") 基于專家知識+AI算法的性能調(diào)優(yōu)
基于專家知識+AI算法的性能調(diào)優(yōu)
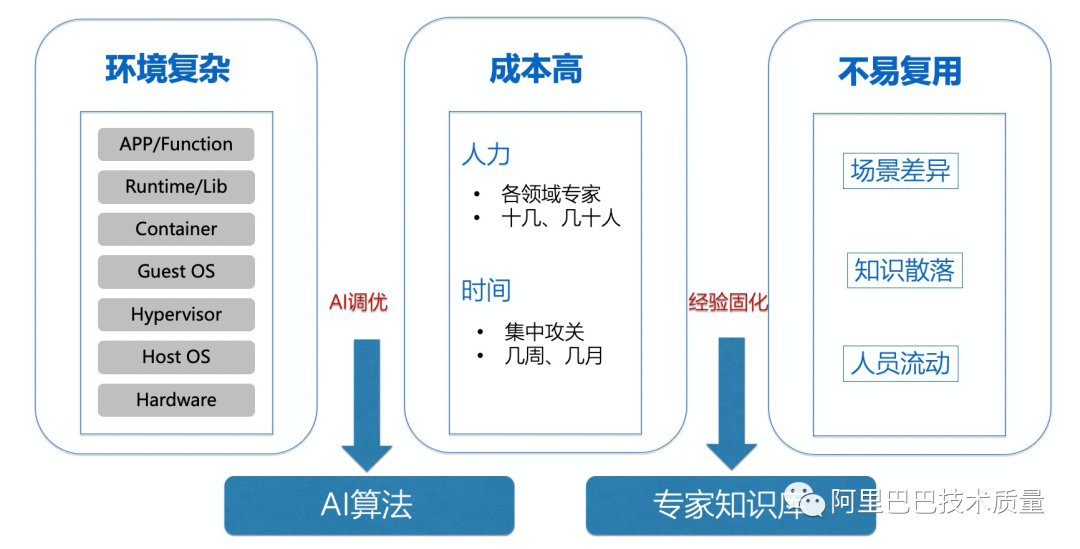
在業(yè)務的性能調(diào)優(yōu)中,我們往往會遇到下面三個方面的問題:
1)操作系統(tǒng)的軟硬件配置過于繁雜。
無論是應用內(nèi)核參數(shù)、系統(tǒng)服務還是應用配置,都有成百上千的參數(shù),而且參數(shù)之間相互,在調(diào)優(yōu)的時候往往存在蹺蹺板現(xiàn)象,如何管理如此大量的領域知識,是非常困難的事情。
2)人力、時間成本高。
做一次有效的全棧調(diào)優(yōu),往往需要把多個領域的專家集中起來進行一次1-3個月的集中攻關,在人力和時間成本上是非常大的代價。
3)專家知識難以固化復用。
即使是我們在一個場景上把所有專家集中起來做了一次非常好的攻關,專家知識還是非常難以固化下來并在下個應用擴展使用起來,到了下一次調(diào)優(yōu)場景,還是幾乎要重頭再來。
針對上述問題我們該如何求解呢?
如果專家知識非常難以固化,那我們?yōu)槭裁床唤ㄒ粋€專家知識庫平臺來把專家知識固化起來呢?
如果我們的配置關系非常復雜,投入時間和人力非常高,那我們?yōu)槭裁床话?a href="http://www.1cnz.cn/tags/ai/" target="_blank">AI算法引入進來,讓人工智能幫我們做一些事情。
??
在容量評估測試中,我們也會遇到類似的問題:Benchmark的參數(shù)眾多,哪些參數(shù)是需要使用的,哪些其實無關緊要?需要使用的參數(shù),如何設置它的值才能保證給出的壓力是足夠的,從而不會因為壓力不足而無法驗證到物理機/系統(tǒng)真實的容量呢?
