 【AI簡報20230310】知存科技再推存算一體芯片、微軟:多模態大模型GPT-4就在下周
【AI簡報20230310】知存科技再推存算一體芯片、微軟:多模態大模型GPT-4就在下周
嵌入式 AI
AI 簡報 20230310 期
1. 知存科技再推存算一體芯片,用AI技術推動助聽器智能化
原文:
https://mp.weixin.qq.com/s/reQvUTJlOJSqEtHGKL4QbA
2022年3月,知存科技量產的國際首顆存內計算SoC芯片WTM2101正式投入市場。如今已在端側實現商用,提供語音、視頻等AI處理方案并幫助產品實現10倍以上的能效提升。WTM2101采用40nm工藝,是一顆擁有高算力存內計算核的芯片,相對于NPU、DSP、MCU計算平臺、AI算力提升10-200倍,具備1.8MB權重、50Gops算力。
顧名思義,存內計算芯片采用存算一體架構,區別于傳統計算架構馮諾伊曼以計算為中心的設計,改為以數據存儲為中心的設計。由于馮諾伊曼架構存在一定的局限性,那就是隨著CPU,或者運算單元的運算能力提高,數據傳輸并沒有跟上CPU運算頻率的同步遞增,這樣就出現存儲墻。
知存科技FAE總監陸彤表示,存儲墻會帶來兩個弊端,一是時延問題,因為由數據從memory 搬到計算單元里是需要時間的,當然也有不同的解決方法,比如采用更快的存儲單元、更寬的數據通道,或者是采用分布式的方式進行存儲。二是功耗問題,預計會占整個芯片功耗的50%-90%左右。
存算一體架構通過在存儲體上采用不同的技術,或者叫重新設計,讓存儲器件單元能直接完成乘加計算,也能存儲數據,極大程度上解決了存儲墻的問題,從而大幅度提升芯片的運行效率,突破瓶頸。
WTM2101在助聽器領域,能夠提供增益調整、EDRC等助聽基本功能,知存科技FAE總監陸彤介紹WTM2101在助聽領域更突出的價值更多還是體現在AI 相關應用上,例如雙麥BF+AI-ENC降噪實現智能融合降噪,能夠做到11ms延時、20db降噪。WTM2101還加入了AI通透功能,能夠選擇性通透電視、音樂等有效聲音。
防嘯叫是助聽器的剛需功能,為了實現該功能,WTM2101除了實施傳統的嘯叫算法,也添加了NN抗嘯叫算法組合;在健康監測方面,還加入了低功耗NN心率算法,并且實現了超低功耗標準模式50uA、運動模式為80uA。
此外,由于助聽器應用在耳道里面,沒有什么按鍵或者其他的方式能夠操作,因此自動環境識別也是助聽器產品需要關注的重點,目前,業內有廠商計劃采用語音控制的方式實現,或者基于AI深度學習/經典算法,進行環境音檢測。WTM2101加入了關鍵詞喚醒功能,算力約為10~20Mops。“如果從算力上來看,這些算法需要上百,甚至上G的OPS 算力需求,可能業內其他產品部署起來會有算力的壓力。但WTM2101具備50Gops算力,是能夠完成這些工作的”。
在低分辨率下,當信噪比到- 10db甚至-5db更低,佩戴者在使用助聽器時就很難區分語音。而WTM2101具備人聲增強功能,PESQ相對小算力AI算法和經典算法提高0.4和0.5.
據了解,飛利浦在去年推出飛利浦HearLink30平臺助聽器,引入了多種AI智能技術。不難發現,在技術的成熟下,越來越多AI技術的應用讓助聽器變得更加智能。“AI給助聽器帶來了很大的升級,AI在智能降噪、去嘯叫和環境識別上面有很大優勢”,知存科技相關負責人對電子發燒友網表示。目前已有多款助聽器不僅僅是助聽功能,還具備健康監測等更多功能,降噪功能也越來越強大。
2. 邊緣人工智能芯片制造商Hailo推出Hailo-15
原文:
https://mp.weixin.qq.com/s/ClhnJZkU1P9cEGfJ7CZDHA
邊緣人工智能(AI)處理器的先鋒芯片制造商Hailo今天公布了突破性的新型Hailo-15系列高性能視覺處理器,該系列旨在直接集成到智能攝像機中,在邊緣提供前所未有的視頻處理和分析。
隨著Hailo-15的推出,該公司正在重新定義智能攝像機類別,在計算機視覺和深度學習視頻處理方面設立新標準,能夠在不同行業的廣泛應用中帶來突破性的人工智能性能。
利用Hailo-15,智能城市運營商可以更迅速地檢測和應對事件;制造商可以提高生產力和機器正常運行時間;零售商可以保護供應鏈并提高客戶滿意度;交通當局可以識別走失的兒童、事故、放錯地方的行李等各種對象。
"Hailo-15代表著在使邊緣人工智能更加可擴展和可負擔方面邁出的重要一步。"Hailo首席執行官Orr Danon表示,"通過這次發布,我們正在利用我們在已被全球數百家客戶部署的邊緣解決方案方面的領先地位,我們的人工智能技術的成熟度以及我們全面的軟件套件,從而以攝像機外形尺寸實現高性能人工智能。"
Hailo-15 VPU系列包括三個型號:Hailo-15H、Hailo-15M和Hailo-15,以滿足智能攝像機制造商和AI應用提供商的不同處理需求和價格點。這個VPU系列的性能達到7 TOPS(每秒萬億次運算)至驚人的20 TOPS,比目前市場上的解決方案高出5倍以上,而價格相當。所有Hailo-15 VPU都支持4K分辨率的多輸入流,將強大的CPU和DSP子系統與Hailo經過現場驗證的AI核心相結合。
通過在攝像機中引入優異的人工智能功能,Hailo正在滿足市場上對增強邊緣視頻處理和分析能力的日益增長的需求。憑借這種無與倫比的人工智能能力,搭載Hailo-15的攝像機可以進行明顯更多的視頻分析,并行運行多個人工智能任務,包括更快的高分辨率檢測,從而能夠識別更小、更遠的對象,并具有更高的準確性和更少的錯誤警報。
例如,Hailo-15H能夠在高輸入分辨率(1280x1280)下以實時傳感器速率運行最先進的對象檢測模型YoloV5M6,或以非凡的700 FPS運行行業分類模型基準ResNet-50。
通過這個高性能人工智能視覺處理器系列,Hailo率先在攝像機中使用基于視覺的transformers進行實時對象檢測。增加的人工智能能力還可用于視頻增強和低光環境下的更優視頻質量,實現視頻穩定和高動態范圍性能。
3. AI算力芯片:人工智能核心底座,7年空間13倍,國產替代之關鍵
原文:https://baijiahao.baidu.com/s?id=1759514012109489440&wfr=spider&for=pc
還記得這張把谷歌AI搞得團團轉的經典梗圖嗎?
