 CeresDB 1.0正式發布,Rust高性能云原生時序數據庫
CeresDB 1.0正式發布,Rust高性能云原生時序數據庫
CeresDB 是一款高性能、分布式的云原生時序數據庫,采用 Rust 編寫。其開發團隊近日宣布:經過近一年的開源研發工作,時序數據庫 CeresDB 1.0 正式發布,達到生產可用標準。
CeresDB 1.0 官方中文文檔:https://docs.ceresdb.io/cn/CeresDB 1.0 核心特性介紹
存儲引擎- 支持列式混合存儲
- 高效 XOR 過濾器
- 實現了計算存儲分離(支持 OSS 作為數據存儲,WAL 實現支持 OBKV、Kafka)
- 支持 HASH 分區表
- 支持單機部署
- 支持分布式集群部署
- 支持 Prometheus + Grafana 搭建自監控
- 支持 SQL 查詢與寫入
- 實現了 CeresDB 內置高性能讀寫協議,提供多語言 SDK
- 支持 Prometheus,可以作為 Prometheus 的 remote storage 進行使用
CeresDB 架構介紹
CeresDB 是一個時序數據庫,與經典時序數據庫相比,CeresDB 的目標是能夠同時處理時序型和分析型兩種模式的數據,并提供高效的讀寫。在經典的時序數據庫中,Tag列(InfluxDB稱之為Tag,Prometheus稱之為Label)通常會對其生成倒排索引,但在實際使用中,Tag的基數在不同的場景中是不一樣的 ———— 在某些場景下,Tag的基數非常高(這種場景下的數據,我們稱之為分析型數據),而基于倒排索引的讀寫要為此付出很高的代價。而另一方面,分析型數據庫常用的掃描 + 剪枝方法,可以比較高效地處理這樣的分析型數據。因此 CeresDB 的基本設計理念是采用混合存儲格式和相應的查詢方法,從而達到能夠同時高效處理時序型數據和分析型數據。下圖展示了 CeresDB 單機版本的架構
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
性能優化與實驗結果
CeresDB 組合使用了列式混合存儲、數據分區、剪枝、高效掃描等技術,解決海量時間線(high cardinality)下寫入查詢性能變差的問題。
寫入優化
CeresDB 采用類 LSM(Log-structured merge-tree)寫入模型,無需在寫入時處理復雜的倒排索引,因此寫入性能上較好。
查詢優化
主要采用以下技術手段提高查詢性能:
剪枝:
- min/max 剪枝:構建代價比較低,在特定場景,性能較好
- XOR 過濾器:提高對 parquet 文件中的 row group 的篩選精度
高效掃描:
- 多個 SST 間并發:同時掃描多個 SST 文件
- 單個 SST 內部并發:支持 Parquet 層并行拉取多個 row group
- 合并小 IO:針對 OSS 上的文件,合并小 IO 請求,提高拉取效率
- 本地 cache:緩存 OSS 拉取文件,支持內存和磁盤緩存
性能測試結果
采用 TSBS 進行性能測試。壓測參數如下:
- 10 個 Tag
- 10 個 Field
- 時間線(Tags 組合數)100w 量級
壓測機器配置:24c90g
InfluxDB 版本:1.8.5
CeresDB 版本:1.0.0
寫入性能對比
InfluxDB 寫入性能隨著時間下降較多。CeresDB 在寫入穩定后,寫入速率趨于平穩,并且總體寫入性能表現為 InfluxDB 的 1.5 倍以上(一段時間后可達 2 倍以上差距)
下圖中,單行 row 包含 10 個 Field。
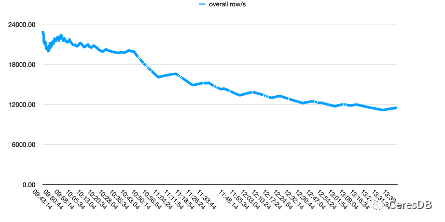
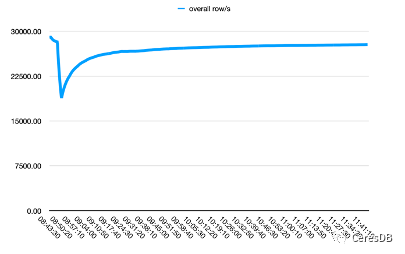
上圖為 Influxdb,下圖為 CeresDB
查詢性能對比
低篩選度條件(條件:os=Ubuntu15.10),CeresDB 比 InfluxDB 快 26 倍,具體數據如下:
- CeresDB 查詢耗時:15s
- InfluxDB 查詢耗時:6m43s
高篩選度條件(命中的數據較少,條件:hostname=[8 個],此時理論上傳統倒排索引會更有效),這是 InfluxDB 更有優勢的場景,此時在預熱完成條件下,CeresDB 比 InfluxDB 慢 5 倍。
- CeresDB:85ms
- InfluxDB:15ms
2023 年 roadmap
開發團隊表示,2023 年,在 CeresDB 1.0 發布之后,他們大部分工作將聚焦在性能、分布式與周邊生態方面的工作。尤其周邊生態的對接支持工作,希望能讓各種不同的用戶更加簡單的用上 CeresDB:
周邊生態
- 生態兼容,包括 PromQL、InfluxdbQL、OpenTSDB 等常用時序數據庫協議兼容
- 運維工具支持,包括 k8s 支持、CeresDB 運維系統、自監控等
- 開發者工具,包括數據導入導出等
性能
- 探索新的存儲格式
- 增強不同類型索引,強化 CeresDB 在不同工作負載下的表現
分布式
- 自動負載均衡
- 提高可用性、可靠性
審核編輯 :李倩
-
數據存儲
+關注
關注
5文章
977瀏覽量
50955 -
數據庫
+關注
關注
7文章
3822瀏覽量
64506 -
Rust
+關注
關注
1文章
229瀏覽量
6619
原文標題:CeresDB 1.0正式發布,Rust高性能云原生時序數據庫
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
云數據庫是哪種數據庫類型?
云原生LLMOps平臺作用
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區 助力打造高性能原生應用
時序數據庫TDengine 2024年保持高增長,實現收入翻倍

艾體寶與Kubernetes原生數據平臺AppsCode達成合作
什么是云原生MLOps平臺
AI時代的數據庫技術發展論壇亮點前瞻
軟通動力榮登2024云原生企業TOP50榜單
云原生和數據庫哪個好一些?
云原生和非云原生哪個好?六大區別詳細對比
利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
京東云原生安全產品重磅發布
基于DPU與SmartNic的云原生SDN解決方案
時序數據庫是什么?時序數據庫的特點
華為云原生多模數據庫 GeminiDB 架構與應用實踐






 工商網監
工商網監
評論