

1. 引言
多年以后,面對圖形處理器(GPU)在人工智能、加密貨幣、高性能計算、自動駕駛等多研究領(lǐng)域的廣泛應用,如今的游戲發(fā)燒友們是否會回想起,1999年Nvidia發(fā)布專業(yè)游戲顯卡GeForce256時那個炎熱的夏天?
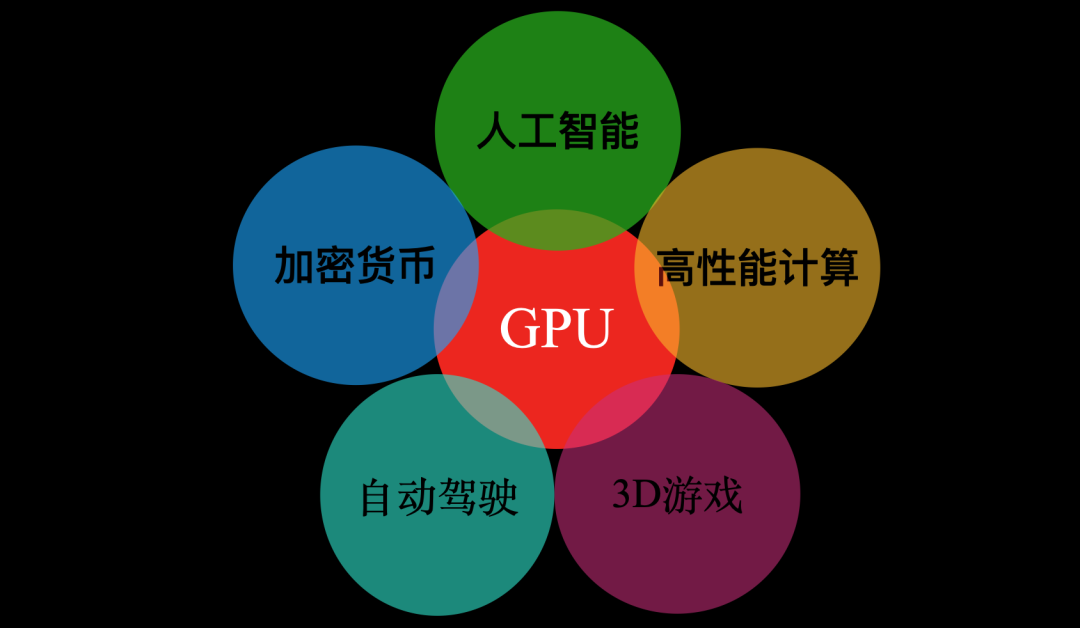
GPU應用
GeForce256發(fā)布以后GPU一詞才被大眾所接受,實際上1994年索尼發(fā)布PS1的時候就提出了GPU的概念,當時使用的是由東芝為索尼設(shè)計的GPU。
而后來在2002年ATI(已被AMD收購)提出的VPU(Visual Processing Unit)一詞則在時代的浪潮中消失無蹤。
從GeForce256發(fā)布至今的21年時間,GPU實現(xiàn)了從PC游戲時代到AI時代的巨大跨越。本文將和大家一起揭秘GPU為何能夠撬動計算機圖形學和人工智能這兩個博大精深的領(lǐng)域。
2. GPU與計算機圖形學
今年3月18日,國際計算機學會ACM官方公布了2019年度圖靈獎(計算機界的諾貝爾獎)獲得者Hanrahan和Catmull,以表彰他們對3D計算機圖形學的貢獻。
Hanrahan提出的renderMan很大程度上對GPU產(chǎn)生了影響。例如著色器(Shader)一詞的出現(xiàn),最先是由Pixar與1988年五月發(fā)布的renderMan接口規(guī)范中提出。
renderMan技術(shù)制作了一系列成功電影,其中包括《阿凡達》、《玩具總動員》、《泰坦尼克號》等。

renderMan渲染的阿凡達
另外,Hanrahan和他的學生還開發(fā)了一種用于 GPU 的語言:Brook,并最終催生了 NVIDIA的CUDA。
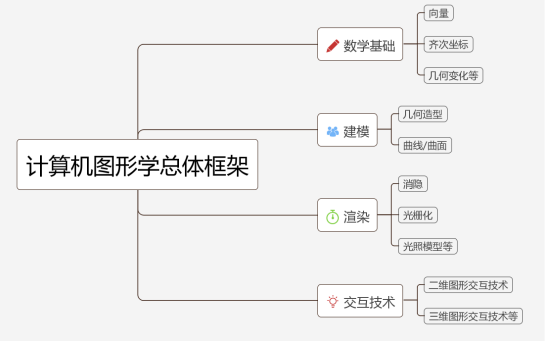
事實上,計算機圖形學是一個廣泛的學科,其中包括:
而我們的GPU,正是用來為計算機圖形學中實時圖像渲染加速的。
GPU的硬件設(shè)計上引入了圖形管線,使得各任務(wù)可以通過流水線進行并行處理。
