 一文讀懂圖像分割
一文讀懂圖像分割
圖像分割(Image Segmentation)是計算機視覺領域中的一項重要基礎技術,是圖像理解中的重要一環。近日,數據科學家Derrick Mwiti在一篇文章中,就什么是圖像分割、圖像分割架構、圖像分割損失函數以及圖像分割工具和框架等問題進行了討論,讓我們一探究竟吧。
什么是圖像分割?
顧名思義,這是將一個圖像分割成多個片段的過程。在這個過程中,圖像中的每個像素都與一個對象類型相關聯。圖像分割主要有兩種類型:語義分割和實例分割。
在語義分割中,同一類型的所有對象都使用一個類標簽進行標記,而在實例分割中,相似的對象使用各自獨立的標簽。 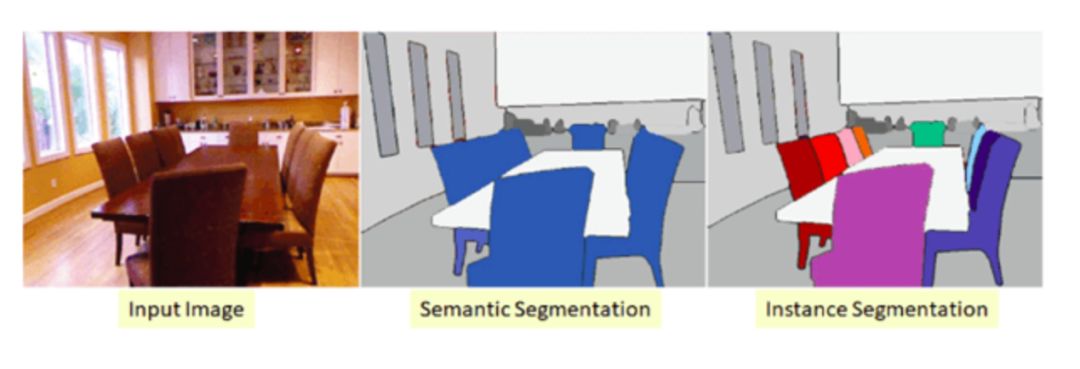 ?
?
圖像分割的體系結構
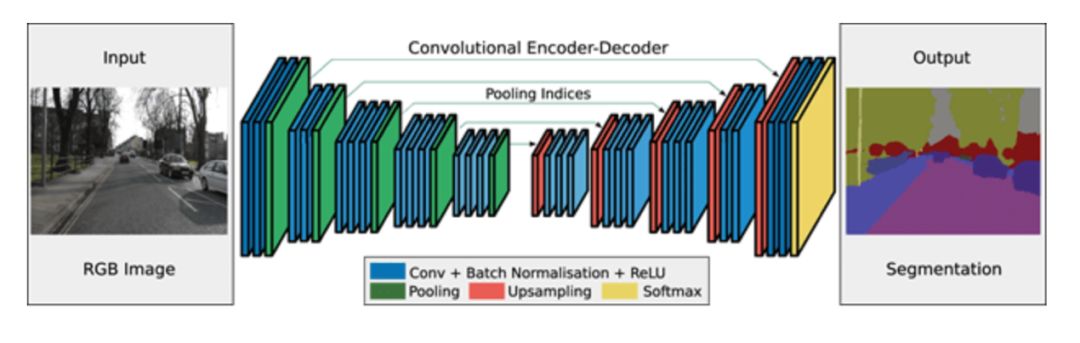
圖像分割的基本結構包括編碼器和解碼器。
 ?
?
