 Arm Mobile Studio 2022.4實現自動性能監控等功能
Arm Mobile Studio 2022.4實現自動性能監控等功能
Arm Mobile Studio(https://developer.arm.com/Tools%20and%20Software/Arm%20Mobile%20Studio)在過去幾個版本中進行了多項增強,以支持游戲開發人員更輕松的進行性能分析。隨著我們的最新版本2022.4現在可以下載,我們采取了一些大膽的舉措-我們的所有專業功能現在都是免費的,所有人都可以使用。我們還考慮到新用戶的體驗,改進了工具的性能,并添加了分析光追內容的新功能,您可以開始測試下一代設備的性能。
以下是最新版本的一些亮點,以及今年早些時候發布的一些您可能錯過的亮點。
現在所有人都可以使用專業CI功能
不再需要購買Arm Mobile Studio專業許可證才能在持續集成(CI)工作流中使用這些工具。因為我們相信所有游戲工作室都可以使用可擴展的性能分析,所以我們在免費版本中提供了所有的專業功能。
為了確保您的移動游戲擁有廣泛的受眾,您需要對盡可能多的設備進行性能測試。為設備群中的每個設備手動執行此操作非常耗時和昂貴。此外,您應該在整個開發過程中定期測試內容。與在發布周期結束時再修補問題相比,在出現問題時就修復問題要容易得多。
在headless模式下運行Arm Mobile Studio工具,作為連續集成系統的一部分,可以跨多個設備進行自動性能測試。每天晚上都要運行這個程序,并獲得每日性能反饋,并可以跟蹤性能隨時間的變化。您可以將報告數據導出為CSV和JSON格式的可讀文件,以便在自定義數據分析中使用。使用它可以使用任何兼容的數據庫和可視化工具(如ELK堆棧)構建性能儀表板。
你可以閱讀我們的教程(https://developer.arm.com/documentation/102543/latest/Overview)以幫助您進行設置。
Android版本變體支持
現在,您可以在運行“eng”或“userdebug”操作系統版本的Android設備上評測不可調試的應用程序版本。有關這些構建變體的詳細信息,請參閱Android文檔(https://source.android.com/docs/setup/create/new-device#build-variants)。
支持新的Arm CPU和GPU
Arm Mobile Studio工具支持最新的Arm CPU和GPU:
. Cortex-X3(https://www.arm.com/products/cortex-x)
. Cortex-A715(https://developer.arm.com/Processors/Cortex-A715)
. Immortalis-G715(https://developer.arm.com/Processors/Immortalis-G715)
. Mali-G715(https://developer.arm.com/Processors/Mali-G715)
. Mali-G615(https://developer.arm.com/Processors/Mali-G615)
DWARF5調試支持
Streamline中的軟件評測現在支持使用DWARF5調試格式的應用程序二進制文件。
Streamline中的Mali時間線事件
您現在可以在Streamline中監視Mali時間線事件。這有助于您確定GPU調度問題,其中non-fragment和fragment隊列在整個或部分幀中串行運行。理想情況下,這兩個工作負載應該重疊。如果您看到一個隊列空閑而另一個處于活動狀態的區域,則可能存在序列化問題。為了識別可能導致管道等待的問題,可以將計數器樣本與渲染過程和計算分派相關聯。有關更多信息,請參閱我們推薦的工作負載流水線(https://developer.arm.com/documentation/102521/0100)和流水線瓶頸(https://developer.arm.com/documentation/102521/0100/Pipeline-Bottlenecks)的最佳實踐。
