 為什么要在CPU和DDR之間增加一個cache呢?
為什么要在CPU和DDR之間增加一個cache呢?
1, 簡介
Cache被稱為高速緩沖存儲器(cache memory),是一種小容量高速的存儲器,屬于存儲子系統的一部分,存放程序常使用的指令和數據。對于做service開發的同學,可能很少關注過這個模塊,一般也不關心數據是在內存,還是在cache里。畢竟大部分時候,上層的程序只要遵循一定的開發規范(比如局部性原理),就不會太影響cache的工作。但是對于底層開發的工程師,比如操作系統開發、固件開發、性能優化和編譯器開發工程師,在做開發、性能優化的時候,cache是需要重點關注的模塊,如果對cache的理解不夠深入,開發出來的程序不僅性能不好,并且可能會存在穩定性問題。
我們既然有了DDR,為什么還需要在CPU和DDR之間增加一個cache呢?主要是由于兩個原因:一是CPU和DDR的訪問、讀寫速度相差很大,二是減少CPU與其他模塊爭搶訪存頻率。
DDR的性能雖然也在提升,但是與CPU的差距越來越大,當前兩者的速度相差幾百倍,一條加載指令需要上百個時鐘周期,才能從DDR讀取數據到CPU的內部寄存器,這會導致CPU停滯等待加載指令,嚴重影響了CPU的性能。CPU的運行速度跟cache相差不大,并且程序運行遵循著時間、空間的局限性。因此通過在CPU與DDR之間增加一個cache,就可以很大地緩解CPU與DDR之間的速度差距。你可能會想,既然cache的讀寫速度這么快,是不是可以直接替代DDR?想法是好的,不過現實比較殘酷,cache的成本是DDR的幾十倍,最主要的是cache的單位存儲的面積也要比DDR大,1G的cache面積有A4紙大小。因此不論從成本,還是芯片面積角度來看,基本上不能用cache替代DDR。
具有訪存需求的模塊不僅有CPU,還有GPU、DSP、DMA等模塊。這些模塊協同工作,存在很大概率的并行、競爭訪問DDR的時刻。在CPU與DDR之間增加cache,會減少CPU直接訪問DDR的頻率,這樣對其他模塊訪問DDR的速度提升有幫助。
其實在微架構中,除了CPU與DDR之間的cache外,還存在著其他的一些cache。比如,用于虛擬地址與物理地址轉換的TLB(Table Lookup Buffer),用于指令流水線中的重排序緩沖區(Re-Order Buffer),用于指令亂序執行的內存重排緩沖區(Memory Ordering Buffer)等。本文主要談論的是CPU與DDR之間的cache。
Cache一般由集成在CPU內部的SRAM(Static Random Access Memory)和Tag組成。在CPU第一次從DDR中讀取數據時,也會把這個數據緩存在cache里,當CPU再次讀取時,直接從cache中取數據,從而大大提高讀寫的速度。CPU讀寫數據的時候,如果數據在cache中,稱為高速緩存命中(cache hit),如果數據不在cache中,稱為高速緩存未命中(cache miss)。如果程序的高速緩存命中率比較高,不僅會提升CPU性能,還會降低系統的功耗。
2, 框架
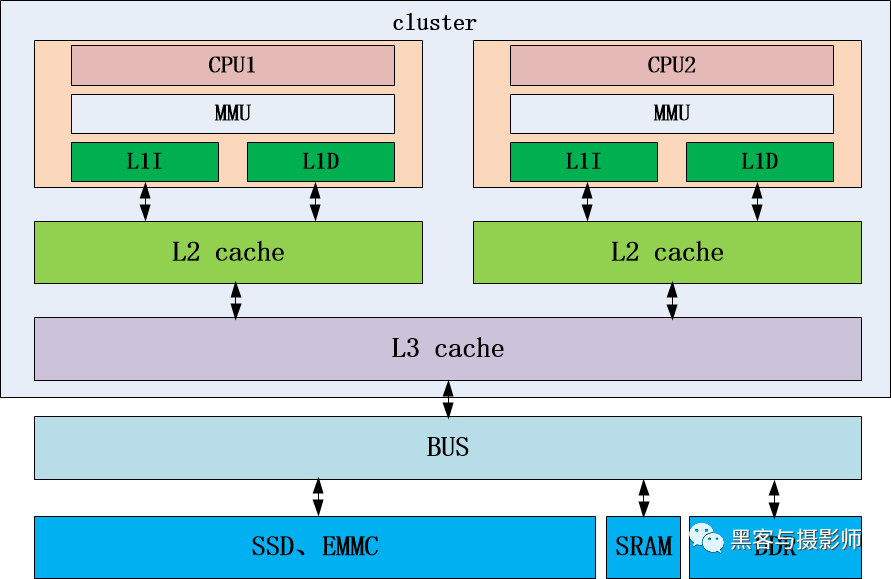
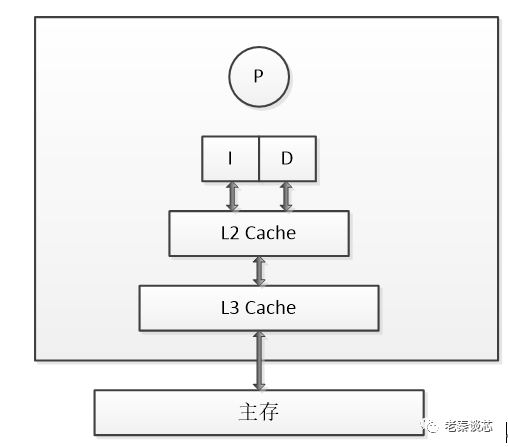
如上圖是一個經典ARM64體系結構處理器系統,其中包含了多級的cache。一個cluster CPU族包含了兩個CPU內核,每個CPU都有自己的L1 cache及L2 cache,其中L1 cache分了L1I(Level 1 Instruction)、L1D(Level 1 Data)兩種。不同CPU共享L3 cache,L3 cache位于cluster內。Cluster通過BUS與DDR、EMMC、SSD等建立連接,這樣CPU就可以訪問到EMMC、SSD中的數據。在程序執行時,會先將程序及數據,從SSD或者EMMC加載到內存中,然后將內存中的數據,加載到共享的 L3 Cache 中,再加載到每個核心獨有的 L2 Cache,最后才進入到最快的 L1 Cache,之后才會被 CPU 讀取。
在系統設計時,需要在cache的性能和成本(芯片面積)之間做tradeoff,由于程序運行遵循著局部性原理,因此現在CPU都采用了多級cache設計方案。越靠近CPU的cache,速度越快,成本越高,容量越小,越遠離CPU的存儲模塊,速度越慢,成本越低、容量越大。不同存儲器的訪問速度、成本對比如下圖:
