 ChatGPT算力成本巨大,成為云廠商的一大門檻,大廠如何選擇
ChatGPT算力成本巨大,成為云廠商的一大門檻,大廠如何選擇
導讀:沒有足夠的高性能GPU數量,或者性能欠佳,都將造成AI推理和模型訓練的準確度不足,即使有類似的對話機器人, 它的“智商”也會遠低于ChatGPT
國內云廠商高性能GPU芯片的短缺,正在成為限制生成式AI在中國誕生的最直接因素。
2022年12月,微軟投資的AI創業公司OpenAI推出了聊天機器人ChatGPT。這是生成式人工智能在文本領域的實際應用。所謂生成式AI,是指依靠AI大模型和AI算力訓練來生成內容。ChatGPT的本質是OpenAI自主研發的GPT-3.5語言大模型。大型模型包含近 1800 億個參數。
微軟的 Azure 云服務為 ChatGPT 構建了超過 10,000 個 Nvidia A100 GPU 芯片的 AI 計算集群。
美國市場研究公司TrendForce在3月1日的一份報告中計算得出,要處理1800億參數的GPT-3.5大型模型,需要的GPU芯片數量高達2萬顆。未來GPT大模型商業化所需的GPU芯片數量甚至會超過3萬顆。此前在 2022 年 11 月,英偉達在其官網的公告中提到,數萬顆 A100/H100 高性能芯片部署在微軟 Azure 上。這是第一個使用 NVIDIA 高端 GPU 構建的大規模 AI 計算集群。
鑒于英偉達在高性能GPU方面的技術領先地位,國內云計算專業人士普遍認為,10000顆英偉達A100芯片是一個好的AI模型的算力門檻。
目前國內云廠商擁有的GPU主要是英偉達的中低端性能產品(如英偉達A10)。擁有超過 10,000 個 GPU 的公司不超過 5 家,而擁有 10,000 個 Nvidia A100 芯片的公司最多只有一家。也就是說,單從算力來看,短期內能夠部署ChatGPT的國內玩家非常有限。
聊天GPT看似只是一個聊天機器人,但這卻是微軟AI算力、AI大模型和生成AI在云計算的實力展示。在企業市場,這是云計算新一輪的增長點。Microsoft Azure ML(深度學習服務)擁有 200 多家客戶,其中包括制藥公司拜耳和審計公司畢馬威。Azure ML 連續四個季度收入增長超過 100%。這是微軟云三大業務中增長最快的板塊,即云、軟件、AI。
今年2月,包括阿里巴巴和百度在內的中國企業宣布將開發類似ChatGPT的產品,或將投資研發生成式人工智能。在國內,AI算力、AI大模型、生成式AI被認為只有云廠商才有資格。華為、阿里、騰訊、字節跳動、百度都有云業務,理論上都有跑通AI算力、AI大模型、生成AI應用的能力。
但是有能力不代表可以跑到終點線。這需要長期的高成本投資。GPU芯片的價格是公開的,算力成本也很容易衡量。大型模型需要數據收集、手動標記和模型訓練。這些軟成本很難簡單計算。生成式人工智能的投資規模通常高達數百億。
多位云計算廠商和服務器廠商的技術人員表示,高性能GPU芯片短缺,硬件采購成本和運營成本高,國內市場短期商用困難。這三個問題才是真正的挑戰。在他們看來,有資本儲備、戰略意愿和實踐能力的公司不會超過3家。
GPU芯片數量決定了“智商”
決定AI大模型“智商”的核心因素有三個,計算能力的規模、算法模型的復雜程度、數據的質量和數量。
AI大模型的推理和訓練高度依賴英偉達的GPU芯片。缺少芯片會導致算力不足。計算能力不足意味著無法處理龐大的模型和數據量。最終的結果是AI應用存在智商差距。