同時通過可編程的著色器,使得GPU硬件能夠根據(jù)圖形學算法更好的被使用。
通過下一節(jié)我們可以詳細的了解到什么是GPU圖形管線和可編程著色器。
2.1 GPU圖形管線
GPU圖形管線共分為三個部分,分別是應用程序階段、幾何階段、光柵化階段。
我們在最終在屏幕上看到的畫面,就是3D模型經(jīng)過這三個階段渲染后得到的。

GPU圖形管線
- 應用程序階段
圖形渲染管線概念上的第一個階段,開發(fā)者通過程序的方式對圖元數(shù)據(jù)等信息進行配置和調(diào)控,最后傳輸?shù)较聜€階段。
- 幾何階段
幾何階段分為模型視點變換、頂點著色、裁剪、屏幕映射等步驟。
模型視點變換 :由每個模型自己的局部坐標系轉(zhuǎn)換到世界坐標系,然后到視覺空間,通過將每個模型的各頂點坐標與相應的變換矩陣相乘來實現(xiàn)。
下圖是一個模型視點變換的實例,每個建模好的立方體的坐標是以原點為中心的局部坐標系,可以通過矩陣變換將各模型放到同一個世界坐標系中。
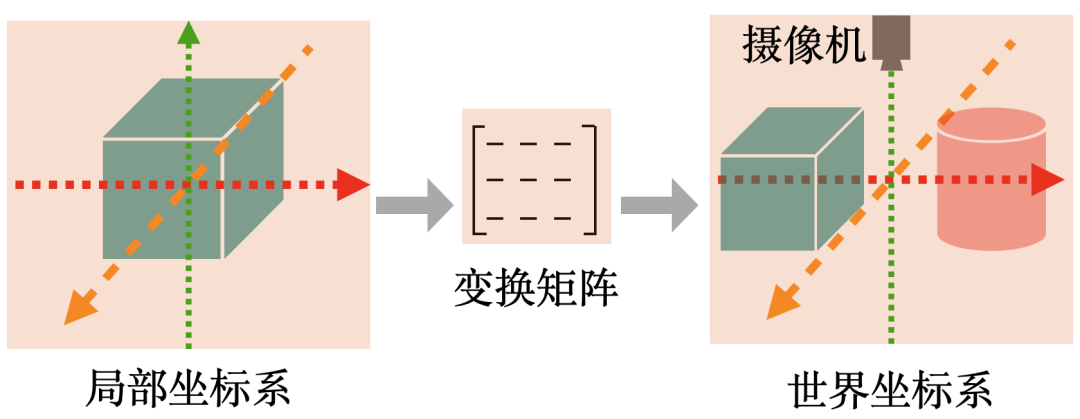
模型視點變換
頂點著色:著色是指確定材質(zhì)的顏色,材質(zhì)的顏色實際上和光照有關(guān)。目前常用的光照模型是馮氏光照模型,包括環(huán)境、漫反射和鏡面光照。
裁剪 :對于在屏幕空間外的物體,我們并沒有必要去計算它的顏色等信息
屏幕映射:是將之前步驟得到的坐標映射到對應的屏幕坐標系上。
- 光柵化階段
給定經(jīng)過變換和投影之后的頂點,顏色以及紋理坐標(均來自于幾何階段),給每個像素正確配色,以便正確繪制整幅圖像,這個過程叫光柵化。
光柵化包括三角形設(shè)定、三角形遍歷、像素著色、融合階段(如下圖所示)。

光柵化階段
三角形設(shè)定階段:計算三角形表面的差異和三角形表面的其他相關(guān)數(shù)據(jù)。
三角形遍歷階段:到那些采樣點或像素在三角形中的過程通常叫三角形遍歷。
像素著色階段:主要目的是計算所有需要逐像素計算操作的過程。
