") 【AI簡報20230304期】 ChatGPT API 正式發(fā)布、2023年中國人工智能產(chǎn)業(yè)趨勢報告
【AI簡報20230304期】 ChatGPT API 正式發(fā)布、2023年中國人工智能產(chǎn)業(yè)趨勢報告
嵌入式 AI
?1. 2023年中國人工智能產(chǎn)業(yè)趨勢報告
原文:
http://k.sina.com.cn/article_1716314577_664ce1d1001017mhf.html
1.概述
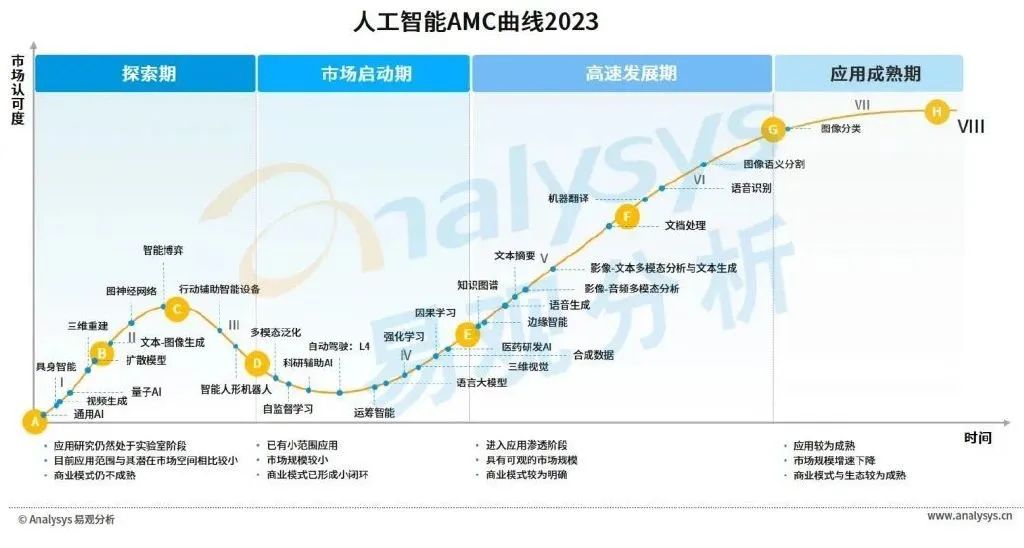
易觀人工智能AMC模型顯示,圖像分類與圖像語義分割類應(yīng)用已經(jīng)較為成熟且有著較為穩(wěn)定的市場空間,文本處理、語音識別與雙模態(tài)等應(yīng)用正逐漸實現(xiàn)對于市場的滲透。強(qiáng)化學(xué)習(xí)、因果學(xué)習(xí)、語言大模型等相關(guān)應(yīng)用通過技術(shù)的迭代成功走出實驗室,正不斷摸索其商業(yè)模式。圖神經(jīng)網(wǎng)絡(luò)、多模態(tài)泛化與自監(jiān)督學(xué)習(xí)等應(yīng)用正加速跨越從試驗研發(fā)到產(chǎn)業(yè)落地的難關(guān),對擴(kuò)散模型、量子AI、具身智能等的研究也將孕育智能程度更高、通用性更強(qiáng)的應(yīng)用。建議短期關(guān)注處于市場啟動期與高速發(fā)展期之間的應(yīng)用成熟情況,長期關(guān)注處于探索期與市場啟動期的應(yīng)用研發(fā)進(jìn)展。
2.基礎(chǔ)設(shè)施篇
趨勢1
人工智能發(fā)展需求將快速提升數(shù)據(jù)眾包產(chǎn)業(yè)規(guī)模與專業(yè)性
趨勢2
我國將形成芯片-人工智能產(chǎn)業(yè)內(nèi)循環(huán)
趨勢3
加速對邊緣智能的探索需不同類型參與方進(jìn)行緊密合作
3.算法模型篇
趨勢4
文本-圖像生成模型將出現(xiàn)針對細(xì)分領(lǐng)域需求的定制化產(chǎn)品
趨勢5
大規(guī)模語言模型在專業(yè)領(lǐng)域的商業(yè)化方向仍需持續(xù)探索
趨勢6
強(qiáng)化學(xué)習(xí)應(yīng)用或?qū)⒃诳蒲信c產(chǎn)業(yè)研發(fā)領(lǐng)域率先商業(yè)化
趨勢7
圖神經(jīng)網(wǎng)絡(luò)各類應(yīng)用的商業(yè)價值均將大幅提升
趨勢8
擴(kuò)散模型將在年內(nèi)應(yīng)用于設(shè)計、建筑、廣告等行業(yè)
