") 你會從哪些維度進(jìn)行MySQL性能優(yōu)化?1
你會從哪些維度進(jìn)行MySQL性能優(yōu)化?1
你會從哪些維度進(jìn)行MySQL性能優(yōu)化?你會怎么回答?
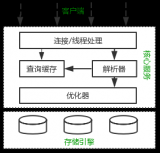
所謂的性能優(yōu)化,一般針對的是MySQL查詢的優(yōu)化。既然是優(yōu)化查詢,我們自然要先知道查詢操作要經(jīng)過哪些環(huán)節(jié),然后思考可以在哪些環(huán)節(jié)進(jìn)行優(yōu)化。
下面從5個(gè)角度介紹一下MySQL優(yōu)化的一些策略。
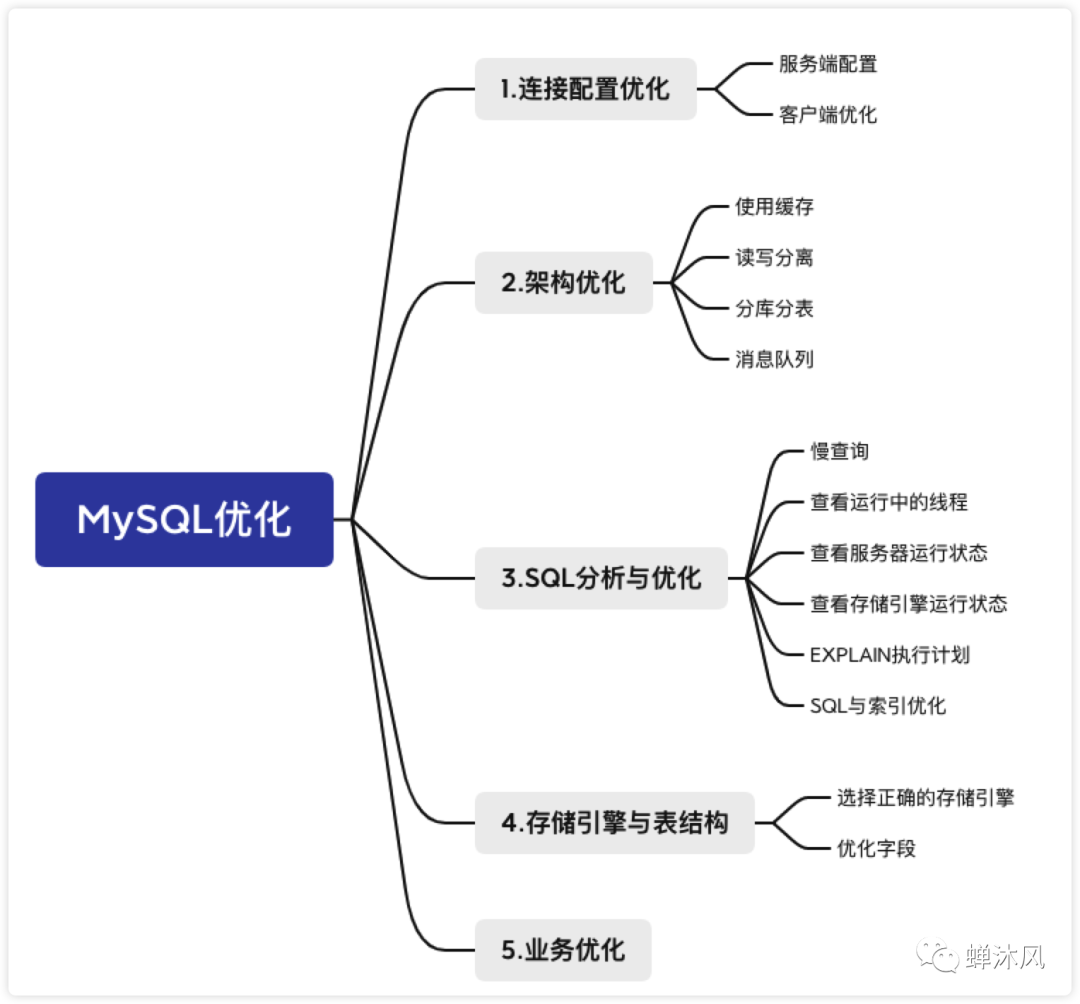
image-20220405204100602
1. 連接配置優(yōu)化
處理連接是MySQL客戶端和MySQL服務(wù)端親熱的第一步,第一步都邁不好,也就別談后來的故事了。
既然連接是雙方的事情,我們自然從服務(wù)端和客戶端兩個(gè)方面來進(jìn)行優(yōu)化嘍。
1.1 服務(wù)端配置
服務(wù)端需要做的就是盡可能地多接受客戶端的連接,或許你遇到過error 1040: Too many connections的錯(cuò)誤?就是服務(wù)端的胸懷不夠?qū)拸V導(dǎo)致的,格局太小!
我們可以從兩個(gè)方面解決連接數(shù)不夠的問題:
- 增加可用連接數(shù),修改環(huán)境變量
max_connections,默認(rèn)情況下服務(wù)端的最大連接數(shù)為151個(gè)
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
1 row in set (0.01 sec)
- 及時(shí)釋放不活動的連接,系統(tǒng)默認(rèn)的客戶端超時(shí)時(shí)間是28800秒(8小時(shí)),我們可以把這個(gè)值調(diào)小一點(diǎn)
mysql> show variables like 'wait_timeout';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set (0.01 sec)