融合階段:合成當前儲存于緩沖器中的由之前的像素著色階段產(chǎn)生的片段顏色。
2.2 可編程著色器
可編程著色器(shader),簡單來說就是可以運行在GPU上的程序,這種程序會使用特定的著色語言(類似于C語言)。
2.2.1 著色器語言
不同圖形編程接口對應不同的著色語言,Windows平臺上的圖形編程接口DirectX使用的是HLSL,而跨平臺的圖形編程接口OpenGL則是使用的GLSL,HLSL與GLSL的語法與C語言十分相似。而新一代圖形編程接口Vulkan則是直接定義了一套二進制中間語言SPIR-V。
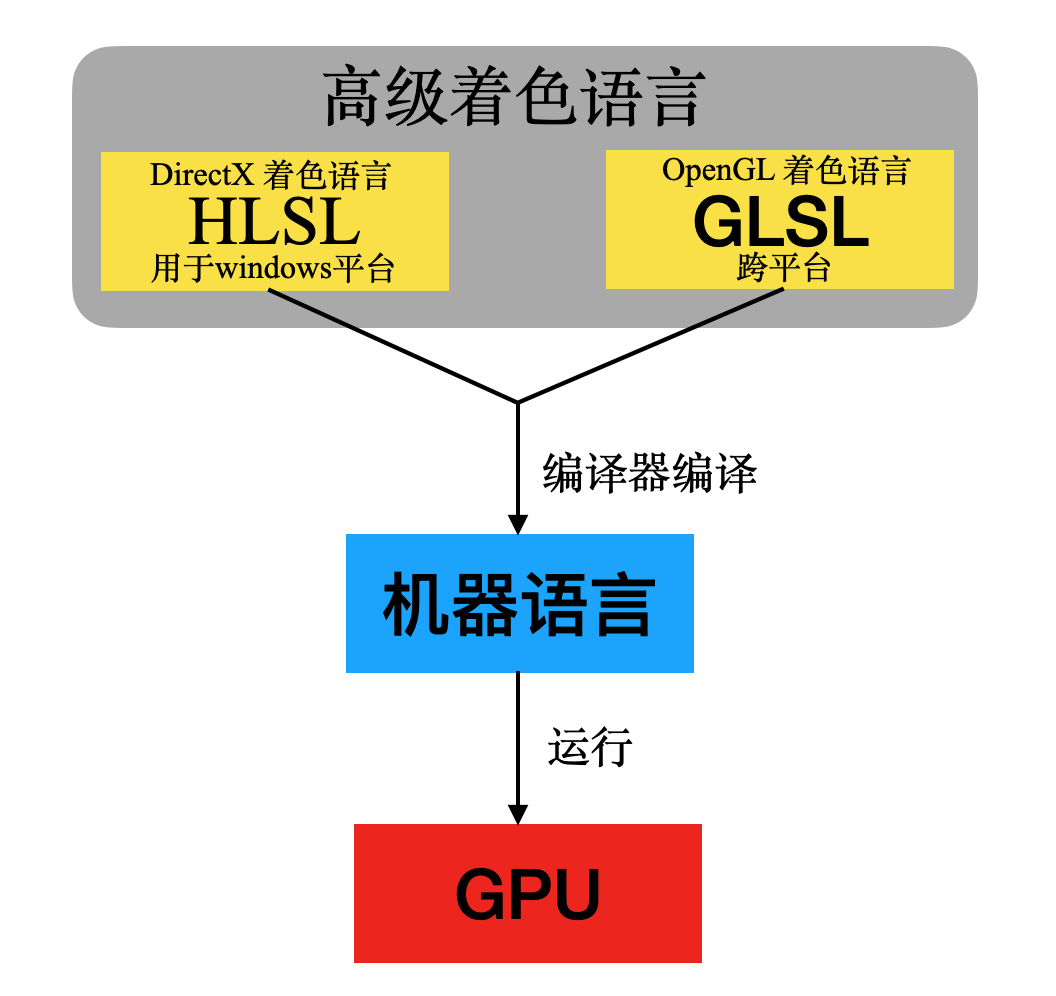
HLSL與GLSL都可以編譯成獨立于機器的中間語言(SPIR-V本身就是中間語言),然后在驅(qū)動中通過編譯器轉(zhuǎn)換成實際的機器語言。這樣可以實現(xiàn)對不同硬件的兼容,因為不同廠商可以在驅(qū)動中調(diào)用自己的編譯器生成自家GPU識別的指令。
有了著色語言以后,我們的工程師就可以通過高級語言來控制GPU對圖形進行實時渲染。
但實際上我們的GPU一開始支持的Shader并沒有那么多。這與GPU硬件的可編程渲染架構(gòu)發(fā)展有關(guān)。
GPU可編程渲染架構(gòu)經(jīng)歷了分離渲染架構(gòu)到統(tǒng)一渲染架構(gòu)的進化過程。
如下圖所示,左邊是分離渲染架構(gòu),右邊是統(tǒng)一渲染架構(gòu)。
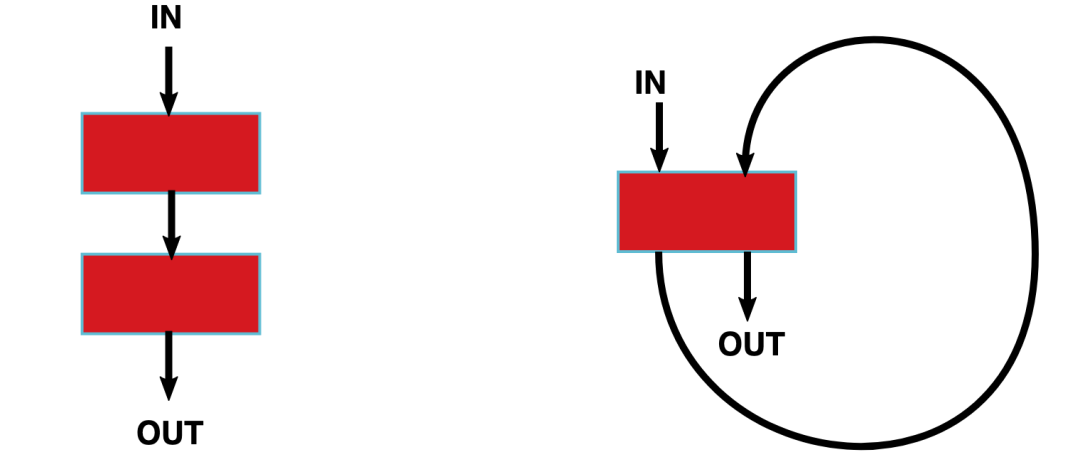
分離架構(gòu) vs 統(tǒng)一渲染架構(gòu)
分離渲染架構(gòu):頂點著色器與像素著色器在兩個不同的著色器核(紅色部分)上運行。
統(tǒng)一渲染架構(gòu):所有的著色器程序都可以在同一個著色器核上運行。
與分離渲染架構(gòu)相比,統(tǒng)一渲染架構(gòu)更加靈活且利用率更高。
下面以DirectX(openGL也有對應的版本)發(fā)布為線索,分別介紹分離渲染架構(gòu)與統(tǒng)一渲染架構(gòu)的發(fā)展歷史。