4.產(chǎn)業(yè)應(yīng)用篇
趨勢9
產(chǎn)業(yè)界將出現(xiàn)更多結(jié)合算法模型原理進(jìn)行設(shè)計的智能化應(yīng)用
趨勢10
科研人工智能作為國家戰(zhàn)略其重要性將進(jìn)一步提升
趨勢11
智能設(shè)備在工業(yè)領(lǐng)域的應(yīng)用滲透率將快速提升
趨勢12
消費(fèi)領(lǐng)域?qū)π袆虞o助的需求或?qū)⒋龠M(jìn)相關(guān)智能設(shè)備先行發(fā)展
2. ChatGPT API 今日正式發(fā)布,中國廠商往何處去?
原文:
https://mp.weixin.qq.com/s/ClhnJZkU1P9cEGfJ7CZDHA
價格一折
OpenAI在官網(wǎng)發(fā)布,ChatGPT 向外界開放了API,并且開放的是已經(jīng)實裝應(yīng)用到 ChatGPT 產(chǎn)品中的 “gpt-3.5 - turbo” 模型,可以說是拿出了壓箱底的招牌武器。不僅如此,在定價上,OpenAI 僅收取每1000個 token 0.002美元的價格,是原先 GPT-3.5 模型價格的1/10。價格之低,令不少業(yè)者大跌眼鏡,以為自己小數(shù)點后多看了一個“0”。
此外,OpenAI還推出了另一個新的Whisper API,該API是由人工智能驅(qū)動的語音轉(zhuǎn)文本模型,該模型去年9月推出,并可以通過API進(jìn)行使用,這也為開發(fā)者提供了更靈活的互動方式。
先前, ChatGPT 有點小貴的價格還令一些使用者頗有微詞,并且前股東馬斯克也曾多次在推特上指責(zé) ChatGPT 閉源的行為,已經(jīng)讓 OpenAI 從一家非盈利公司,變成了微軟控制下的“走狗”。而這次API發(fā)布之人們才發(fā)現(xiàn),OpenAI 或許真的有著一顆“普惠”的心。
ChatGPT 為什么選擇在今天,以一個如此低廉的價格開放 API?他們直言:通過一系列系統(tǒng)層面的優(yōu)化,12月以來,團(tuán)隊將 ChatGPT 的成本降低了90%,而這些被節(jié)省了的費(fèi)用,則可以被團(tuán)隊用來惠及更多的開發(fā)者。
過去有消息稱,ChatGPT完成單次訓(xùn)練大概需要一個月的時間,花費(fèi)1200萬美元左右的成本。而訓(xùn)練效率的提升,無疑使AI也完成了巨大的“降本增效”。
4天前,OpenAI的創(chuàng)始人——山姆·奧特曼就曾在推特上表示:一種新的摩爾定律馬上即將成為現(xiàn)實——每過18個月,宇宙中的智能數(shù)量就會翻上一番。
此言一出,引得業(yè)內(nèi)爭議不斷。今天看來,或許是為了今天ChatGPT API 的發(fā)布造勢。
在官網(wǎng)中,他們寫道:“開發(fā)者們現(xiàn)在可以在他們的App和產(chǎn)品中,通過我們的 API 將 ChatGPT 整合其中。”
中國公司們準(zhǔn)備好了嗎?
ChatGPT 開放 API利好開發(fā)者,但對那些新進(jìn)加入 ChatGPT 賽道的創(chuàng)業(yè)者,此時也被迫感受到了一絲寒意。
入局本就落后于人,少了先發(fā)優(yōu)勢,不少人團(tuán)隊還沒完全建成,壯志豪言剛剛出口,而抬頭一看,ChatGPT已經(jīng)一騎絕塵,想要望其項背,都還需不少苦工。
而對于大廠,OpenAI 此舉也是敲山震虎——百度、阿里這樣的大廠,想做類ChatGPT 產(chǎn)品,怎么才能做得比本尊更好,投入也更少?
AI科技評論認(rèn)為,對于中國的廠商來說,ChatGPT 開放 API,也并不全然代表失去了未來生存和盈利的機(jī)會。
百度的“文心一言”、阿里的“通義”、華為的“盤古”、IDEA的“封神榜”、瀾舟的“孟子”、智源的“悟道”……在這個賽道上有所積累的玩家不少。技術(shù)層面,他們的路徑并不相同,實力上也各有千秋;如何完成更高效、廉價、貼合市場的工程化,是擺在他們面前“彎道超車”的絕佳機(jī)遇。
從“模型、算力、數(shù)據(jù)、場景”的四個因素角度上來看,大模型的算法壁壘,并沒有外界看來的如此不可逾越,隨著時間推移和研究進(jìn)步,算法性能很可能逐漸趨同;而算力方面,則是真金白銀的投入,資本和資源的比拼。
如果拋開算法、算力兩大方面,在數(shù)據(jù)和場景上,中國廠商則有很大的優(yōu)勢。
IDEA研究院的講席科學(xué)家張家興博士,曾在一次演講中做過類比:投入了數(shù)百名正式員工、上千名標(biāo)注員,用了3年時間,OpenAI 從 GPT-3 再到 ChatGPT,持續(xù)對一項模型進(jìn)行修改,并未對模型結(jié)構(gòu)進(jìn)行過創(chuàng)新。
正如搜索引擎公司,調(diào)用數(shù)萬名員工、數(shù)千標(biāo)注員,二十年如一日地打磨優(yōu)化,最終只為了將引擎做得至臻至美。
大投入、長堅持,是未來一家成功AI公司,最珍貴的品質(zhì)——若非如此,AI就做不好工程化落地的工作,而這也是中國AI公司面前最大的機(jī)會。
在數(shù)據(jù)上,越來越多業(yè)者發(fā)現(xiàn),要用AI講好中國故事,首先需要的是中國本土原生的數(shù)據(jù)集,這樣才能更貼近中文的使用,也更貼近中國的市場環(huán)境。
如果再聊到政治環(huán)境,數(shù)據(jù)脫敏、以及對于涉黃、違法、涉政內(nèi)容的風(fēng)險管控,也是大模型工程化落地,所不得不關(guān)注的核心難題。
做數(shù)據(jù)集的收集,中國廠商自然近水樓臺;而到了實際操作中,中國廠商在人力資源和成本上,也相較OpenAI要更有優(yōu)勢。
而尋找場景和技術(shù)產(chǎn)品化,更是中國廠商的強(qiáng)項。文章先前還提到的,那些將 ChatGPT 鏡像做成產(chǎn)品,賺取用戶差價的“掮客”,早在王小川、王慧文宣布入局之前,就以這種思路,賺取到了“ChatGPT”的第一桶金。
要想全民進(jìn)入AIGC時代,AI產(chǎn)品化的進(jìn)步,可以說與AI技術(shù)的進(jìn)步同等重要——技術(shù)不僅要有用,還得“能用”,讓用戶用得舒服。有國內(nèi)巨大市場作為后盾,AI產(chǎn)品一旦起勢,就很容易形成馬太效應(yīng),在用戶中形成強(qiáng)大的影響力。
ChatGPT如同一只鲇魚鉆進(jìn)了池子,用風(fēng)卷殘云之勢攪動乾坤。面臨如此強(qiáng)敵,中國的競爭者們也必須動起來,才能在激烈的競逐中獲得一席之地。
評價這件事時,張家興說道:“OpenAI是一群相信通用人工智能AGI會實現(xiàn)的人,當(dāng)我們在焦慮如何做出中國ChatGPT的時候,他們已經(jīng)在探索AGI的下一步,同時把當(dāng)下的成熟技術(shù)推向落地,這才是ChatGPT API發(fā)布這件事情真正的含義。”
3. 微軟亞研院:Language Is Not All You Need
原文:
https://mp.weixin.qq.com/s/n7ziKJeVzEzVB1w1kpsn4g
還記得這張把谷歌AI搞得團(tuán)團(tuán)轉(zhuǎn)的經(jīng)典梗圖嗎?
現(xiàn)在,微軟亞研院的新AI可算是把它研究明白了。
拿著這張圖問它圖里有啥,它會回答:我看著像鴨子。
但如果你試圖跟它battle,它就會改口:看上去更像兔子。并且還解釋得條條是道:
圖里有兔子耳朵。

是不是有點能看得懂圖的ChatGPT內(nèi)味兒了?