3月5日,十四屆全國人大一次會議開幕式后,科技部部長王志剛在全國兩會“部長通道”在接受媒體采訪時表示,ChatGPT作為大模型,將大數據、大算力、強算法有效結合。其計算方法有所改進,特別是在保證算法的實時性和算法質量的有效性方面。“就像發動機一樣,每個人都可以造發動機,只是質量不一樣。踢球就是運球和射門,但要做到像梅西那么好并不容易。”
Nvidia是全球知名的半導體廠商,占據了數據中心GPU市場90%以上的份額。英偉達A100芯片在2020年推出,致力于自動駕駛、高端制造、醫療醫藥行業等AI推理或訓練場景。2022年,英偉達推出了性能更強的新一代產品——H100。A100/H100是目前最強大的數據中心專用GPU,市場上幾乎沒有可擴展的替代品。包括特斯拉、Facebook在內的企業已經使用A100芯片搭建AI計算集群,采購規模超過7000顆。
多位云計算技術人員告訴記者,運行ChatGPT至少需要1萬顆英偉達A100芯片。但是,擁有超過10,000顆GPU芯片的公司不超過5家。其中,最多只有一家公司擁有 10,000 個 Nvidia A100 GPU。
另一位大型服務器廠商人士表示,即使樂觀估計,GPU儲備最大的公司也不超過5萬片,并以來自英偉達的中低端數據中心芯片(如英偉達A10) ) 為主。這些GPU芯片分散在不同的數據中心,一個數據中心通常只配備數千顆GPU芯片。
此外,由于去年8月美國政府開始實施貿易限制,中國企業長期無法獲得NVIDIA A100芯片。現有A100芯片儲備全部為存貨,剩余使用壽命約4-6年。
2022年8月31日,英偉達和AMD兩家半導體公司生產的GPU產品被美國納入限制范圍。Nvidia 的受限產品包括 A100 和 H100,AMD受監管的 GPU 產品包括 MI250。根據美國政府的要求,未來峰值性能等于或超過A100的GPU產品也被限制銷售。
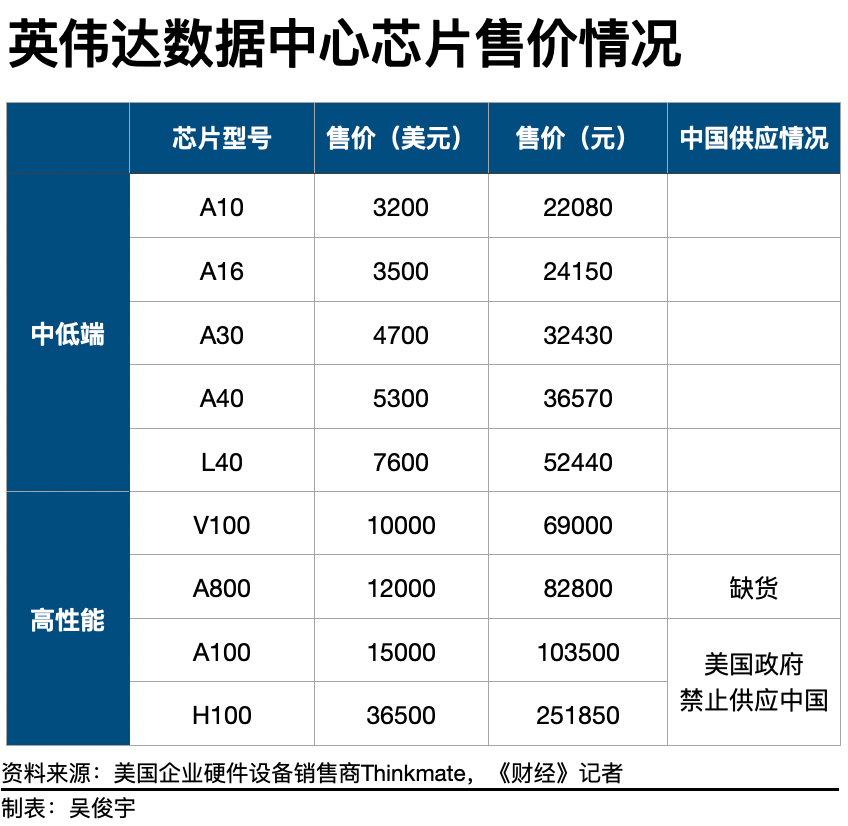
中國企業目前可以獲得的最佳替代品是英偉達的A800芯片。A800被認為是A100的“閹割版”。2022年8月,在A100被禁止在中國市場銷售后,英偉達在當年第三季度推出了專供中國市場使用的A800芯片。這款產品的計算性能與A100基本持平,但數據傳輸速度降低了30%。這會直接影響AI集群的訓練速度和效果。
不過目前A800芯片在中國市場嚴重缺貨。雖然是A100的“閹割版”,但A800在京東官網的售價卻超過了8萬元/件,甚至超過了A100的官方售價(1萬美元/件)。即便如此,A800在京東官網依然處于斷貨狀態。
一位云廠商人士告訴記者,A800的實際售價甚至高于10萬元/片,而且價格還在上漲。A800目前在浪潮、新華三等國內服務器廠商手中屬于稀缺產品,一次只能采購數百枚。
GPU 數量或性能不足直接導致 AI 推理和模型訓練的準確性不足。其結致使中國企業做出類似的對話機器人,機器人的“智商”也會遠低于ChatGPT。國內云廠商高性能GPU芯片的短缺,正成為限制中國版ChatGPT誕生的最直接因素。
成本高企
AI算力和大模型是比云還燒錢的吞金猛獸。
即使有足夠的高性能GPU,中國云廠商也將面臨高昂的硬件采購成本、模型訓練成本和日常運營成本。面對以上成本,有資本儲備、戰略選擇和實際能力的企業不超過3家。