2.2.2 分離渲染架構(gòu)

- 1999年微軟DirectX7提供了硬件頂點變換的編程接口,NV的Geforc256對此進行了支持,從此NV公司從眾多顯卡制造商中殺出重圍,逐漸占據(jù)了龍頭老大的地位。
- 2001年DirectX8發(fā)布,包含Shader Model 1.0標準。遵循這一模型的GPU可以具備頂點和像素的可編程性。同年,NVIDIA發(fā)布了Geforce3,ATI發(fā)布了Radeon8500,這兩種GPU支持頂點編程。但是這一時期的GPU都不支持像素編程,只是提供了簡單的配置功能。
- 2002年,DirectX9.0公布,包含Shader Model 2.0。此模型是真正的可編程頂點著色器及像素著色器。頂點著色器主要執(zhí)行頂點的變換、完成光照與材質(zhì)的運用及計算等相關(guān)操作。
- 2003年,NVIDIA和ATI發(fā)布的新產(chǎn)品都同時具備了可編程頂點處理和可編程像素處理器。從此,GPU具備了可編程屬性,也叫做可編程圖形處理單元。
2.2.3 統(tǒng)一渲染架構(gòu)
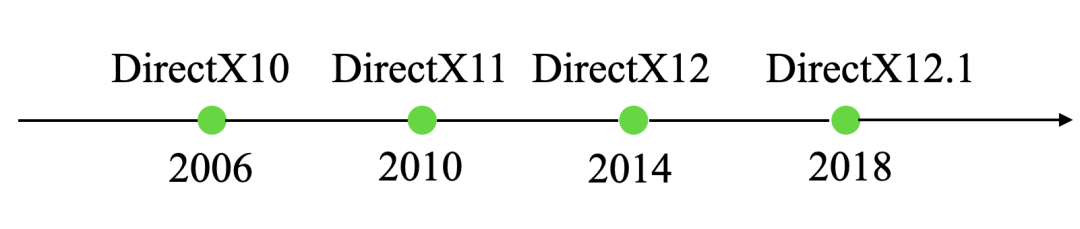
- 2006年包含DirectX10的 Shader Model4.0發(fā)布,采用統(tǒng)一渲染架構(gòu),使用統(tǒng)一的流處理器。這一時期,比較有代表性的GPU有NVIDIA的Geforce9600和ATI的Radeon 3850。
- 2010年,包含DirectX11的Shader Model 5.0 發(fā)布,增加了曲面細分著色器、外殼著色器、鑲嵌單元著色器、域著色器、計算著色器。這一時期比較有代表性的GPU是GeForece405
- 2014年,DirectX 12發(fā)布,主要特性有輕量化驅(qū)動層、硬件級多線程渲染支持、更完善的硬件資源管理,比較有代表性的GPU有GeForceGT 710
- 2018,DirectX 12.1發(fā)布,代表性GPU是TITAN RTX,擁有1770MHz主頻,24G顯存,384位帶寬,支持8K分辨率。