這個新AI名叫Kosmos-1,諧音Cosmos(宇宙)。AI如其名,本事確實不小:圖文理解、文本生成、OCR、對話QA都不在話下。
甚至連瑞文智商測試題都hold住了。
而具備如此能力的關(guān)鍵,就寫在論文的標(biāo)題里:Language is not all you need。
多模態(tài)大語言模型
簡單來說,Kosmos-1是一種把視覺和大語言模型結(jié)合起來的多模態(tài)大語言模型。
在感知圖片、文字等不同模態(tài)輸入的同時,Kosmos-1還能夠根據(jù)人類給出的指令,以自回歸的方式,學(xué)習(xí)上下文并生成回答。
研究人員表示,在多模態(tài)語料庫上從頭訓(xùn)練,不經(jīng)過微調(diào),這個AI就能在語言理解、生成、圖像理解、OCR、多模態(tài)對話等多種任務(wù)上有出色表現(xiàn)。
比如甩出一張貓貓圖,問它這照片好玩在哪里,Kosmos-1就能給你分析:貓貓戴上了一個微笑面具,看上去就像在笑。

Kosmos-1的骨干網(wǎng)絡(luò),是一個基于Transformer的因果語言模型。Transformer解碼器作為通用接口,用于多模態(tài)輸入。
用于訓(xùn)練的數(shù)據(jù)來自多模態(tài)語料庫,包括單模態(tài)數(shù)據(jù)(如文本)、跨模態(tài)配對數(shù)據(jù)(圖像-文本對)和交錯的多模態(tài)數(shù)據(jù)。
值得一提的是,雖說“Language is not all you need”,但為了讓Kosmos-1更能讀懂人類的指示,在訓(xùn)練時,研究人員還是專門對其進(jìn)行了僅使用語言數(shù)據(jù)的指令調(diào)整。
具體而言,就是用(指令,輸入,輸出)格式的指令數(shù)據(jù)繼續(xù)訓(xùn)練模型。
關(guān)于更多的細(xì)節(jié),請點擊查看原文。
4. 沒錯!真·14cm制程
原文:
https://mp.weixin.qq.com/s/OW7Rsa3Oz0FcuzLt7oYOIg
兩年時間,一個90后體制內(nèi)小哥下班之后只干三件私務(wù),那就是:
手搓CPU!手搓CPU!還是***手搓CPU!
而這個小哥也不陌生,他名叫林乃衛(wèi),相信很多讀者之前也看過量子位寫的[《B站焊武帝爆火出圈:純手工拼晶體管自制CPU,耗時半年,可跑程序》
時隔一年半,如今千呼萬喚始出來,就來康康這爆肝兩年的自研CPU終極形態(tài)到底是什么?
“底層邏輯、架構(gòu)、指令集均是自主研發(fā)”
話不多說,直接先來看手搓出來的“CPU終極形態(tài)”的參數(shù)如何:
-
頻率:13kHz,超頻最大33kHz;
-
ROM:64kB,支持熱更新,16位ROM尋址、16位靜態(tài)數(shù)據(jù)尋址;
-
內(nèi)存:系統(tǒng)內(nèi)存256B、應(yīng)用內(nèi)存64kB;
-
IO口數(shù)量:78bit(48支持位操作);
-
103條指令,功耗10瓦。
做成這樣,成本統(tǒng)共算下來只有2000元左右,若是再刨去電烙鐵、示波器這類工具,花在基礎(chǔ)器件上的錢還不到1000塊。

整體性能方面,小哥表示它和70年代初期的CPU差不多,并且在指令上還要優(yōu)于當(dāng)時的CPU。
形象點來說,目前它可以簡單刷個屏幕,顯示文字、圖像,甚至一些小游戲(類似貪吃蛇)也能跑起來。
其實在去年7月份,小哥就已經(jīng)在B站更新過一個“純手工自制CPU”的視頻,搭建的是CPU雛形,耗時6個月。
不過當(dāng)時的CPU還僅處于能跑起來的階段,要運(yùn)行更復(fù)雜的程序還比較困難。
于是小哥就開始了他的手搓“進(jìn)階版CPU”歷程,在剛制作好的CPU雛形上進(jìn)行調(diào)試維修,這一步他的計劃是:
-
把指令增加到100多條;
-
增加了堆棧、 IO 口,運(yùn)算器的這些比較復(fù)雜一點的部件,還有內(nèi)存管理;
-
可以滿足一些復(fù)雜的運(yùn)算;
……
這一把調(diào)試維修,直接就整了小哥一年半的時間。
為了有效提高CPU的性能,期間小哥下了“血本”購入了示波器這類專業(yè)器材,用來檢測整個CPU每一個節(jié)點的信號。
然后小哥以最簡易的方式去拆除了一些器件,直接把CPU的頻率從1kHz提升到33kHz,性能翻了33倍。
話說回來,徒手搓出CPU,小哥可是完全是依靠自己本科就已經(jīng)掌握的電子領(lǐng)域、IT領(lǐng)域的知識,實打?qū)嶉_發(fā)出來的。
從前期的電路仿真、PCB設(shè)計到中后期的焊接、調(diào)試以及軟件編程……小哥一個人獨(dú)攬一條“CPU生產(chǎn)線”。
(聽起來就很頭疼對吧)不過這對“愛好技術(shù)類手工制作”的小哥來說可就不一樣了。
獨(dú)創(chuàng)技術(shù)了解一下~
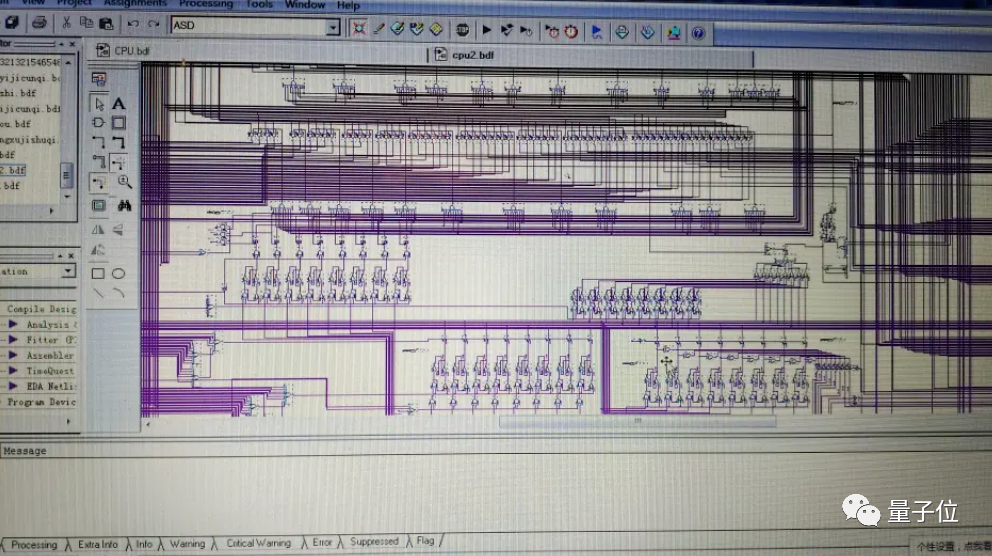
看過視頻的盆友或許都知道,小哥在視頻中特別提到了自己的獨(dú)創(chuàng)雙通道內(nèi)存。

看看這電路圖,嗯,話不多說,各位跪好,自行搜索B站視頻觀看。
5. 大卷積模型 + 大數(shù)據(jù)集 + 有監(jiān)督訓(xùn)練!探尋ViT的前身:Big Transfer (BiT)
