 從FPGA說起的深度學習
從FPGA說起的深度學習
這是新的系列教程,在本教程中,我們將介紹使用 FPGA 實現深度學習的技術,深度學習是近年來人工智能領域的熱門話題。
在本教程中,旨在加深對深度學習和 FPGA 的理解。
用 C/C++ 編寫深度學習推理代碼
高級綜合 (HLS) 將 C/C++ 代碼轉換為硬件描述語言
FPGA 運行驗證
在上一篇文章中,我們用C語言實現了一個卷積層,并查看了結果。在本文中,我們將實現其余未實現的層:全連接層、池化層和激活函數 ReLU。
每一層的實現
全連接層
全連接層是將輸入向量X乘以權重矩陣W,然后加上偏置B的過程。下面轉載第二篇的圖,能按照這個圖計算就可以了。
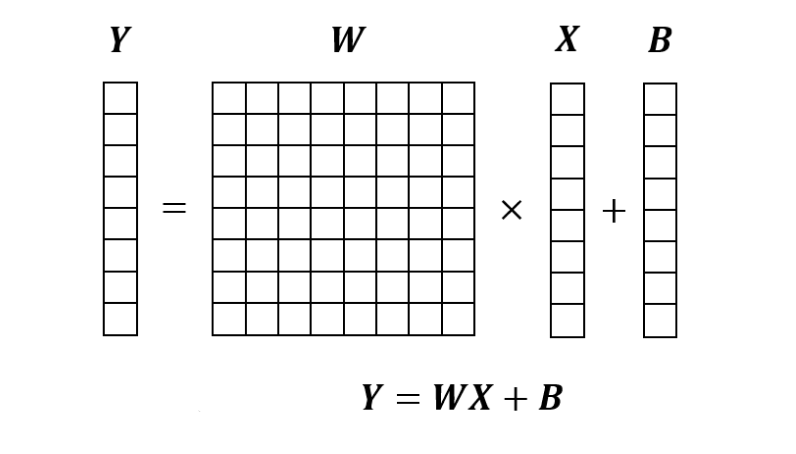
全連接層的實現如下。
voidlinear(constfloat*x,constfloat*weight,constfloat*bias, int64_tin_features,int64_tout_features,float*y){ for(int64_ti=0;i
該函數的接口和各個數據的內存布局如下。
考慮稍后設置 PyTorch 參數,內存布局與 PyTorch 對齊。
輸入
x: 輸入圖像。shape=(in_features)
weight: 權重因子。shape=(out_features, in_features)
bias: 偏置值。shape=(out_features)
輸出
y: 輸出圖像。shape=(out_features)
參數
in_features: 輸入順序
out_features: 輸出順序
在全連接層中,內部操作數最多為out_channels * in_channels一個,對于典型參數,操作數遠低于卷積層。
另一方面,關注權重因子,卷積層為shape=(out_channels, in_channels, ksize, ksize),而全連接層為shape=(out_features, in_features)。例如,如果層從卷積層變為全連接層,in_features = channels * width * height則以下關系成立。width, height >> ksize考慮到這一點,在很多情況下,全連接層參數的內存需求大大超過了卷積層。
由于FPGA內部有豐富的SRAM緩沖區,因此擅長處理內存訪問量大和內存數據相對于計算總量的大量復用。單個全連接層不會復用權重數據,但是在視頻處理等連續處理中,這是一個優勢,因為要進行多次全連接。
另一方面,本文標題中也提到的邊緣環境使用小型FPGA,因此可能會出現SRAM容量不足而需要訪問外部DRAM的情況。如果你有足夠的內存帶寬,你可以按原樣訪問它,但如果你沒有足夠的內存帶寬,你可以在參數調整和訓練后對模型應用稱為剪枝和量化的操作。
池化層
池化層是對輸入圖像進行縮小的過程,這次使用的方法叫做2×2 MaxPooling。在這個過程中,取輸入圖像2x2區域的最大值作為輸出圖像一個像素的值。這個看第二張圖也很容易理解,所以我再貼一遍。
即使在池化層,輸入圖像有多個通道,但池化過程本身是針對每個通道獨立執行的。因此,輸入圖像中的通道數和輸出圖像中的通道數在池化層中始終相等。
池化層的實現如下所示:
voidmaxpool2d(constfloat*x,int32_twidth,int32_theight,int32_tchannels,int32_tstride,float*y){ for(intch=0;ch
這個函數的接口是:
此實現省略了邊緣處理,因此圖像的寬度和高度都必須能被stride整除。
輸入
x: 輸入圖像。shape=(channels, height, width)
輸出
y: 輸出圖像。shape=(channels, height/stride, width/stride)
參數
width: 圖像寬度
height: 圖像高度
stride:減速比
ReLU
ReLU 非常簡單,因為它只是將負值設置為 0。
voidrelu(constfloat*x,int64_tsize,float*y){ for(int64_ti=0;i
由于每個元素的處理是完全獨立的,x, y因此未指定內存布局。
硬件生成
到這里為止的內容,各層的功能都已經完成了。按照上一篇文章中的步驟,可以確認這次創建的函數也產生了與 libtorch 相同的輸出。此外,Vivado HLS 生成了一個通過 RTL 仿真的電路。從這里開始,我將簡要說明實際生成了什么樣的電路。
如果將上述linear函數原樣輸入到 Vivado HLS,則會發生錯誤。這里,將輸入輸出設為指針->數組是為了決定在電路制作時用于訪問數組的地址的位寬。另外,in_features的值為778=392,out_將features的值固定為32。這是為了避免Vivado HLS 在循環次數可變時輸出性能不佳。
staticconststd::size_tkMaxSize=65536; voidlinear_hls(constfloatx[kMaxSize],constfloatweight[kMaxSize], constfloatbias[kMaxSize],floaty[kMaxSize]){ dnnk::linear(x,weight,bias,7*7*8,32,y); }
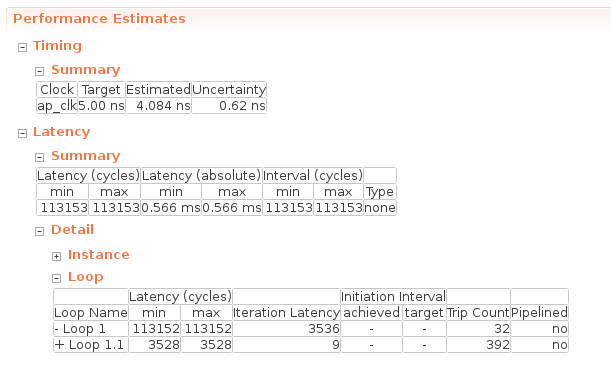
linear_hls函數的綜合報告中的“性能估計”如下所示:
在Timing -> Summary中寫入了綜合時指定的工作頻率,此時的工作頻率為5.00 ns = 200MHz。重要的是 Latency -> Summary 部分,它描述了執行此函數時的周期延遲(Latency(cycles))和實時延遲(Latency(absolute))。看看這個,我們可以看到這個全連接層在 0.566 ms內完成。
在 Latency -> Detail -> Loop 列中,描述了每個循環的一次迭代所需的循環次數(Iteration Latency)和該循環的迭代次數(Trip Count)。延遲(周期)包含Iteration Latency * Trip Count +循環初始化成本的值。Loop 1 是out_features循環到loop 1.1 in_features。在Loop1.1中進行sum += x[j] * weight[i * in_features + j]; 簡單計算會發現需要 9 個周期才能完成 Loop 1.1 所做的工作。