Mali時間線事件顯示為時間線視圖底部的自定義活動圖。
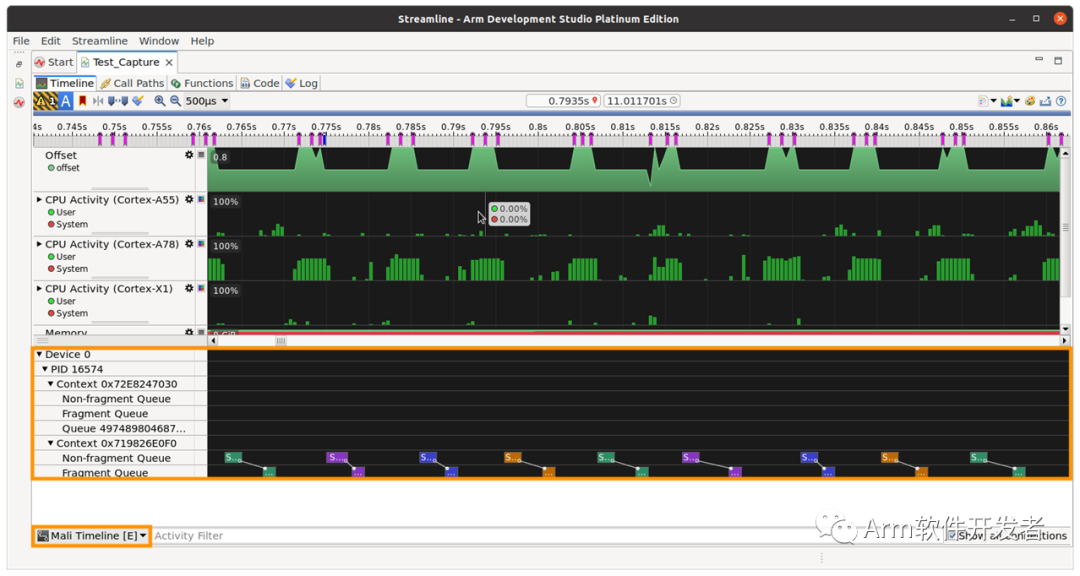
有關如何捕獲Mali時間線事件的說明,請參閱Streamline用戶指南(https://developer.arm.com/documentation/101816/latest/Capture-a-Streamline-profile/Counter-Configuration/Enable-Mali-Timeline-Events)。
注意:此功能需要具有Android Perfetto服務(https://perfetto.dev/)和兼容的Mali設備驅動程序版本r40p0或更高版本的Android 10設備。
性能增強
在Arm,我們明白工具的可用性至關重要。這就是為什么在每個版本中,我們都會分配一些工程時間,以使我們的工具運行得更快。這一次,對于Streamline,對于包含大量應用程序調試信息的軟件配置文件,我們顯著改進了分析時間和內存占用。
分析一個具有大約3GB調試信息的示例Unreal Engine項目所需的時間已從25分鐘降至2.5分鐘。
對于OpenGL ES和Vulkan,Performance Advisor從移動設備上運行的應用程序收集幀邊界和屏幕截圖數據的機制得到了顯著增強。這種新的實現提高了可靠性并減少了對目標應用程序的性能影響。
注意:對于OpenGL ES應用程序,我們現在只能使用層(layer)驅動程序收集數據,這需要Android 10或更高版本。要在早期版本的Android設備上使用Performance Advisor,您需要從應用程序手動發出所需的幀邊界注釋。有關如何執行此操作的說明,請參閱Performance Advisor用戶指南(https://developer.arm.com/documentation/102009/latest/Adding-semantic-input-to-the-reports/Send-and-include-annotations-from-application-code/Send-annotations-from-your-application-code)。
保存屏幕截圖
捕獲慢幀屏幕截圖(目前僅限OpenGL ES)時,如果上一個屏幕截圖仍在保存,Performance Advisor將跳過屏幕截圖。這消除了應用程序中積壓的屏幕截圖導致的性能問題。此外,當在未壓縮模式下運行時,屏幕截圖現在保存為.bmp圖像,而不是未壓縮的.png圖像。這將捕獲和寫入屏幕截圖所需的時間從250毫秒減少到80毫秒以下,從而減少了對應用程序的性能影響。
Performance Advisor區域分析
如果應用程序使用區域標記(https://developer.arm.com/documentation/102009/latest/Adding-semantic-input-to-the-reports/Send-annotations-from-your-application-code)來指定感興趣的時間區域,則這些區域在Performance Advisor的幀速率分析圖表上可見。此外,每個區域的數據將單獨報告。這有助于為報告提供上下文。但是,如果應用程序具有多個區域,則報告的數據可能會變得過于精細,從而使報告難以閱讀。
