 實現無線監控網絡100%的可靠性
實現無線監控網絡100%的可靠性
高端端到端可靠性是那些具有關鍵監控和驅動要求的人所要求的質量。迄今為止,無線傳感器網絡(WSN)用戶通常認為次優可靠性是無線技術固有的。我們描述了一個集中監控TDMA網絡,其策略選擇以最大化接收的數據包數量,同時保持低功耗特性。介紹了檢測和診斷數據包丟失的方法以及其相對影響的預期邊界。該診斷允許對所有已知的損失機制進行編目,并分析以50.99%穩態端到端可靠性運行的99節點網絡中的損失。
介紹
無線監控網絡是一種 WSN,其中數據在所有網絡節點上定期生成,并通過稱為管理器的單個節點上的多跳傳輸收集。知道節點數和生成速率可以計算預期的數據包數:讓可靠性是一個無單位的數量,描述管理器接收的唯一數據包數除以應接收的唯一數據包數。WSN的學術研究旨在提供最佳解決方案:最低能源成本,最低延遲或最高帶寬。雖然這些元素對工業和商業WSN用戶很重要,但他們主要關心的通常是網絡中生成的數據包應該在集中式數據存儲庫中可靠地接收并可用于分析。網絡上的實際壓力通常不會那么高:例如,一個 50 節點網絡,每個節點每分鐘使用 10.76 kbps 無線電收發器生成 8 字節的數據有效載荷。此網絡使用的原始可用帶寬不到管理器的 0.1%。許多研究人員回避研究這些微不足道的要求也就不足為奇了。但是,即使在大量預配的方案中,也很難滿足嚴格的可靠性要求。所介紹的時間同步協議提供了一種高可靠性的無線網絡解決方案,該解決方案還支持低功耗路由和高可用帶寬。激勵目標不一定是獲得完美的可靠性,而是了解每個丟失數據包的原因并能夠綁定每個丟失機制。
在歷史有線域中安裝 WSN5將低可靠性確定為采用該技術的主要風險之一。可靠性指標通常在處理WSN部署的系統論文中討論,但很少是主要關注點。ExScal等項目2不斷擴展 WSN 大小和整體性能的限制。這項特殊的工作引用了86%的端到端可靠性,并暗示缺乏關于困擾可靠運行的故障和可變性的公開數據。另一個自稱“工業傳感器網絡”的項目7評論可靠性的重要性,但指出實驗中的大多數節點報告了超過80%的數據,表明整體可靠性遠未接近100%的范圍。很明顯,這些作者認識到可靠性在商業應用中的重要性,但同樣清楚的是,單個數據包的丟失并不是最重要的問題。一個揭示性的情節3顯示了節點編號/生命周期空間中已發布網絡的跨度,但沒有直接評論這些網絡的可靠性。到目前為止,網絡在給定的時間跨度內保持運行就足夠了,并不是說網絡一定能夠在這段時間內進行可靠的數據包交付。工作的含義4它試圖使用網絡來檢測“罕見,隨機和短暫的事件”,即網絡必須準備好感知消失的微小時間和空間區域。這一原則的延續表明,由于如此簡短但重要的事件而生成的單個數據包應保持相同的高標準。
最近的新平臺和系統6,8專注于從第一原則重新設計 WSN,但沒有提供近乎完美的可靠性的明確目標。對更廣泛的無線網狀網絡領域的調查1僅簡要提到了可靠性的主題,這表明即使在傳感器網絡領域之外,無線多跳也沒有專注于這一目標。
無線網絡
眾所周知,無線信道隨時間和空間而變化。為了克服這一挑戰,我們使用多種技術和策略來最大限度地提高可靠性:
TDMA 調度以確保足夠的帶寬
網狀拓撲提供冗余路由
刪除消息前所需的 ACK
跳頻以避免阻塞通道
優化拓撲以選擇更好的路線
高功率模式可恢復斷開連接的節點
一致使用可靠性診斷