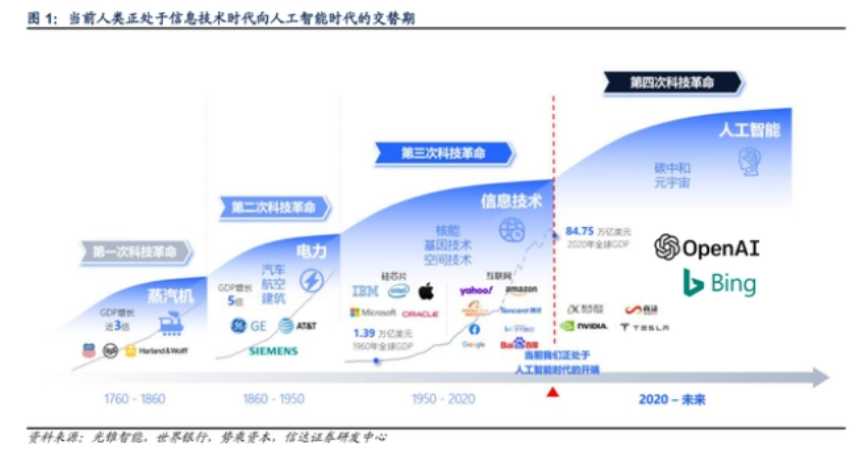
每一次科技創新浪潮都是突破某一項生產力要素,從而提升人類生產效率。
人工智能引領著新一輪科技革命,而生成式AI的出現,真正賦予了人工智能大規模落地的場景,有望在更高層次輔助甚至代替人類工作,提升人類生產效率。
今年,生成式AI代表產品ChatGPT所產生的鯰魚效應持續發酵,引發市場廣泛關注。
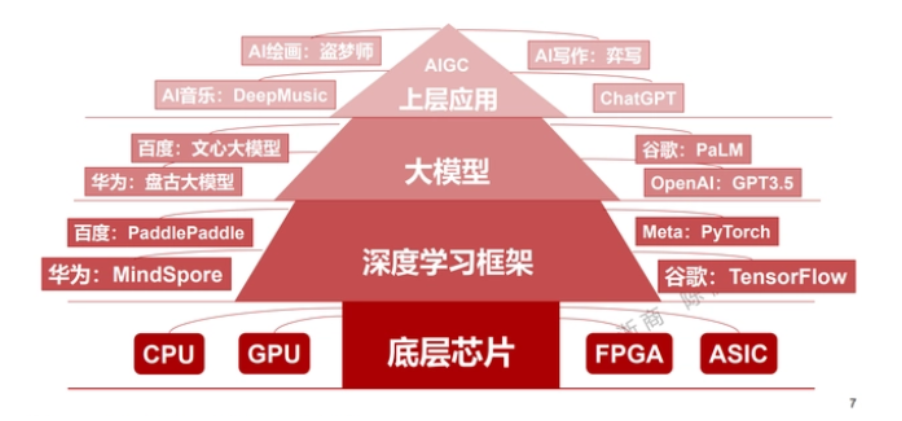
深入了解后能夠發現,生成式AI競爭的焦點主要有兩個,一是巨大參數量、超大規模的AI模型,二是提供超強算力的AI芯片,兩者缺一不可。
市場也逐漸意識到,人工智能的競爭是巨頭之間的競爭,巨額研發投入迫使小公司聚焦于上層應用,同時,底層算力支撐愈發關鍵,沒有扎實的底盤,上層建筑皆是空中樓閣。
不僅在人工智能,在整個數字經濟當中,下游技術應用的實現,都離不開算力。
算力,是國內的短板,而國際供應鏈問題愈發凸顯,算力不足的問題可能顯現,不僅對人工智能有影響,還將影響整個數字經濟,所以,算力芯片成為突圍關鍵點。
AI算力芯片需求激增
AI算力進入大模型時代,大模型的實現需要強大的算力來支撐訓練和推理過程。比如Open AI,微軟專門為其打造了一臺超級計算機,專門用來在Azure公有云上訓練超大規模的人工智能模型
這臺超級計算機擁有28.5萬個CPU核心,超過1萬顆GPU(英偉達 V100 GPU),按此規格,如果自建IDC,以英偉達A100 GPU芯片替代V100 GPU芯片,依照性能換算,大約需要3000顆A100 GPU芯片。
想要了解更多內容,請點擊查看原文。
4. 全方位分析大模型參數高效微調,清華研究登Nature子刊
原文:
https://mp.weixin.qq.com/s/wHc87AZafnRp8eMFOJxPoA
近年來,清華大學計算機系孫茂松團隊深入探索語言大模型參數高效微調方法的機理與特性,與校內其他相關團隊合作完成的研究成果 “面向大規模預訓練語言模型的參數高效微調”(Parameter-efficient Fine-tuning of Large-scale Pre-trained Language Models)3 月 2 日在《自然?機器智能》(Nature Machine Intelligence)上發表。該研究成果由計算機系孫茂松、李涓子、唐杰、劉洋、陳鍵飛、劉知遠和深圳國際研究生院鄭海濤等團隊師生共同完成,劉知遠、鄭海濤、孫茂松為該文章的通訊作者,清華大學計算機系博士生丁寧(導師鄭海濤)與秦禹嘉(導師劉知遠)為該文章的共同第一作者。
論文鏈接:https://www.nature.com/articles/s42256-023-00626-4
OpenDelta 工具包:https://github.com/thunlp/OpenDelta
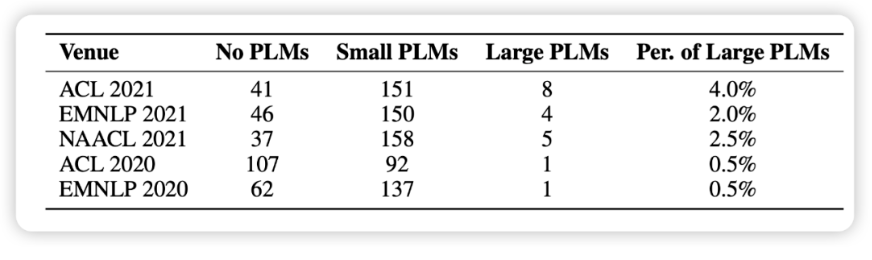
2018 年以來,預訓練語言模型 (PLM) 及其 “預訓練 - 微調” 方法已成為自然語言處理(NLP)任務的主流范式,該范式先利用大規模無標注數據通過自監督學習預訓練語言大模型,得到基礎模型,再利用下游任務的有標注數據進行有監督學習微調模型參數,實現下游任務的適配。
隨著技術的發展,PLM 已經毫無疑問地成為各種 NLP 任務的基礎架構,而且在 PLM 的發展中,呈現出了一個似乎不可逆的趨勢:即模型的規模越來越大。更大的模型不僅會在已知任務上取得更好的效果,更展現出了完成更復雜的未知任務的潛力。
然而,更大的模型也在應用上面臨著更大的挑戰,傳統方法對超大規模的預訓練模型進行全參數微調的過程會消耗大量的 GPU 計算資源與存儲資源,巨大的成本令人望而卻步。這種成本也造成了學術界中的一種 “慣性”,即研究者僅僅在中小規模模型上驗證自己的方法,而習慣性地忽略大規模模型。