在此版本中,如果某些區域較短或嵌套在其他區域之下,您現在可以選擇從Performance Advisor報告中省略這些區域。這為您提供了對區域分析方式的更多控制。
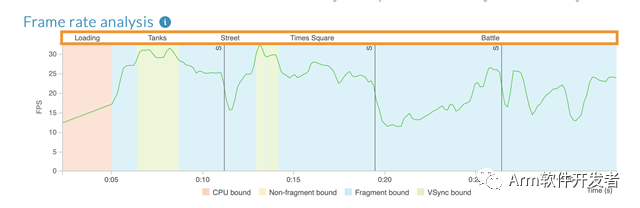
生成報告時,使用以下新的pa命令選項(https://developer.arm.com/documentation/102009/latest/Command-line-options/The-pa-command)忽略區域:
----region-report-min-length=length
報告中省略給定最小長度以下的區域。
----region-report-max-depth=level
報告中省略區域層次結構中比給定級別更深的區域。
Mali脫機編譯器增強功能
我們對用于著色器分析的性能報告工具Mali Offline Compiler進行了多項增強。
光線(Ray)查詢性能反饋
新的Immortalis-G715在移動設備中引入了硬件加速光線跟蹤(https://community.arm.com/arm-community-blogs/b/graphics-gaming-and-vr-blog/posts/developing-ray-tracing-content-for-mobile-games),同時支持Vulkan光線查詢和完整光線跟蹤管道。在此版本中,Mali Offline Compiler使用光線查詢和所有光線跟蹤管道階段為內容提供反饋。
以下示例報告已識別出碎片著色器中的慢速光線跟蹤:
Mali Offline Compiler v7.8.0 (Build aeadf0)
Copyright (c) 2007-2022 Arm Limited. All rights reserved.
Configuration
=============
Hardware: Immortalis-G715 r0p0
Architecture: Valhall
Driver: r41p0-00rel0
Shader type: Vulkan Fragment
Main shader
===========
Work registers: 64 (100% used at 50% occupancy)
Uniform registers: 10 (15% used)
Ray traversal contexts: 16 objects
Stack spilling: 32 bytes
16-bit arithmetic: 0%
A LS V T Bound
Total instruction cycles: 4.70 64.60 0.03 0.00 LS
Shortest path cycles: 0.47 19.00 0.03 0.00 LS
Longest path cycles: N/A N/A N/A N/A N/A
A = Arithmetic, LS = Load/Store, V = Varying, T = Texture
Shader properties
=================
Has uniform computation: true
Has side-effects: false
Modifies coverage: false
Uses late ZS test: false
Uses late ZS update: false
Reads color buffer: false
Has slow ray traversal: true
Note: This tool shows only the shader-visible property state.
API configuration may also impact the value of some properties.