I可行的解決途徑——KeenTune的緣起
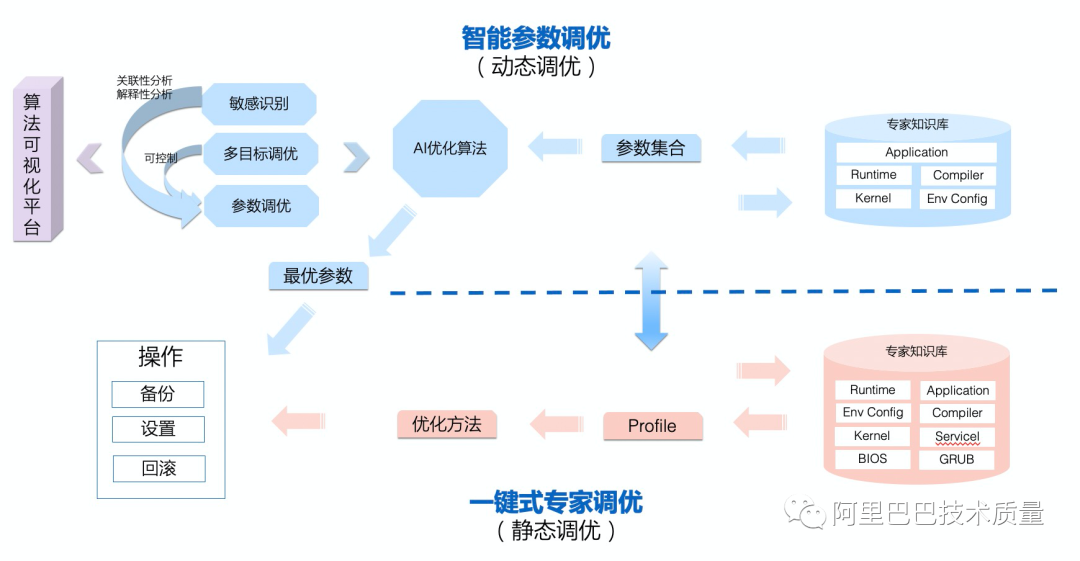
從上個部分中,我們其實可以看出求解的方式,一個是需要專家知識的固化平臺,一個是可以考慮引入AI算法來解決人工無法有效探索參數(shù)取值空間的問題。這也就是KeenTune的起源,其主要完成兩大部分的功能,一方面將人工的經(jīng)驗固化下來,形成能夠在業(yè)務上一鍵調(diào)優(yōu)的專家知識庫——也就是靜態(tài)調(diào)優(yōu);另一方面,在有了需要調(diào)優(yōu)的參數(shù)及其取值空間的概要知識的情況下,可以使用AI算法來進行最優(yōu)取值搜索。
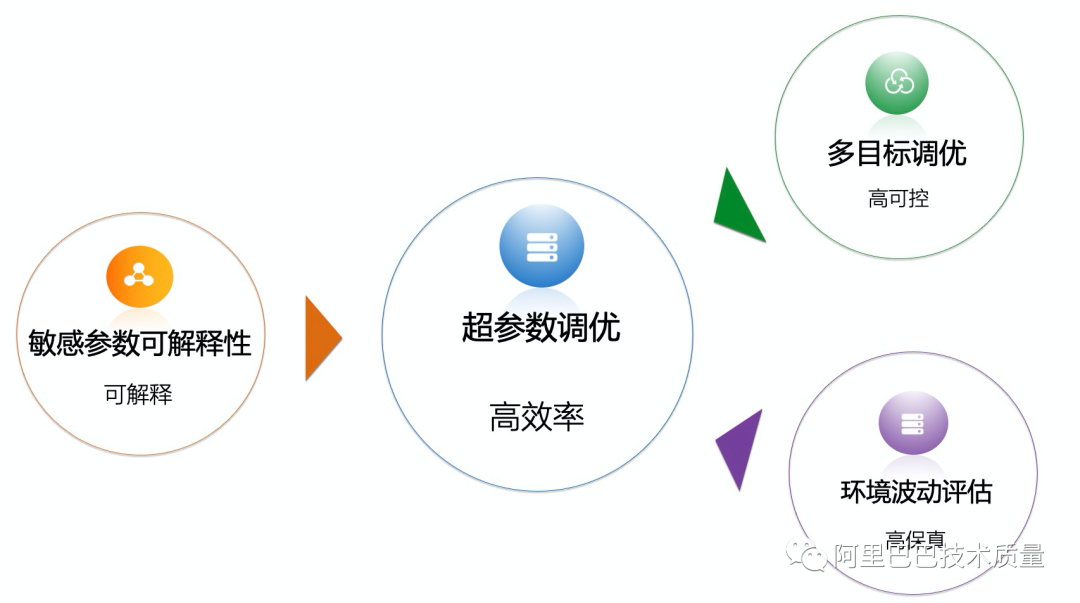
這是KeenTune產(chǎn)品開始研發(fā)時最樸素的想法,后面也因為業(yè)務的實際需要,引入了參數(shù)可解釋性方向的算法,來識別出來哪些參數(shù)對結果真實有影響,其最優(yōu)取值范圍是什么,從而指導進行人工解釋和進一步研究;同時,也引入了高保真方向的算法來規(guī)避Benchmark/業(yè)務環(huán)境的波動對調(diào)優(yōu)效果的準確性帶來的影響;另外,也針對“在不增加時延的情況下,提升吞吐量”這樣的帶控制條件的實際調(diào)優(yōu)需求,引入了多目標調(diào)優(yōu)方向的算法。

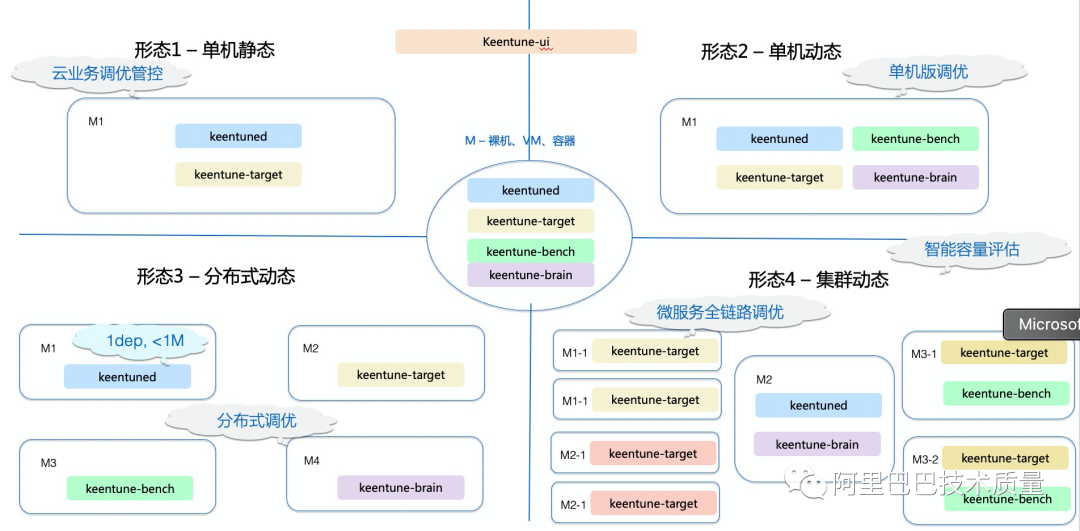
請注意,KeenTune提供的動靜態(tài)協(xié)同調(diào)優(yōu)的能力,可以協(xié)助實際業(yè)務解決如下問題:
1)POC小集群調(diào)優(yōu)到線上大規(guī)模集群調(diào)優(yōu),比如:POC小集群動態(tài)調(diào)優(yōu)完后,調(diào)優(yōu)經(jīng)驗固化成靜態(tài)調(diào)優(yōu),直接大規(guī)模部署到線上;
2)相似場景的精細化調(diào)優(yōu),比如:調(diào)優(yōu)過mysql后,使用mysql的固化出的靜態(tài)專家知識庫,轉化成動態(tài)進行精細化調(diào)優(yōu)。
