") 基于矢量量化字典與雙解碼器的人臉盲修復網(wǎng)絡
基于矢量量化字典與雙解碼器的人臉盲修復網(wǎng)絡
盡管生成式面部先驗和結(jié)構化面部先驗最近已經(jīng)證明了可以生成高質(zhì)量的人臉盲修復結(jié)果,穩(wěn)定、可靠生成更細粒度的臉部細節(jié)仍然是一個具有挑戰(zhàn)性的問題。這篇文章受最近基于字典的方法和基于矢量量化的方法啟發(fā),提出了一種 基于矢量量化(VQ-based)的人臉盲修復方法VQFR。VQFR從高質(zhì)量的圖像中抽取特征,構建low-level特征庫從而恢復逼真的面部細節(jié)。
這篇工作重點關注如下兩個問題:
1.codebook中每個code對應的原圖patch大小會極大影響人臉網(wǎng)絡修復結(jié)果的質(zhì)量與保真度權衡,而實際落地應用中,質(zhì)量與保真度需要做到良好的平衡以獲得最佳視覺效果。
2.原圖退化特征需要與來自codebook的高質(zhì)量特征做融合,融合過程中,如何做到高質(zhì)量特征不被退化特征所干擾而導致性能降低?
詳細介紹引入
人臉恢復的目標是恢復低質(zhì)量(LQ)面孔并糾正未知退化,例如噪聲、模糊、下采樣引起的退化等。在實際情況下,此任務變得更具挑戰(zhàn)性,因為存在更復雜的退化、多樣的面部姿勢和表情。以前的作品通常利用特定于人臉的先驗,包括幾何先驗、生成先驗和參考先驗。具體來說,幾何先驗通常包括面部標志、面部解析圖和面部組件熱圖。它們可以為恢復準確的面部形狀提供全局指導,但不能幫助生成逼真的細節(jié)。
此外,幾何先驗是從退化圖像中估計出來的,因此對于具有嚴重退化的輸入變得不準確。這些特性促使研究人員尋找更好的先驗。最近的人臉修復工作開始研究生成先驗(GAN-Prior),并取了優(yōu)異的性能。這些方法通常利用預先訓練的人臉生成對抗網(wǎng)絡(例如StyleGAN)的強大生成能力來生成逼真的紋理。這些方法通常將退化的圖像投影回GAN潛在空間,然后使用預先訓練的生成器解碼高質(zhì)量(HQ)人臉結(jié)果。
盡管基于GAN先驗的方法最初從整體上講具有良好的恢復質(zhì)量,但仍然無法生成細粒度的面部細節(jié),特別是精細的頭發(fā)和精致的面部組件。這是因為訓練有素的GAN模型,其潛在空間仍然是不夠完善的。基于參考的方法(Reference-based methods)—探索了高質(zhì)量的指導面孔或面部組件字典來解決面部恢復問題。
DFDNet是該類別中的代表方法,它不需要訪問相同身份的面孔,就可以產(chǎn)生高質(zhì)量的結(jié)果。它明確建立高質(zhì)量的“紋理庫”,用于幾個面部組件,然后用字典中最近的高質(zhì)量面部組件替換退化的面部組件。這種離散的替換操作可以直接彌合低質(zhì)量面部部件與高質(zhì)量部件之間的差距,因此具有提供良好面部細節(jié)的潛力。然而,DFDNet中的面部組件字典仍然有兩個缺點。