MySQL有非常多的配置參數(shù),并且大部分參數(shù)都提供了默認(rèn)值,默認(rèn)值是MySQL作者經(jīng)過精心設(shè)計(jì)的,完全可以滿足大部分情況的需求,不建議在不清楚參數(shù)含義的情況下貿(mào)然修改。
1.2 客戶端優(yōu)化
客戶端能做的就是盡量減少和服務(wù)端建立連接的次數(shù),已經(jīng)建立的連接能湊合用就湊合用,別每次執(zhí)行個(gè)SQL語句都創(chuàng)建個(gè)新連接,服務(wù)端和客戶端的資源都吃不消啊。
解決的方案就是使用連接池來復(fù)用連接。
常見的數(shù)據(jù)庫連接池有DBCP、C3P0、阿里的Druid、Hikari,前兩者用得很少了,后兩者目前如日中天。
但是需要注意的是連接池并不是越大越好,比如Druid的默認(rèn)最大連接池大小是8,Hikari默認(rèn)最大連接池大小是10,盲目地加大連接池的大小,系統(tǒng)執(zhí)行效率反而有可能降低。為什么?
對于每一個(gè)連接,服務(wù)端會創(chuàng)建一個(gè)單獨(dú)的線程去處理,連接數(shù)越多,服務(wù)端創(chuàng)建的線程自然也就越多。而線程數(shù)超過CPU個(gè)數(shù)的情況下,CPU勢必要通過分配時(shí)間片的方式進(jìn)行線程的上下文切換,頻繁的上下文切換會造成很大的性能開銷。
Hikari官方給出了一個(gè)PostgreSQL數(shù)據(jù)庫連接池大小的建議值公式,CPU核心數(shù)*2+1。假設(shè)服務(wù)器的CPU核心數(shù)是4,把連接池設(shè)置成9就可以了。這種公式在一定程度上對其他數(shù)據(jù)庫也是適用的,大家面試的時(shí)候可以吹一吹。
2. 架構(gòu)優(yōu)化
2.1 使用緩存
系統(tǒng)中難免會出現(xiàn)一些比較慢的查詢,這些查詢要么是數(shù)據(jù)量大,要么是查詢復(fù)雜(關(guān)聯(lián)的表多或者是計(jì)算復(fù)雜),使得查詢會長時(shí)間占用連接。
如果這種數(shù)據(jù)的實(shí)效性不是特別強(qiáng)(不是每時(shí)每刻都會變化,例如每日報(bào)表),我們可以把此類數(shù)據(jù)放入緩存系統(tǒng)中,在數(shù)據(jù)的緩存有效期內(nèi),直接從緩存系統(tǒng)中獲取數(shù)據(jù),這樣就可以減輕數(shù)據(jù)庫的壓力并提升查詢效率。