OpenAI 可以做 ChatGPT,背后微軟提供資金和算力。2019 年,微軟向 OpenAI 投資了 10 億美元。2021年,微軟又進行一輪新投資,金額不詳。今年 1 月,微軟宣布未來幾年將向 OpenAI 投資 100 億美元。
對于云廠商來說,AI算力和大模型需要面臨高昂的硬件采購成本、模型訓練成本和日常運營成本。
一是硬件采購成本和智能計算集群建設成本。如果以10000顆英偉達A800 GPU為標配打造智能算力集群,以10萬元/顆的價格計算,光是GPU的采購成本就高達10億元。一臺服務器通常需要4-8顆GPU,一臺搭載A800的服務器成本超過40萬元。國產服務器均價在4萬-5萬元。GPU服務器的成本是普通服務器的10倍以上。服務器采購成本通常占數據中心建設成本的30%,一個智能計算集群的建設成本超過30億元。
第二,模型訓練的成本。如果算法模型要足夠準確,則需要進行多輪算法模型訓練。一家外資云廠商的資深技術人員告訴記者,ChatGPT一個完整的模型訓練成本超過1200萬美元(約合人民幣8000萬元)。如果進行10次完整的模型訓練,成本將高達8億元。GPU芯片的價格是公開的,算力成本相對容易衡量。但是,大型AI模型還需要進行數據采集、人工標注、模型訓練等一系列工作。這些軟成本很難簡單計算。具有不同效果的模型具有不同的最終成本。
第三,日常運營成本。數據中心的模型訓練會消耗網絡帶寬和電力資源。此外,模型訓練還需要算法工程師負責調優。上述成本也以數十億美元計算。
也就是說,進入AI算力和AI規模化賽道,前期的硬件采購和集群建設成本高達數十億元。后期的模型訓練、日常運營、產品研發等成本也高達數十億元。某管理咨詢公司的技術戰略合作伙伴告訴記者,生成人工智能的投資規模高達百億。
微軟大規模采購GPU構建智能計算集群,在業務邏輯上是可行的。2022年,微軟在云計算基礎設施上的支出超過250億美元。當年微軟的營業利潤達到828億美元,而微軟的云營業利潤超過400億美元。微軟的云盈利超過支出,在AI算力和大規模模型業務上的大規模投入與微軟的財務狀況相匹配。
微軟AI計算有產品、有客戶、有收入,形成新的增長點。微軟客戶通常會在云上租用數千個高性能 GPU 進行語言模型學習,以此使用他們自己的生成 AI。
微軟擁有 Azure ML 和 OpenAI。Azure ML 有 200 多家客戶,包括制藥公司拜耳和審計公司畢馬威。Azure ML 連續四個季度收入增長超過 100%。微軟云甚至形成了“云-企業軟件-AI計算”三個旋轉的增長曲線。其中,公有云Azure營收增速約為30%-40%,軟件業務營收增速約為50%-60%,AI算力營收增速超過100%。
中國企業對云基礎設施的資本支出有限,投資智能計算集群和AI大模型需要分流有限的預算支出。更大的挑戰不僅是中短期內無法盈利,還會虧損更多。
科技公司的資本支出通常用于購買服務器、建設數據中心、購買園區用地等固定資產。以亞馬遜為例,2022年的資本支出為580億美元,其中超過50%用于投資云基礎設施。阿里、騰訊、百度最近一個財年的資本支出情況,發現3家公司的數據分別為533億元、622億元、112億元。
三家公司均未披露投資云基礎設施的資本支出。假設這3家公司和亞馬遜一樣,50%的資本支出用于投資云基礎設施,數據分別為266億元、311億元、56億元。資本支出充裕的公司投資數十億美元能負擔得起,但對于資本支出不足的企業來說是一種負擔。