以上僅列舉了部分Shader Model的特性,如要查看完整特性,有興趣的同學可以參考這個鏈接Shader Model
2.3 小結(jié)
上一節(jié)介紹了GPU渲染架構(gòu)發(fā)展歷史、GPU圖形管線、以及能夠在GPU上運行的高級著色語言。
可以看到,GPU對圖形渲染的過程需要并行處理海量數(shù)據(jù),涉及大量矩陣運算,這一特性使得GPU能夠在人工智能應用中發(fā)揮巨大的作用。
下一節(jié)我們將看到GPU的這些特性是如何為深度學習加速的。
3. GPU與人工智能
2018年,國際計算機學會將圖靈獎頒發(fā)給了深度學習領(lǐng)域的三位大師Hinton,LeCun 和 Bengio。
深度學習剛被提出的時候曾經(jīng)遭到學術(shù)屆的質(zhì)疑,而如今卻成為了人工智能領(lǐng)域的熱點。
人工智能的三大要素:算法、算力、大數(shù)據(jù)。
深度學習被質(zhì)疑的一部分原因正是因為當時的計算能力無法滿足深度學習的要求,而如今異構(gòu)計算則成為了深度學習的重要支柱。
使用不同的類型指令集、不同的體系架構(gòu)的計算單元,組成一個混合的系統(tǒng),執(zhí)行計算的特殊方式,就叫做異構(gòu)計算。
3.1 異構(gòu)計算
目前關(guān)于深度學習流行的異構(gòu)解決方案共三種,分別是ASIC、FPGA、GPU。
但是從開發(fā)人員數(shù)量和受歡迎程度以及生態(tài)系統(tǒng)來說,GPU無疑是最有優(yōu)勢的。
通過下面三種方案的對比,我們可以看到這三種方案各自的優(yōu)缺點。
- CPU+ASIC
ASIC即專用集成電路,是指應特定用戶要求和特定電子系統(tǒng)的需要而設(shè)計、制造的集成電路。
優(yōu)點::體積小、功耗低、計算性能高、計算效率高、芯片出貨量越大成本越低。
缺點:算法固定,一旦算法變化就無法使用。目前人工智能算法遠沒有到算法平穩(wěn)期,ASIC專用芯片如何做到適應各種算法是個最大的問題。