緩存的使用
2.2 讀寫分離(集群、主從復(fù)制)
項(xiàng)目的初期,數(shù)據(jù)庫通常都是運(yùn)行在一臺服務(wù)器上的,用戶的所有讀寫請求會直接作用到這臺數(shù)據(jù)庫服務(wù)器,單臺服務(wù)器承擔(dān)的并發(fā)量畢竟是有限的。
針對這個(gè)問題,我們可以同時(shí)使用多臺數(shù)據(jù)庫服務(wù)器,將其中一臺設(shè)置為為小組長,稱之為master節(jié)點(diǎn),其余節(jié)點(diǎn)作為組員,叫做slave。用戶寫數(shù)據(jù)只往master節(jié)點(diǎn)寫,而讀的請求分?jǐn)偟礁鱾€(gè)slave節(jié)點(diǎn)上。這個(gè)方案叫做 讀寫分離 。給組長加上組員組成的小團(tuán)體起個(gè)名字,叫 集群 。

這就是集群
注:很多開發(fā)者不滿
master-slave這種具有侵犯性的詞匯(因?yàn)樗麄冋J(rèn)為會聯(lián)想到種族歧視、黑人奴隸等),所以發(fā)起了一項(xiàng)更名運(yùn)動。受此影響MySQL也會逐漸停用
master、slave等術(shù)語,轉(zhuǎn)而用source和replica替代,大家碰到的時(shí)候明白即可。
使用集群必然面臨一個(gè)問題,就是多個(gè)節(jié)點(diǎn)之間怎么保持?jǐn)?shù)據(jù)的一致性。畢竟寫請求只往master節(jié)點(diǎn)上發(fā)送了,只有master節(jié)點(diǎn)的數(shù)據(jù)是最新數(shù)據(jù),怎么把對master節(jié)點(diǎn)的寫操作也同步到各個(gè)slave節(jié)點(diǎn)上呢?
主從復(fù)制技術(shù)來了!我在一條SQL更新語句是如何執(zhí)行的?中粗淺地介紹了一下binlog日志,我直接搬過來了。
binlog是實(shí)現(xiàn)MySQL主從復(fù)制功能的核心組件。master節(jié)點(diǎn)會將所有的寫操作記錄到binlog中,slave節(jié)點(diǎn)會有專門的I/O線程讀取master節(jié)點(diǎn)的binlog,將寫操作同步到當(dāng)前所在的slave節(jié)點(diǎn)。

主從復(fù)制
這種集群的架構(gòu)對減輕主數(shù)據(jù)庫服務(wù)器的壓力有非常好的效果,但是隨著業(yè)務(wù)數(shù)據(jù)越來越多,如果某張表的數(shù)據(jù)量急劇增加,單表的查詢性能就會大幅下降,而這個(gè)問題是讀寫分離也無法解決的,畢竟所有節(jié)點(diǎn)存放的是一模一樣的數(shù)據(jù)啊,單表查詢性能差,說的自然也是所有節(jié)點(diǎn)性能都差。
這時(shí)我們可以把單個(gè)節(jié)點(diǎn)的數(shù)據(jù)分散到多個(gè)節(jié)點(diǎn)上進(jìn)行存儲,這就是 分庫分表 。
2.3 分庫分表
分庫分表中的節(jié)點(diǎn)的含義比較寬泛,要是把數(shù)據(jù)庫作為節(jié)點(diǎn),那就是分庫;如果把單張表作為節(jié)點(diǎn),那就是分表。
大家都知道分庫分表分成垂直分庫、垂直分表、水平分庫和水平分表,但是每次都記不住這些概念,我就給大家詳細(xì)說一說,幫助大家理解。
2.3.1 垂直分庫