該網絡由無線節點和選定節點對之間的重復定向TDMA通信插槽組成。每個這樣的節點對定義一個路徑,并且可以由一個TDMA超幀中的一個或多個插槽組成。每次傳輸和接收都經過安排,因此網絡流量不會發生沖突。此選擇考慮了低功耗,但它也允許比基于爭用的協議更好的擁塞可靠性。在 TDMA 計劃中為每個節點分配足夠數量的插槽,以滿足自身和后代預期的最大帶寬需求。這里需要“監控網絡”假設:很難充分配置具有未知流量需求的網絡。TDMA網絡需要嚴格的時間同步,這帶來了一系列挑戰。
通過構建網絡,使管理器沒有父級,并且路徑集合生成的二合字母中不允許循環,流量向上流向管理器。隨著每個節點尋找兩個父節點,生成的網狀結構最大限度地減少了由于單路徑故障而導致的數據包丟失。管理器-節點控制通信是通過沿相反方向的相同路徑的廣播泛洪來實現的。TDMA協議的細節對于本次討論并不重要;重要的是安排足夠的帶寬,以盡量減少意外擁塞或來自外部來源的干擾的影響。高可靠性網絡在帶寬方面過度配置,唯一的代價是額外的空閑偵聽槽。這允許隊列在大多數網絡操作中保持空。在發射端,僅當有數據包等待發送時,才會激活無線電,因此空閑插槽沒有能源成本。但是,在傳輸的情況下,接收器必須始終在插槽開始時偵聽一小段時間,因此分配的帶寬越多,消耗的能量就越多。由于一些流量沿著次優路由傳輸到管理器,網狀網絡可能會支付前期延遲和能量損失,但這些成本可確保不可避免的路徑穩定性變化導致連接損失很少。
我們的網絡范式是,一旦生成數據包,就永遠不應該丟棄它,而應該逐節點拓撲地傳遞到更接近管理器的位置。管理器是一個中央數據存儲庫,所有數據包都路由到該存儲庫,并且通常連接到用戶可訪問的數據庫。多跳傳播是通過一系列握手完成的:在收到來自父級的 ACK 之前,不會從子級中刪除數據包。這要求每個節點上都有一個大小合理的數據包隊列。當隊列填滿時,節點無法再存儲新生成的本地數據,并開始丟失這些數據包。在這種情況下,完整隊列不會導致外部數據包丟失,因為節點會從其子節點接收來自其子級的消息。
為了克服可能對可靠性產生不利影響的本地窄帶干擾,我們的網絡在空間和時間上將通信傳播到多個通道上。傳輸在 50MHz 頻段跳躍超過 900 個通道,在 16.2GHz 頻段中跳躍超過 4 個通道。如果一個或某些信道存在干擾,則在隨后嘗試使用其他信道時,傳輸仍可成功。同樣,帶寬的過度配置允許網絡即使在信道阻塞的情況下也能保持高可靠性。跳頻會導致更長的加入時間,因為新節點必須掃描多個信道才能找到其對等節點,但動態無線電環境中的長期可靠性有利于多信道策略。
網絡架構有助于在網絡形成和運行過程中進行路徑優化。管理器不斷尋找重定向網絡圖的方法,以確保可靠性最大化。優化評分基于路徑質量(經驗測量或 RSSI)、管理器的躍點數和父級的生存期。這使我們能夠持續確保網絡使用最佳可用路由來存儲數據。
網絡可以在低功耗或高功率模式下運行。在網絡形成期間和連接斷開后,網絡會自動切換到高功率模式,以方便和加快節點加入。網絡外部節點花費的時間是數據包丟失的時間;為了盡量減少丟失的數據包,需要花費更多精力來盡快恢復丟失的節點。
最后,正如下一節將詳細描述的那樣,我們始終采用幾種獨立的診斷方法來跟蹤丟失的數據包。隨著可靠性水平的提高,丟失的數據包變得更加難以跟蹤,并且在短時間實驗中無法跟蹤特別罕見的事件。因此,在所有運行網絡上使用診斷工具提供了發現所有丟失機制的最大機會。
識別丟失的數據包
在我們的網絡中,通過比較兩個獨立的數據包計數來識別丟失的數據包:來自每個節點的定期診斷數據包和管理器接收的唯一數據包列表。診斷數據包通知管理器在最近的收集間隔內源自節點的數據包數,以及由于消息緩沖區已滿而丟棄的本地生成的數據包數。目標是能夠一致地跟蹤丟失的數據包數量以及每次丟失的原因。除了這些方法之外,我們還使用直接有線和無線節點查詢、網絡模擬和節點仿真來確定數據包丟失的來源。根據標準網絡操作期間可用的數據,我們可以將任何丟失的數據包分為以下幾類:
擁塞
設備重置
設備故障
CRC腐敗
會計差錯
未知
擁塞丟失由診斷數據包中的節點直接報告,因此最容易跟蹤。但是,持續的擁塞會導致診斷數據包被中止以阻止進一步的丟失,因此當節點 n 的診斷數據包未到達的時間間隔內,節點 n 的管理器報告為丟失的數據包被假定為擁塞丟失。節點 n 只能由于擁塞而丟失自己的消息;節點在其消息緩沖區已滿時 NACK 子節點。這不會改變進入網絡的每個數據包都保持安全的概念,而是顯示了如何防止某些預期的數據包進入網絡。
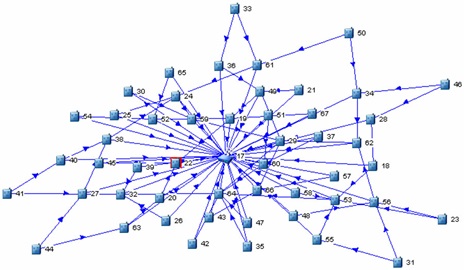
圖1.顯示測試部署中的子父關系的網絡圖。
節點在失去與所有父節點的連接時會重置其軟件。這會導致節點丟失其隊列中的所有數據包,其中可能包括來自其他節點的數據包。管理中心通過節點的父節點和子節點生成的警報數據包以及節點重新加入網絡的請求來檢測重置事件。在已知節點已脫離網絡的時間間隔內丟失的數據包被假定為由于此重置節點造成的,無論其初始來源如何。同樣,需要一些維護(例如更換電池)的設備故障最初可能導致來自多個來源的丟失,但隨著時間的推移,只有來自故障節點的數據包會丟失。
所有消息都附加一個 16 位 CRC,以確保鏈路級完整性。但是,對于較長的數據包,此 CRC 不是唯一的,某些錯誤組合可能導致錯誤百出的數據包與無錯誤數據包具有相同的 CRC。但是,使用另一個端到端加密 MIC,因此在解密時會在管理器上檢測到錯誤(但無法糾正)。
已經發現并修復了會計錯誤的幾個迭代,并且不能保證沒有保留。我們假設數據包在管理器報告之前丟失,因此所有錯誤都是誤報丟失。盡管如此,仍然無法區分會計錯誤和丟失的數據包,因此必須始終假設最壞的情況。最大的麻煩來自數據包序列,這些數據包順序嚴重混亂,跨越不同的 15 分鐘間隔。在本研究中,保留了所有傳入消息的獨立跟蹤,以確定自動分析中是否存在任何會計錯誤。
一年前,這份損失機制清單大不相同。有些問題解決了,有些問題被發現了。隨著可靠性、網絡規模和流量水平的不斷提高,將揭示更多隱蔽和隱蔽的損失。當 10-6 水平損失普遍存在時,在 10-3 水平上考慮的因素是不可見的。同樣,這強調了能夠解釋已知丟失類型的每個丟失數據包的必要性。正如下一節將看到的,測試網絡中數據包丟失的當前主要形式是通過未識別的機制。我們推測這是由于對同一無線電空間中其他不同步網絡的邏輯干擾。
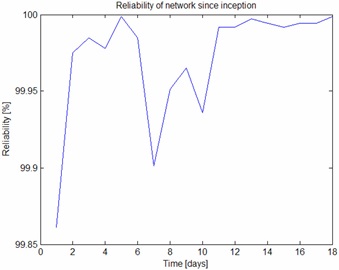
圖2.網絡生命周期內的日常可靠性。
案例研究:50 節點網絡
作為可達到的可靠性水平的一個例子,在我們的辦公樓內和周圍部署了一個 50 節點的監控網絡。節點放置在我們工作空間內和屋頂頂部的兩個垂直水平上。該網絡旨在以非常高的可靠性運行,同時具有較低的節點間通道穩定性;為每個節點選擇 1 分鐘報告速率,以最大程度地減少數據包因擁塞而丟失的可能性。該網絡每天生成 72,000 個數據包,每個數據包平均通過 2.0 個躍點進行無線傳輸。距離管理器最遠的節點平均每個數據包 3.6 個躍點。
網絡正在運行 199 個插槽(6.2 秒)的 TDMA 超幀。網絡二合圖如圖1所示。在運行的第一天,可靠性為99.86%,但觀察到整整一周至少99.99%的可靠性。無需人工干預的 17 天的可靠性數據如圖 2 所示。