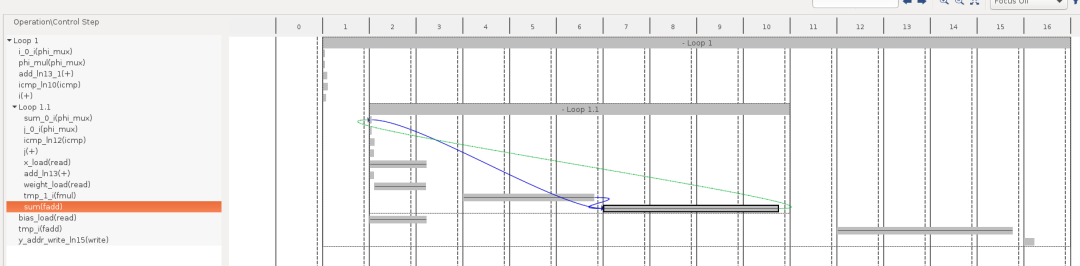
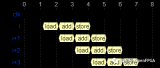
使用HLS中的“Schedule Viewer”功能,可以更詳細地了解哪些操作需要花費更多長時間。下圖橫軸的2~10表示Loop1.1的處理內容,大致分為x,weights等的加載2個循環,乘法(fmul)3個循環,加法(fadd)4個循環共計9個循環。
在使用 HLS 進行開發期間通過添加#pragma HLS pipeline指令,向此代碼添加優化指令以指示它創建高效的硬件。與普通的 FPGA 開發類似,運算單元的流水線化和并行化經常用于優化。通過這些優化,HLS 報告證實了加速:
流水線:減少迭代延遲(min=1)
并行化:減少行程次數,刪除循環
正如之前也說過幾次的那樣,這次的課程首先是以FPGA推理為目的,所以不會進行上述的優化。有興趣進行什么樣的優化的人,可以參考以下教程和文檔。
教程
https://github.com/Xilinx/HLS-Tiny-Tutorials
文檔
https://www.xilinx.com/support/documentation/sw_manuals/xilinx2019_2/ug902-vivado-high-level-synthesis.pdf
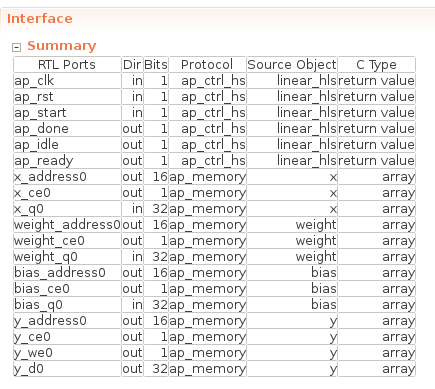
最后,該函數的接口如下所示。
由于本次沒有指定接口,所以數組接口如x_ 等ap_memory對應FPGA上可以1個周期讀寫的存儲器(BRAM/Distributed RAM)。在下一篇文章中,我們將連接每一層的輸入和輸出,但在這種情況下,我們計劃連接 FPGA 內部的存儲器作為每一層之間的接口,如本例所示。
總結
在本文中,我們實現了全連接層、池化層和 ReLU。現在我們已經實現了所有層,我們將在下一篇文章中組合它們。之后我們會實際給MNIST數據,確認我們可以做出正確的推論。
審核編輯:湯梓紅
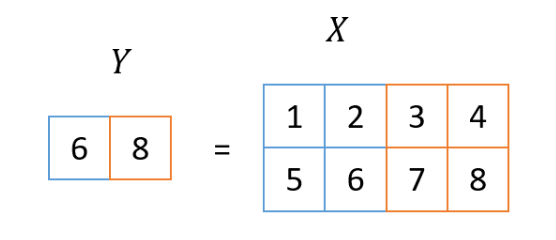
-
FPGA
+關注
關注
1629文章
21729瀏覽量
603009 -
C語言
+關注
關注
180文章
7604瀏覽量
136692 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238260 -
C++
+關注
關注
22文章
2108瀏覽量
73622 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:從FPGA說起的深度學習(四)
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
相比GPU和GPP,FPGA是深度學習的未來?
FPGA在深度學習應用中或將取代GPU
【詳解】FPGA:深度學習的未來?
為什么說FPGA是機器深度學習的未來?
什么是深度學習?使用FPGA進行深度學習的好處?
深度學習方案ASIC、FPGA、GPU比較 哪種更有潛力

FPGA在深度學習領域有哪些優勢?
從FPGA說起的深度學習:任務并行性
從FPGA說起的深度學習:數據并行性





 工商網監
工商網監
評論