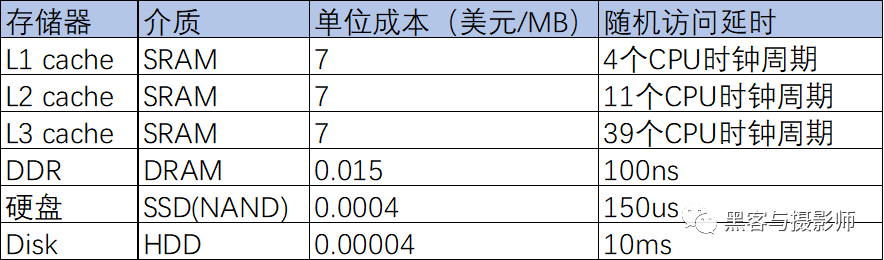
不同存儲器成本、性能對比
2.1 cache和MMU的關系
Cache和MMU基本上都是一起使用的,會同時開啟或同時關閉。因為MMU頁表中的entry屬性,控制著內存的權限和cache緩存的策略。CPU在訪問DDR的時候用的地址是虛擬地址(Virtual Address,VA),經過MMU將VA映射成物理地址(Physucal Address,PA),然后使用物理地址查詢高速緩存,這種高速緩存稱為物理高速緩存。物理高速緩存在的缺點主要是,CPU查詢TLB或MMU后才能訪問cache,增加了流水線的延時。物理高速緩存的工作流程如下:
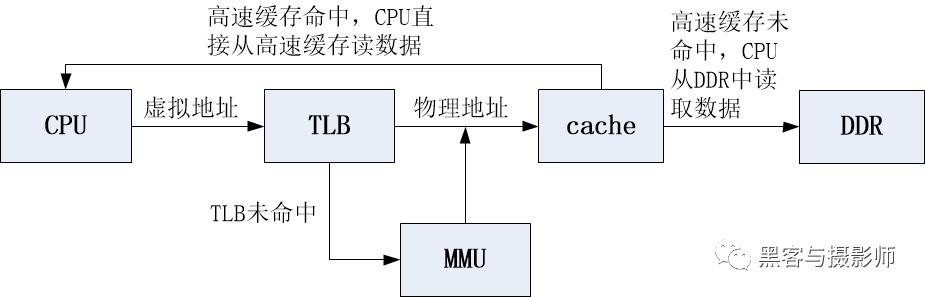
物理高速緩存的工作流程
CPU使用虛擬地址尋址高速緩存,這種高速緩存稱為虛擬高速緩存。CPU在尋址時,先把虛擬地址發送到高速緩存,若在高速緩存里找到所需數據,就不再訪問TLB和DDR。虛擬高速緩存的工作流程如下:
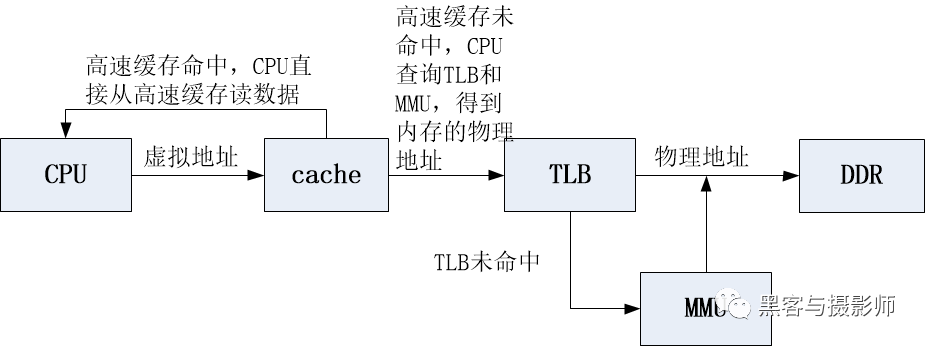
虛擬高速緩存的工作流程
2.2 L1、L2、L3 cache
1)cache分級的原因
L1、L2、L3 cache主要是由SRAM及tag組成的,其中L1 cache采用的是分離緩存方式:L1I(Level 1 Instruction)、L1D(Level 1 Data)cache。L2、L3 cache采用的卻是統一緩存的方式,沒有將數據、指令分開存儲。從上面各存儲器的訪問延時對比來看,L1、L2、L3存在一定差異,但是成本相近,為什么要做成這種多級緩存形式,不直接將L1 cache做大,然后去掉L2、L3?
不采用一級cache的原因,一方面是:cache做地太大會影響讀寫速度。如果要更大的容量,就需要更多的晶體管,這不僅帶來芯片的面積變大,還會導致速度下降。因為訪問速度和要訪問的晶體管信號線的長度成反比。也就是說當晶體管數增加后,信號路徑會變長,讀寫存在大延遲,從而影響讀寫速度。另一方面,多級不同尺寸的緩存有利于提高整體的性能。尤其是對于CPU存在私有的L1、L2 cache,會減少對L3 cache的訪問競爭。
L1、L2、L3 cache的區別是什么呢?L1是為了更快的速度訪問,而優化過的。它用了更多、更復雜、更大的晶體管,從而更加昂貴和更加耗電。L2是為提供更大的容量優化的,用了更少、更簡單的晶體管,從而相對便宜和省電。L3相對L2的優化也是類似的道理。在相同的制程、工藝中,單位面積可以放入晶體管的數目是確定的,這些晶體管如果都給L1,則容量太少,Cache命中率(Hit Rate)嚴重降低,功耗上升太快。如果都給L2、L3,容量大了,但延遲提高了一個數量級。如何平衡L1、L2和L3,用固定的晶體管數目達成最好的性能、最低的功耗、最小的成本,這是一種平衡的藝術。
2)cache命中率與大小的關系
對于L2、L3一般比L1要大,但是比DDR還是小了很多,L2、L3是不是可以更大?其實這跟上面講述的L1不能做的太大的原因類似,主要是成本、面積、速度限制了L2、L3不能做的太大。L2、L3也是基于SRAM實現的,一個存儲單元需要6個晶體管,再加上tag電路,至少需要幾十個晶體管,另外命中率并不是隨著L2、L3的增加一直大幅度增加的。命中率和各級cache大小的關系如下:
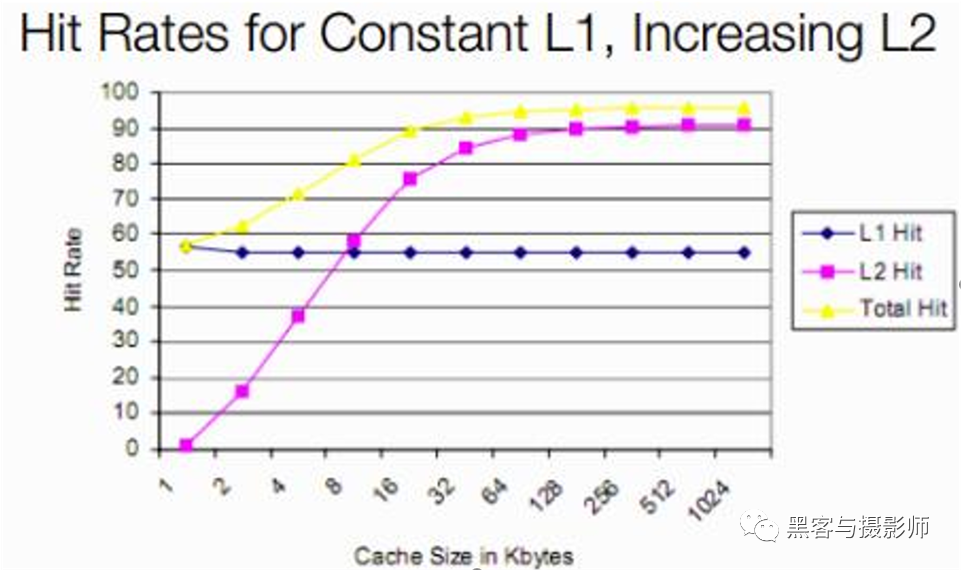
命中率和cache大小關系
為方便分析,我們假設L1維持在50%~60%的命中率(實際上95%左右)。從圖中可以看出,隨著L2容量的快速增加,開始時整體命中率也會快速提高,這表明提高L2容量,對提升整體命中率效用很明顯。但隨后L2的命中率,在容量增加到64KB后,隨著容量增加,命中率增長趨緩,而整體命中率也同時趨緩。增加同樣的晶體管,而受益卻越來越少,個人理解這跟運行程序的訪存特點有關,就是說當訪存的頻次、大小等確定后,開始L2容量增加,整體命中率也會增加,但是一旦達到一個臨界點后,就算再增加容量,命中率的提升也是很有限的。因此在做CPU cache大小設計的時候,一定要建立在業務訪存特點的基礎之上,不然要么造成成本浪費,要么造成性能不足。
3)為什么L1 cache采用分離緩存的方式,而L2、L3采用統一緩存的形式?