編碼器通過過濾器從圖像中提取特征。解碼器負責生成最終的輸出,通常是一個包含對象輪廓的分割掩碼。大多數體系結構都有這種結構或其變體,看幾個例子:
U-Net
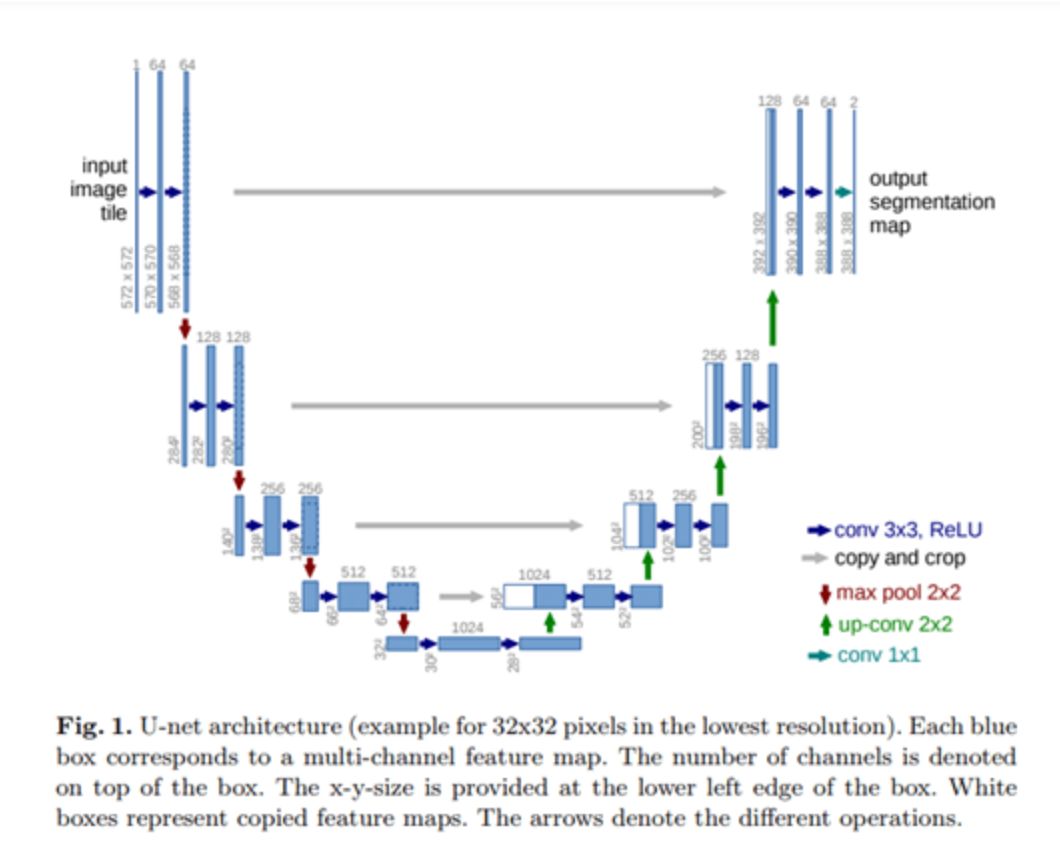
U-Net是最初用于分割生物醫學圖像的卷積神經網絡。可視化時,其架構看起來像字母U,因此名稱為U-Net。
它的體系結構由兩部分組成,左邊部分是收縮路徑,右邊部分是擴展路徑。收縮路徑的目的是捕獲上下文,而擴展路徑的作用是幫助精確定位。
 ?
?
U-Net由右邊的擴展路徑和左邊的收縮路徑組成。收縮路徑由兩個3×3的卷積組成,卷積之后是一個整流的線性單元和一個用于降采樣的兩乘二最大池計算。
FastFCN —Fast Fully-connected network
在這種結構中,聯合金字塔上采樣(JPU)模塊被用來代替擴展卷積,因為它們消耗大量的內存和時間。它的核心是一個全連接網絡,同時使用JPU進行上采樣。JPU將低分辨率特征圖提升為高分辨率特征圖。 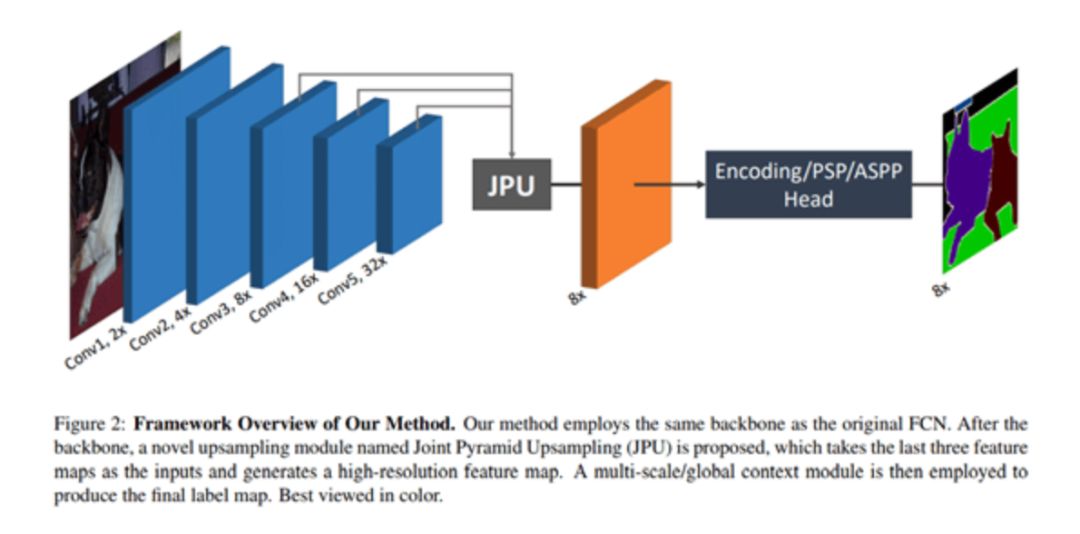 ?
