 如何用10行代碼搞定圖Transformer
如何用10行代碼搞定圖Transformer
讓所有人都能快速使用圖機器學習。
2019 年,紐約大學、亞馬遜云科技聯手推出圖神經網絡框架 DGL (Deep Graph Library)。如今 DGL 1.0 正式發布!DGL 1.0 總結了過去三年學術界或工業界對圖深度學習和圖神經網絡(GNN)技術的各類需求。從最先進模型的學術研究到將 GNN 擴展到工業級應用,DGL 1.0 為所有用戶提供全面且易用的解決方案,以更好的利用圖機器學習的優勢。
DGL 1.0 為不同場景提供的解決方案。
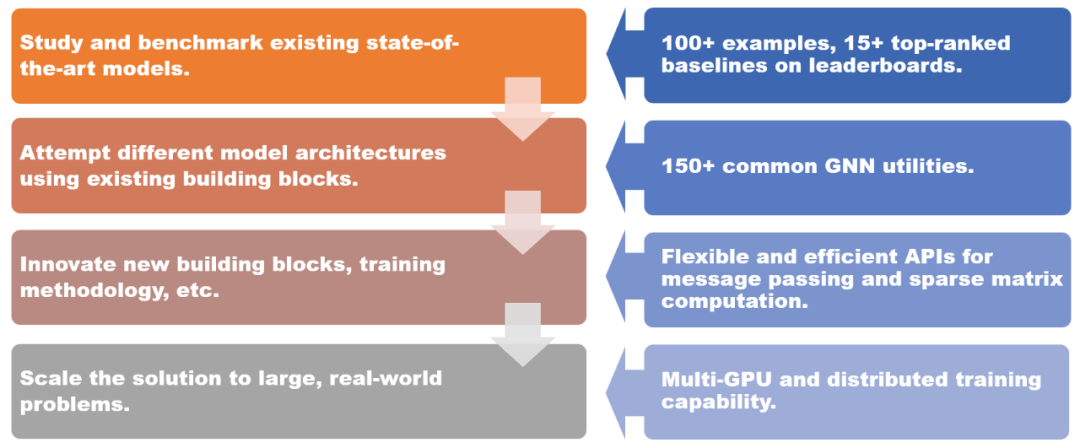
DGL 1.0 采用分層和模塊化的設計,以滿足各種用戶需求。本次發布的關鍵特性包括:
- 100 多個開箱即用的 GNN 模型示例,15 多個在 Open Graph Benchmark(OGB)上排名靠前的基準模型;
- 150 多個 GNN 常用模塊,包括 GNN 層、數據集、圖數據轉換模塊、圖采樣器等,可用于構建新的模型架構或基于 GNN 的解決方案;
- 靈活高效的消息傳遞和稀疏矩陣抽象,用于開發新的 GNN 模塊;
- 多 GPU 和分布式訓練能力,支持在百億規模的圖上進行訓練。

DGL 1.0 技術棧圖

地址:https://github.com/dmlc/dgl
此版本的亮點之一是引入了 DGL-Sparse,這是一個全新的編程接口,使用了稀疏矩陣作為核心的編程抽象。DGL-Sparse 不僅可以簡化現有的 GNN 模型(例如圖卷積網絡)的開發,而且還適用于最新的模型,包括基于擴散的 GNN,超圖神經網絡和圖 Transformer。
DGL 1.0 版本的發布在外網引起了熱烈反響,深度學習三巨頭之一 Yann Lecun、新加坡國立大學副教授 Xavier Bresson 等學者都點贊并轉發。


在接下來的文章中,作者概述了兩種主流的 GNN 范式,即消息傳遞視圖和矩陣視圖。這些范式可以幫助研究人員更好地理解 GNN 的內部工作機制,而矩陣視角也是 DGL Sparse 開發的動機之一。
消息傳遞視圖和矩陣視圖
電影《降臨》中有這么一句話:「你所使用的語言決定了你的思維方式,并影響了你對事物的看法。」這句話也適合 GNN。
表示圖神經網絡有兩種不同的范式。第一種稱為消息傳遞視圖,從細粒度、局部的角度表達 GNN 模型,詳細描述如何沿邊交換消息以及節點狀態如何進行相應的更新。第二種是矩陣視角,由于圖與稀疏鄰接矩陣具有代數等價性,許多研究人員選擇從粗粒度、全局的角度來表達 GNN 模型,強調涉及稀疏鄰接矩陣和特征向量的操作。