為什么L1采用了分離緩存的方式,分了L1I和L1D?主要原因如下:
原因一:避免取指令單元和取數據單元競爭訪問緩存:在CPU中,取指令和取數據指令是由兩個不同的單元完成的,也就是說在流水線控制中取指和訪存是分開的。如果使用統一緩存,當CPU使用超前控制或流水線控制(并行執行)的控制方式時,會存在取指令操作和取數據操作,同時爭用同一個緩存的情況,這會降低CPU運行效率。
原因二:內存中數據和指令是相對聚集的,分離緩存能提高命中率:在現代計算機系統中,內存中的指令和數據并不是隨機分布的,而是相對聚集地分開存儲的。因此,CPU Cache中也采用分離緩存的策略,這更符合DDR內存中數據的組織形式,從而提高cache命中率。
為什么L2、L3采用了統一緩存的方式?主要原因如下:
原因一:CPU直接跟L1 cache打交道,L1采用分離緩存后,已經解決了取指令單元和取數據單元的競爭訪問緩存問題,所以L2是否使用分離緩存,影響不大。
原因二:當緩存容量較大時,分離緩存無法動態調節分離比例,不能最大化發揮緩存容量的利用率。例如數據緩存滿了,但是指令緩存還有空閑,而L2使用統一緩存,則能夠保證最大化利用緩存空間。
4)L3 cache為多核共享的,能不能放在片外?
集成在芯片內部的緩存稱為片內緩存,放在在芯片外部的緩存稱為片外緩存。開始由于芯片工藝的限制,片內緩存不可能很大,不然芯片會非常大,因此 L2 / L3 緩存都是設計在板子上,而不是在芯片內的。后來,隨著芯片制作工藝的提升,L2 / L3 才逐漸集成到 CPU 芯片內部。片內緩存優于片外緩存的主要原因如下:
原因一:片內緩存物理距離更短:片內緩存與取指令單元和取數據單元的物理距離更短,延遲更小,訪問速度更快。
原因二:片內緩存不占用系統總線:片內緩存使用獨立的CPU片內總線,可以減輕系統總線的負擔。
5)多級cache替換策略
多級cache的替換策略設計有很多種方式,可以根據一個cache的內容,是否同時存在于其他級cache來分類,即Cache inclusion policy。如果低級別cache中的所有cache line,也存在于較高級別cache中,則稱高級別cache包含(inclusive)低級別cache。如果高級別的cache,僅包含低級別cache不存在的cache line,則稱高級別的cache不包含(exclusive)較低級別的cache。如果高級cache的內容,既不嚴格包含,也不排除低級cache,則稱為非包含非排他(non-inclusive non-exclusive,NINE)cache。
Inclusive Policy cache:CPU對數據A進行讀取操作時,若A在L1 cache中找到,則從L1 cache中讀取數據,并返回給CPU。若A未在L1 cache中找到,但存在L2 cache中,則從L2 cache中提取該數據所在cache line,并將其填充到L1中。若一個cache line從L1 cache中被逐出,則L2 cache不做操作。若在L1或L2中均未找到想要的數據,則從L3中尋找,找到后會填充到L2、L1,若未在L3中找到,則從DDR中以cache line為單位取出該數據,并將其填充到L1、L2、L3中。若有來自L2的逐出,L2會向L1發送invalidation,以便遵循“Inclusive Policy”。
為了保持inclusion,需要滿足:
無論set的數量多少,L2 way的數量都必須大于或等于 L1 way的數量。
無論 L2 way的數量多少,L2 set的數量必須大于或等于 L1 set的數量。