原文:https://mp.weixin.qq.com/s/tpEEIYkFO_af7NkCAFQvUw
論文地址:https://arxiv.org/pdf/1912.11370.pdf
1 ViT 的前奏:Scale up 卷積神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)通用視覺表示
1.1 背景和動機(jī)
使用深度學(xué)習(xí)實現(xiàn)的強(qiáng)大性能通常需要大量 task-specific 的數(shù)據(jù)和計算。如果每個任務(wù)都經(jīng)歷這樣的過程,就會給新任務(wù)的訓(xùn)練過程帶來非常高昂的代價。遷移學(xué)習(xí)提供了一種解決方案:我們可以首先完成一個預(yù)訓(xùn)練 (Pre-train) 的階段,即:在一個更大的,更通用的數(shù)據(jù)集上訓(xùn)練一次網(wǎng)絡(luò),然后使用它的權(quán)重初始化后續(xù)任務(wù),這些任務(wù)可以用更少的數(shù)據(jù)和更少的計算資源來解決。
在本文中,作者重新審視了一個簡單的范例,即:在大型有監(jiān)督數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練 (注意本文是 ECCV 2020 的工作,當(dāng)時的視覺模型有監(jiān)督訓(xùn)練還是主流) ,并在目標(biāo)任務(wù)上進(jìn)行微調(diào)。本文的目標(biāo)不是引入一個新的模型,而是提供一個 training recipe,使用最少的 trick,也能夠在許多任務(wù)上獲得出色的性能,作者稱之為 Big Transfer (BiT)。
作者在3種不同規(guī)模的數(shù)據(jù)集上訓(xùn)練網(wǎng)絡(luò)。最大的 BiT-L 是在 JFT-300M 數(shù)據(jù)集上訓(xùn)練的,該數(shù)據(jù)集包含 300M 噪聲標(biāo)記的圖片。再將 BiT 遷移到不同的下游任務(wù)上。這些任務(wù)包括 ImageNet 的 ImageNet-1K,ciremote -10/100 ,Oxford-IIIT Pet,Oxford Flowers-102,以及1000樣本的 VTAB-1k 基準(zhǔn)。BiT-L 在許多這些任務(wù)上都達(dá)到了最先進(jìn)的性能,并且在很少的下游數(shù)據(jù)可用的情況下驚人地有效。
重要的是,BiT 只需要預(yù)訓(xùn)練一次,后續(xù)對下游任務(wù)的微調(diào)成本很低。BiT 不僅需要對每個新任務(wù)進(jìn)行簡短的微調(diào)協(xié)議,而且 BiT 也不需要對新任務(wù)進(jìn)行大量的超參數(shù)調(diào)優(yōu)。作者提出了一種設(shè)置超參數(shù)的啟發(fā)式方法,在多種任務(wù)中表現(xiàn)得很好。除此之外,作者強(qiáng)調(diào)了使 Big Transfer 有效的最重要的要素,并深入了解了規(guī)模、架構(gòu)和訓(xùn)練超參數(shù)之間的相互作用。
1.2 Big Transfer 上游任務(wù)預(yù)訓(xùn)練
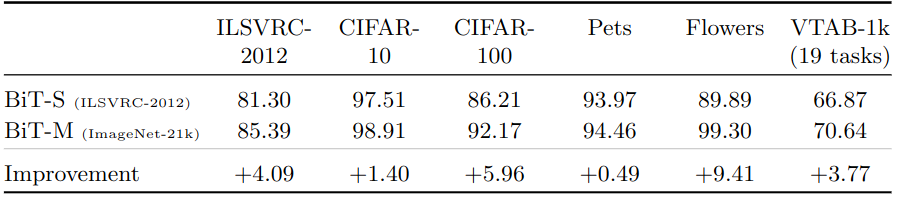
Big Transfer 上游預(yù)訓(xùn)練第一個要素是規(guī)模 (Scale)。眾所周知,在深度學(xué)習(xí)中,更大的網(wǎng)絡(luò)在各自的任務(wù)上表現(xiàn)得更好。但是,更大的數(shù)據(jù)集往往需要更大的架構(gòu)才能有收益。作者研究了計算預(yù)算 (訓(xùn)練時間)*、*架構(gòu)大小和數(shù)據(jù)集大小之間的相互作用,在3個大型數(shù)據(jù)集上訓(xùn)練了3個 BiT 模型:在 ImageNet-1K (1.3M 張圖像) 上訓(xùn)練 BiT-S, 在 ImageNet-21K (14M 張圖像) 上訓(xùn)練 BiT-M,在 JFT-300M (300M 張圖像) 上訓(xùn)練 BiT-M。
Big Transfer 上游預(yù)訓(xùn)練第二個要素是 Group Normalization[1] 和權(quán)重標(biāo)準(zhǔn)化 (Weight Standardization, WS)[2]。在大多數(shù)的視覺模型中,一般使用 BN 來穩(wěn)定訓(xùn)練,但是作者發(fā)現(xiàn) BN 不利于 Big Transfer。
原因是:
-
在訓(xùn)練大模型時,BN 的性能較差,或者會產(chǎn)生設(shè)備間同步成本。
-
由于需要更新運(yùn)行統(tǒng)計信息,BN 不利于下游任務(wù)的遷移。
當(dāng) GN 與 WS 結(jié)合時,已被證明可以提高 ImageNet 和 COCO 的小 Batch 的訓(xùn)練性能。本文中,作者證明了 GN 和WS 的組合對于大 Batch 的訓(xùn)練是有用的,并且對遷移學(xué)習(xí)有顯著的影響。
1.3 Big Transfer 下游任務(wù)遷移