消息傳遞視角揭示了 GNN 與 Weisfeiler Lehman (WL)圖同構測試之間的聯系,后者也依賴于從鄰居聚合信息。而矩陣視角則從代數角度來理解 GNN,引發了一些有趣的發現,比如過度平滑問題。
總之,這兩種視角都是研究 GNN 不可或缺的工具,它們互相補充,幫助研究人員更好地理解和描述 GNN 模型的本質和特性。正是基于這個原因,DGL 1.0 發布的主要動機之一就是在已有的消息傳遞接口基礎之上,增加對于矩陣視角的支持。
DGL Sparse:為圖機器學習設計的稀疏矩陣庫
DGL 1.0 版本中新增了一個名為 DGL Sparse 的庫(dgl.sparse),它和 DGL 中的消息傳遞接口一起,完善了對于全類型的圖神經網絡模型的支持。DGL Sparse 提供專門用于 圖機器學習的稀疏矩陣類和操作,使得在矩陣視角下編寫 GNN 變得更加容易。在下一節中,作者演示多個 GNN 示例,展示它們在 DGL Sparse 中的數學公式和相應的代碼實現。
圖卷積網絡(Graph Convolutional Network)
GCN 是 GNN 建模的先驅之一。GCN 可以同時用消息傳遞視圖和矩陣視圖來表示。下面的代碼比較了 DGL 中用這兩種方法實現的區別。


使用消息傳遞 API 實現 GCN

使用 DGL Sparse 實現 GCN
基于圖擴散的 GNN
圖擴散是沿邊傳播或平滑節點特征或信號的過程。PageRank 等許多經典圖算法都屬于這一類。一系列研究表明,將圖擴散與神經網絡相結合是增強模型預測有效且高效的方法。下面的等式描述了其中比較有代表性的模型 APPNP 的核心計算。它可以直接在 DGL Sparse 中實現。


超圖神經網絡
超圖是圖的推廣,其中邊可以連接任意數量的節點(稱為超邊)。超圖在需要捕獲高階關系的場景中特別有用,例如電子商務平臺中的共同購買行為,或引文網絡中的共同作者等。超圖的典型特征是其稀疏的關聯矩陣,因此超圖神經網絡 (HGNN) 通常使用稀疏矩陣定義。以下是超圖卷積網絡(Feng et al., 2018)和其代碼實現。


圖 Transformer
Transformer 模型已經成為自然語言處理中最成功的模型架構。研究人員也開始將 Transformer 擴展到圖機器學習。Dwivedi 等人開創性地提出將所有多頭注意力限制為圖中連接的節點對。通過 DGL Sparse 工具,只需 10 行代碼即可輕松實現該模型。


DGL Sparse 的關鍵特性
相比 scipy.sparse 或 torch.sparse 等稀疏矩陣庫,DGL Sparse 的整體設計是為圖機器學習服務,其中包括了以下關鍵特性:
- 自動稀疏格式選擇:DGL Sparse 的設計讓用戶不必為了選擇正確的數據結構存儲稀疏矩陣(也稱為稀疏格式)而煩惱。用戶只需要記住 dgl.sparse.spmatrix 創建稀疏矩陣,而 DGL 在內部則會根據調用的算子來自動選擇最優格式;
- 標量或矢量非零元素:很多 GNN 模型會在邊上學習多個權重(如 Graph Transformer 示例中演示的多頭注意力向量)。為了適應這種情況,DGL Sparse 允許非零元素具有向量形狀,并擴展了常見的稀疏操作,例如稀疏 - 稠密 - 矩陣乘法(SpMM)等。可以參考 Graph Transformer 示例中的 bspmm 操作。
通過利用這些設計特性,與之前使用消息傳遞接口的矩陣視圖模型的實現相比,DGL Sparse 將代碼長度平均降低了 2.7 倍。簡化的代碼還使框架的開銷減少 43%。此外DGL Sparse 與 PyTorch 兼容,可以輕松與 PyTorch 生態系統中的各種工具和包集成。
開始使用 DGL 1.0
DGL 1.0 已經在全平臺發布,并可以使用 pip 或 conda 輕松安裝。除了前面介紹的示例之外,DGL Sparse 的第一個版本還包括 5 個教程和 11 個端到端示例,所有教程都可以在 Google Colab 中直接體驗,無需本地安裝。
想了解更多關于 DGL 1.0 的新功能,請參閱作者的發布日志。如果您在使用 DGL 的過程中遇到任何問題或者有任何建議和反饋,也可以通過 Discuss 論壇或者 Slack 聯系到 DGL 團隊。
原文鏈接:https://www.dgl.ai/release/2023/02/20/release.html
-
gpu
+關注
關注
28文章
4729瀏覽量
128890 -
數據集
+關注
關注
4文章
1208瀏覽量
24689 -
GNN
+關注
關注
1文章
31瀏覽量
6335
發布評論請先 登錄
相關推薦
如何用10行代碼輕松在ZYNQ MP上實現圖像識別

【DFRobot Beetle ESP32-C3開發板試用體驗】6行代碼搞定OLED顯示
三行搞定獨立按鍵
【DFRobot Beetle ESP32-C3開發板試用體驗】6行代碼搞定OLED顯示
【鴻蒙IPC開發板開發板體驗】+ 10行代碼 搞定HiSpark IPC DIY Camera
如何實現計算機視覺的目標檢測10行Python代碼幫你實現
濤思數據開源TDengine,10多萬行C代碼,登頂GitHub!
Transformer模型結構,訓練過程

教你如何用兩行代碼搞定YOLOv8各種模型推理






 工商網監
工商網監
評論