在本文的統計中,我們隨機選取了 1000 篇來自最近五個 NLP 會議的論文,發現使用預訓練模型已經成為了研究的基本范式,但涉及大模型的卻寥寥無幾(如圖 1 所示)。
在這樣的背景下,一種新的模型適配方案,參數高效(Parameter-efficient) 方法逐漸受到關注,與標準全參數微調相比,這些方法僅微調模型參數的一小部分,而其余部分保持不變,大大降低了計算和存儲成本,同時還有著可以媲美全參數微調的性能。我們認為,這些方法本質上都是在一個 “增量”(Delta Paremters)上進行調整,因此將它命名為 Delta Tuning。
在本文中,我們定義和描述了 Delta Tuning 問題,并且通過一個統一的框架對以往的研究進行梳理回顧。在這個框架中,現有的 Delta Tuning 方法可以被分為三組:增量式(Addition-based)、指定式(Specification-based)和重參數化(Reparameterization)的方法。
除去實踐意義之外,我們認為它還具有非常重要的理論意義,Delta Tuning 在某種程度上昭示著大模型的背后機理,有助于我們進一步發展面向大模型甚至深度神經網絡的理論。為此,我們從優化和最優控制兩個角度,提出理論框架去討論 Delta Tuning,以指導后續的結構和算法設計。此外,我們對代表性方法進行了全面的實驗對比,并在超過 100 個 NLP 任務的結果展示了不同方法的綜合性能比較。實驗結果涵蓋了對 Delta Tuning 的性能表現、收斂表現、高效性表現、Power of Scale、泛化表現、遷移性表現的研究分析。我們還開發了一個開源工具包 OpenDelta,使從業者能夠高效、靈活地在 PLM 上實現 Delta Tuning。

方法優勢:
快速訓練與存儲空間節省。Transformer 模型雖然本質上是可并行化的,但由于其龐大的規模,訓練起來非常緩慢。盡管 Delta Tuning 的收斂速度可能比傳統的全參數微調慢,但隨著反向傳播期間可微調參數的計算量顯著減少,Delta Tuning 的訓練速度也得到了顯著提升。以前的研究已經驗證了,使用 Adapter 進行下游調優可以將訓練時間減少到 40%,同時保持與全參數微調相當的性能。由于輕量的特性,訓練得到的 Delta 參數還可以節省存儲空間,從而方便在從業者之間共享,促進知識遷移。
多任務學習。構建通用的人工智能系統一直是研究人員的目標。最近,超大型 PLM (例如 GPT-3) 已經展示了同時擬合不同數據分布和促進各種任務的下游性能的驚人能力。因此,在大規模預訓練時代,多任務學習受到越來越多的關注。作為全參數微調方法的有效替代,Delta Tuning 具有出色的多任務學習能力,同時保持相對較低的額外存儲。成功的應用包括多語言學習、閱讀理解等。此外,Delta Tuning 也有望作為持續學習中災難性遺忘的潛在解決方案。在預訓練期間獲得的語言能力存儲在模型的參數中。因此,當 PLM 在一系列任務中按順序進行訓練時,在沒有正則化的情況下更新 PLM 中的所有參數可能會導致嚴重的災難性的遺忘。由于 Delta Tuning 僅調整最小參數,因此它可能是減輕災難性遺忘問題的潛在解決方案。