1)它使用預先訓練的VGGFace網(wǎng)絡進行離線生成,該網(wǎng)絡是為識別任務優(yōu)化的,明顯并不適合恢復任務。
2)它只關注幾個面部組件(即眼睛、鼻子和嘴巴),但不包括其他重要區(qū)域,例如頭發(fā)和皮膚。
面部組件字典的局限性促使VQFR探索矢量量化(VQ)碼本,這是一個為所有面部區(qū)域構建的字典。VQFR提出的人臉恢復方法VQFR既利用字典方法又利用GAN訓練,但不需要任何幾何或GAN先驗。與面部組件字典相比,VQ碼本可以提供更全面的低層特征庫,而不局限于有限的面部組件。
它也是通過面部重建任務以端到端的方式來學習的。此外,矢量量化的機制使其在不同的退化情況下更加穩(wěn)健。盡管簡單地應用VQ碼本可以取得不錯的效果,但要實現(xiàn)良好的結(jié)果也不容易。后續(xù)進一步介紹了兩個特殊的網(wǎng)絡設計以應對前文提到的兩個problems,這將幫助VQFR在細節(jié)生成和身份保留方面都超越先前的方法。
具體來說,為了生成逼真的細節(jié),作者發(fā)現(xiàn)選擇適當?shù)膲嚎s補丁大小至關重要,它表示codebook的一個code“由多大的補丁表示”。如圖2所示,較大的patch可以帶來更好的視覺質(zhì)量,但是真實度卻會下降。經(jīng)過全面的調(diào)查,我們建議輸入圖像大小512x512時,32大小的patch size最合適。然而,這種選擇只是在質(zhì)量和真實度之間進行權衡。
表情和身份也可能會因適當?shù)膲嚎s補丁大小而有很大的變化。一個直接的解決方案是將輸入特征與不同的解碼器層融合,這與GFP-GAN中的操作類似。盡管輸入特征可以帶來更多的真實度信息,但它們也會干擾從VQ代碼本生成的逼真細節(jié)特征。這個問題引出了作者的第二個網(wǎng)絡設計:并行解碼器。
具體而言,并行解碼器結(jié)構包括紋理解碼器和主解碼器。VQFR的紋理解碼器僅接收來自VQ代碼本的潛在表示的信息,而主解碼器將紋理解碼器中的特征做變換以匹配退化輸入的需保留的特征。
為了避免高質(zhì)量細節(jié)的損失并更好地匹配退化的面部,VQFR在主解碼器中進一步采用了具有可變卷積的紋理變換模塊。通過VQ codebook作為面部字典和并行解碼器設計,VQFR可以實現(xiàn)更高質(zhì)量的面部細節(jié)修復,同時盡可能得保留面部恢復的真實度。
VQFR方法概述
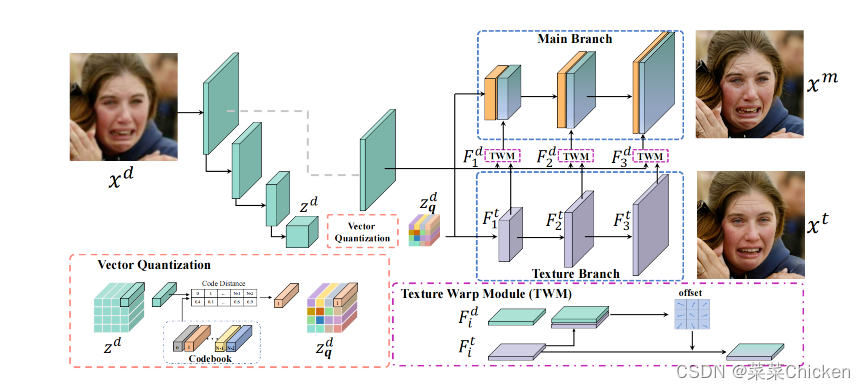
VQFR模型架構圖。VQFR由一個編碼器組成,用于映射退化的人臉進入潛在和并行解碼器以利用 HQ 代碼和輸入功能。編碼器和解碼器由矢量量化模型和預訓練的 HQ 碼本,將編碼的latent feature替換為 HQ 代碼
Vector-Quantized Codebook最早在VQVAE中被引入,旨在學習離散的先驗來編碼圖像。VQFR中的codebook部分與VQGAN中的基本一致。VQGAN 主要是采用了感知損失和對抗性損失以鼓勵具有更好感知質(zhì)量的重建。VQFR方法主要基于以下兩個觀察來提高修復性能:
通過采用合適的壓縮補丁大小,可以用僅由高品質(zhì)人臉訓練的VQ碼本來去除LQ人臉的退化。
在訓練恢復任務時,在改進的細節(jié)紋理和保真度變化之間需要保持一個平衡。
針對觀察現(xiàn)象一,VQFR采用合適的f大小來控制codebook效果,f取32最佳。針對觀察現(xiàn)象二,VQFR提出利用雙分支架構的decoder來逐漸將高質(zhì)量紋理特征補充進待修復特征中,texture warp module利用可變形卷積很好的實現(xiàn)了這一目的。反觀之前的相似工作,之前工作中單一分支decoder架構很難較好的融合低質(zhì)特征和高質(zhì)量特征,這導致了恢復性能不佳。
實驗
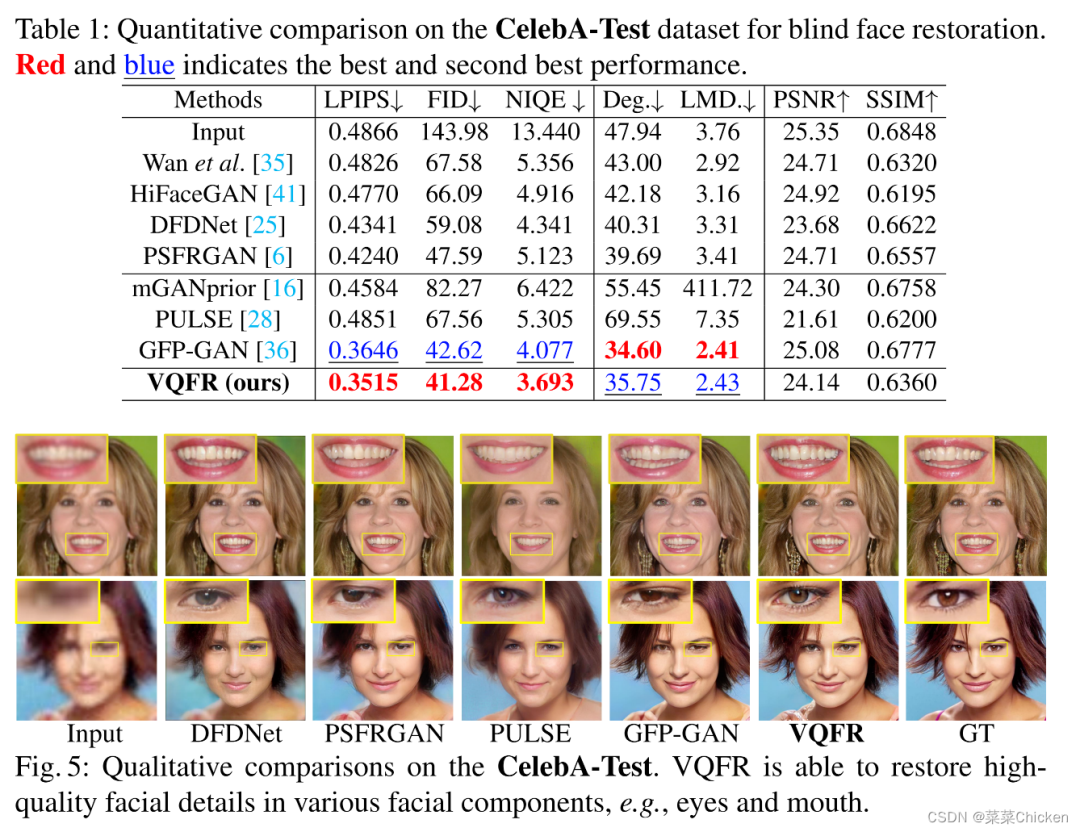
VQFR在CelebA-Test數(shù)據(jù)集和LFW數(shù)據(jù)集上均取得了領先的性能結(jié)果,值得關注的是其PSNR/SSIM指標并不十分出色,但是FID、NIQE、LMD指標非常不錯,視覺效果也體現(xiàn)了該方法的優(yōu)越性。
真實度與保真度的平衡
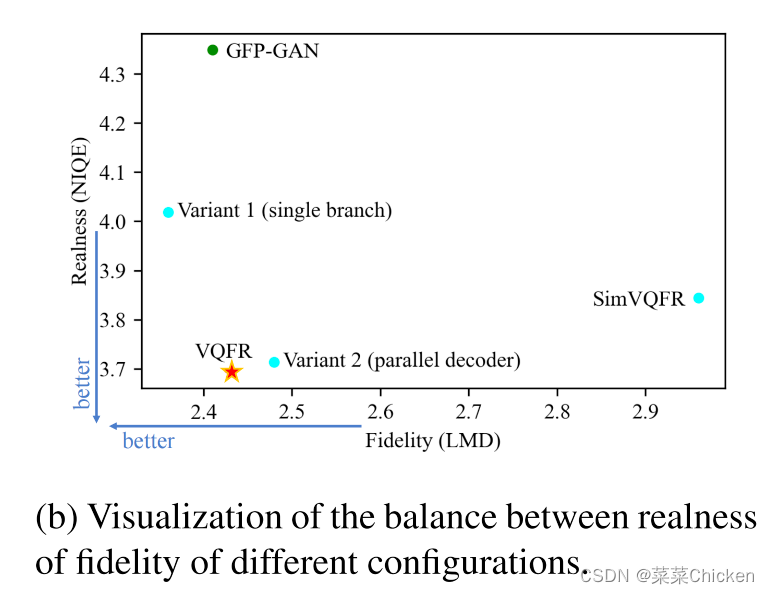
可以看出VQFR取得了非常不錯的真實度與保真度的平衡,實驗效果很出色。
總結(jié)
本文提出的VQFR是一種性能非常不錯的人臉盲修復方法,文章思路非常清晰,明確點出核心motivation和為解決的相關問題,最后的實驗結(jié)果也非常精彩,很好的證明了方法的基本理論與出發(fā)點,更多細節(jié)建議大家參考原文。
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1143瀏覽量
40718 -
GaN
+關注
關注
19文章
1933瀏覽量
73286 -
生成器
+關注
關注
7文章
315瀏覽量
21003 -
GFP
+關注
關注
0文章
5瀏覽量
1410
原文標題:ECCV'22 Oral|VQFR|基于矢量量化字典與雙解碼器的人臉盲修復網(wǎng)絡
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
怎么實現(xiàn)ffmpeg解碼器到龍芯3B的移植?
基于Hopfield神經(jīng)網(wǎng)絡的圖像矢量量化
基于DTMF的解碼器設計
基于小波變換與矢量量化的圖像壓縮研究
一種增強的LPC參數(shù)多級矢量量化技術
基于矢量量化編碼的數(shù)據(jù)壓縮算法的研究與實現(xiàn)
基于Gabor特征與投影字典的人臉識別算法
基于TMS320DM642的最大熵矢量量化實現(xiàn)
基于多級矢量量化實現(xiàn)優(yōu)化LSF參數(shù)碼本的設計

高清解碼器的作用
壓縮感知中的聯(lián)合信源信道矢量量化
一種基于變分自編碼器的人臉圖像修復方法







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論