在主著色器部分,報告顯示編譯器分配的光線遍歷上下文的數量。每個光線查詢或光線跟蹤管道遍歷至少需要一個遍歷上下文。然而,上下文可能由具有非重疊生存期的多個遍歷共享。有時,單個源查詢或遍歷可能需要多個上下文。多上下文遍歷比單個上下文遍歷慢。
著色器(shader properties)部分報告,如果著色器正在使用至少一個光線遍歷,則著色器具有緩慢的光線遍歷。這迫使編譯器回退到較慢的多上下文遍歷行為。
《Mali Offline Compiler用戶指南》中添加了必須遵循的Vulkan ray查詢最佳實踐指南,以避免緩慢的遍歷路徑(https://developer.arm.com/documentation/101863/latest/Using-Mali-Offline-Compiler/Performance-analysis/Shader-properties)。
頂點著色器(Vertex Shaders)的內存分區建議
從Bifrost架構開始的Mali GPU將用戶著色器分為兩部分,一部分計算位置,另一部分計算所有非位置屬性。在幾何體剔除之前只需要位置,因此非位置屬性著色器僅對可見頂點運行。為了最小化冗余內存訪問,Mali 最佳實踐(https://developer.arm.com/documentation/101897/latest/Vertex-shading/Attribute-layout)建議您將兩個著色器所需的輸入屬性拆分為兩個壓縮流。Mali 離線編譯器頂點著色器性能報告用于實現Bifrost架構或更新版本的Arm GPU,現在報告屬性流的建議內存分區。
Recommended attribute streams
=============================
Position attributes
- position (location=dynamic)
Non-position attributes
- None
預期著色器核心線程占用率Mali Offline Compiler現在報告了預期的著色器核心線程占用率以及寄存器計數。這減少了對線程占用信息參考外部數據表的需要。
Main shader
===========
Work registers: 64 (100% used at 50% occupancy)
Uniform registers: 10 (15% used)
Ray traversal contexts: 16 objects
Stack spilling: 32 bytes
16-bit arithmetic: 0%
更多Mali脫機編譯器功能以下是我們對Mali Offline Compiler的一些更新:
. 所有實現Valhall體系結構的Arm GPU的性能報告現在都報告了基于微體系結構感知成本模型的單一運算成本。使用--detailed命令行選項,每個算術指令類型的組件成本仍然可用。. Bifrost和Valhall架構GPU的加載/存儲單位成本模型已得到改進,現在正確地反映了統一加載和堆棧訪問的較低訪問成本。. 將Bifrost和Valhall架構GPU的編譯器后端更新為r41p0. 更新了Khronos glslangValidator前端,用于將GLSL源代碼編譯為SPIR-V IR,以支持SPIR-V 1.6功能。. 通過指定--name命令行選項,直接從GLSL源代碼編譯的Vulkan著色器現在可以使用“main()”以外的入口點。. 增加了對SPIR-V計算內核的OpenCL 3.0支持。. 添加了過濾功能以刪除性能報告中的重復編譯器警告。總結我們希望您在這個版本中找到一些增強性能分析工作流的東西。無論您是小型獨立開發人員,還是大型游戲工作室,Arm Mobile studio都具有幫助您的游戲在各種設備上表現出色的功能。通過我們的免費版,將性能分析按比例構建到您的開發工作流中現在更容易訪問。性能分析現在更快了,您可以更好地控制收集的數據。
我們預計搭載最新Immortalis-G715 GPU的移動設備將于2023年上市。Mali離線編譯器硬件加速光線跟蹤的新功能有助于深入了解未來移動硬件如何處理光線跟蹤內容。
有關更改、修復和增強的完整列表以及安裝指南,請參閱2022.4發行說明(https://developer.arm.com/documentation/107649/2022-4/)。
下載Arm Mobile Studio:https://developer.arm.com/mobile-studio/downloads
審核編輯 :李倩
-
Android
+關注
關注
12文章
3937瀏覽量
127484 -
監控
+關注
關注
6文章
2212瀏覽量
55237 -
編譯器
+關注
關注
1文章
1634瀏覽量
49153
原文標題:Arm Mobile Studio 2022.4實現自動性能監控等功能
文章出處:【微信號:Arm軟件開發者,微信公眾號:Arm軟件開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
海康攝像頭dll開發,控制,顯示,拍照等功能實現
如何實現基于WinCE的ARM視頻監控系統的設計?
如何在驅動器內部實現軌跡規劃等功能
如何實現定時器輸入捕獲與輸出比較等功能呢
將Arm Mobile Studio集成到CI工作流中
ARM Mobile Studio的常見問題解答
請問SEGGER Embedded Studio for ARM 7.32怎么實現代碼自動補全功能
VB_S7-200的PPI通訊,以及監控等功能實現
Arm Mobile Studio的學習資源

Arm Mobile Studio 2022.4實現自動性能監控等功能
Helix QAC 2022.4 中的新增功能






 工商網監
工商網監
評論