在算法創(chuàng)新的同時,基于阿里業(yè)務自身的特點,KeenTune采用了高度模塊化的分布式部署的方式,在業(yè)務端只需要部署輕量的agent(keentune-target),管控調(diào)度模塊keentuned,算法模塊keentune-brain,Benchmark管控模塊keentune-bench,前端管控與算法可視化模塊keentune-ui都是可以部署在網(wǎng)絡可連通的其他環(huán)境上,因此,對業(yè)務的適配度非常高。
一、創(chuàng)新點
KeenTune項目目前已經(jīng)提交13篇專利,其中9篇已提交專利;另外,還有3篇正在提交流程中。A類論文發(fā)表1篇(FSE2022:KeenTune: Inteligent Parameter Interpretability and Tuning Tool for Linux System),1篇在投A類論文。
本章節(jié)的各小節(jié)中,后續(xù)也會簡單介紹一下KeenTune的創(chuàng)新點。
I多領域算法的集成
KeenTune主要使用的算法為Hyper Parameter Tuning方向,目標是在參數(shù)空間上尋找最優(yōu)組合。不過,在實際應用落地中,發(fā)現(xiàn)在實際應用中會存在很多問題:
1)在高維空間上,無論是傳統(tǒng)的Bayes,還是更新的HORD、EPTE等算法,都無法達到工程需求的快速收斂(比如:100個連續(xù)/分散取值的參數(shù),在100輪達成收斂目標),而一般Benchmark的執(zhí)行時間都會在幾分鐘甚至幾小時,每一輪執(zhí)行代價都非常大,因此,降低輪次成為首要問題。
2)非單一目標調(diào)優(yōu),在實際中,往往是“不增加時延的情況下提升吞吐”、“不僅avg_latency降低,還要求99_latency、95_latency都降低” 3)無論是Benchmark還是業(yè)務環(huán)境,都存在抖動的問題,如何識別出環(huán)境抖動并且盡量消除,是個問題。
為應對這些問題,KeenTune集成了多個領域的算法來使參數(shù)調(diào)優(yōu)在實際工程中能夠產(chǎn)生效果:
敏感參數(shù)可解釋性方向算法:從眾多的參數(shù)中識別出真正對結果有影響的TOP參數(shù),并且能夠給出其最優(yōu)取值的范圍,給出參考。一方面,可以成為參數(shù)調(diào)優(yōu)算法的輸入,大大降低參數(shù)空間,從而實現(xiàn)快速找到優(yōu)化點的目標。另一方面,也可以為人工提煉專家靜態(tài)知識庫并進行領域分析提供依據(jù)。
多目標調(diào)優(yōu)算法:KeenTune自研的帶有可控制條件的多目標調(diào)優(yōu),有效地解決了工程中遇到的各種多個評價指標同時調(diào)優(yōu),甚至是帶有強制限制條件的調(diào)優(yōu)問題。
高保真算法:能夠通過評估環(huán)境的波動情況,調(diào)整每輪運行的次數(shù),從而保證調(diào)優(yōu)效果。另外,結合early stop機制,能夠智能化控制實際的運行效率,從而大大提升對于每次調(diào)優(yōu)的收斂效率。
I自研參數(shù)調(diào)優(yōu)算法BGCS
為了實現(xiàn)高效可擴展的參數(shù)調(diào)優(yōu)算法,BGCS參考了HORD框架進行了改進,使用CNN/MLP模型取代RBF模型作為代理模型,以提高代理模型預測準確性。
在HORD算法的DYCORS過程中,通過兩個變量φ和δ來控制變異的過程,前者控制的是給坐標的某個維度進行變異的概率,后者決定了增加變異的幅度。在調(diào)優(yōu)過程中,φ隨著調(diào)優(yōu)的進行遞減,而δ根據(jù)每一輪是否發(fā)現(xiàn)了新的最優(yōu)參數(shù)進行動態(tài)調(diào)整。
雖然有兩個變量干預參數(shù)的變異,但HORD算法的參數(shù)變異過程整體來說是隨機的,在這個過程中會產(chǎn)生大量無意義的參數(shù)配置。我們針對這個過程加入性能梯度對參數(shù)編譯的過程進行指導,避免盲目隨機地生成大量參數(shù)配置。同時使用梯度對參數(shù)維度進行排序,優(yōu)先針對性能梯度較高的參數(shù)進行變異,同時保持性能梯度低參數(shù)的取值,降低代理模型預測誤差的干擾。
I自研參數(shù)可解釋性算法XSen
為了達成算法能夠正確的找到真正對結果產(chǎn)生影響的參數(shù),PIA將多種不同的敏感參數(shù)領域算法進行融合,根據(jù)實際情況使用。下圖中列出了PIA的框架,主要是分為analyzer和aggregator。