?
Gated-SCNN
該架構由雙流CNN架構組成。在此模型中,一個單獨的分支用于處理圖像形狀信息。形狀流用于處理邊界信息。
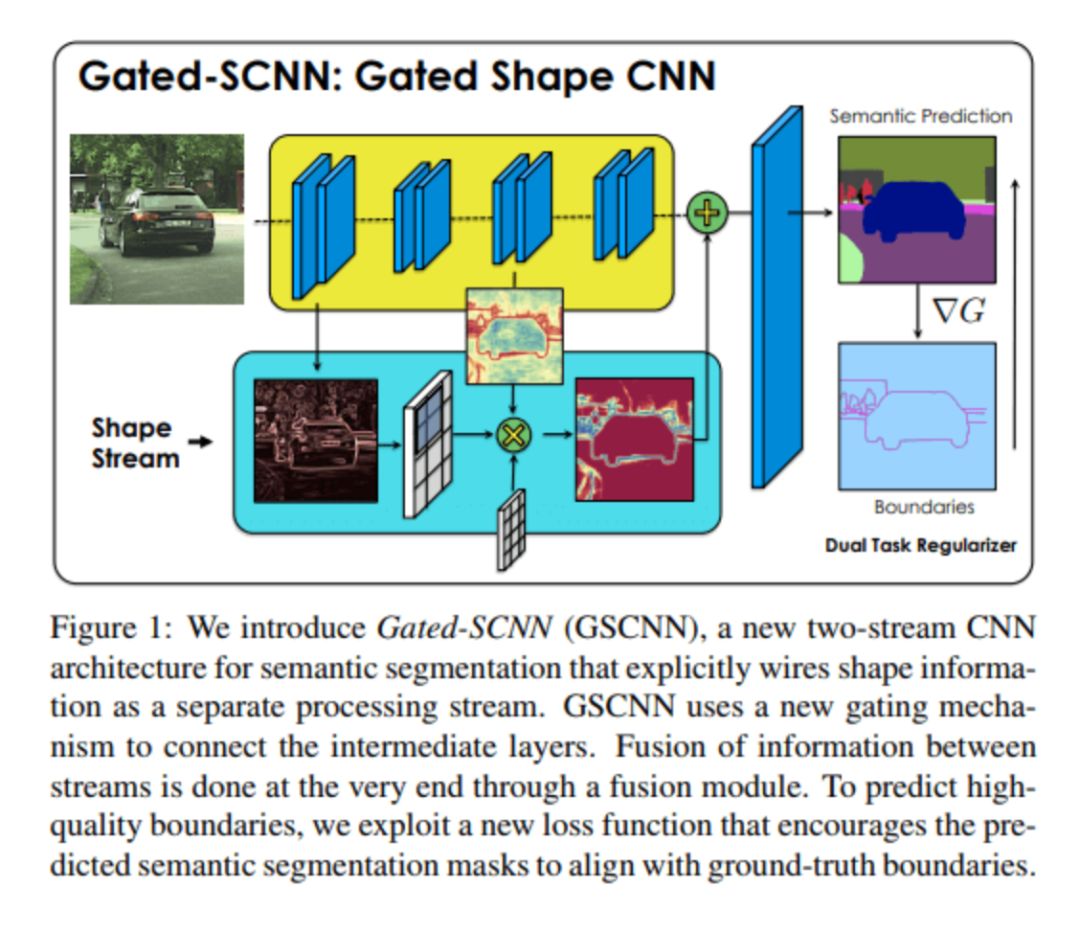 ?