Exclusive Policy cache:CPU對數據A進行讀取操作時,若A在L1中找到,則從 L1 中讀取數據并返回給CPU。若未在L1中找到,但存在L2中,則將該A數據所在的cache line從L2移動到L1。若一個cache line從L1中被逐出,則被逐出的cache line將被放置到L2中。這是L2 填充的唯一方式。若在L1、L2中都未找到A數據,則將其從L3中取出,并填充到L1,若在L3中也未找到,則在主存中取出,并填充到L1中。
NINE(non-inclusive non-exclusive)Policy:CPU對數據A進行讀取操作時,若A在L1中找到,則從L1中讀取數據并返回給CPU。若在L1中未找到,但存在L2中,則從L2中提取(復制)該數據對應的cache line,并放置到L1中。若一個cache line從L1中被逐出,則L2不做操作,這與inclusive policy相同。若在L1、L2中都沒找到該A數據,則從L3中查找,若L3中找到該數據,將該數據所在cache line取出,并填充到L1、L2,若L3中沒找到,從主存中取出該數據對應的cache line,填充到L1、L2、L3。
三種數據關系策略的比較:
inclusive policy的優點:在每個處理器都有私有cache 時,如果存在cache miss,則檢查其他處理器私有cache,以查找該cache line。如果L2 cache包含L1 cache,并且在L1 cache中miss,則不需要再大面積搜索L2 cache。這意味著與exclusive cache和 NINE cache相比,inclusive cache的miss 延遲更短。
inclusive policy的缺點:cache的內存容量由L3 cache決定的。exclusive cache的容量是層次結構中,所有cache的總容量。如果L3 cache較小,則在inclusive cache中浪費的cache容量更多。
盡管exclusive cache具有更多的內存容量,但相比NINE cache,它需要占用更多的帶寬,因為L1 cache 逐出時,會將逐出數據填充到L2、L3 cache。
3, cache的工作原理
3.1 cache的存儲單元
Cache的存儲部分是由SRAM實現的,cache的存儲單元就是SRAM的存儲單元,SRAM存儲單元由6個三極管組成,如下圖所示:
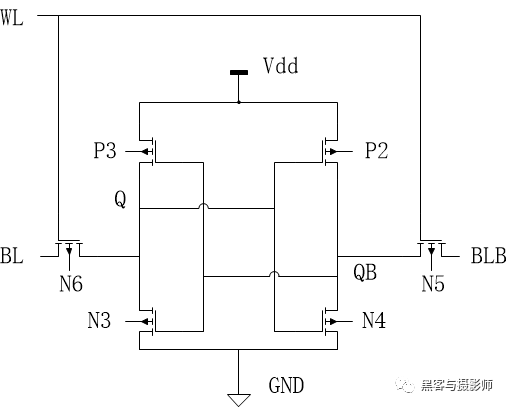
SRAM的存儲單元
寫入“1”的過程如下(寫入數據“0”的過程類似):
先將某一組地址值輸入到行、列譯碼器中,選中特定的單元,如上圖所示。
使寫使能信號WE有效,將要寫入的數據“1”,通過寫入電路變成“1”和“0”后,分別加到選中單元的兩條位線BL、BLB上。
選中單元的WL=1,晶體管N6、N5打開,把BL、BLB上的信號分別送到Q、QB點,從而使Q=1,QB=0,這樣數據“1”就被鎖存在晶體管P2、P3、N3、N4構成的鎖存器中。
讀“1”的過程如下(讀取數據“0”的過程類似):
通過譯碼器選中某列位線對BL、BLB進行預充電到電源電壓VDD。
預充電結束后,再通過行譯碼器選中某行,則某一存儲單元被選中。
由于其中存放的是“1”,則WL=1、Q=1、QB=0。晶體管N4、N5導通,有電流經N4、N5到地,從而使BLB電位下降,BL、BLB間電位產生電壓差,當電壓差達到一定值后打開靈敏度放大器,對電壓進行放大,再送到輸出電路,讀出數據。
3.2 高速緩存的映射方式
CPU訪問DDR前,都會先對cache進行操作,無論對Cache數據檢查、讀取還是寫入,CPU都需要知道訪問的內存數據,對應于Cache上的哪個位置,這就是內存地址與 Cache 地址的映射問題。由于內存塊和緩存塊的大小分別是固定的,所以在映射的過程中,我們只需要考慮 “內存塊索引 - 緩存塊索引” 之間的映射關系,而具體訪問的是塊內的哪一個字,則使用相同的偏移在塊中尋找。