作者提出了一種適用于許多不同下游任務(wù)的微調(diào)策略。作者不去對每個任務(wù)和數(shù)據(jù)集進(jìn)行昂貴的超參數(shù)搜索,每個任務(wù)只嘗試一種超參數(shù)。作者使用了一種啟發(fā)式的規(guī)則,BiT-HyperRule,選擇最重要的超參數(shù)進(jìn)行調(diào)優(yōu)。作者發(fā)現(xiàn),為每個任務(wù)設(shè)置以下超參數(shù)很重要:訓(xùn)練 Epoch、分辨率以及是否使用 MixUp 正則化。作者使用 BiT-HyperRule 處理超過20個任務(wù),訓(xùn)練集從每類1個樣本到超過1M個樣本。
在微調(diào)中,作者使用以下標(biāo)準(zhǔn)數(shù)據(jù)預(yù)處理:將圖像大小調(diào)整為一個正方形,裁剪出一個較小的隨機(jī)正方形,并在訓(xùn)練時隨機(jī)水平翻轉(zhuǎn)圖像。在測試時,只將圖像調(diào)整為固定大小。這個固定大小作者設(shè)置為把分辨率提高一點,因為作者發(fā)現(xiàn)這樣更適合遷移學(xué)習(xí)。
此外,作者還發(fā)現(xiàn) MixUp 對于預(yù)訓(xùn)練 BiT 是沒有用的,可能是由于訓(xùn)練數(shù)據(jù)比較豐富。但是,它有時對下游的遷移是有效的。令人驚訝的是,作者在下游調(diào)優(yōu)期間不使用以下任何形式的正則化技術(shù) (regularization):權(quán)值衰減到零、權(quán)值衰減到初始參數(shù)或者 Dropout。盡管網(wǎng)絡(luò)非常大,BiT 有9.28億個參數(shù),但是卻在沒有正則化的情況下,性能驚人好。作者發(fā)現(xiàn)更大的數(shù)據(jù)集訓(xùn)練更長的時間,可以提供足夠的正則化。
1.4 上游任務(wù)預(yù)訓(xùn)練實驗設(shè)置
作者在3個大型數(shù)據(jù)集上訓(xùn)練了3個 BiT 模型:在 ImageNet-1K (1.3M 張圖像) 上訓(xùn)練 BiT-S, 在 ImageNet-21K (14M 張圖像) 上訓(xùn)練 BiT-M,在 JFT-300M (300M 張圖像) 上訓(xùn)練 BiT-M。注意:“-S/M/L”后綴指的是預(yù)訓(xùn)練數(shù)據(jù)集的大小和訓(xùn)練時長,而不是架構(gòu)的大小。作者用幾種架構(gòu)大小訓(xùn)練 BiT,最大的是 ResNet152x4。
所有的 BiT 模型都使用原始的 ResNet-v2 架構(gòu),并在所有卷積層中使用 Group Normalization + Weight Standardization。
1.5 下游任務(wù)遷移實驗設(shè)置
使用的數(shù)據(jù)集分別是:ImageNet-1K, CIFAR10/100, Oxford-IIIT Pet 和 Oxford Flowers-102。這些數(shù)據(jù)集在圖像總數(shù)、輸入分辨率和類別性質(zhì)方面存在差異,從 ImageNet 和 CIFAR 中的一般對象類別到 Pet 和 Flowers 中的細(xì)粒度類別。
為了進(jìn)一步評估 BiT 學(xué)習(xí)到的表征的普遍性,作者在 Visual Task Adaptation Benchmark (VTAB) 上進(jìn)行評估。VTAB 由19個不同的視覺任務(wù)組成,每個任務(wù)有1000個訓(xùn)練樣本。這些任務(wù)被分為3組:natural, specialized and structured,VTAB-1k 分?jǐn)?shù)是這19項任務(wù)的平均識別表現(xiàn)。
下游任務(wù)遷移實驗中,大多數(shù)的超參數(shù)在所有數(shù)據(jù)集中都是固定的,但是訓(xùn)練長度、分辨率和 MixUp 的使用取決于任務(wù)圖像分辨率和訓(xùn)練集大小。
1.6 標(biāo)準(zhǔn)計算機(jī)視覺 Benchmark 實驗結(jié)果
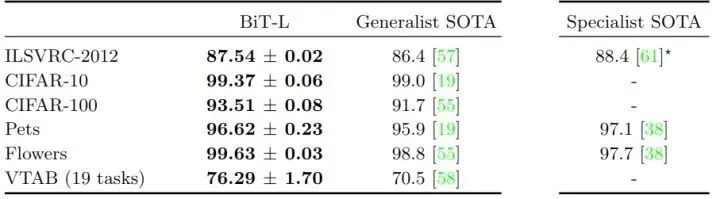
作者在標(biāo)準(zhǔn)基準(zhǔn)上評估 BiT-L,對比的結(jié)果主要有2類:Generalist SOTA 指的是執(zhí)行任務(wù)獨(dú)立的預(yù)訓(xùn)練的結(jié)果,Specialist SOTA 指的是對每個任務(wù)分別進(jìn)行預(yù)訓(xùn)練的結(jié)果。Specialist 的表征是非常有效的,但每個任務(wù)需要大量的訓(xùn)練成本。相比之下,Generalist 的表征只需要一次大規(guī)模的訓(xùn)練,然后就只有一個廉價的微調(diào)階段。
受到在 JFT-300M 上訓(xùn)練 BiT-L 的結(jié)果的啟發(fā),作者還在公開的 ImageNet-21K 數(shù)據(jù)集上訓(xùn)練模型。對于 ImageNet-1K 這種大規(guī)模的數(shù)據(jù)集,有一些眾所周知的,穩(wěn)健的訓(xùn)練過程。但對于 ImageNet-21K 這種超大規(guī)模的數(shù)據(jù)集,有14,197,122張訓(xùn)練數(shù)據(jù),包含21841個類別,在2020年,對于如此龐大的數(shù)據(jù)集,目前還沒有既定的訓(xùn)練程序,本文作者提供了一些指導(dǎo)方針如下:
-