?
DeepLab
在這種結構中,卷積與上采樣濾波器用于涉及密集預測的任務。多個對象的分割是通過空間金字塔池來完成的。
最后,用DCNNs改進對象邊界的定位。通過插入零點或對輸入特征圖進行稀疏采樣來對濾波器進行上采樣,從而實現空洞卷積。
?
可以在PyTorch或TensorFlow上嘗試其實現。
Mask R-CNN
在這種體系結構中,使用bounding box和語義分割對對象進行分類和定位,并將每個像素分類為一組類別。每個感興趣的區域都有一個分割掩碼,最終的輸出是一個類標簽和一個bounding box。
該體系結構是Faster R-CNN的擴展,Faster R-CNN由提出區域的深度卷積網絡和利用區域的檢測器組成。 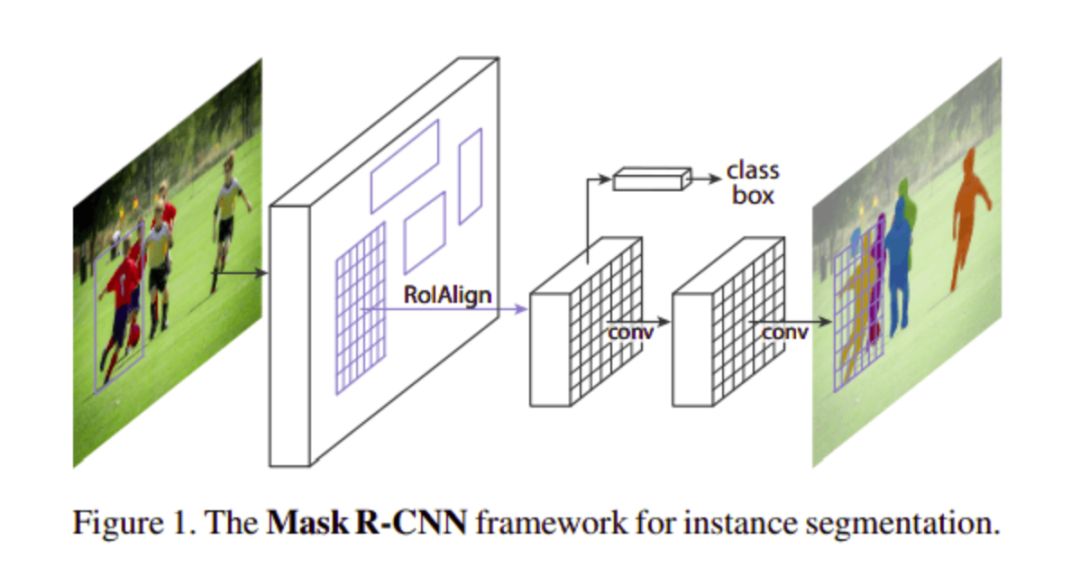
這是在COCO測試集上得到的結果的圖像  ?
?
圖像分割損失函數
語義分割模型在訓練過程中通常使用一個簡單的交叉熵損失函數。但是,如果對獲取圖像的粒度信息感興趣,則必須恢復到稍微高級一些的損失函數,來看幾個例子:
Focal Loss
這種損失是對標準交叉熵準則的改進。這是通過改變其形狀來實現的,使得分配給分類良好的示例的損失權重降低了。最終,確保不存在類不平衡。
在這個損失函數中,交叉熵損失是會隨著縮放系數衰減為零而縮,訓練時,比例因數自動降低了簡單示例的權重,并將重點放在困難示例上。 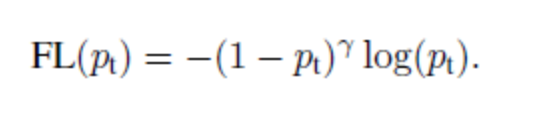 ?
?