中心化模型服務和并行計算。超大型 PLM 通常作為服務發布,即用戶通過與模型提供者公布的 API 交互來使用大模型,而不是本地存儲大模型。考慮到用戶和服務提供商之間難以承受的通信成本,由于其輕量級的特性,Delta Tuning 顯然是比傳統全參數微調更具競爭力的選擇。一方面,服務提供商可以支持訓練多個用戶所需的下游任務,同時消耗更少的計算和存儲空間。此外,考慮到一些 Delta Tuning 算法本質上是可并行的(例如 Prompt Tuning 和 Prefix-Tuning 等),因此 Delta Tuning 可以允許在同一個 batch 中并行訓練 / 測試來自多個用戶的樣本(In-batch Parallel Computing)。最近的工作還表明,大多數 Delta Tuning 方法,如果本質上不能并行化,也可以通過一些方法修改以支持并行計算。另一方面,當中心的達模型的梯度對用戶不可用時,Delta Tuning 仍然能夠通過無梯度的黑盒算法,僅調用模型推理 API 來優化大型 PLM。
更多的細節,請點擊鏈接查看原文。
5. 目標檢測中正負樣本的問題經驗分析
https://mp.weixin.qq.com/s/9C7mszKErCCoSs0sYB3YcA
1. 什么是正負樣本?
對于像YOLO系列的結構,正負樣本就是feature map上的每一個grid cell(或者說對應的anchor)。
對于像RCNN系列的結構,RPN階段定義的正負樣本其實和YOLO系列一樣,也是每一個grid cell。RCNN階段定義的正負樣本是RPN模塊輸出的一個個proposals,即感興趣區域(region of interesting,roi),最后會用RoIPooling或者RoIAlign對每一個proposal提取特征,變成區域特征,這和grid cell中的特征是不一樣的。
對于DETR系列,正負樣本就是Object Queries,與gt是嚴格的一對一匹配。而YOLO,RCNN是可以多對一的匹配。
通常情況下,檢測問題會涉及到3種不同性質的樣本:
正樣本(positive)
對于positive,一旦判定某個grid cell或者proposal是正樣本,你就需要對其負責cls+bbox的訓練。
忽略樣本(ignore)
ignore最大的用處就是可以處理模棱兩可的樣本,以及影響模型訓練的樣本。所以對于ignore,對其不負責任何訓練,或者對其負責bbox的訓練,但是不負責cls的訓練。
負樣本(negative)
對于negative,只負責cls的訓練,不負責bbox的訓練。
2. 怎么定義哪些是正樣本/ignore/負樣本
常規使用的方法:
借助每個grid cell中人為設置的anchor,計算其與所有gt(ground truth)的iou,通過iou的信息來判定每個grid cell屬于positive/ignore/negative哪種。
以當前gt為中心的一定范圍內,去判定每個grid cell屬于哪種樣本。
在具體的自動駕駛量產項目中,往往會根據實際需求,比如對precision和recall的要求,在與gt匹配的邏輯中,會從類別、大小等角度去考慮,另外還會考慮特殊標記的gt框(hard、dontcare)。
有以下幾個原則:
-
數量少的類別A,為其盡可能匹配適當多一點的anchor,數量多的類別B,為其匹配少量且高質量的anchor。這樣做目的是提高A的recall,提高B的precision,保證每個batch中,各類別間生成的正樣本數量趨于1:1
-
為小目標匹配高質量的anchor,忽略其周圍低質量的anchor。這樣做是為了減少小目標的誤檢,可能在一定程度上犧牲了召回。
-
對于中大目標,就要考慮具體那個類別的數量了,數量少的類別匹配多一點,數量多就少匹配。
-
對于特殊標記的gt框,如hard、dontcare, 如果一些負樣本和這些hard、dontcare強相關,那么把這些負樣本變成ignore,避免讓樣本間產生歧義。
正負樣本的定義過程是一個迭代的過程,會根據模型的實際訓練過程以及測試效果來動態調整,比如模型對某個類recall偏低,那么此時我們就要增加該類生成正樣本的數量了。
