 探究Redis網絡模型究竟有多強大(中)
探究Redis網絡模型究竟有多強大(中)
3.2.1 創建socket
創建socket這一步和客戶端沒啥區別,不同的是這個socket我們稱之為 等待連接socket(或監聽socket) 。
3.2.2 綁定端口號
bind()函數會將端口號寫入上一步生成的監聽socket中,這樣一來,監聽socket就完整保存了服務端的IP和端口號。
3.2.3 listen()的真正作用
listen(<Server描述符>, <最大連接數>);
很多小伙伴一定會對這個listen()有疑問,監聽socket都已經創建完了,端口也已經綁定完了,為什么還要多調用一個listen()呢?
我們剛說過監聽socket和客戶端創建的socket沒什么區別,問題就出在這個沒什么區別上。
socket被創建出來的時候都默認是一個 主動socket ,也就說,內核會認為這個socket之后某個時候會調用connect()主動向別的設備發起連接。這個默認對客戶端socket來說很合理,但是監聽socket可不行,它只能等著客戶端連接自己,因此我們需要調用listen()將監聽socket從主動設置為被動,明確告訴內核:你要接受指向這個監聽socket的連接請求!
此外,listen()的第2個參數也大有來頭!監聽socket真正接受的應該是已經完整完成3次握手的客戶端,那么還沒完成的怎么辦?總得找個地方放著吧。于是內核為每一個監聽socket都維護了兩個隊列:
- 半連接隊列(未完成連接的隊列)
這里存放著暫未徹底完成3次握手的socket(為了防止半連接攻擊,這里存放的其實是占用內存極小的request _sock,但是我們直接理解成socket就行了),這些socket的狀態稱為SYN_RCVD。
- 已完成連接隊列
每個已完成TCP3次握手的客戶端連接對應的socket就放在這里,這些socket的狀態為ESTABLISHED。
文字太多了,有點干,上個圖!

listen與3次握手
解釋一下動圖中的內容:
- 客戶端調用
connect()函數,開始3次握手,首先發送一個SYN X的報文(X是個數字,下同); - 服務端收到來自客戶端的
SYN,然后在監聽socket對應的半連接隊列中創建一個新的socket,然后對客戶端發回響應SYN Y,捎帶手對客戶端的報文給個ACK; - 直到客戶端完成第3次握手,剛才新創建的socket就會被轉移到已連接隊列;
- 當進程調用
accept()時,會將已連接隊列頭部的socket返回;如果已連接隊列為空,那么進程將被睡眠,直到已連接隊列中有新的socket,進程才會被喚醒,將這個socket返回 。
第4步就是阻塞的本質啊,朋友們!
3.3 答疑時間
Q1.隊列中的對象是socket嗎?
呃。。。乖,咱就把它當成socket就好了,這樣容易理解,其實具體里邊存放的數據結構是啥,我也很想知道,等我寫完這篇文章,我研究完了告訴你。
Q2.accept()這個函數你還沒講是啥意思呢?
accept()函數是由服務端調用的,用于從已連接隊列中返回一個socket描述符;如果socket為阻塞式的,那么如果已連接隊列為空,accept()進程就會被睡眠。BIO恰好就是這個樣子。
Q3.accept()為什么不直接把監聽socket返回呢?
因為在隊列中的socket經過3次握手過程的控制信息交換,socket的4元組的信息已經完整了,用做socket完全沒問題。
監聽socket就像一個客服,我們給客服打電話,然后客服找到解決問題的人,幫助我們和解決問題的人建立聯系,如果直接把監聽socket返回,而不使用連接socket,就沒有socket繼續等待連接了。
哦對了,accept()返回的socket也有個名字,叫 連接socket 。
3.4 BIO究竟阻塞在哪里
拿Server端的BIO來說明這個問題,阻塞在了serverSocket.accept()以及bufferedReader.readLine()這兩個地方。有什么辦法可以證明阻塞嗎?
簡單的很!你在serverSocket.accept(); 的下一行打個斷點,然后debug模式運行BIOServerSocket,在沒有客戶端連接的情況下,這個斷點絕不會觸發!同樣,在bufferedReader.readLine();下一行打個斷點,在已連接的客戶端發送數據之前,這個斷點絕不會觸發!
readLine()的阻塞還帶來一個非常嚴重的問題,如果已經連接的客戶端一直不發送消息,readLine()進程就會一直阻塞(處于睡眠狀態),結果就是代碼不會再次運行到accept(),這個ServerSocket沒辦法接受新的客戶端連接。
解決這個問題的核心就是別讓代碼卡在readLine()就可以了,我們可以使用新的線程來readLine(),這樣代碼就不會阻塞在readLine()上了。
3.5 改造BIO
改造之后的BIO長這樣,這下子服務端就可以隨時接受客戶端的連接了,至于啥時候能read到客戶端的數據,那就讓線程去處理這個事情吧。
public class BIOServerSocketWithThread {
public static void main(String[] args) {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8099);
System.out.println("啟動服務:監聽端口:8099");
// 等待客戶端的連接過來,如果沒有連接過來,就會阻塞
while (true) {
// 表示阻塞等待監聽一個客戶端連接,返回的socket表示連接的客戶端信息
Socket socket = serverSocket.accept(); //連接阻塞
System.out.println("客戶端:" + socket.getPort());
// 表示獲取客戶端的請求報文
new Thread(new Runnable() {
@Override
public void run() {
try {
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(socket.getInputStream())
);
String clientStr = bufferedReader.readLine();
System.out.println("收到客戶端發送的消息:" + clientStr);
BufferedWriter bufferedWriter = new BufferedWriter(
new OutputStreamWriter(socket.getOutputStream())
);
bufferedWriter.write("ok\\n");
bufferedWriter.flush();
} catch (Exception e) {
//...
}
}
}).start();
}
} catch (IOException e) {
// 錯誤處理
} finally {
// 其他處理
}
}
}
事情的順利進展不禁讓我們飄飄然,我們居然是使用高階的多線程技術解決了BIO的阻塞問題,雖然目前每個客戶端都需要一個單獨的線程來處理,但accept()總歸不會被readLine()卡死了。