Analyzer分為mutual information analyzer、linear analyzer、non-linear analyzer三種。Non-linear analyzer分為兩種:DNN模型、樹形模型,linear analyzer使用線性模型。在工程驗證中,高維度non-linear analyzer的準確度更高,但是運行時間較久;linear analyzer運行時間在1s內(nèi),不過準確度相對不高。mutual information analyzer捕捉線性和非線性信息,通過信息識別來識別敏感參數(shù)。
二、應用實踐
IKeenTune在Linux全棧性能調(diào)優(yōu)中的實踐
KeenTune不僅在算法層面上實現(xiàn)了對kernel、environment configuration、runtime、compiler、application的多個層級的參數(shù)的動態(tài)算法調(diào)優(yōu),還積累了包括多層級的人工經(jīng)驗。目前,在云場景、云原生場景、編譯器場景等多個合作項目中達成了調(diào)優(yōu)目標,并且在社區(qū)中與統(tǒng)信、中興、intel等SIG伙伴進行相關共建。
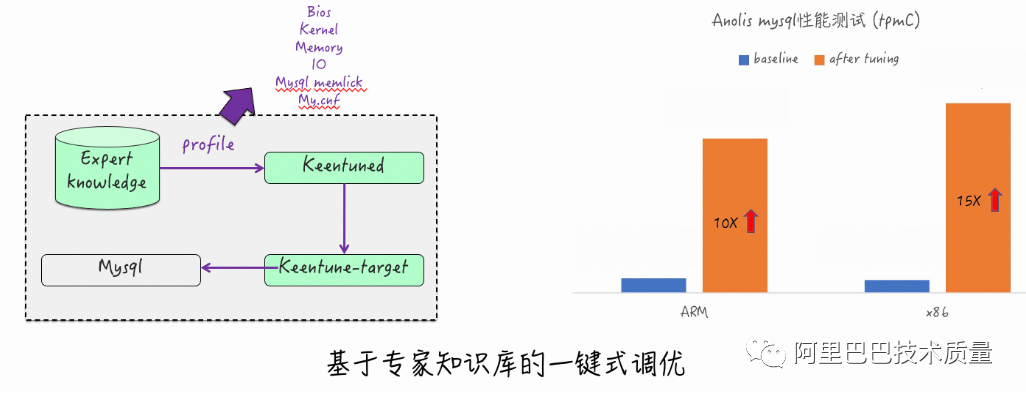
1. 專家一鍵式調(diào)優(yōu) –MySQL的競分打榜
項目背景:
某商業(yè)打榜
調(diào)優(yōu)目標:
AnolisOS提供自研性能調(diào)優(yōu)工具能力,主流應用(MySQL)調(diào)優(yōu)能力不低于友商
調(diào)優(yōu)效果:
MySQL的TPCC跑分在一鍵式專家調(diào)優(yōu)后,相比初始安裝性能提升10倍+
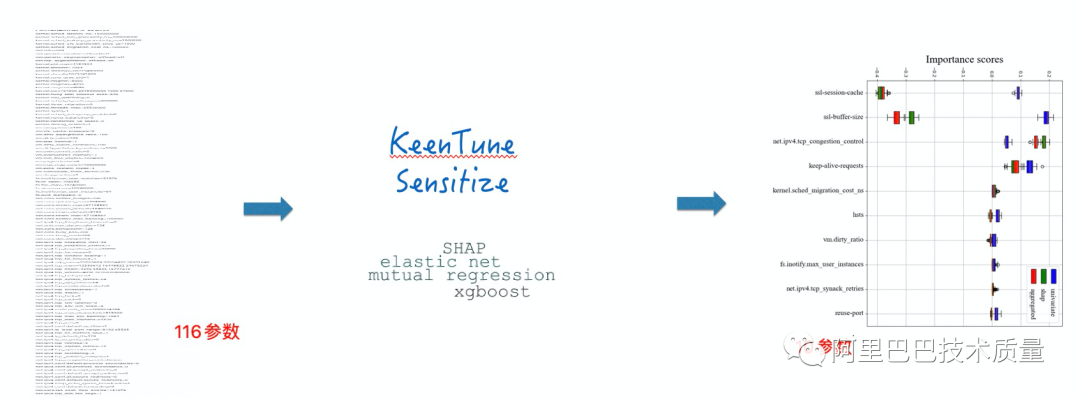
2. 敏感參數(shù)識別 –Nginx業(yè)務的參數(shù)可解釋性
項目背景:
調(diào)優(yōu)參數(shù)多導致參數(shù)空間巨大,進而導致參數(shù)調(diào)優(yōu)算法收斂慢(100參數(shù)收斂需要2000輪以上)