定義的過程就是將正負樣本嚴格區分開,為后續的采樣提供方便,如下圖,將從正樣本過渡到負樣本的這些樣本歸入ignore。
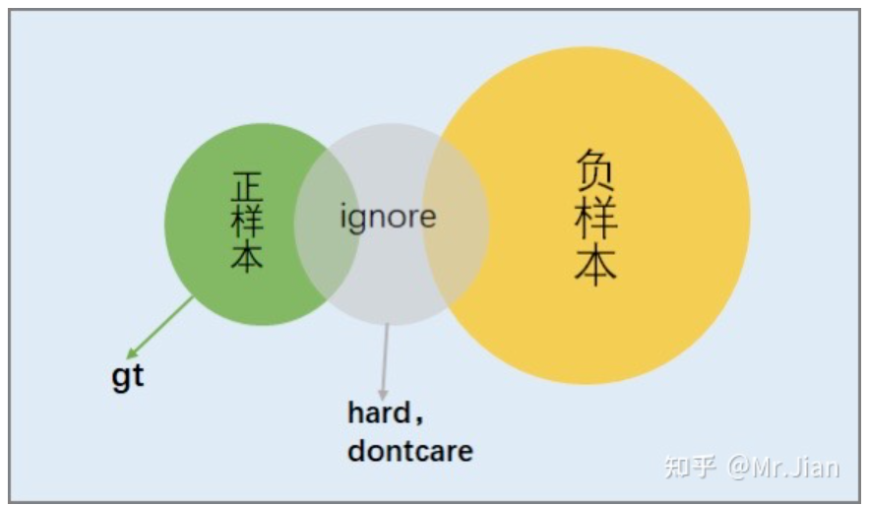
3. 采樣哪些正負樣本參與訓練
個人認為:該部分是訓練檢測模型最為核心的部分,直接決定模型最后的性能。理解正負樣本的訓練,實質是理解正負樣本的變化是如何影響precision和recall的。
我們先考慮3個基本問題,對于某個類別gt:
-
假設我們希望precision=1,不考慮recall,那么屬于該gt的并且參與訓練的正負樣本理想情況會是什么樣的?
正樣本:數量越多越好,并且質量越高越好。
負樣本:多樣性越豐富越好,數量越多越好(實際已經滿足數量多的情況)。
-
假設我們希望recall=1,不考慮precision呢?
正樣本:數量越多越好。
負樣本:數量為0最好。
-
現在我們希望precision=1, recall=1呢?
正樣本:數量越多越好,并且質量越高越好。
負樣本:多樣性越豐富越好,并且數量越多越好。
從以上3個問題分析得到,對于某個類別的gt,屬于該gt的正樣本中,數量和質量是矛盾的。數量越多,那么質量必然下降,recall會偏高,precision會偏低。反之,數量越少,質量會高,但是recall會偏低,precision會偏高。對于負樣本來說,要求它數量越多,并且多樣性越豐富,這并不矛盾,實際是可以做到這點。
有人會問,不看mAP嗎?
mAP是綜合衡量了recall從0到1變化的過程中(實際recall達不到1),precision的變化曲線,mAP并不直觀,實際把mAP當做其中一個衡量指標而已。
所以,我們采樣的目標就是:
正樣本:質量高,數量適當
負樣本:多樣性越豐富,數量適當(或者說是正樣本數量的n倍,n一般取值[3,10])
一般情況下,定義的那些正樣本都會采樣參與訓練,負樣本就隨機采樣一些去訓練。但在訓練的過程中你需要考慮幾點:
-
定義的那些正樣本,模型真的都能搞定嗎?
在量產級的數據集中,往往會有百千萬量級的目標,雖然在定義正樣本的時候考慮到了很多因素,但是面對百千萬量級的目標,往往會存在一定比例的正樣本,模型壓根就學不會,訓練后期模型loss就在一個小區間里震蕩,所以我們就要對這些樣本做進一步處理,把其歸為ignore,減少他們對模型訓練的影響。
對于FN(漏檢),我們就要根據具體的需求分析這些FN到底是否需要檢出,如果需要檢出,就需要調整定義這些FN的正樣本的匹配邏輯,讓其產生適合訓練的正樣本。
-
面對數量眾多的負樣本,怎么針對性的采樣(適應自己的項目)。
其實在項目前期,負樣本的采樣可以選擇隨機,但當你進行大量路采數據測試后,總結發現模型輸出的FP,比如,發現模型輸出大框背景的頻次偏高,那么這個時候我們就要改變隨機采樣負樣本的策略,就要針對性的增加小分辨率feature map上的負樣本的采樣。如果模型經常把特定背景(樹尖,房屋)檢測為目標,那么我們需要1. 檢查gt的標注質量。2. 想辦法采樣到這類的負樣本參與訓練。
-
盡可能保證每個batch中,類別間采樣的正樣本比例為1:1。
在量產級數據中,因為是實車采集,往往會出現類別不均衡現象,隨著數據量的不斷增加,這種不均衡會被嚴重放大,如果直接采樣全部正樣本采樣訓練,模型很可能出現precision和recall偏向類別多的那個類,比如類A,這個時候就需要考慮適當降低類A的采樣,同時考慮適當增加類B類C的采樣訓練,來達成類別間正樣本的比例接近1:1。
所以,正負樣本的采樣是根據當前模型的檢測效果來動態改變優化的,但是不管怎么改變,對正負樣本的采樣不會偏離理想狀態的,只不過離理想狀態的距離由自己手頭的數據集標注質量決定。
6. 微軟:多模態大模型GPT-4就在下周,撞車百度?