目前,主要有 3 種映射方案:
直接相聯映射(Direct Mapped Cache):固定的映射關系;
全相聯映射(Fully Associative Cache):靈活的映射關系;
組相聯映射(N-way Set Associative Cache):前兩種方案的折中方法。
接下來,我們分別以內存有32個內存塊,CPU Cache有8個緩存塊為例講解這3種映射方案。
1) 直接相聯映射
直接相聯映射的策略:在內存塊和緩存塊之間建立起固定的映射關系,一個內存塊總是映射到同一個緩存塊上。直接映射是三種映射方式中最簡單的。我們通過以下圖來了解直接相聯映射,其中cache塊跟內存塊大小相等,大小為cache line。
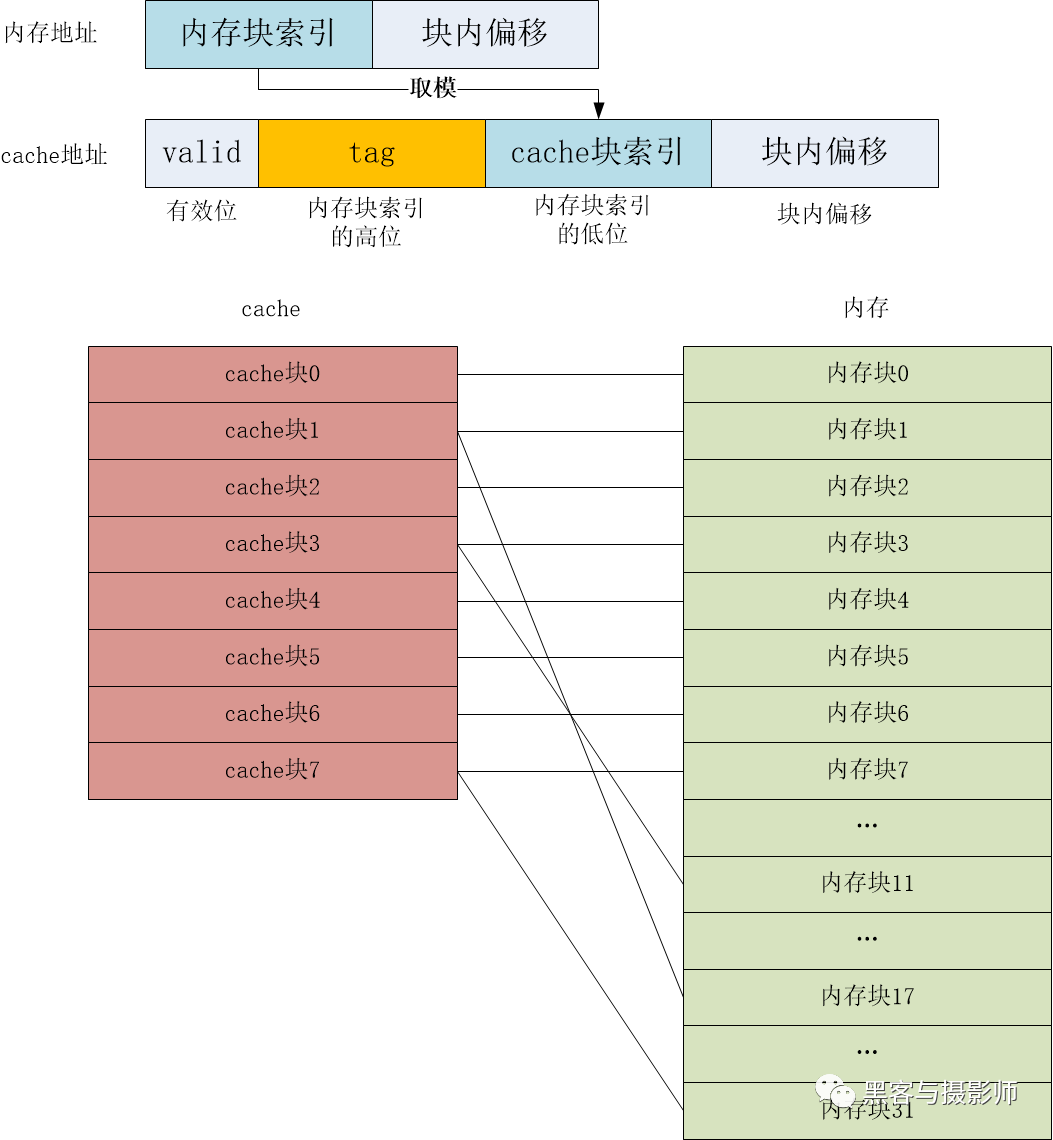
直接相聯映射
具體方式如下:
將內存塊索引對 Cache 塊個數取模,得到固定的映射位置。例如11號內存塊映射的位置就是11 % 8 = 3,對應3號Cache塊。
取模后,多個內存塊會映射到同一個緩存塊上,這會產生塊沖突,所以需要在Cache塊上,增加一個組標記(TAG),標記當前緩存塊存儲的是哪一個內存塊的數據。其實,組標記就是內存塊索引的高位,而 Cache 塊索引就是內存塊索引的低4位(8個字塊需要4位);
由于初始狀態Cache塊中的數據是空的,也是無效的。為了標識Cache塊中的數據,是否已經從內存中讀取,需要在Cache塊上增加一個有效位(Valid bit)。如果有效位為1,則CPU可以直接讀取 Cache 塊上的內容,否則需要先從內存讀取內存塊,并填入Cache塊,再將有效位改為 1。
2) 全相聯映射
對于直接映射存在2個問題:
問題1,緩存利用不充分:每個內存塊只能映射到固定的位置上,即使Cache上有空閑位置也不會使用。
問題2,塊沖突率高:直接映射會頻繁出現塊沖突,影響緩存命中率。
為了改進直接相聯映射的缺點,全相聯映射的策略是:允許內存塊映射到任何一個Cache塊上。這種方式能夠充分利用 Cache 的空間,塊沖突率也更低,但是所需要的電路結構物更復雜,成本更高。
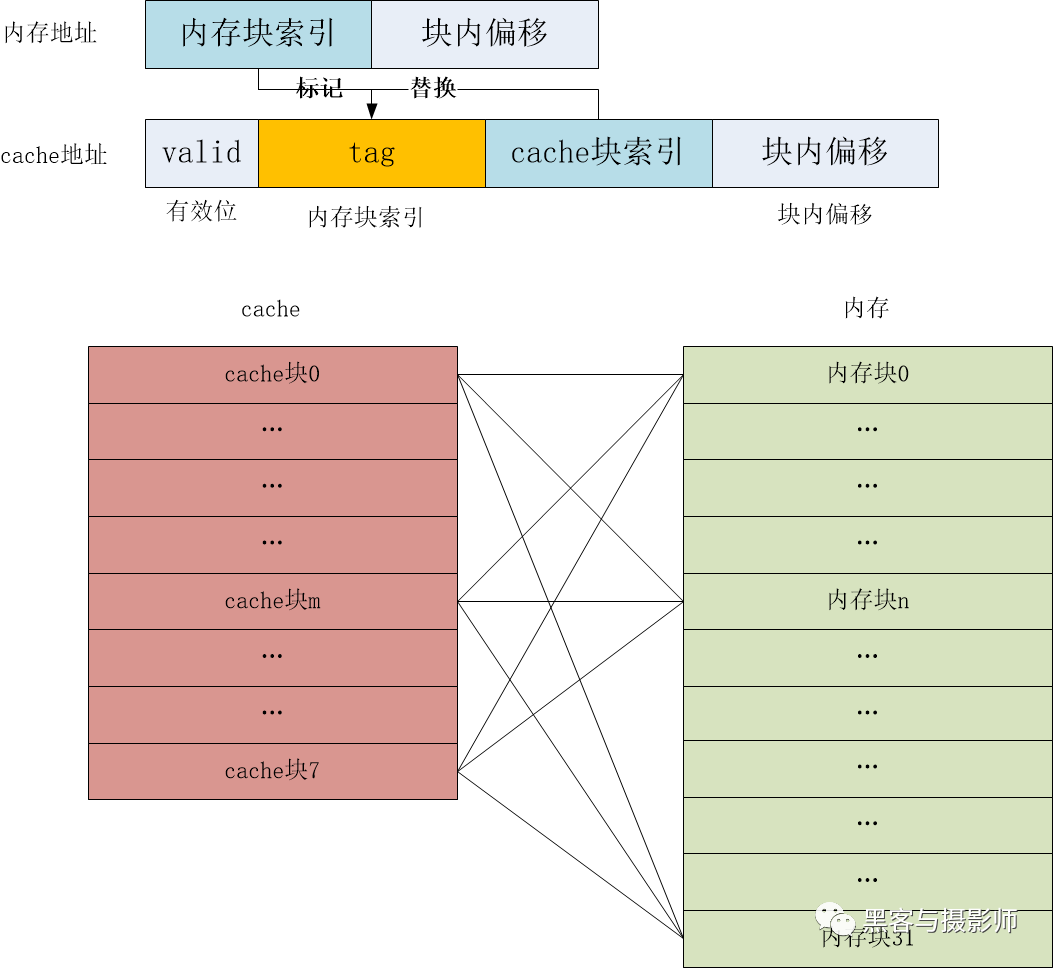
全相聯映射
具體方式如下:
當Cache塊上有空閑位置時,使用空閑位置。
當Cache被占滿時,則替換出一個舊的塊騰出空閑位置。
由于一個Cache塊會映射所有內存塊,因此組標記TAG需要擴大到與主內存塊索引相同的位數,而且映射的過程需要沿著Cache從頭到尾匹配Cache塊的TAG標記。
3) 組相聯映射
組相聯映射結合了直接相聯映射和全相聯映射的優點,組相聯映射的策略是:將Cache分為多組,每個內存塊固定映射到一個分組中,又允許映射到組內的任意Cache塊。顯然,組相聯的分組為1時,就等于全相聯映射,而分組等于Cache塊個數時,就等于直接映射。
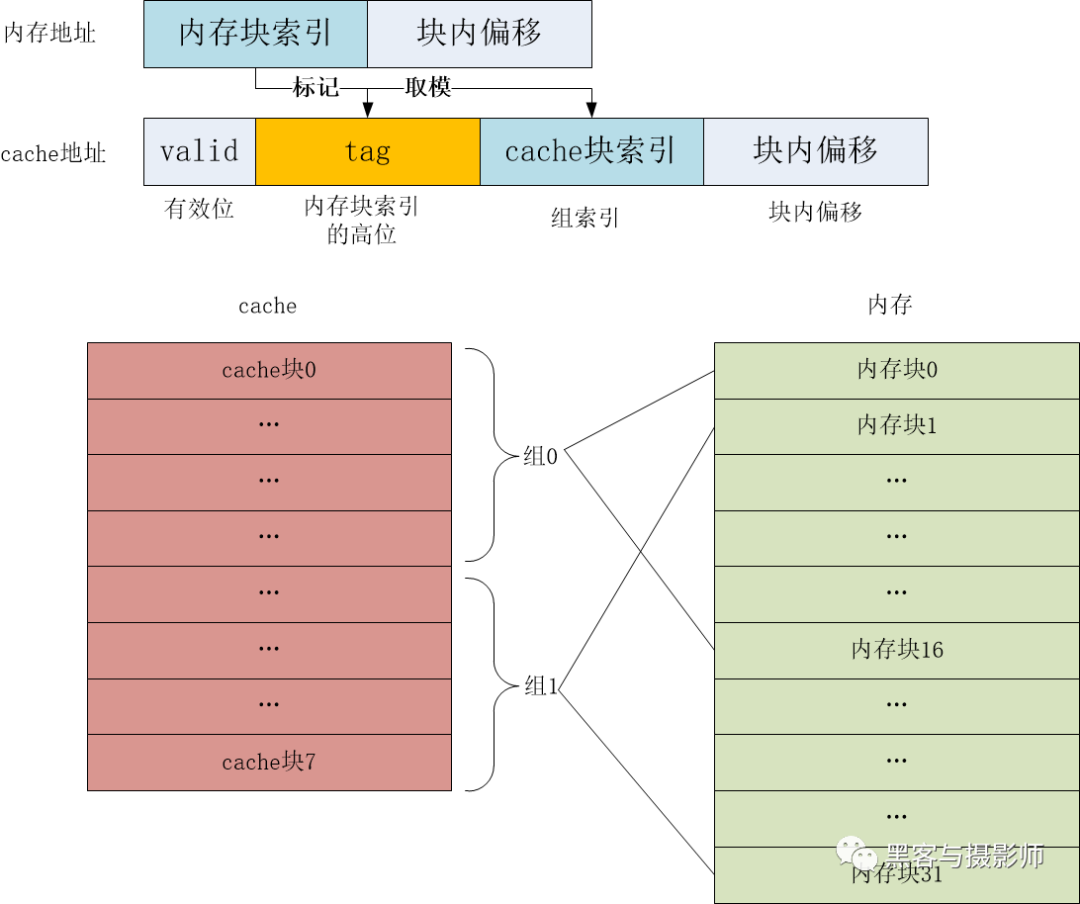
組相聯映射
3.3 cache的基本結構
Cache的基本結構如下圖所示:
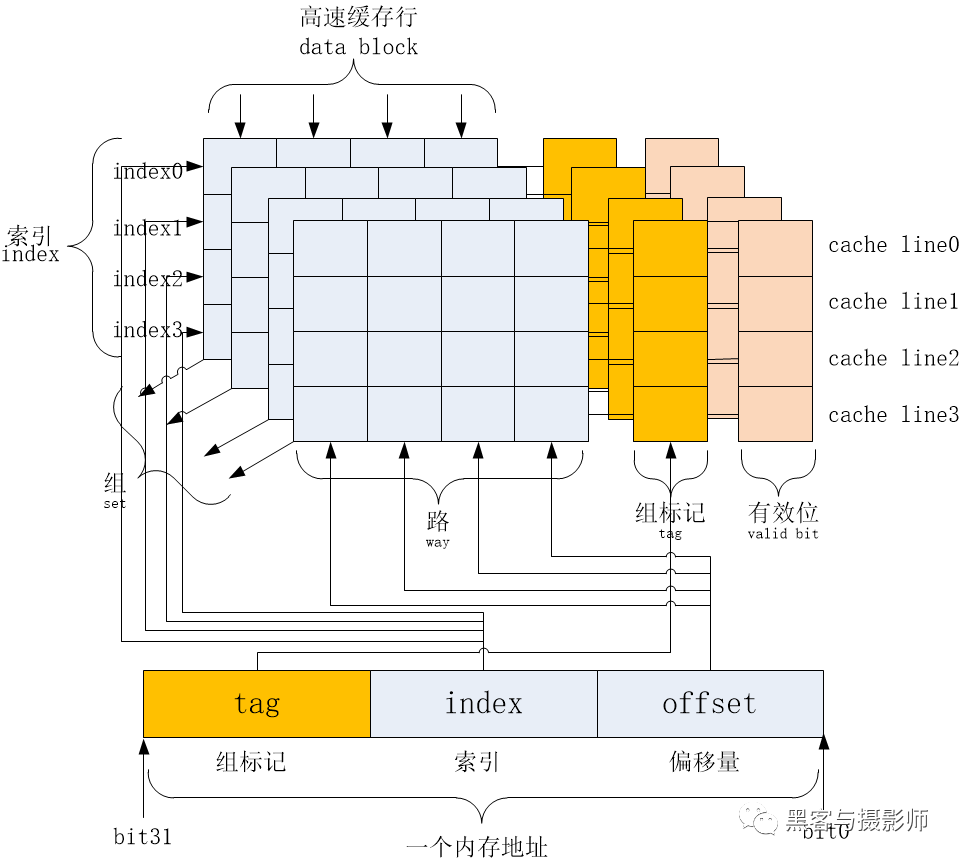
cache的基本結構
地址:以32位為例,CPU訪問cache時的地址編碼,分為3個部分:偏移量(offset)域、索引(index)域和標記(tag)域。
高速緩存行:高速緩存中最小的訪問單元,包含一小段DDR中的數據。常見的高速緩存行大小是32字節或64字節。
索引(index):高速緩存地址編碼的一部分,用于索引和查找地址在高速緩存行的哪一組中。
組(set):由相同索引的高速緩存行組成。
路(way):在組相聯的高速緩存中,高速緩存分成大小相同的幾個塊。如上每一路由四個緩存行組成。