調(diào)優(yōu)目標:
116個聯(lián)合參數(shù)(內(nèi)核+ Nginx) 中對結果影響大的參數(shù),目標20個以內(nèi)
識別效果:
TOP10參數(shù)對Nginx吞吐與時延的影響已經(jīng)超過90%,降維后調(diào)優(yōu)效果和全量保持一致
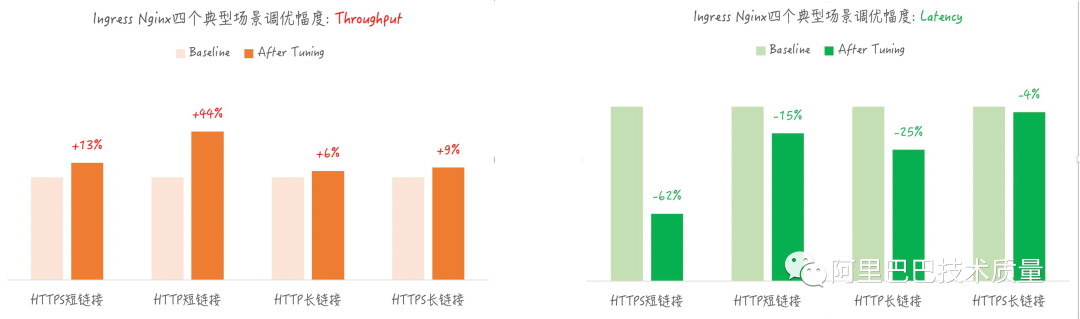
3. 智能參數(shù)調(diào)優(yōu) – 云原生業(yè)務Ingress-Nginx的全棧調(diào)優(yōu)
項目背景:
調(diào)優(yōu)參數(shù)多導致參數(shù)空間巨大,進而導致參數(shù)調(diào)優(yōu)算法收斂慢(100參數(shù)收斂需要500輪以上)
調(diào)優(yōu)目標:
四個場景完整覆蓋:HTTP短鏈接,HTTP長鏈接,HTTPs短鏈接,HTTPs長鏈接
多領域參數(shù)協(xié)同調(diào)優(yōu):Sysctl,Nginx
兩個指標統(tǒng)一優(yōu)化:Throughput提升的同時Latency下降
調(diào)優(yōu)效果:
四個場景均達成了throughput提升的同時latency下降,有些場景最好效果達到40%+
達成內(nèi)核到應用的全棧調(diào)優(yōu),取得良好效果
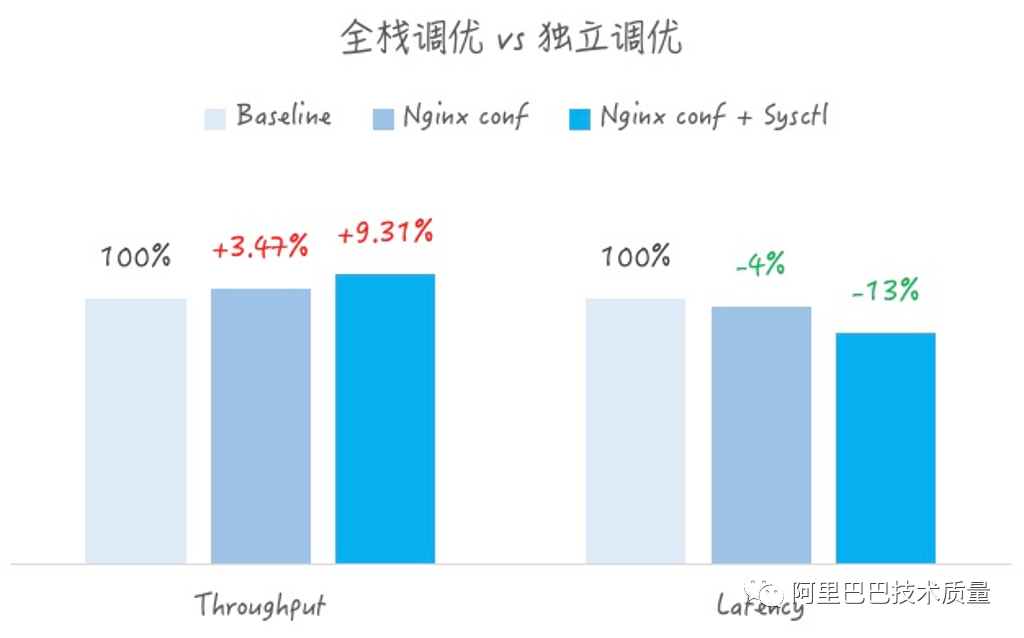
同時,在其中,尤其是長連接的場景,對比了只進行nginx.conf參數(shù)調(diào)優(yōu),與內(nèi)核+Nginx的全量調(diào)優(yōu)的對比,可以非常明顯的看出,多層級的全棧調(diào)優(yōu)效果會比單一層級的調(diào)優(yōu)效果突出。
4. 智能參數(shù)調(diào)優(yōu) – 云業(yè)務gcc編譯參數(shù)調(diào)優(yōu)
項目背景:
gcc編譯參數(shù)對應用性能影響較大,人工定義配置比較困難
調(diào)優(yōu)目標:
對云業(yè)務上TOP3的應用進行編譯參數(shù)優(yōu)化
調(diào)優(yōu)效果:
TOP3應用的主要指標均達成調(diào)優(yōu)目標(目標1-3%)