BIO改造之后
所以我們改造完之后的程序是不是就是非阻塞IO了呢?
想多了。。。我們只是用了點奇技淫巧罷了,改造完的代碼在系統調用層面該阻塞的地方還是阻塞,說白了,Java提供的API完全受限于操作系統提供的系統調用,在Java語言級別沒能力改變底層BIO的事實!
Java沒這個能力!
3.6 掀開BIO的遮羞布
接下來帶大家看一下改造之后的BIO代碼在底層都調用了哪一些系統調用,讓我們在底層上對上文的內容加深一下理解。
給大家打個氣,接下來的內容其實非常好理解,大家跟著文章一步步地走,一定能看得懂,如果自己動手操作一遍,那就更好了。
對了,我下來使用的JDK版本是JDK8。
strace是Linux上的一個程序,該程序可以追蹤并記錄參數后邊運行的進程對內核進行了哪些系統調用。
strace -ff -o out java BIOServerSocketWithThread
其中:
-o:
將系統調用的追蹤信息輸出到out文件中,不加這個參數,默認會輸出到標準錯誤stderr。
-ff
如果指定了-o選項,strace會追蹤和程序相關的每一個進程的系統調用,并將信息輸出到以進程id為后綴的out文件中。舉個例子,比如BIOServerSocketWithThread程序運行過程中有一個ID為30792的進程,那么該進程的系統調用日志會輸出到out.30792這個文件中。
我們運行strace命令之后,生成了很多個out文件。

這么多進程怎么知道哪個是我們需要追蹤的呢?我就挑了一個容量最大的文件進行查看,也就是out.30792,事實上,這個文件也恰好是我們需要的,截取一下里邊的內容給大家看一下。

可以看到圖中的有非常多的行,說明我們寫的這么幾行代碼其實默默調用了非常多的系統調用,拋開細枝末節,看一下上圖中我重點標注的系統調用,是不是就是上文中我解釋過的函數?我再詳細解釋一下每一步,大家聯系上文,會對BIO的底層理解的更加通透。
- 生成監聽socket,并返回socket描述符
7,接下來對socket進行操作的函數都會有一個參數為7; - 將
8099端口綁定到監聽socket,bind的第一個參數就是7,說明就是對監聽socket進行的操作; listen()將監聽socket(參數為7)設置為被動接受連接的socket,并且將隊列的長度設置為50;- 實際上就是
System.out.println("啟動服務:監聽端口:8099");這一句的系統調用,只不過中文被編碼了,所以我特意把:8099圈出來證明一下;
額外說兩點:
其一:可以看到,這么一句簡單的打印輸出在底層實際調用了兩次
write系統調用,這就是為什么不推薦在生產環境下使用打印語句的原因,多少會影響系統性能;其二:
write()的第一個參數為1,也是文件描述符,表示的是標準輸出stdout。
- 系統調用阻塞在了
poll()函數,怎么看出來的阻塞?out文件的每一行運行完畢都會有一個= 返回值,而poll()目前沒有返回值,因此阻塞了。實際上poll()系統調用對應的Java語句就是serverSocket.accept();。
不對啊?為什么底層調用的不是accept()而是poll()?poll()應該是多路復用才是啊。在JDK4之前,底層確實直接調用的是accept(),但是之后的JDK對這一步進行了優化,除了調用accept(),還加上了poll()。poll()的細節我們下文再說,這里可以起碼證明了poll()函數依然是阻塞的,所以整個BIO的阻塞邏輯沒有改變。
接下來我們起一個客戶端對程序發起連接,直接用Linux上的nc程序即可,比較簡單:
nc localhost 8099
發起連接之后(但并未主動發送信息),out.30792的內容發生了變化:

poll()函數結束阻塞,程序接著調用accept()函數返回一個連接socket,該socket的描述符為8;- 就是
System.out.println("客戶端:" + socket.getPort());的底層調用; - 底層使用
clone()創造了一個新進程去處理連接socket,該進程的pid為31168,因此JDK8的線程在底層其實就是輕量級進程; - 回到
poll()函數繼續阻塞等待新客戶端連接。
由于創建了一個新的進程,因此在目錄下對多出一個out.31168的文件,我們看一下該文件的內容:

發現子進程阻塞在了recvfrom()這個系統調用上,對應的Java源碼就是bufferedReader.readLine();,直到客戶端主動給服務端發送消息,阻塞才會結束。
3.7 BIO總結
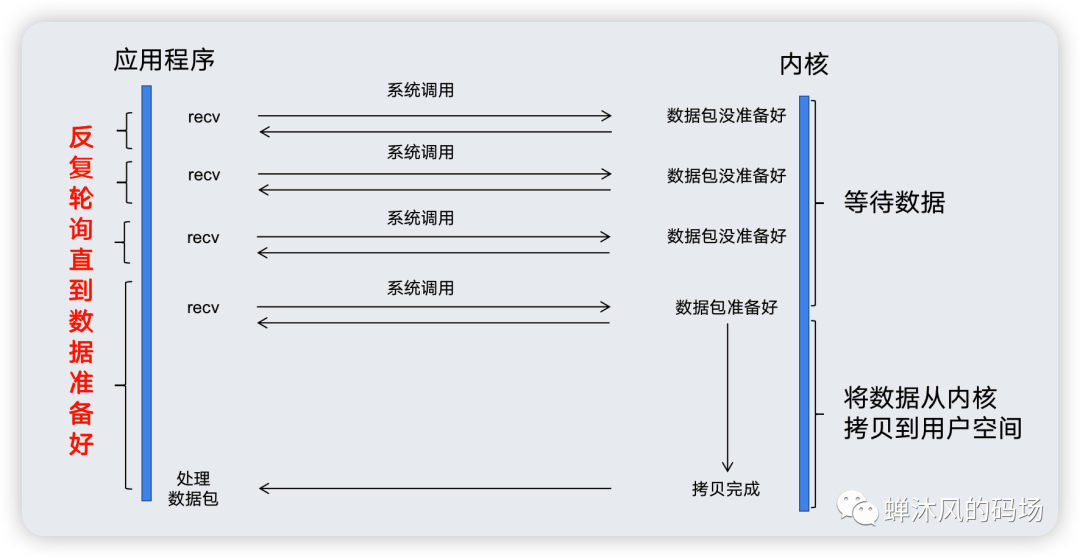
到此為止,我們就通過底層的系統調用證明了BIO在accept()以及readLine()上的阻塞。最后用一張圖來結束BIO之旅。

BIO模型
BIO之所以是BIO,是因為系統底層調用是阻塞的,上圖中的進程調用recv,其系統調用直到數據包準備好并且被復制到應用程序的緩沖區或者發生錯誤為止才會返回,在此整個期間,進程是被阻塞的,啥也干不了。
-
Socket
+關注
關注
0文章
212瀏覽量
34794 -
函數
+關注
關注
3文章
4344瀏覽量
62847 -
Redis
+關注
關注
0文章
377瀏覽量
10905
發布評論請先 登錄
相關推薦
小米5的那顆核心,究竟有多強
Redis Stream應用案例
定時器中斷類型探究 精選資料分享
華為榮耀Magic今日發布:“未來”手機究竟有多強?
ibm的2nm芯片究竟有多強 2nm芯片對續航的影響
Molex莫仕連接器的功能究竟有多強大?看他們的行業應用你就知道了!
探究Redis網絡模型究竟有多強大(上)





 工商網監
工商網監
評論