當節點位于不同的垂直平面上時,平均路徑穩定性相當低,為 60%,這意味著十分之四的傳輸嘗試失敗并重試。選擇低路徑穩定性是為了鼓勵所有可能的誤差類別在網絡中顯現出來。所有節點都是相同的 - 沒有一個被區分為“路由器”節點 - 并且都使用相同的AA電池運行。網絡一對 AA 電池的最短節點壽命為 13 個月。網絡生命周期內的平均數據包延遲為 3.9 秒。該網絡在下雨期間運行,屋頂節點測量的地表溫度已超過70攝氏度。
表 1 總結了截至撰寫本文之日所有丟失數據包的性質。丟失的數據包總數為 367 個,已收到 1 萬個唯一數據包。
| Loss Mechanism | Number of Packets | Loss Rate |
| Node Reset | 265 | 2x10-4 |
| Unknown | 71 | 6x10-5 |
| Congestion | 26 | 2x10-5 |
| CRC Failure | 5 | 4x10-6 |
| Failed Device | 0 | 0 |
| Accounting | 0 | 0 |
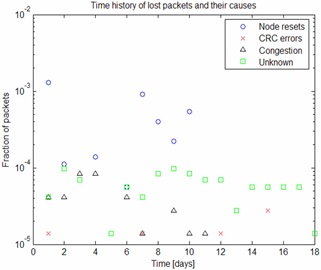
圖3.網絡生命周期內每日數據包丟失的機制。
圖3顯示了對損失機制的進一步基于日期的分析。在最近一周的運行中,沒有數據包因節點重置或擁塞而丟失。這是由于網絡中運行的優化例程 - 拓撲已經過優化,通過確保使用的所有路徑都具有足夠高的穩定性以確保可靠運行,幾乎消除了數據包丟失的這些組件。在所有這些過程中,會創建單個路徑并失敗,但由于網狀架構,這不一定會導致數據包丟失。
大多數節點重置事件發生在網絡形成和優化過程中;預計在穩態操作期間,這些損失的頻率將大大降低。未知和CRC故障的數量應該繼續以目前的速度進行,我們預計網絡將繼續以99.99%的可靠性報告數據,至少在未來13個月內。
結論和今后的工作
擬議的基于TDMA的WSN策略允許低功耗50節點網絡以99.99%的穩定可靠性水平運行,而無需人工干預。這種可靠性水平是通過圍繞將每個數據包交付給集中式管理器的目標對整個系統進行精心設計來實現的。對協議的更改可能會導致網絡丟失低于 10-4 個數據包,包括在加入期間,方法是在重置期間保留隊列內容并增加隊列長度以消除擁塞損失。
展望未來,目標是確定來源并減少未知損失的數量。這些誤差的大小足夠高,以至于CRC類型的誤差相對來說很少受到關注。進一步的發現將通過更廣泛地使用有線連接直接監控單個節點對來實現。網絡沒有出現任何節點故障,但這種可靠性水平要求故障是可預測的(例如通過電池監控)或極其罕見。在 99.9% 的可靠性水平下,我們可以承受大約 1/10000 的故障停機時間。如果每次故障更換需要一天時間,我們需要設備故障發生的頻率低于每 27 年一次。
雖然測試網絡僅由 50 個節點組成,但該協議可擴展到更大的網絡,并且具有類似的每個節點的可靠性。對于監控網絡,必須相應地調整報告速率,以確保擁塞級別不會增加,但協議沒有根本性的變化。在修復一些錯誤之前,我們已經運行了 250 個節點的網絡,持續時間超過 99 個月,可靠性為 ><>%。如果節點可以保持在同一級別連接,則操作的其余部分是相同的,并且應該導致相同的損失分數。
審核編輯:郭婷
-
嵌入式
+關注
關注
5082文章
19104瀏覽量
304817 -
接收器
+關注
關注
14文章
2468瀏覽量
71873 -
無線傳感器
+關注
關注
15文章
770瀏覽量
98350
發布評論請先 登錄
相關推薦










 工商網監
工商網監
評論