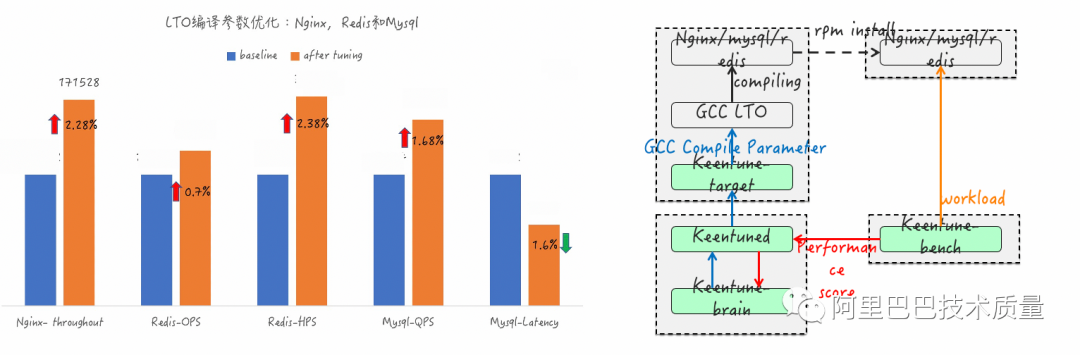
IKeenTune在容量評估方向的實踐
容量評估一直一直以來的痛點,就是Benchmark工具,大家都知道是什么,怎么用,不過卻不一定能夠用對。現(xiàn)在集團內(nèi)的使用方式基本上還是人工定義性能測試用例,用這個結果直接評估是否正確,這就對Benchmark使用人員有著非常高的要求,怎么創(chuàng)建模型,定義Benchmark的各個參數(shù)是很有講究的。
往往存在直接從網(wǎng)上找到使用的命令行方式,修改修改參數(shù),跑出來個結果就開始做分析。可是這樣子就會有幾個問題:
1)不少Benchmark的參數(shù)都非常多,比如:sysbench,那么,哪些參數(shù)是我們需要關注并且使用的呢?
2)在不同規(guī)格的機器上,都使用相同一套參數(shù)的測試用例,是不是不合適?換個說法,是否能夠提供足夠的壓力用來提供容量評估?
3)Benchmark本身的資源消耗怎樣?會不會因為參數(shù)設置不當,或者環(huán)境選用不當,導致Benchmark自己占掉了所有資源而無法給出足夠壓力?這一點在wrk上非常明顯。
為了解決這些問題,KeenTune的參數(shù)調(diào)優(yōu)算法登場了,開始在看似不屬于自己的領域,進行了一些還挺有效果的實踐。
1. 基礎Benchmark的壓力管控 – iperf3網(wǎng)絡帶寬測試
項目背景:
在與私有云團隊進行容量評估的需求分析時,發(fā)現(xiàn)使用人工用例進行容量評估,往往存在因為Benchmark壓力不足導致無法測出真實容量
壓控目標:
通過動態(tài)控壓,評測出硬件和云上環(huán)境的真實容量
壓控效果:
相比人工測試用例,評測出更真實的網(wǎng)絡容量,高出10%+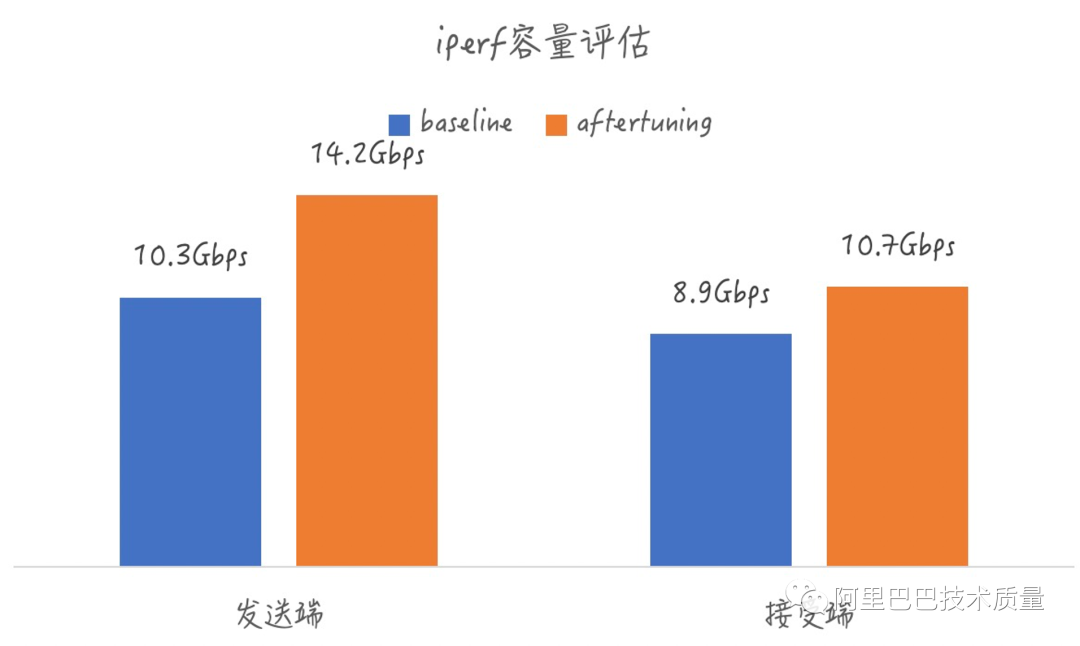
管控更多工具參數(shù),并且能夠提供最佳效果取值范圍
說明:左邊的兩個圖分別是iperf3進行接收端和發(fā)送端容量評估時,iperf3中參數(shù)真正對結果有效果的3個參數(shù),右邊的兩列圖,分別給出來了接收端和發(fā)送端在當前規(guī)格機器中這三個敏感參數(shù)的取值推薦。