國內已經宣布建設智能計算集群的企業有阿里云、華為、百度等,但智能計算集群的GPU芯片數量未知。2022年,各大云廠商都把增加毛利、減少虧損作為戰略重點。現階段購買高性能GPU和構建智能計算集群需要巨大的投資。不僅會加重損失,還需要依靠群體輸血。這考驗企業管理層的戰略意志。
大模型高昂,先做小模型
華為、阿里、騰訊、字節跳動、百度都有云服務,理論上有中國版ChatGPT的實力。
云計算業內人士指出,幾家有能力的公司也會有實際的戰略考慮。比如騰訊、百度、字節跳動有云,數據量也很大,但云業務虧損,長期資金儲備和戰略意志存疑。華為依靠自研升騰芯片建立了大模型技術,但受“斷供”影響,無法獲得英偉達的GPU芯片,作為硬件廠商,缺乏互聯網公司的數據積累。
由于以上限制,目前能夠實現AI大模型商業化的公司寥寥無幾。到最后,同時具備資本儲備、戰略意志和實踐能力的企業將屈指可數。
目前,沒有一家中國云廠商像微軟那樣擁有數萬顆A100/H100芯片。目前中國云廠商的高性能GPU算力不足。更務實的觀點是,即使中國云廠商真的獲得了10000顆NVIDIA高性能GPU,也不應該簡單地投入中國版ChatGPT這一熱門應用場景。
在算力資源緊缺的情況下,可以優先投資行業市場,為企業客戶提供服務。一位管理咨詢公司的技術戰略合作伙伴認為,ChatGPT只是一個對話機器人,商業應用場景的展示暫時有限。用戶規模越大,成本越高,損失越大。如何在細分領域將AI算力和大模型商業化,是獲得正現金流的關鍵。
中國市場AI算力規模化商業模式仍處于起步階段。目前,國內已有少量自動駕駛、金融等領域客戶開始使用AI算力。例如,小鵬汽車目前使用阿里云的智能計算中心進行自動駕駛模型訓練。
一位數據中心產品經理認為,國內銀行金融客戶在反欺詐中大量使用模型訓練技術,通常只需要租用數百個性能較低的GPU訓練模型即可。也是AI計算和模型訓練,是一種成本更低的方案。事實上,通用的大規模模型并不能解決特定行業的問題,金融、汽車、消費等各個領域都需要行業模型。
中國沒有足夠的高性能 GPU 來進行大規模 AI 模型訓練,所以可以先在細分領域做小模型。人工智能技術的飛速發展已經超出了人們的認知。對于中國企業來說,根本之道還是要堅持持續布局從而達成戰略性發力。
審核編輯 :李倩
-
芯片
+關注
關注
455文章
50714瀏覽量
423145 -
云計算
+關注
關注
39文章
7774瀏覽量
137351 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7595
原文標題:ChatGPT算力成本巨大,成為云廠商的一大門檻,大廠如何選擇
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺析三大算力之異同

算力服務器為什么選擇GPU
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
華為云技術新突破:Flexus X 實例以其柔性算力加速企業一鍵上云
柔性算力的創新之作!華為云 Flexus X 實例以 6 倍性能,帶來旗艦體驗
輕松破除上云門檻,新一代柔性算力 Flexus X 實例如此簡單
助力企業數智化上云躍級提升,云耀 X 實例柔性算力一直加速一直快
華為云新一代柔性算力服務器,加速企業輕松上云數智化轉型
助力中小企業一鍵上云部署,新一代柔性算力云耀 X 實例展實力
解鎖未來,華為云耀云服務器 X 實例引領柔性算力新時代

芯科技,解密ChatGPT暢聊之算力芯片





 工商網監
工商網監
評論