實例:寒武紀的NPU、地平線的BPU、Google的TPU都是屬于ASIC。如圖是Google的TPU,兼具了CPU與ASIC的特點。

Google TPU
- CPU+FPGA
FPGA是一種硬件可重構(gòu)的體系結(jié)構(gòu)。它的英文全稱是Field Programmable Gate Array,中文名是現(xiàn)場可編程門陣列。

CPU+FPGA
優(yōu)點:靈活性高、無需取指令、譯碼,執(zhí)行效率高。FPGA中的寄存器和片上內(nèi)存由各自的邏輯進行控制無需仲裁和緩存。多個邏輯單元之間的通信已經(jīng)確定,無需通過共享內(nèi)存進行通信。
缺點:總體性價比和效率不占優(yōu)勢。FPGA的大規(guī)模開發(fā)難度偏高,從業(yè)人員相對較少,生態(tài)環(huán)境不如GPU。
實例:微軟使用FPGA為Bing搜索智能化進行加速。
- CPU+GPU

CPU+GPU
GPU具有更好的生態(tài)環(huán)境,例如具備CUDA支持的GPU為用戶學習Caffe、Theano等研究工具提供了很好的入門平臺。為初學者提供了相對更低的應用門檻。
除此之外,CUDA在算法和程序設(shè)計上相比其他應用更加容易,通過NVIDIA多年的推廣也積累了廣泛的用戶群,開發(fā)難度更小。
最后則是部署環(huán)節(jié),GPU通過PCI-e接口可以直接部署在服務(wù)器中,方便快速。得益于硬件支持與軟件編程、設(shè)計方面的優(yōu)勢,GPU才成為了目前應用最廣泛的平臺。
3.2 GPU與深度學習
與大多機器學習算法一樣,深度學習依賴于數(shù)學和統(tǒng)計學計算。人工神經(jīng)網(wǎng)絡(luò)(ANN),卷積神經(jīng)網(wǎng)絡(luò)(CNN)和循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)是一些現(xiàn)代深度學習的實現(xiàn)。
這些算法都有以下基本運算:
- 矩陣相乘:所有的深度學習模型中都包括這一運算,計算十分密集。
- 卷積:也是深度學習中常用的運算,占用了模型中大部分的浮點運算。
上節(jié)中提到,GPU在進行圖像渲染時間需要處理每秒大量的矩陣乘法運算,
下圖是一個簡單直觀的例子:將一幅圖像倒置,在我們?nèi)庋劭磥硎且环B續(xù)的圖形,在GPU看來實際上是由多個離散的像素組成,將圖像倒置實際上對每個像素做矩陣乘法。
當然這只是一個簡單的例子,實際上的3D渲染處理的數(shù)據(jù)比這更多也更加復雜。

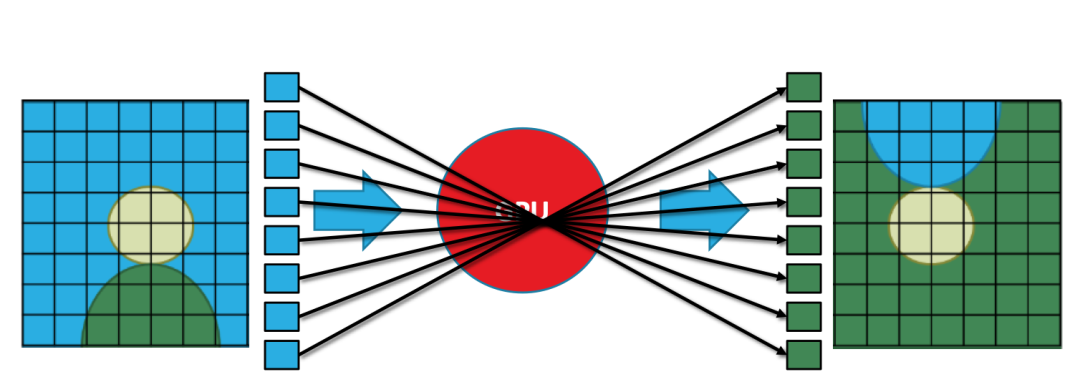
GPU并行處理
深度學習同樣需要并行處理,因為神經(jīng)網(wǎng)絡(luò)是一種典型的并行結(jié)構(gòu),每個節(jié)點的計算簡單且獨立,但是數(shù)據(jù)龐大,通常深度學習的模型需要幾百億甚至幾萬億的矩陣運算。
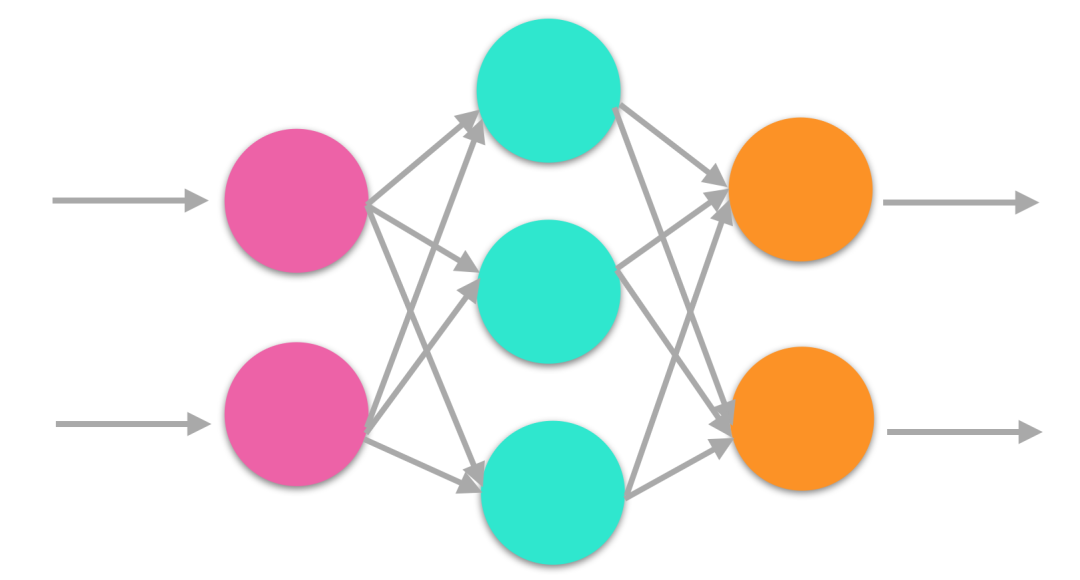
神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
可以看到,圖形渲染與深度學習有著相似之處。這兩種場景都需要處理每秒大量的矩陣乘法運算。
而GPU擁有數(shù)千個內(nèi)核的處理器,能夠并行執(zhí)行數(shù)百萬個數(shù)學運算。
因此GPU完美地與深度學習技術(shù)相契合。使用GPU做輔助計算,能夠更快地提高AI的性能。
總的來說,GPU做深度學習有三大優(yōu)勢:
- 每一個GPU擁有大量的處理器核心,允許大量的并行處理。
- 深度學習需要處理大量的數(shù)據(jù),需要大量的內(nèi)存帶寬(最高可達到750GB/S,而傳統(tǒng)的CPU僅能提供50GB/S),因此GPU更適合深度學習。
- 更高的浮點運算能力。浮點運算能力是關(guān)系到3D圖形處理的一個重要指標。現(xiàn)在的計算機技術(shù)中,由于大量多媒體技術(shù)的應用,浮點數(shù)的計算大大增加了,比如3D圖形的渲染等工作,因此浮點運算的能力是考察處理器計算能力的重要指標。