2. 應用的調(diào)優(yōu)、壓力雙控 – MySQL的調(diào)優(yōu)與變壓
項目背景:
進行應用的調(diào)優(yōu)時,需要解決兩部分問題:(1)Benchmark壓力不足;(2)應用環(huán)境及自身調(diào)優(yōu)
壓控目標:
同時管控MySQL與Benchmark的參數(shù),保證壓力控制的狀況下進行MySQL調(diào)優(yōu)

審核編輯:劉清
-
操作系統(tǒng)
+關注
關注
37文章
6801瀏覽量
123283 -
PoC
+關注
關注
1文章
69瀏覽量
20513 -
RBF
+關注
關注
0文章
40瀏覽量
15711 -
MYSQL數(shù)據(jù)庫
關注
0文章
96瀏覽量
9389 -
AI算法
+關注
關注
0文章
249瀏覽量
12259
原文標題:基于專家知識+AI算法的性能調(diào)優(yōu)、容量評估
文章出處:【微信號:軟件質(zhì)量報道,微信公眾號:軟件質(zhì)量報道】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
基于全HDD aarch64服務器的Ceph性能調(diào)優(yōu)實踐總結
KeenTune的算法之心——KeenOpt 調(diào)優(yōu)算法框架 | 龍蜥技術
深度 | 性能全面超數(shù)據(jù)庫專家,騰訊基于機器學習的性能優(yōu)化系統(tǒng)
歐拉(openEuler)Summit 2021:基于AI的操作系統(tǒng)性能調(diào)優(yōu)引擎
openEuler Summit開發(fā)者峰會:基于AI的操作系統(tǒng)性能調(diào)優(yōu)引擎A-Tune
詳細介紹算法效果調(diào)優(yōu)的流程
關于JVM的調(diào)優(yōu)知識
KeenOpt調(diào)優(yōu)算法框架實現(xiàn)對調(diào)優(yōu)對象和配套工具的快速適配
鴻蒙開發(fā)實戰(zhàn):【性能調(diào)優(yōu)組件】
OSPI控制器PHY調(diào)優(yōu)算法

MMC SW調(diào)優(yōu)算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論