標記(tag):高速緩存地址編碼的一部分,通常是高速緩存地址的高位部分,用于盤點高速緩存行中的數據地址,是否和處理器尋找的地址一致。
偏移量(offset):高速緩存行中的偏移量。CPU可以按字節或字來尋址高速緩存行的內容。
CPU訪問高速緩存的流程如下:
CPU對訪問高速緩存時的地址進行編碼。根據索引域來查找組。對于組相聯的高速緩存,一個組里有多個緩存行的候選者。比如上圖,有一個4路組相聯的高速緩存,一個組里有4個高速緩存行候選者。
在4個高速緩存行候選者中,通過組標記域進行比對。若組標記域相同則說明命中高速緩存行。
通過偏移量域來尋址高速緩存行對應的數據。
3.4 cache的體系結構
高速緩存可以設計成,通過虛擬地址或者物理地址來訪問,這在處理器設計時就確定下來了。高速緩存可以分成如下3類:
VIVT(Virtual Index Virtual Tag):使用虛擬地址的索引域和虛擬地址的標記域,相當于虛擬高速緩存。
PIPT(Physical Index Physical Tag):使用物理地址的索引域和物理地址的標記域,相當于物理高速緩存。
VIPT(Virtual Index Physical Tag):使用虛擬地址的索引域和物理地址的標記域。
在當前ARM架構中,L1 cache都是VIPT的,也就是當有一個虛擬地址送進來,MMU在開始進行地址翻譯的時候,Virtual Index就可以去L1 cache中查詢了,MMU查詢和L1 cache的index查詢是同時進行的。如果L1 Miss了,則再去查詢L2,L2還找不到則再去查詢L3。注意在ARM架構中,僅僅L1是VIPT,L2和L3都是PIPT。我們看看VIPT的工作過程:
CPU輸出的虛擬地址會同時發送到TLB和高速緩存。TLB是一個用于存儲虛擬地址到物理地址的轉換的小緩存,處理器先使用有效頁幀號(Effective Page Number,EPN),在TLB中查找最終的實際頁幀號(Real Page Number,RPN)。如果期間發生TLB未命中(TLB miss),將會帶來一系列嚴重的系統懲罰,處理器需要查詢頁表。假設發生TLB命中(TLB hit),就會很快獲得合適的RPN,并得到相應的物理地址。
同時,處理器通過高速緩存編碼地址的索引(index)域,可以很快找到高速緩存行對應的組。但是這里的高速緩存行中的數據,不一定是處理器所需要的,因此有必要進行一些檢查,將高速緩存行中存放的標記域和通過虛實地址轉換得到的物理地址的標記域進行比較,如果相同并且狀態位匹配,就會發生高速緩存命中,處理器通過字節選擇與對齊(byte select and align)部件,就可以獲取所需要的數據。如果發生高速緩存未命中,處理器需要用物理地址進一步訪問主存儲器,來獲得最終的數據,數據也會填充到相應的高速緩存行中。
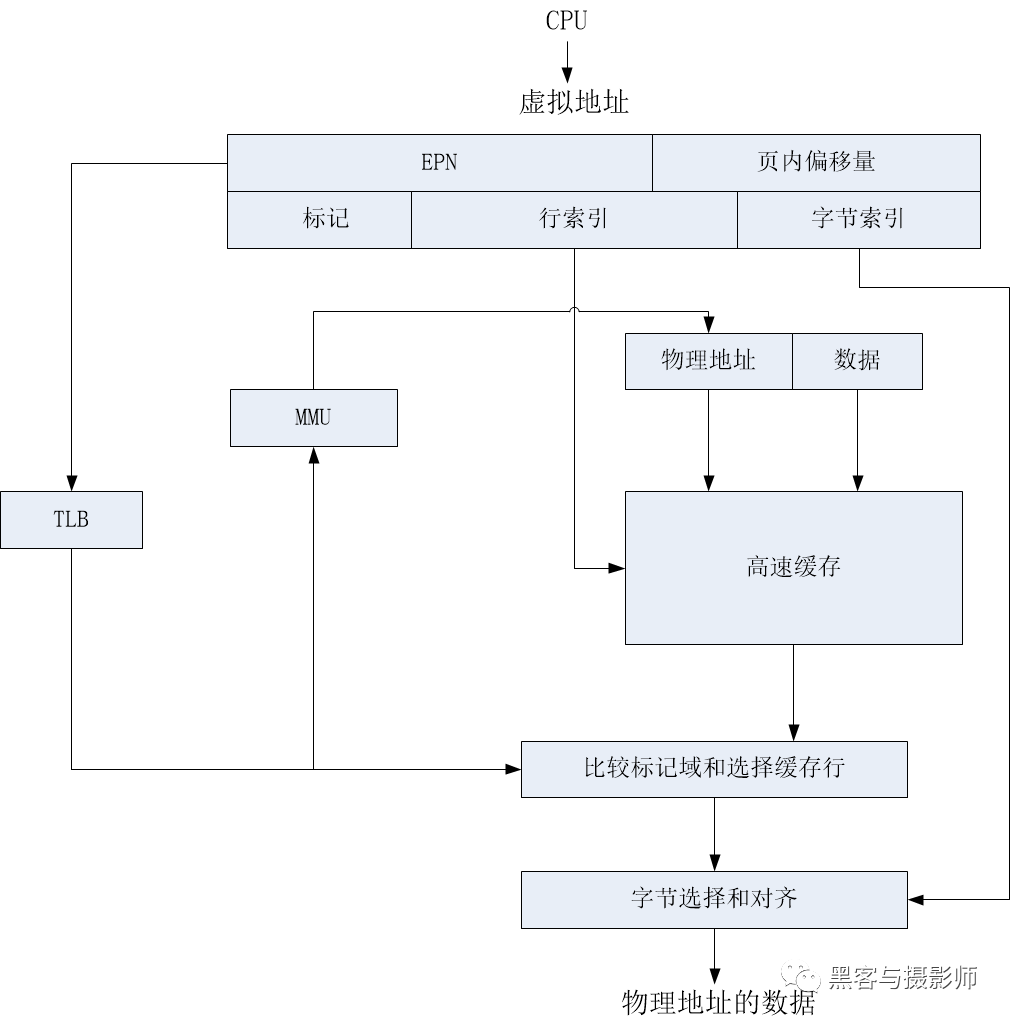
VIPT高速緩存體系結構
3.5 cache的替換策略
在使用直接相聯映射的 Cache 中,由于每個主內存塊都與某個Cache塊有直接映射關系,因此不存在替換策略。而使用全相聯映射或組相聯映射的Cache,由于主內存塊與Cache塊沒有固定的映射關系,當新的內存塊需要加載到Cache中時,且Cache塊沒有空閑位置,則需要替換到Cache塊上的數據。此時就存在替換策略的問題。
常見cache中數據的替換策略如下,cache中數據的替換以cache line為單位:
隨機法:使用一個隨機數生成器,隨機地選擇要被替換的 Cache 塊。優點是實現簡單,缺點是沒有利用 “局部性原理”,無法提高緩存命中率。
FIFO先進先出法:記錄各個Cache塊的加載事件,最早調入的塊最先被替換。缺點同樣是沒有利用 “局部性原理”,無法提高緩存命中率。