3.3 小結(jié)
本節(jié)介紹了異構(gòu)計算對深度學習加速的優(yōu)缺點,主要包括FPGA、ASIC、GPU三種硬件解決方案。
最后通過比較GPU進行圖形渲染與深度學習計算時的相似之處,解釋了GPU為何能夠加速深度學習,以及GPU加速深度學習的優(yōu)勢。
4. 總結(jié)
計算機圖形學與人工智能是兩個博大精深的領(lǐng)域,本文僅從GPU實時渲染與GPU并行加速的角度進行了闡述。
寫這篇文章的初衷是因為聯(lián)想到GPU與近三年來的圖靈獎領(lǐng)域息息相關(guān)。
2019年圖靈獎授予了計算機圖形學領(lǐng)域、2018年授予了深度學習領(lǐng)域,2017年授予了計算機體系結(jié)構(gòu)領(lǐng)域。
GPU實時渲染、GPU并行加速、GPU架構(gòu)分別與這三個領(lǐng)域有著千絲萬縷的聯(lián)系,因此想到了寫這樣一篇GPU探秘的文章。
5. 推薦閱讀
-
gpu
+關(guān)注
關(guān)注
28文章
4961瀏覽量
131490 -
算法
+關(guān)注
關(guān)注
23文章
4713瀏覽量
95584 -
可編程
+關(guān)注
關(guān)注
2文章
1061瀏覽量
40690
發(fā)布評論請先 登錄
計算機圖形學年鑒:研究現(xiàn)狀、應用和未來
基于OpenGL的計算機圖形學教學改革探索
計算機圖形學的非線性投影研究
NVIDIA將人工智能引入計算圖形學 NVIDIA GPU渲染加速視覺特效
清華AMiner團隊發(fā)布計算機圖形學研究報告

2018計算機圖形學AMiner的研究報告詳細資料免費下載
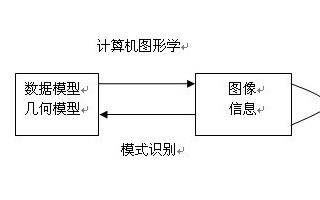
計算機圖形學 數(shù)字圖像處理和計算機視覺是什么?
計算機圖形學:探索虛擬世界的構(gòu)建之道






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論