 重建AST
重建AST
利用antlr完成了語法分析之后,就需要進行語義分析了。
詞法與語法分析相對固定,利用工具就可以完成,但語義分析則需要設計這么語言或者腳本的人員來完善它。
語義即語言最終需要表達的含義。
我們先來看一個自然語言例子,以我們熟悉的中文為例:我是程序猿!首先我們通過詞法分析工具將他拆分開:我,是,程序猿。通過語法分析將它建立成一個AST節點
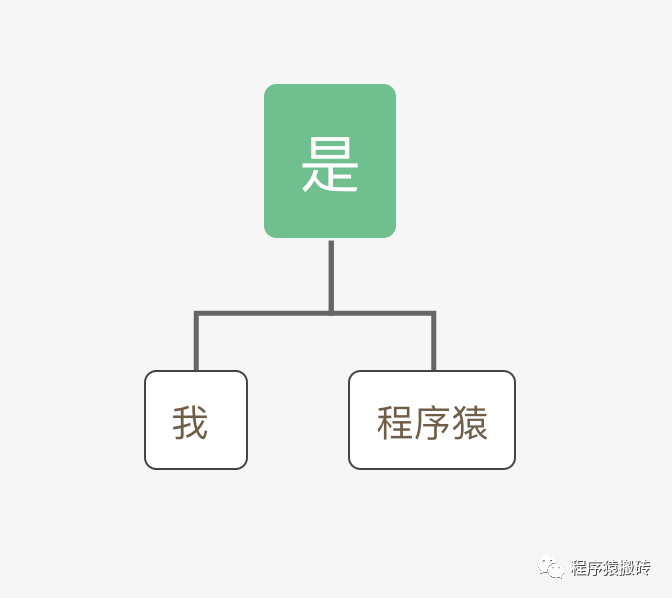
接下來我們通過兩種不能的算法將它運算一下看看會得到什么樣的結果。
第一種算法:左子節點+根節點+右子節點,運算結果是“我是程序猿”。
第二種算法:右子節點+根節點+左子節點,運算結果是“程序猿是我”。
可以得出,不同的運算規則得到的結果的含義是不一樣的,這也是為什么語義分析需要設計人員自己來實現了。但是我們不能隨意運算,運算也要符合規則。如果運算規則是:根節點+左子節點+右子節點則得出的結果就是錯誤的了。
從上面的自然語言例子不難得出,我們設計用于與計算機打交道的語言也是一樣的,計算機的目的是計算。
一元表達式,二元表達式,三元表達式他們都有一個根節點是計算符號,子節點是需要計算的表達式。
給這個節點賦予怎么樣的含義完成取決于設計這們語言的人。
我已經將第三節中的語法分析規則與詞法分析規則進行了完善:
「將原來的點取值改成了方括號取值,完善了小括號優先級語法。具體規則代碼如下:」
lexer grammar DynamicDSLLexer;
//關鍵字
If: 'if';
FOR: 'for';
WHILE: 'while';
IN: 'in';
/// 基礎數據類型
Int: 'int';
Double: 'double';
Float: 'float';
String: 'string';
Bool: 'bool';
//字面量
IntLiteral: [0-9]+;
DoubleLiteral: [0-9]+ Dot [0-9]+;
StringLiteral: ('"' .*? '"') | ('\\'' .*? '\\''); //字符串字面量
True: 'true';
False: 'false';
//操作符
AssignmentOP: '=';
RelationalOP: '>' | '>=' | '<' | '<=';
Star: '*';
Plus: '+';
Sharp: '#';
SemiColon: ';';
Dot: '.';
Comm: ',';
LeftBracket: '[';
RightBracket: ']';
LeftBrace: '{';
RightBrace: '}';
LeftParen: '(';
RightParen: ')';
//標識符
Id: [a-zA-Z_] ([a-zA-Z_] | [0-9])*;
//空白字符,拋棄
WS: [ \\t\\r\\n]+ -> skip;
grammar DynamicDSLScript;
import DynamicDSLLexer;
/// 表達式,按右邊產生式的順序來依次優先推導
expression:
primary
| LSB = '[' expression RSB = ']'
| expression LSB = '[' expression RSB = ']'
| LB = '(' expression RB = ')'
| expression LB = '(' expression RB = ')'
| FOR Id IN Id
| declare = (Int | Double | Float | String | Bool) Id assign = '=' expression // 申明變量并賦值
| declare = (Int | Double | Float | String | Bool) Id /// 申明變量,沒有賦值
| Id assign = '=' expression /// 賦值,需要查變量是否申明
| expression postfix = ('++' | '--')
| prefix = ('++' | '--') expression
| expression bop = ('*' | '/' | '%') expression
| expression bop = ('+' | '-') expression
| expression bop = ('<' | '<=' | '>' | '>=') expression
| expression bop = ('==' | '!=') expression
| expression bop = ('&&' | '||') expression
| expression bop = '?' expression bop = ':' expression;
primary:
Id
| StringLiteral
| IntLiteral
| DoubleLiteral
| TF = (True | False);
我們來看這樣一個例子: (3+5) *(123-5) / 2 + [object][age] 分的語法分析結果是這樣的:

這是antlr分析出來的結果,現在我們需要對這個分析結果進行重建,將antlr分析的AST重建成更容易理解與運算的AST。重建后的結果如下:

每一個節點都是我們在語法規則文件中定義的一種推導規則,要計算根節點,就必須先計算子節點,通過遞歸的方式從子節點到根節點運算的過程就是:深度優先遍歷。通過對這個AST進行深度優先遍歷,得到最終的運算符。
A:加減乘除運算就是將左右的結果作對應的運算
B: []取舍則是將先取值運算的作為后取值運算的子節點,所以它的推導式是這樣的:
| LSB = '[' expression RSB = ']'
| expression LSB = '[' expression RSB = ']'
首先嘗試推導是否是一個獨立的[]運算,比如這樣[object]。
我們在這里賦予它的含義是,從棧幀上下文中去尋找名稱為object的變量,并取出它的值。
如果是連續的[]運算,比如[object][age]則我們使用上面的第一條推導式發現推導是失敗的,
接著嘗試第二條推導式,首先將[age]推導出來成為一個節點,接著[object]繼續重新按第一條再次推導,發現推導成功,再將這個節點作用[age]推導出來的子節點。
在求值的時候就會優先求子節點[object]得到的結果作為[age]節點的上下文變量環境繼續尋找名稱是age的變量的值。
Antlr的語法推導是按定義的順序進行推導的,首先推導定義在前面的規則,推導失敗再繼續推導后面的規則。
推導成功立即建立一個AST節點,推導未完成的部分繼續進行推導并成功后變成此節點的子節點。
每增加一種推導規則我們就增加一種運算節點。
接下來,我們將利用C++來完成對AST的節點實現,實現一個簡單的節點與數據類型模型。完成AST的C++實現與運算。
如果你覺得有用,請分享給更多的人。
-
語義
+關注
關注
0文章
21瀏覽量
8691 -
ANTLR
+關注
關注
0文章
3瀏覽量
5770 -
語法分析
+關注
關注
0文章
2瀏覽量
1009
發布評論請先 登錄
相關推薦
2009伊拉克重建展
2010黎巴嫩重建展|黎巴嫩重建工程展|黎巴嫩重建展
2011伊拉克重建展
AST3TQ評估板旨在促進AST3TQ系列TCXO和VCTCXO的電氣性能測試
ASMT-JR30-AST01 3W迷你大功率LED

ASMT-AR30-AST00 3W大功率LED

ASMT-AR00-AST00 1W大功率LED

ASMT-AR00-AST01 1W大功率LED

ASMT-JR10-AST01 1W迷你大功率LED







 工商網監
工商網監
評論