Dice loss
該損失是通過計算平滑dice coefficient函數獲得的。這種損失是最常用的損失,是分割 問題。
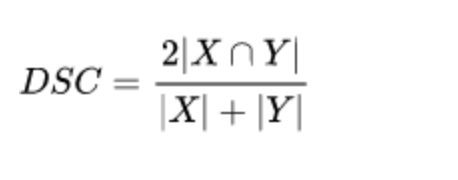 ?
?
Intersection over Union (IoU)-balanced Loss
IoU平衡分類損失的目的是增加高IoU樣本的梯度,降低低IoU樣本的梯度。從而提高了機器學習模型的定位精度。
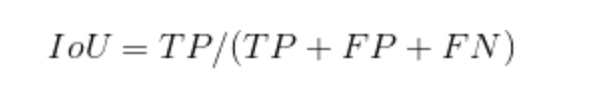 ?
?
Boundary loss
Boundary loss的一種變體應用于具有高度不平衡分段的任務。
這種損失的形式是空間輪廓而非區域上的距離度量。通過這種方式,它解決了高度不平衡的分割任務的區域損失所帶來的問題。
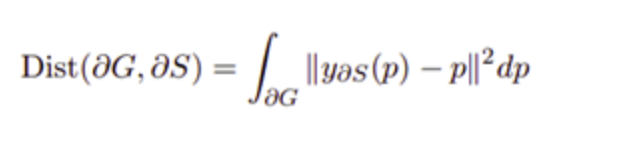
Weighted cross-entropy
在交叉熵的一個變體中,所有正例均按一定系數加權。它用于涉及類不平衡的方案。
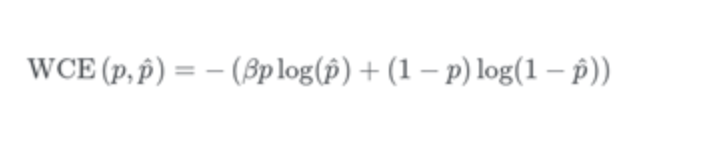 ?
?
Lovász-Softmaxloss
該損失基于子模塊損失的convex Lovasz擴展,對神經網絡中的intersection-over-union loss進行了直接優化。
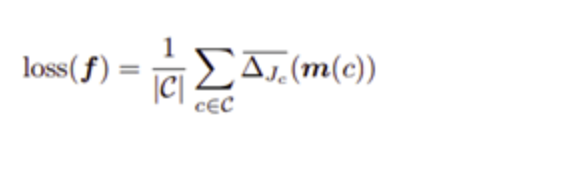 ?
?
其他值得一提的損失有:
TopK loss:其目標是確保網絡在訓練過程中專注于困難樣本。
Distance penalized CE loss:它將網絡引向難以分割的邊界區域。
Sensitivity-Specificity (SS) loss:計算特異性和敏感性的均方差的加權和。
Hausdorff distance(HD) loss:可從卷積神經網絡估計Hausdorff距離。
這些是在圖像分割中使用的一些損失函數。
圖像分割的數據集
Common Objects in COntext—Coco Dataset
COCO是一個大型的對象檢測、分割和字幕數據集。數據集包含91個類。它有25萬人,都有自己的關鍵點。它的下載大小是37.57 GiB。它包含80個對象類別。它在Apache 2.0的許可下可用。
PASCAL Visual Object Classes (PASCAL VOC)
PASCAL有20個不同的類,9963張圖片。訓練/驗證集是一個2GB的tar文件。
The Cityscapes Dataset