垂直分庫
在單體數(shù)據(jù)庫的基礎(chǔ)上垂直切幾刀,按照業(yè)務(wù)邏輯拆分成不同的數(shù)據(jù)庫,這就是垂直分庫啦。

垂直分庫
2.3.2 垂直分表

垂直分表
垂直分表就是在單表的基礎(chǔ)上垂直切一刀(或幾刀),將一個(gè)表的多個(gè)字短拆成若干個(gè)小表,這種操作需要根據(jù)具體業(yè)務(wù)來進(jìn)行判斷,通常會把經(jīng)常使用的字段(熱字段)分成一個(gè)表,不經(jīng)常使用或者不立即使用的字段(冷字段)分成一個(gè)表,提升查詢速度。

垂直分表
拿上圖舉例:通常情況下商品的詳情信息都比較長,而且查看商品列表時(shí)往往不需要立即展示商品詳情(一般都是點(diǎn)擊詳情按鈕才會進(jìn)行顯示),而是會將商品更重要的信息(價(jià)格等)展示出來,按照這個(gè)業(yè)務(wù)邏輯,我們將原來的商品表做了垂直分表。
2.3.3 水平分表
把單張表的數(shù)據(jù)按照一定的規(guī)則(行話叫分片規(guī)則)保存到多個(gè)數(shù)據(jù)表上,橫著給數(shù)據(jù)表來一刀(或幾刀),就是水平分表了。

水平分表

水平分表
2.3.4 水平分庫
水平分庫就是對單個(gè)數(shù)據(jù)庫水平切一刀,往往伴隨著水平分表。

水平分庫

水平分庫
2.3.5 總結(jié)
水平分,主要是為了解決存儲的瓶頸;垂直分,主要是為了減輕并發(fā)壓力。
2.4 消息隊(duì)列削峰
通常情況下,用戶的請求會直接訪問數(shù)據(jù)庫,如果同一時(shí)刻在線用戶數(shù)量非常龐大,極有可能壓垮數(shù)據(jù)庫(參考明星出軌或公布戀情時(shí)微博的狀態(tài))。
這種情況下可以通過使用消息隊(duì)列降低數(shù)據(jù)庫的壓力,不管同時(shí)有多少個(gè)用戶請求,先存入消息隊(duì)列,然后系統(tǒng)有條不紊地從消息隊(duì)列中消費(fèi)請求。

隊(duì)列削峰
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7004瀏覽量
88944 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9124瀏覽量
85331 -
MySQL
+關(guān)注
關(guān)注
1文章
804瀏覽量
26531 -
服務(wù)端
+關(guān)注
關(guān)注
0文章
66瀏覽量
7004
發(fā)布評論請先 登錄
相關(guān)推薦
MySQL的執(zhí)行過程 SQL語句性能優(yōu)化常用策略
MySQL性能優(yōu)化淺析及線上案例
MySQL優(yōu)化之查詢性能優(yōu)化之查詢優(yōu)化器的局限性與提示

幫助優(yōu)化MySQL數(shù)據(jù)庫性能的7個(gè)技巧
詳解MySQL的查詢優(yōu)化 MySQL邏輯架構(gòu)分析
MySQL數(shù)據(jù)庫:理解MySQL的性能優(yōu)化、優(yōu)化查詢

MySQL索引的使用問題
利用MySQL進(jìn)行一主一從的主從復(fù)制
如何將數(shù)據(jù)從MySQL遷移到Influxdb中
MySQL性能優(yōu)化方法
MySQL執(zhí)行過程:如何進(jìn)行sql 優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論