原文:
https://mp.weixin.qq.com/s/Se3xzcF6rtgcI7YXYgDZ8Q
我們知道,引爆如今科技界軍備競賽的 ChatGPT 是在 GPT-3.5 上改進得來的,OpenAI 很早就預告 GPT-4 將會在今年發布。最近各家大廠爭相入局的行動似乎加快了這個進程。
最新消息是,萬眾期待的 GPT-4 下周就要推出了:在 3 月 9 日舉行的一場名為「AI in Focus - Digital Kickoff」的線下活動中,四名微軟德國員工展示了 GPT 系列等大型語言模型(LLM)的顛覆性力量,以及 OpenAI 技術應用于 Azure 產品的詳細信息。
在活動中,微軟德國首席技術官 Andreas Braun 表示 GPT-4 即將發布,自從 3 月初多模態模型 Kosmos-1 發布以來,微軟一直在測試和調整來自 OpenAI 的多模態模型。
GPT-4,下周就出
「我們將在下周推出 GPT-4,它是一個多模態的模型,將提供完全不同的可能性 —— 例如視頻(生成能力),」Braun 說道,他將語言大模型形容為游戲規則改變者,因為人們在這種方法之上讓機器理解自然語言,機器就能以統計方式理解以前只能由人類閱讀和理解的內容。
與此同時,這項技術已經發展到基本上「適用于所有語言」:你可以用德語提問,然后用意大利語得到答案。借助多模態,微軟和 OpenAI 將使「模型變得全面」。
改變業界
微軟德國公司首席執行官 Marianne Janik 全面談到了人工智能對業界的顛覆性影響。Janik 強調了人工智能的價值創造潛力,并表示,當前的人工智能發展和 ChatGPT 是「iPhone 發布一樣的時刻」。她表示,這不是要代替人類工作,而是幫助人們以不同于以往的方式完成重復性任務。
改變并不一定意味著失業。Janik 強調說,這意味著「許多專家會開始利用 AI 實現價值增長」。傳統的工作行為正在發生變化,由于新的可能性出現,也會產生全新的職業。她建議公司成立內部「能力中心」,培訓員工使用人工智能并將想法整合到項目中。
此外,Janik 還強調,微軟不會使用客戶的數據來訓練模型(但值得注意是,根據 ChatGPT 的政策,這不會或至少不會適用于他們的研究合作伙伴 OpenAI)。

實際用例
微軟的兩位 AI 技術專家 Clemens Sieber 和 Holger Kenn 提供了關于 AI 實際使用的一些信息。他們的團隊目前正在處理具體的用例,他們講解了用例涉及的技術。
Kenn 解釋了什么是多模態人工智能,它不僅可以將文本相應地翻譯成圖像,還可以翻譯成音樂和視頻。除了 GPT-3.5 模型之外,他還談到了嵌入,用于模型中文本的內部表征。根據 Kenn 的說法,「負責任」的 AI 已經內置到微軟的產品中,并且可以通過云將數百萬個查詢映射到 API 中。
Clemens Siebler 則用用例說明了今天已經成為可能的事情,例如可以把電話呼叫的語音直接記錄成文本。根據 Siebler 的說法,這可以為微軟在荷蘭的一家大型客戶每天節省 500 個工作小時。該項目的原型是在兩個小時內創建的,一個開發人員在兩周內完成了該項目。據他介紹,三個最常見的用例是回答只有員工才能訪問的公司信息、AI 輔助文檔處理和在呼叫中心處理口語的半自動化。
微軟表示人們很快就會與其全新的 AI 工具見面。特別是在編程領域,Codex 和 Copilot 等模型可以更輕松地創建代碼,令人期待。
