

谷歌正在開發各種人工智能技術,其中包括一個通用語音模型,這是該公司試圖建立一個可以理解世界上1000種最常用語言的模型的一部分。
有傳言稱,除了計劃在今年的年度 I/O 活動中展示20多款人工智能產品外,谷歌正在朝著構建支持1,000種不同語言的人工智能語言模型的目標邁進。在周一發布的更新中,谷歌分享了有關通用語音模型 (USM) 的更多信息,該系統被谷歌描述為實現其目標的“關鍵的第一步”。
去年11月,該公司宣布計劃創建一個支持1,000種世界上使用最廣泛的語言的語言模型,同時還展示其 USM 模型。谷歌將 USM 描述為“最先進的語音模型家族”,有20億個參數,經過1200萬小時的語音和280億個句子的訓練,涵蓋300多種語言。
USM 已被 YouTube 用于生成隱藏式字幕,它還支持自動語音識別 (ASR),支持自動檢測和翻譯語言,包括英語、普通話、阿姆哈拉語等。
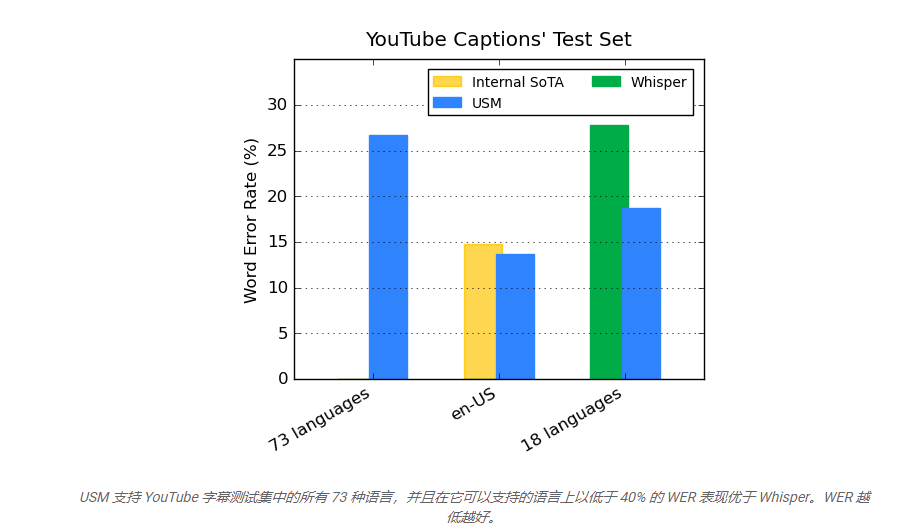
目前,谷歌表示 USM 支持100多種語言,并將作為構建更廣泛系統的“基礎”。另外,Meta 也正在開發一種類似的 AI 翻譯工具,該工具仍處于早期階段。
審核編輯黃宇
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
谷歌
+關注
關注
27文章
6215瀏覽量
106694 -
AI
+關注
關注
87文章
32894瀏覽量
272379 -
USM
+關注
關注
0文章
7瀏覽量
7272
發布評論請先 登錄
相關推薦
《AI Agent 應用與項目實戰》----- 學習如何開發視頻應用
再次感謝發燒友提供的閱讀體驗活動。本期跟隨《AI Agent 應用與項目實戰》這本書學習如何構建開發一個視頻應用。AI Agent是一種智能應用,能
發表于 03-05 19:52


AI大語言模型開發步驟
開發一個高效、準確的大語言模型是一個復雜且多階段的過程,涉及數據收集與預處理、模型架構設計、訓練與優化、評估與調試等多個環節。接下來,AI部
大語言模型開發語言是什么
在人工智能領域,大語言模型(Large Language Models, LLMs)背后,離不開高效的開發語言和工具的支持。下面,AI部落小
一文理解多模態大語言模型——下
/understanding-multimodal-llms ? 《一文理解多模態大語言模型 - 上》介紹了什么是多模態大語言

【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
的表達方式和生成能力。通過預測文本中缺失的部分或下一個詞,模型逐漸掌握語言的規律和特征。
常用的模型結構
Transformer架構:大語言
發表于 08-02 11:03
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
的機會!
本人曾經也參與過語音識別產品的開發,包括在線和離線識別,但僅是應用語言模型實現端側的應用開發,相當于調用模型的接口函數,實際對
發表于 07-21 13:35
超ChatGPT-4o,國產大模型竟然更懂翻譯,8款大模型深度測評|AI 橫評
、速度慢、費用高且難以準確理解上下文”的問題。相比之下,AI大模型憑借其強大的學習能力和適應性,在翻譯質量、效率、上下文理解和多

谷歌發布新型大語言模型Gemma 2
在人工智能領域,大語言模型一直是研究的熱點。近日,全球科技巨頭谷歌宣布,面向全球研究人員和開發人員,正式發布了其最新研發的大
大語言模型(LLM)快速理解
自2022年,ChatGPT發布之后,大語言模型(LargeLanguageModel),簡稱LLM掀起了一波狂潮。作為學習理解LLM的開始,先來整體理解一下大

【大語言模型:原理與工程實踐】大語言模型的評測
的工具。通過這一框架,研究人員和使用者可以更準確地了解模型在實際應用中的表現,為后續的優化和產品化提供有力支持。針對語言理解類評測任務,特別是古文及諺語理解,我們深入評估
發表于 05-07 17:12





 工商網監
工商網監

評論