LRU最近最少使用法:記錄各個Cache塊的使用情況,最近最少使用的塊最先被替換。這種方法相對比較復雜,也有類似的簡化方法,即記錄各個塊最近一次使用時間,最久未訪問的最先被替換。與前 2 種策略相比,LRU策略利用了 “局部性原理”,平均緩存命中率更高。
多級cache的替換策略,在上面的“多級cache替換策略”里說明了常見的三種替換策略:Inclusive Policy cache,Exclusive Policy cache,NINE(non-inclusive non-exclusive)Policy。接下來以DynamIQ架構中的cortex-A710的L1、L2 cache的替換策略為例,做分析。
我們先看一下DynamIQ架構中的cache中新增的幾個概念:
(1) Strictly inclusive: 對應Inclusive Policy cache,所有存在于L1 cache的數據,必然也存在L2 cache中。
(2) Weakly inclusive: 對應NINE(non-inclusive non-exclusive)Policy,當miss的時候,數據會被同時緩存到L1和L2,但在之后,L2中的數據可能會被替換。
(3) Fully exclusive: 對應Exclusive Policy cache,當miss的時候,數據只會緩存到L1。L1中的數據會逐出到L2。
其實inclusive/exclusive屬性描述的是 L1和L2之間的替換策略,這部分是硬件定死的,軟件不可更改。
根據ARMV9 cortex-A710 trm手冊中的描述,查看該core的cache類型如下:
L1 I-cache和L2之間是 weakly inclusive的,當發生I-cache發生miss時,數據緩存到L1 I-cache的時候,也會被緩存到L2 Cache中,當L2 Cache被替換時,L1 I- cache不會被替換。
L1 D-cache和L2之間是 strictly inclusive的,當發生D-cache發生miss時,數據緩存到L1 D-cache的時候,也會被緩存到L2 Cache中,當L2 Cache被替換時,L1 D-cache也會跟著被替換。
dynamIQ 架構中 L1和L2之間的替換策略,是由core的inclusive/exclusive的硬件特性決定的,軟無法更改。core cache之間的替換策略,是由SCU(或DSU)執行的MESI協議中定義的,軟件也無法更改。多cluster之間的緩存一致性,由 CCI/CMN 來執行維護,沒有使用MESI協議。在L1 data cache TAG中,有記錄MESI相關比特。將一個core內的cache看做是一個整體,core與core之間的緩存一致性,就由DSU執行MESI協議來維護,因此L1D遵從MESI協議。對于L1I cache來說,都是只讀的,cpu不會改寫L1I中的數據,所以也就不需要硬件維護多核之間緩存的不一致。
3.6 高速緩存分配策略
cache的分配策略是指我們什么情況下應該為數據分配cache line。cache分配策略分為讀和寫兩種情況。
讀分配(read allocation)是指當CPU讀數據時,發生cache缺失,這種情況下都會分配一個cache line,緩存從主存讀取的數據。默認情況下,cache都支持讀分配。寫分配(write allocation)是指當CPU寫數據發生cache缺失時,才會考慮寫分配策略。當我們不支持寫分配的情況下,寫指令只會更新主存數據,然后就結束了。當支持寫分配的時候,我們首先從主存中加載數據到cache line中(相當于先做個讀分配動作),然后會更新cache line中的數據。
1)寫操作時,cache更新策略