訓(xùn)練時長:增加訓(xùn)練時長和預(yù)算。
-
權(quán)重衰減:較低的權(quán)重衰減可以導(dǎo)致明顯的加速收斂,但是模型最終性能不佳。這種反直覺的行為源于權(quán)值衰減和歸一化層的相互作用。weight decay 變低之后,導(dǎo)致權(quán)重范數(shù)的增加,這使得有效學(xué)習(xí)率下降。這種效應(yīng)會給人一種更快收斂的印象,但最終會阻礙進(jìn)一步的進(jìn)展。為了避免這種影響,需要一個足夠大的權(quán)值衰減,作者在整個過程中使用10?4。
如下圖2所示是與 ImageNet-1K 相比,在 ImageNet-21K 數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練時提高了精度,兩種模型都是 ResNet152x4。
1.7 單個數(shù)據(jù)集更少數(shù)據(jù)的實驗結(jié)果
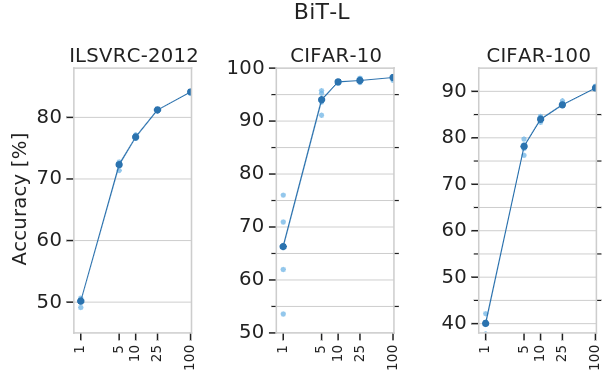
作者研究了成功轉(zhuǎn)移 BiT-L 所需的下游數(shù)據(jù)的數(shù)量。作者使用 ImageNet-1K、CIFAR-10 和 CIFAR-100 的子集傳輸BiT-L,每個類減少到1個訓(xùn)練樣本。作者還對19個 VTAB-1K 任務(wù)進(jìn)行了更廣泛的評估,每個任務(wù)有1000個訓(xùn)練樣本。實驗結(jié)果如下圖3所示,令人驚訝的是,即使每個類只有很少的樣本,BiT-L 也可以表現(xiàn)出強(qiáng)大的性能,并迅速接近全數(shù)據(jù)集的性能。特別是,在 ImageNet-1K 上,每個類只有5個標(biāo)記樣本時,其 top-1 的準(zhǔn)確度達(dá)到 72.0%,而在100個樣本時, top-1 的準(zhǔn)確度達(dá)到 84.1%。在 CIFAR-100 中,我們每個類只有10個樣本, top-1 的準(zhǔn)確度達(dá)到 82.6%。
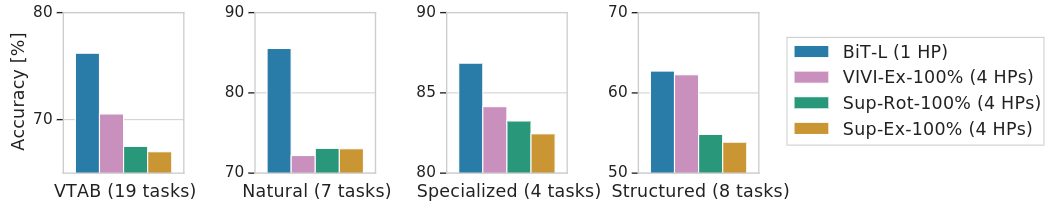
如下圖4所示是 BiT-L 在19個 VTAB-1k 任務(wù)上的性能。在研究 VTAB-1k 任務(wù)子集的性能時,BiT 在 natural, specialized 和 structured 任務(wù)上是最好的。在上游預(yù)訓(xùn)練期間使用視頻數(shù)據(jù)的 VIVIEx-100% 模型在結(jié)構(gòu)化任務(wù)上展示出非常相似的性能。
1.8 ObjectNet:真實世界數(shù)據(jù)集的實驗結(jié)果
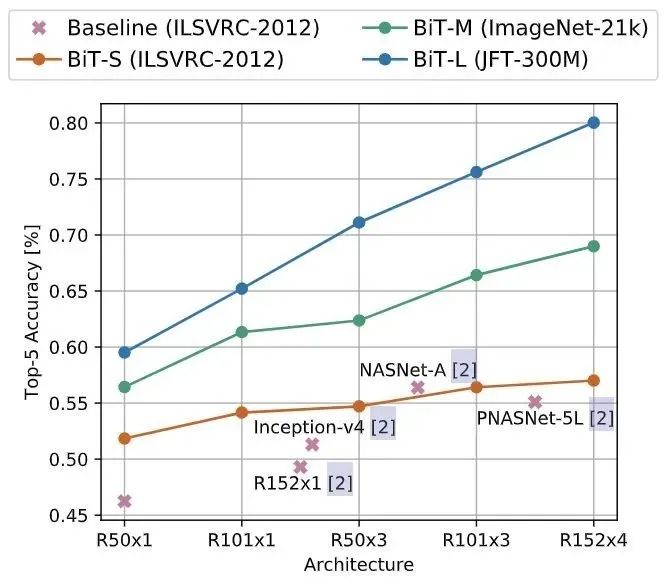
ObjectNet 數(shù)據(jù)集是一個僅包含測試集的,非常類似于現(xiàn)實場景的數(shù)據(jù)集,總共有313個類,其中113個與ImageNet-1K 重疊。實驗結(jié)果如圖5所示,更大的結(jié)構(gòu)和對更多數(shù)據(jù)的預(yù)訓(xùn)練可以獲得更高的準(zhǔn)確性。作者還發(fā)現(xiàn)縮放模型對于實現(xiàn) 80% top-5 以上的精度非常重要。
1.9 目標(biāo)檢測實驗結(jié)果
數(shù)據(jù)集使用 COCO,檢測頭使用 RetinaNet,使用預(yù)訓(xùn)練的 BiT 模型 ResNet-101x3 作為 Backbone,如下圖6所示是實驗結(jié)果。BiT 模型優(yōu)于標(biāo)準(zhǔn) ImageNet 預(yù)訓(xùn)練的模型,可以看到在 ImageNet-21K 上進(jìn)行預(yù)訓(xùn)練,平均精度 (AP) 提高了1.5個點,而在 JFT-300M 上進(jìn)行預(yù)訓(xùn)練,則進(jìn)一步提高了0.6個點。

總結(jié)
本文回顧了在大數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練的范式,并且提出了一種簡單的方法 Scale up 了預(yù)訓(xùn)練的數(shù)據(jù)集,得到的模型獲得了很好的下游任務(wù)的性能,作者稱之為 Big Transfer (BiT)。通過組合幾個精心的組件,訓(xùn)練和微調(diào)的策略,并使用簡單的遷移學(xué)習(xí)方法平衡復(fù)雜性和性能,BiT 在超過20個數(shù)據(jù)集上實現(xiàn)了強(qiáng)大的性能。
6. 神經(jīng)網(wǎng)絡(luò)INT8量化部署實戰(zhàn)教程
原文:
https://mp.weixin.qq.com/s/oxHnjABZG2xdsEFSfcJYqQ
開篇
剛開始接觸神經(jīng)網(wǎng)絡(luò)量化是2年前那會,用NCNN和TVM在樹莓派上部署一個簡單的SSD網(wǎng)絡(luò)。那個時候使用的量化腳本是參考于TensorRT和NCNN的PTQ量化(訓(xùn)練后量化)模式,使用交叉熵的方式對模型進(jìn)行量化,最終在樹莓派3B+上部署一個簡單的分類模型(識別剪刀石頭布靜態(tài)手勢)。
轉(zhuǎn)眼間過了這么久啦,神經(jīng)網(wǎng)絡(luò)量化應(yīng)用已經(jīng)完全實現(xiàn)大面積落地了、相比之前成熟多了!