這個數據集包含城市場景的圖像。該方法可用于評價視覺算法在城市場景中的性能。
The Cambridge-driving Labeled Video Database?—?CamVid
這是一個基于動作的分割和識別數據集。它包含32個語義類。以下鏈接包含數據集的進一步說明和下載鏈接。
圖像分割框架
如果準備好了數據集,那么來談談一些可用于入門的工具/框架。
FastAI庫:給定一個圖像,該庫能夠為圖像中的對象創建掩碼。
Sefexa圖像分割工具:可用于半自動圖像分割,圖像分析和創建地面實況。
Deepmask:Facebook Research的Deepmask是DeepMask和SharpMask的Torch實現。
MultiPath:這是一個Torch實現,從“用于目標檢測的多路徑網絡”中提取目標檢測網絡。
OpenCV:這是一個開放源代碼的計算機視覺庫,具有2500多種優化算法。
MIScnn:醫學圖像分割開源庫。它允許在幾行代碼中使用最新的卷積神經網絡和深度學習模型建立管道。
Fritz:提供了多種計算機視覺工具,包括用于移動設備的圖像分割工具。
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1143瀏覽量
40717 -
編碼器
+關注
關注
45文章
3638瀏覽量
134426 -
圖像分割
+關注
關注
4文章
182瀏覽量
17995 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45976 -
cnn
+關注
關注
3文章
352瀏覽量
22203
原文標題:沒你想的那么難 | 一文讀懂圖像分割
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦


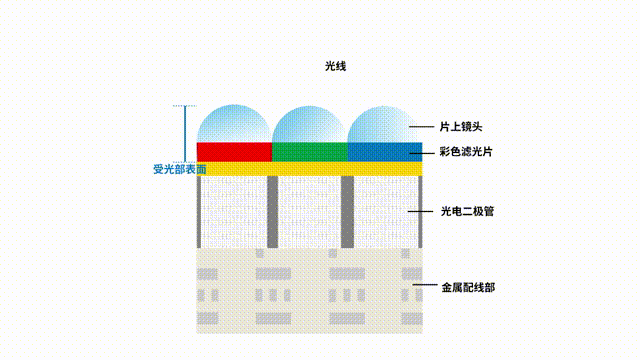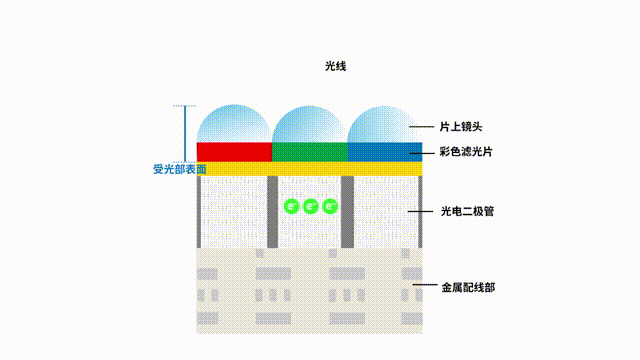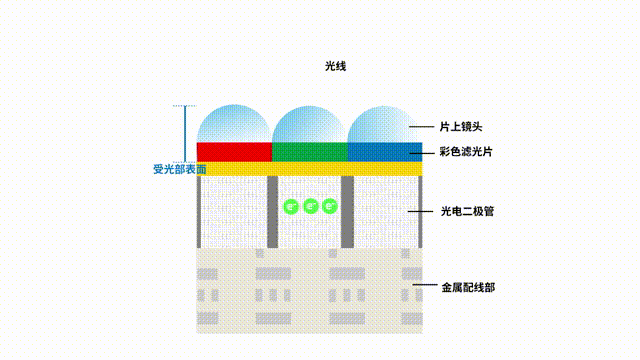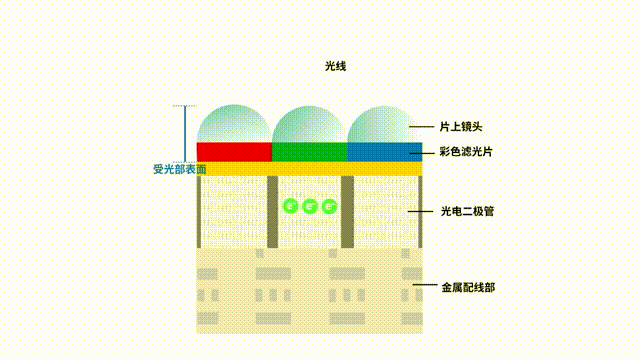
一文讀懂圖像傳感器的選型
圖像語義分割的實用性是什么
圖像分割與目標檢測的區別是什么
圖像分割與語義分割中的CNN模型綜述
機器人視覺技術中圖像分割方法有哪些
電主軸:教您如何一文讀懂?|深圳恒興隆機電.
一文讀懂寬帶、帶寬、網速之間的區別與關系
一文讀懂:圖像特征檢測算法!






 工商網監
工商網監
評論