一條存儲器讀寫指令,通過取指、譯碼、發射和執行等一系列操作之后,會到達LSU(Load Store Unit)。LSU是指令流水線中的一個執行部件,連接指令流水線和高速緩存,包括加載隊列(load queue)和存儲隊列(store queue)。存儲器讀寫指令通過LSU后,會到達L1控制器,L1控制器先發起探測(probe)操作。對于讀操作,發起高速緩存讀探測操作,并帶回數據。對于寫操作,發起高速緩存寫探測操作。發起寫探測操作前,需要準備好待寫的高速緩存行。探測操作返回時,會帶回數據,存儲器寫指令獲得最終數據,并進行提交操作后,才會將數據寫入,這個寫入可以采用直寫(write through)模式,或者回寫(write back)模式。
在探測過程中,對于寫操作,若沒有找到相應的高速緩存行,就出現寫未命中(write miss)。否則就出現寫命中(write bit)。對于寫未命中的處理策略是寫分配(write allocate),L1控制器將分配一個新的高速緩存行,之后和獲取的數據合并,然后寫入L1D。
若寫未命中,存在兩種不同的策略:
寫分配(write allocate)策略:先把要寫的數據加載到高速緩存中,然后修改高速緩存的內容。
不寫分配(no write allocate)策略:不分配高速緩存,而直接把內容寫入內存。
若寫命中,存在兩種不同的策略:
直寫模式:進行寫操作時,數據同時寫入當前的高速緩存,下一級高速緩存,或主存儲器中,cache和主存的數據始終保持一致。。直寫模式可以降低高速緩存一致性實現的難度,缺點是消耗比較多的總線帶寬,性能比回寫模式差。
回寫模式:在進行寫操作時,數據直接寫入當前高速緩存,而不會繼續傳遞,當該高速緩存被替換出去時,被改寫的數據才會更新到下一級高速緩存,或主存中。該策略增加了高速緩存一致性的實現難度,但是可有效減少總線帶寬的需求。每個cache line中會有一個bit位記錄數據是否被修改過,稱之為dirty bit。我們會在數據寫到cache中后,將dirty bit置位。主存中的數據只會在cache line被替換或者顯式的clean操作時更新。因此,主存中的數據可能是未修改的數據,而修改的數據躺在cache中。cache和主存的數據可能不一致。此模式的優點是,數據寫入速度快,因為不需要寫存儲。缺點是,一旦更新后的數據,未被寫入存儲時,出現系統掉電的情況,數據將無法找回。
無論是Write-through還是Write-back都可以使用寫缺失的兩種方式之一。只是通常Write-back采用Write allocate方式,而Write-through采用No-write allocate方式。因為多次寫入同一緩存時,Write allocate配合Write-back可以提升性能,而對于Write-through則沒有幫助。
2)讀操作時,cache更新策略
對于讀操作,若高速緩存命中,那么直接從高速緩存中獲取數據。若未命中高速緩存,存在如下兩種策略:
讀分配(read allocate)策略:先把數據加載到高速緩存中,然后將數據返回給CPU。
讀直通(read through)策略:不經過高速緩存,直接從內存中讀取數據。
審核編輯:劉清
-
DDR
+關注
關注
11文章
712瀏覽量
65404 -
Cache
+關注
關注
0文章
129瀏覽量
28364 -
緩沖存儲器
+關注
關注
0文章
8瀏覽量
5809 -
SRAM芯片
+關注
關注
0文章
65瀏覽量
12135
原文標題:一文搞懂cpu cache工作原理
文章出處:【微信號:IC大家談,微信公眾號:IC大家談】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CPU Cache是如何保證緩存一致性的?
為什么要在電路設計中增加一個串聯電阻呢?有何作用?





 工商網監
工商網監
評論