我工作的時候雖然也簡單接觸過量化,但感覺還遠(yuǎn)遠(yuǎn)不夠,趁著最近項目需要,重新再學(xué)習(xí)一下,也打算把重新學(xué)習(xí)的路線寫成一篇系列文,分享給大家。
本篇系列文的主要內(nèi)容計劃從頭開始梳理一遍量化的基礎(chǔ)知識以及代碼實踐。因為對TensorRT比較熟悉,會主要以TensorRT的量化方式進(jìn)行描述以及講解。不過TensorRT由于是閉源工具,內(nèi)部的實現(xiàn)看不到,咱們也不能兩眼一抹黑。所以也打算參考Pytorch、NCNN、TVM、TFLITE的量化op的現(xiàn)象方式學(xué)習(xí)和實踐一下。
當(dāng)然這只是學(xué)習(xí)計劃,之后可能也會變動。對于量化我也是學(xué)習(xí)者,既然要用到這個技術(shù),必須要先理解其內(nèi)部原理。而且接觸了挺長時間量化,感覺這里面學(xué)問還是不少。好記性不如爛筆頭,寫點東西記錄下,也希望這系列文章在能夠幫助大家的同時,拋磚引玉,一起討論、共同進(jìn)步。
參考了以下關(guān)于量化的一些優(yōu)秀文章,不完全統(tǒng)計列了一些,推薦感興趣的同學(xué)閱讀:
-
神經(jīng)網(wǎng)絡(luò)量化入門--基本原理(https://zhuanlan.zhihu.com/p/149659607)
-
從TensorRT與ncnn看卷積網(wǎng)絡(luò)int8量化(https://zhuanlan.zhihu.com/p/387072703)
-
模型壓縮:模型量化打怪升級之路 - 1 工具篇(https://zhuanlan.zhihu.com/p/355598250)
-
NCNN Conv量化詳解(一)(https://zhuanlan.zhihu.com/p/71881443)
當(dāng)然在學(xué)習(xí)途中,也認(rèn)識了很多在量化領(lǐng)域經(jīng)驗豐富的大佬(田子宸、JermmyXu等等),嗯,這樣前進(jìn)路上也就不孤單了。
OK,廢話不多說開始吧。
Why量化
我們都知道,訓(xùn)練好的模型的權(quán)重一般來說都是FP32也就是單精度浮點型,在深度學(xué)習(xí)訓(xùn)練和推理的過程中,最常用的精度就是FP32。當(dāng)然也會有FP64、FP16、BF16、TF32等更多的精度:
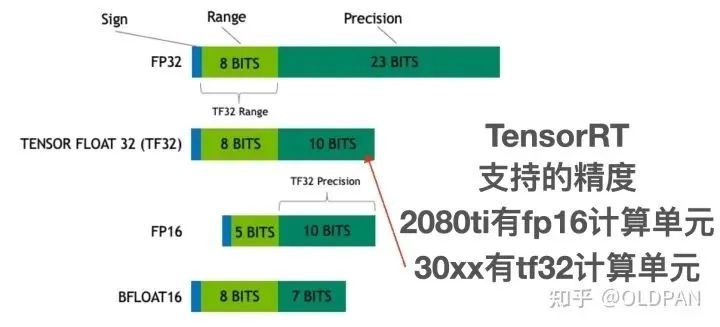
FP32 是單精度浮點數(shù),用8bit 表示指數(shù),23bit 表示小數(shù);FP16半精度浮點數(shù),用5bit 表示指數(shù),10bit 表示小數(shù);BF16是對FP32單精度浮點數(shù)截斷數(shù)據(jù),即用8bit 表示指數(shù),7bit 表示小數(shù)。TF32 是一種截短的 Float32 數(shù)據(jù)格式,將 FP32 中 23 個尾數(shù)位截短為 10 bits,而指數(shù)位仍為 8 bits,總長度為 19 (=1 + 8 + 10) bits。
對于浮點數(shù)來說,指數(shù)位表示該精度可達(dá)的動態(tài)范圍,而尾數(shù)位表示精度。之前的一篇文章中提到,F(xiàn)P16的普遍精度是~5.96e?8 (6.10e?5) … 65504,而我們模型中的FP32權(quán)重有部分?jǐn)?shù)值是1e-10級別。這樣從FP32->FP16會導(dǎo)致部分精度丟失,從而模型的精度也會下降一些。
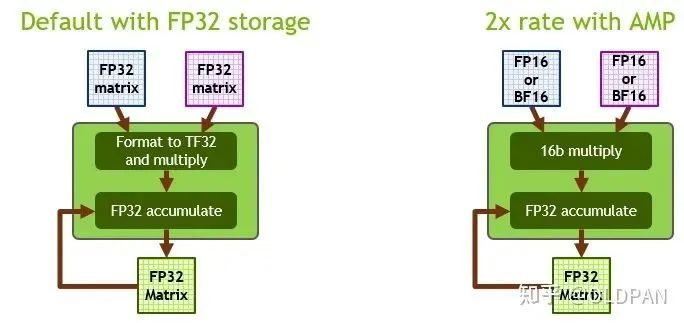
其實從FP32->FP16也是一種量化,只不過因為FP32->FP16幾乎是無損的(CUDA中使用__float2half直接進(jìn)行轉(zhuǎn)換),不需要calibrator去校正、更不需要retrain。
而且FP16的精度下降對于大部分任務(wù)影響不是很大,甚至有些任務(wù)會提升。NVIDIA對于FP16有專門的Tensor Cores可以進(jìn)行矩陣運(yùn)算,相比FP32來說吞吐量提升一倍。

實際點來說,量化就是將我們訓(xùn)練好的模型,不論是權(quán)重、還是計算op,都轉(zhuǎn)換為低精度去計算。因為FP16的量化很簡單,所以實際中我們談?wù)摰牧炕嗟氖?strong style="font-size:inherit;color:inherit;line-height:inherit;">INT8的量化,當(dāng)然也有3-bit、4-bit的量化,不過目前來說比較常見比較實用的,也就是INT8量化了,之后的重點也是INT8量化。
那么經(jīng)過INT8量化后的模型:
-
模型容量變小了,這個很好理解,F(xiàn)P32的權(quán)重變成INT8,大小直接縮了4倍
-
模型運(yùn)行速度可以提升,實際卷積計算的op是INT8類型,在特定硬件下可以利用INT8的指令集去實現(xiàn)高吞吐,不論是GPU還是INTEL、ARM等平臺都有INT8的指令集優(yōu)化
