人的定義是什么?工業(yè)機(jī)器人的應(yīng)用有哪些?
如何對ROS機(jī)器人的定位導(dǎo)航進(jìn)行仿真
基于視覺的機(jī)器人抓取系統(tǒng)設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論