當被問及操作可靠性和事實保真度時,Siebler 表示 AI 不會總是正確回答,因此有必要進行驗證。微軟目前正在創建置信度指標來解決此問題。通常,客戶僅在自己的數據集上使用 AI 工具,主要用于閱讀理解和查詢庫存數據,在這些情況下,模型已經相當準確。然而,模型生成的文本仍然是生成性的,因此不容易驗證。Siebler 表示微軟圍繞生成型 AI 建立了一個反饋循環,包括贊成和反對,這是一個迭代的過程。
看來在 AI 大模型的競爭中,領先的一方也加快了腳步。微軟在過去一周左右接連發布了展示多模態的語言大模型論文 Kosmos-1 和 Visual ChatGPT,這家公司顯然非常支持多模態,希望能夠做到使感知與 LLM 保持一致,如此一來就能讓單個 AI 模型看文字圖片,也能「說話」。
微軟的下次 AI 活動選在了 3 月 16 日,CEO 薩蒂亞?納德拉將親自上臺演講,不知他們是否會在這次活動上發布 GPT-4。有趣的是,微軟的活動和百度推出文心一言選在了同一天。
距離 3 月 16 日百度推出類 ChatGPT 聊天機器人還有一周時間,最近有報道稱,百度正在抓緊時間趕在發布最后期限前完成任務。目前看來,百度打算分階段推出文心一言的各項功能,并首先向部分用戶開放公測。知情人士稱,在春節假期過后,李彥宏就要求包括自動駕駛部門在內的全公司 AI 研究團隊將英偉達 A100 支援給文心一言的開發。
7. 谷歌報復性砸出5620億參數大模型!比ChatGPT更恐怖,機器人都能用,學術圈已刷屏
原文:https://mp.weixin.qq.com/s/Se3xzcF6rtgcI7YXYgDZ8Q
為應對新一輪技術競賽,谷歌還在不斷出后手。
這兩天,一個名叫PaLM-E的大模型在AI學術圈瘋狂刷屏。
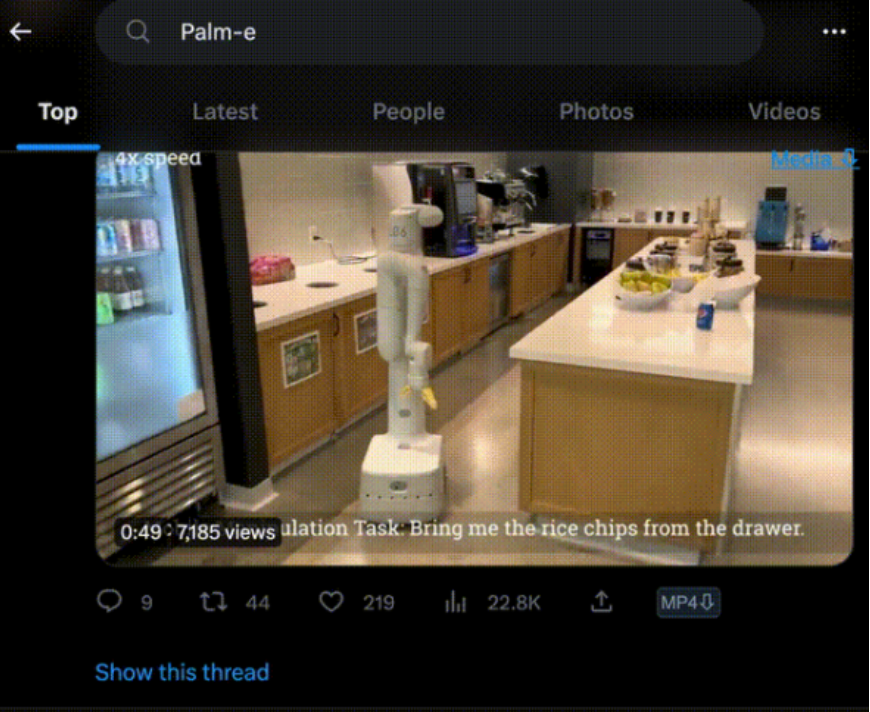
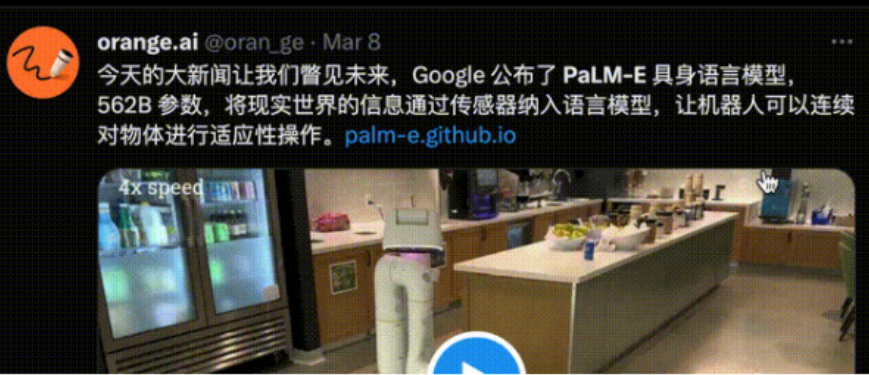
它能只需一句話,就讓機器人去廚房抽屜里拿薯片。即便是中途干擾它,它也會堅持執行任務。
PaLM-E擁有5620億參數,是GPT-3的三倍多,號稱史上最大規模視覺語言模型。而它背后的打造團隊,正是谷歌和柏林工業大學。
作為一個能處理多模態信息的大模型,它還兼具非常強的邏輯思維。
比如能從一堆圖片里,判斷出哪個是能滾動的。

還會看圖做算數:

有人感慨:
這項工作比ChatGPT離AGI更近一步啊!
而另一邊,微軟其實也在嘗試ChatGPT指揮機器人干活。
這么看,谷歌是憑借PaLM-E一步到位了?
邏輯性更強的大模型
PaLM-E是將PaLM和ViT強強聯合。
5620億的參數量,其實就是如上兩個模型參數量相加而來(5400億+220億)。
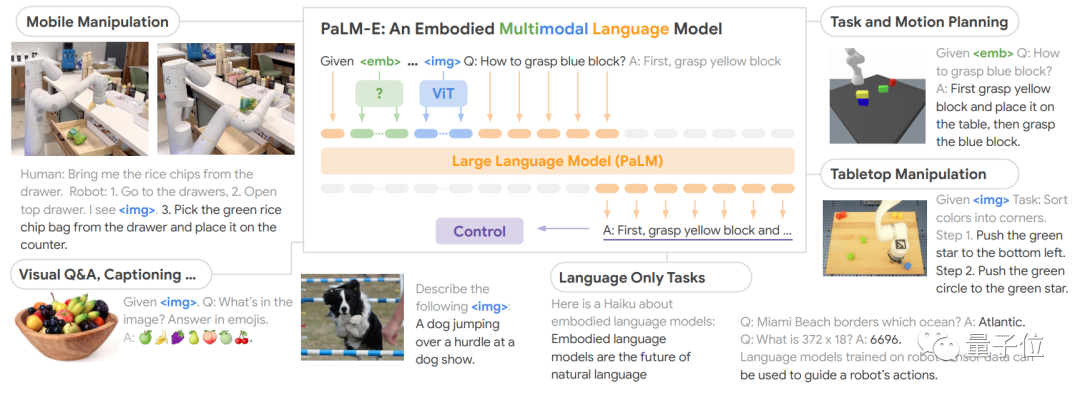
PaLM是谷歌在22年發布的語言大模型,它是Pathways架構訓練出來的,能通過“思考過程提示”獲得更準確的邏輯推理能力,減少AI生成內容中的錯誤和胡言亂語。
Pathways是一種稀疏模型架構,是谷歌AI這兩年重點發展方向之一,目標就是訓練出可執行成千上百種任務的通用模型。
ViT是計算機視覺領域的經典工作了,即Vision Transformer。
兩者結合后,PaLM-E可以處理多模態信息。包括:
-
語言
-
圖像
-
場景表征
-
物體表征
通過加一個編碼器,模型可以將圖像或傳感器數據編碼為一系列與語言標記大小相同的向量,將此作為輸入用于下一個token預測,進行端到端訓練。
具體能力方面,PaLM-E表現出了比較強的邏輯性。
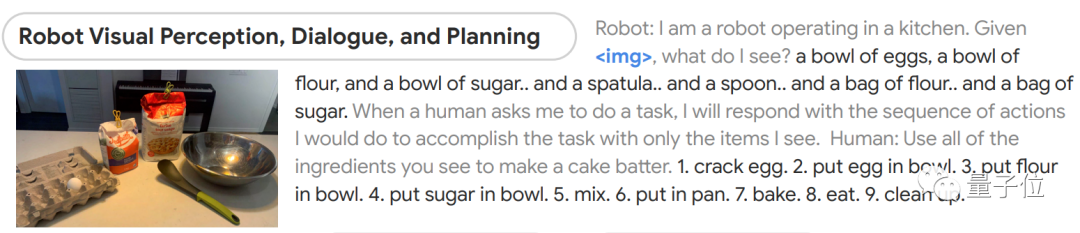