-
對于某些設(shè)備,使用INT8的模型耗電量更少,對于嵌入式側(cè)端設(shè)備來說提升是巨大的
所以說,隨著我們模型越來越大,需求越來越高,模型的量化自然是少不了的一項技術(shù)。
如果你擔(dān)心INT8量化對于精度的影響,我們可以看下NVIDIA量化研究的一些結(jié)論: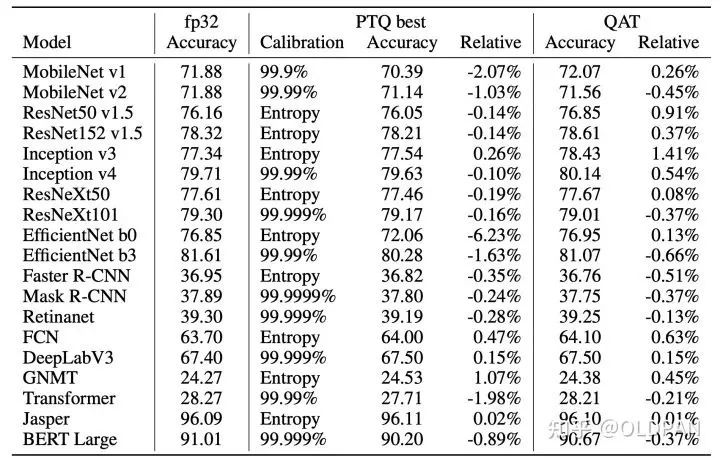
量化現(xiàn)狀
量化技術(shù)已經(jīng)廣泛應(yīng)用于實際生產(chǎn)環(huán)境了,也有很多大廠開源了其量化方法。不過比較遺憾的是目前這些方法比較瑣碎,沒有一套比較成熟比較完善的量化方案,使用起來稍微有點難度。不過我們?nèi)钥梢詮倪@些框架中學(xué)習(xí)到很多。
谷歌是比較早進(jìn)行量化嘗試的大廠了,感興趣的可以看下Google的白皮書Quantizing deep convolutional networks for efficient inference: A whitepaper以及Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference。
TensorFlow很早就支持了量化訓(xùn)練,而TFLite也很早就支持了后訓(xùn)練量化,感興趣的可以看下TFLite的量化規(guī)范 (https://www.tensorflow.org/lite/performance/quantization_spec) ,目前TensorRT支持TensorFlow訓(xùn)練后量化的導(dǎo)出的模型。
TensorRT
TensorRT在2017年公布了自己的后訓(xùn)練量化方法,不過沒有開源,NCNN按照這個思想實現(xiàn)了一個,也特別好用。不過目前TensorRT8也支持直接導(dǎo)入通過ONNX導(dǎo)出的QTA好的模型,使用上方便了不少,之后會重點講下。

TVM
TVM有自己的INT8量化操作,可以跑量化,我們也可以添加自己的算子。不過TVM目前只支持PTQ,可以通過交叉熵或者percentile的方式進(jìn)行校準(zhǔn)。不過如果動手能力強(qiáng)的話,應(yīng)該可以拿自己計算出來的scale值傳入TVM去跑,應(yīng)該也有人這樣做過了。
比較有參考意義的一篇:
-
ViT-int8 on TVM:提速4.6倍,比TRT快1.5倍(https://zhuanlan.zhihu.com/p/365686106)
當(dāng)然還有很多優(yōu)秀的量化框架,想看詳細(xì)的可以看這篇(https://zhuanlan.zhihu.com/p/355598250),后續(xù)如果涉及到具體知識點也會再提到。
更多關(guān)于量化的基礎(chǔ)理論和技巧,請點擊原文查看。
———————End———————
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進(jìn)RT-Thread官方微信交流群!
↓點擊閱讀原文
愛我就請給我在看
原文標(biāo)題:【AI簡報20230304期】 ChatGPT API 正式發(fā)布、2023年中國人工智能產(chǎn)業(yè)趨勢報告
文章出處:【微信公眾號:RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
RT-Thread
+關(guān)注
關(guān)注
31文章
1293瀏覽量
40193
原文標(biāo)題:【AI簡報20230304期】 ChatGPT API 正式發(fā)布、2023年中國人工智能產(chǎn)業(yè)趨勢報告
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
燧原科技亮相2024中國人工智能大會
華為推動中國人工智能框架生態(tài)高速發(fā)展
軟通動力入選《人工智能數(shù)據(jù)標(biāo)注產(chǎn)業(yè)圖譜》
2025 福布斯中國人工智能科技企業(yè) TOP 50 評選正式啟動

名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內(nèi)外大咖齊聚話AI
達(dá)闥機(jī)器人榮登“2024福布斯中國人工智能科技企業(yè)TOP 50”

Nullmax榮登「中國人工智能與大數(shù)據(jù)產(chǎn)業(yè)最佳投資案例TOP10」榜單

愛芯元智榮登“2024福布斯中國人工智能科技企業(yè)TOP 50”榜單

云天勵飛榮譽(yù)入選“2024福布斯中國人工智能科技企業(yè)”

2024中國AI大模型產(chǎn)業(yè)發(fā)展報告

在FPGA設(shè)計中是否可以應(yīng)用ChatGPT生成想要的程序呢
2024 人工智能安全報告





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論