比如給它一張圖片,然后讓它根據所看到的做出蛋糕。
模型能先判斷出圖像中都有什么,然后分成9步講了該如何制作蛋糕,從最初的磕雞蛋到最后洗碗都包括在內。
再次驗證大力出奇跡
目前這項研究已引發非常廣泛的討論。
主要在于以下幾個方面:
1、一定程度上驗證了“大力出奇跡”
2、比ChatGPT更接近AGI?
一方面,作為目前已知的規模最大的視覺語言模型,PaLM-E的表現已經足夠驚艷了。
去年,DeepMind也發布過一個通才大模型Gota,在604個不同的任務上接受了訓練。
但當時有很多人認為它并不算真正意義上的通用,因為研究無法證明模型在不同任務之間發生了正向遷移。
論文作者表示,這或許是因為模型規模還不夠大。
如今,PaLM-E似乎完成了這一論證。

不過也有聲音擔心,這是不是把卷參數從NLP引到了CV圈?
另一方面,是從大趨勢上來看。
有人表示,這項工作看上去要比ChatGPT更接近AGI啊。
的確,用ChatGPT還只是提供文字建議,很多具體動手的事還要自己來。
但PaLM-E屬于把大模型能力拉入到具象化層面,AI和物理世界之間的結界要被打破了。
而且這個趨勢顯然也是大家都在琢磨的,微軟前不久也發布了一項非常相似的工作——讓ChatGPT指揮機器人。
除此之外,還有很多人表示,這再一次驗證了多模態是未來。
不過,這項成果現在只有論文和demo發布,真正能力有待驗證。
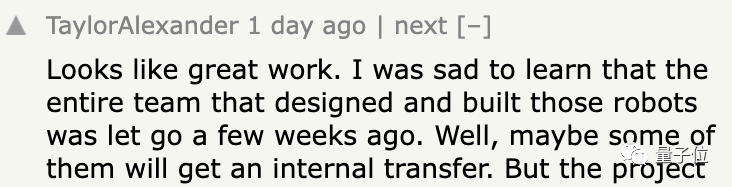
此外還有人發現,模型驅動的機器人,背后的開發團隊在幾周前被谷歌一鍋端了。。。
———————End———————
RT-Thread線下入門培訓
如果你愿意在所在城市協調組織活動(包括尋找合適場地或主持或宣傳),請掃碼填寫以下合作信息,我們將盡快聯系你;
如果你愿意在所在城市為活動提供場地的支持(場地需要有投影等設備),請掃碼填寫以下合作信息,我們將盡快聯系你;
如果你愿意為活動提供禮品/板卡贊助,請掃碼填寫以下合作信息,我們將盡快聯系你;

巡回城市:青島、北京、西安、成都、武漢、鄭州、杭州、深圳
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進RT-Thread官方微信交流群!
你也可以把文章轉給學校老師、公司領導等相關人員,讓RT-Thread可以惠及更多的開發者
-
RT-Thread
+關注
關注
31文章
1289瀏覽量
40135 -
大模型
+關注
關注
2文章
2450瀏覽量
2714
原文標題:【AI簡報20230310】知存科技再推存算一體芯片、微軟:多模態大模型GPT-4就在下周
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
存算于芯 · 智啟未來 — 2024蘋芯科技產品發布會盛大召開

存算一體架構創新助力國產大算力AI芯片騰飛
科技新突破:首款支持多模態存算一體AI芯片成功問世

蘋芯科技引領存算一體技術革新 PIMCHIP系列芯片重塑AI計算新格局

后摩智能推出邊端大模型AI芯片M30,展現出存算一體架構優勢
知存科技助力AI應用落地:WTMDK2101-ZT1評估板實地評測與性能揭秘
存內計算WTM2101編譯工具鏈 資料
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究

知存科技攜手北大共建存算一體化技術實驗室,推動AI創新
北京大學-知存科技存算一體聯合實驗室揭牌,開啟知存科技產學研融合戰略新升級






 工商網監
工商網監
評論